提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
本文章适合于入门小白,利用此框架可以分析做大多数图像重建任务,若要此工程项目,请私信!
该模板是所有图像重建任务的入门模板。
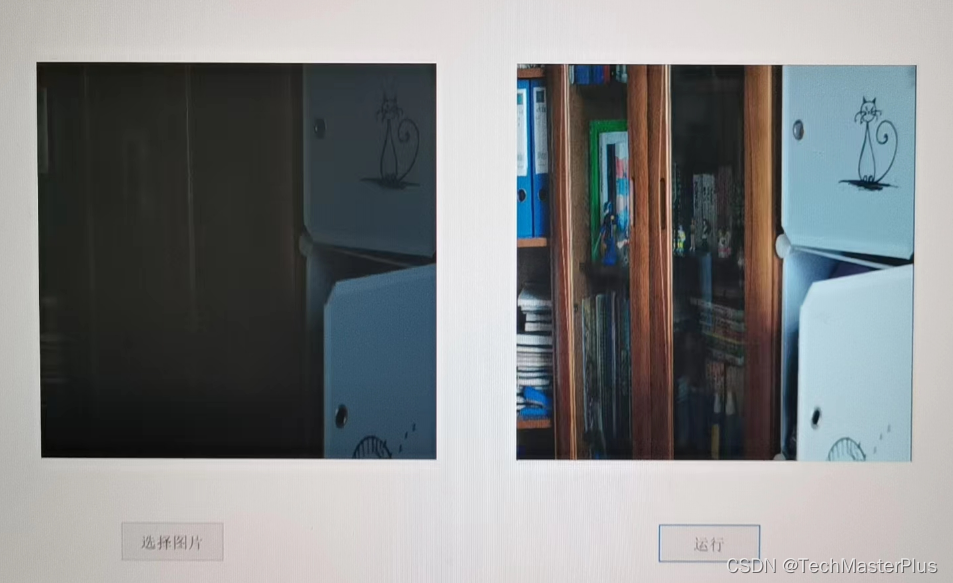
结果图片

一、导入相关包
此处较难安装的库是 torch、其余均可用以下命令:
pip install XXX(包的名称) -i https://pypi.tuna.tsinghua.edu.cn/simple/
来解决,安装torch可以参考博客https://mp.csdn.net/mp_blog/creation/editor/129744112
# 导入相关库
# PyTorch 库
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as Data
import torch.nn.functional as F
import torchvision
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import CosineAnnealingLR
# 工具库
import numpy as np
import cv2
import random
import time
import os
import re
from tqdm.auto import tqdm
import matplotlib.pyplot as plt
from torch.autograd import Variable
import numpy as np
from math import exp
from PIL import Image二、准备数据集
1.加载数据集的dataset
此处为了方便大家训练,设置图像较小,重写数据集类
代码如下(示例):
class MyTrainDataset(Dataset):
def __init__(self, input_path, label_path):
self.input_path = input_path
self.input_files = os.listdir(input_path)
self.label_path = label_path
self.label_files = os.listdir(label_path)
self.transforms = transforms.Compose([
transforms.CenterCrop([64, 64]),
transforms.ToTensor(),
])
def __len__(self):
return len(self.input_files)
def __getitem__(self, index):
label_image_path = os.path.join(self.label_path, self.label_files[index])
label_image = Image.open(label_image_path).convert('RGB')
'''
Ensure input and label are in couple.
'''
#temp = self.label_files[index][:-4]
#self.input_files[index] = temp + 'x2.png'
input_image_path = os.path.join(self.input_path, self.input_files[index])
input_image = Image.open(input_image_path).convert('RGB')
input = self.transforms(input_image)
label = self.transforms(label_image)
return input, label
'''
Dataset for testing.
'''
class MyValidDataset(Dataset):
def __init__(self, input_path, label_path):
self.input_path = input_path
self.input_files = os.listdir(input_path)
self.label_path = label_path
self.label_files = os.listdir(label_path)
self.transforms = transforms.Compose([
transforms.Resize([512, 512]),
transforms.ToTensor(),
])
def __len__(self):
return len(self.input_files)
def __getitem__(self, index):
label_image_path = os.path.join(self.label_path, self.label_files[index])
label_image = Image.open(label_image_path).convert('RGB')
#temp = self.label_files[index][:-4]
#self.input_files[index] = temp + 'x2.png'
input_image_path = os.path.join(self.input_path, self.input_files[index])
input_image = Image.open(input_image_path).convert('RGB')
input = self.transforms(input_image)
label = self.transforms(label_image)
return input, label
2.读入数据
将相应得input_path,label_path,valid_input_path,valid_label_path修改为自己的图片路径即可.
代码如下(示例):
input_path = "./low_light_images"
label_path = "./reference_images"
valid_input_path = './test/test_low'
valid_label_path = './test/test_high'
dataset_train = MyTrainDataset(input_path, label_path)
dataset_valid = MyValidDataset(valid_input_path, valid_label_path)
train_loader = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, pin_memory=True)
valid_loader = DataLoader(dataset_valid, batch_size=batch_size, shuffle=True, pin_memory=True)3、数据集格式
四个文件夹下面的图片故事如下:
——low_light_images
——train1.jpg
——train2.jpg
...
——rederence_images
——train1.jpg
——train2.jpg
...
——test_low
——test1.jpg
——test2.jpg
...
——test_high
——test1.jpg
——test2.jpg
...
三、构建模型
此处使用图像去雨的prNet模型
如果需要有别的任务,可以换别得模型,用prNet也可以完成建模,效果可能不佳。
# 网络架构
class PReNet_r(nn.Module):
def __init__(self, recurrent_iter=6, use_GPU=True):
super(PReNet_r, self).__init__()
self.iteration = recurrent_iter
self.use_GPU = use_GPU
self.conv0 = nn.Sequential(
nn.Conv2d(6, 32, 3, 1, 1),
nn.ReLU()
)
self.res_conv1 = nn.Sequential(
nn.Conv2d(32, 32, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(32, 32, 3, 1, 1),
nn.ReLU()
)
self.conv_i = nn.Sequential(
nn.Conv2d(32 + 32, 32, 3, 1, 1),
nn.Sigmoid()
)
self.conv_f = nn.Sequential(
nn.Conv2d(32 + 32, 32, 3, 1, 1),
nn.Sigmoid()
)
self.conv_g = nn.Sequential(
nn.Conv2d(32 + 32, 32, 3, 1, 1),
nn.Tanh()
)
self.conv_o = nn.Sequential(
nn.Conv2d(32 + 32, 32, 3, 1, 1),
nn.Sigmoid()
)
self.conv = nn.Sequential(
nn.Conv2d(32, 3, 3, 1, 1),
)
def forward(self, input):
batch_size, row, col = input.size(0), input.size(2), input.size(3)
#mask = Variable(torch.ones(batch_size, 3, row, col)).cuda()
x = input
h = Variable(torch.zeros(batch_size, 32, row, col))
c = Variable(torch.zeros(batch_size, 32, row, col))
if self.use_GPU:
h = h.cuda()
c = c.cuda()
x_list = []
for i in range(self.iteration):
x = torch.cat((input, x), 1)
x = self.conv0(x)
x = torch.cat((x, h), 1)
i = self.conv_i(x)
f = self.conv_f(x)
g = self.conv_g(x)
o = self.conv_o(x)
c = f * c + i * g
h = o * torch.tanh(c)
x = h
for j in range(5):
resx = x
x = F.relu(self.res_conv1(x) + resx)
x = self.conv(x)
x = input + x
x_list.append(x)
return x, x_list
四、损失函数实现
图像重建一般均得评价一般是用ssim来评价,因此损失函数大多也是用ssim,这里一般情况下不用做改动
def gaussian(window_size, sigma):
gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
return gauss/gauss.sum()
def create_window(window_size, channel):
_1D_window = gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
return window
def _ssim(img1, img2, window, window_size, channel, size_average = True):
mu1 = F.conv2d(img1, window, padding = window_size//2, groups = channel)
mu2 = F.conv2d(img2, window, padding = window_size//2, groups = channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1*mu2
sigma1_sq = F.conv2d(img1*img1, window, padding = window_size//2, groups = channel) - mu1_sq
sigma2_sq = F.conv2d(img2*img2, window, padding = window_size//2, groups = channel) - mu2_sq
sigma12 = F.conv2d(img1*img2, window, padding = window_size//2, groups = channel) - mu1_mu2
C1 = 0.01**2
C2 = 0.03**2
ssim_map = ((2*mu1_mu2 + C1)*(2*sigma12 + C2))/((mu1_sq + mu2_sq + C1)*(sigma1_sq + sigma2_sq + C2))
if size_average:
return ssim_map.mean()
else:
return ssim_map.mean(1).mean(1).mean(1)
class SSIM(torch.nn.Module):
def __init__(self, window_size = 11, size_average = True):
super(SSIM, self).__init__()
self.window_size = window_size
self.size_average = size_average
self.channel = 1
self.window = create_window(window_size, self.channel)
def forward(self, img1, img2):
(_, channel, _, _) = img1.size()
if channel == self.channel and self.window.data.type() == img1.data.type():
window = self.window
else:
window = create_window(self.window_size, channel)
if img1.is_cuda:
window = window.cuda(img1.get_device())
window = window.type_as(img1)
self.window = window
self.channel = channel
return _ssim(img1, img2, window, self.window_size, channel, self.size_average)
def ssim(img1, img2, window_size = 11, size_average = True):
(_, channel, _, _) = img1.size()
window = create_window(window_size, channel)
if img1.is_cuda:
window = window.cuda(img1.get_device())
window = window.type_as(img1)
return _ssim(img1, img2, window, window_size, channel, size_average)
五、优化器、超参数等设置
设置学习率,批次大小和迭代次数
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
learning_rate = 1e-3
batch_size = 2
epoch = 60
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
scheduler = CosineAnnealingLR(optimizer, T_max=epoch)
六、训练和验证
for i in range(epoch):
# ---------------Train----------------
net.train()
train_losses = []
'''
tqdm is a toolkit for progress bar.
'''
for batch in tqdm(train_loader):
inputs, labels = batch
outputs, _ = net(inputs.to(device))
loss = loss_f(labels.to(device), outputs)
loss = -loss
optimizer.zero_grad()
loss.backward()
'''
Avoid grad to be too BIG.
'''
grad_norm = nn.utils.clip_grad_norm_(net.parameters(), max_norm=10)
optimizer.step()
'''
Attension:
We need set 'loss.item()' to turn Tensor into Numpy, or plt will not work.
'''
train_losses.append(loss.item())
train_loss = sum(train_losses) / len(train_losses)
Loss_list.append(train_loss)
print(f"[ Train | {i + 1:03d}/{epoch:03d} ] SSIM_loss = {train_loss:.5f}")
scheduler.step()
for param_group in optimizer.param_groups:
learning_rate_list.append(param_group["lr"])
print('learning rate %f' % param_group["lr"])
# -------------Validation-------------
'''
Validation is a step to ensure training process is working.
You can also exploit Validation to see if your net work is overfitting.
Firstly, you should set model.eval(), to ensure parameters not training.
'''
net.eval()
valid_losses = []
for batch in tqdm(valid_loader):
inputs, labels = batch
'''
Cancel gradient decent.
'''
with torch.no_grad():
outputs, _ = net(inputs.to(device))
loss = loss_f(labels.to(device), outputs)
loss = -loss
valid_losses.append(loss.item())
valid_loss = sum(valid_losses) / len(valid_losses)
Valid_Loss_list.append(valid_loss)
print(f"[ Valid | {i + 1:03d}/{epoch:03d} ] SSIM_loss = {valid_loss:.5f}")
break_point = i + 1
'''
Update Logs and save the best model.
Patience is also checked.
'''
if valid_loss < best_valid_loss:
print(
f"[ Valid | {i + 1:03d}/{epoch:03d} ] SSIM_loss = {valid_loss:.5f} -> best")
else:
print(
f"[ Valid | {i + 1:03d}/{epoch:03d} ] SSIM_loss = {valid_loss:.5f}")
if valid_loss < best_valid_loss:
print(f'Best model found at epoch {i+1}, saving model')
torch.save(net.state_dict(), f'model_best.ckpt')
best_valid_loss = valid_loss
stale = 0
else:
stale += 1
if stale > patience:
print(f'No improvement {patience} consecutive epochs, early stopping.')
break
七、绘制结果图片
'''
Use plt to draw Loss curves.
'''
plt.figure(dpi=500)
plt.subplot(211)
x = range(break_point)
y = Loss_list
plt.plot(x, y, 'ro-', label='Train Loss')
plt.plot(range(break_point), Valid_Loss_list, 'bs-', label='Valid Loss')
plt.ylabel('Loss')
plt.xlabel('epochs')
plt.subplot(212)
plt.plot(x, learning_rate_list, 'ro-', label='Learning rate')
plt.ylabel('Learning rate')
plt.xlabel('epochs')
plt.legend()
plt.show()八、预测图片
修改img_path为自己的图片路径,即可完成自己得图像预测
transforms = transforms.Compose([
transforms.Resize([512, 512]),
transforms.ToTensor(),
])
img_path="test/test_low/5.png"
net = PReNet_r(use_GPU=False).to('cpu')#cuda()
net.load_state_dict(torch.load('./model_best.ckpt')) # 加载训练好的模型参数
net.eval()
input_image = Image.open(img_path).convert('RGB')
input = transforms(input_image)
input = input.to('cpu')#cuda()
input=input.unsqueeze(0)
print(input.size())
output_image = net(input)
img=output_image[0]
save_image(img, './'+str(1).zfill(4)+'.jpg') # 直接保存张量图片,自动转换总结
本文适用于图像重建任务的小白入门,其中包括,图像去噪、图像去雨、图像对比度调整、图像压缩等等等,均可以通过改变模型来实现任务,因为图像输入和输出均为(3,512,512)相对来讲,修改比较容易。