项目:入门卷积注意力/卷积注意力机制对ResNet的改进
简介
此项目以常用又基础的三类卷积注意力模块对ResNet-18的改进为例,在CIFAR-10数据集上做图片分类效果的对比,以此学习卷积注意力机制的原理与观察效果。
结论
在ResNet-18这种浅层网络中,以SE注意力模块为代表的传统通道注意力机制模块对网络的改进,能达到最佳分类精度。甚至精度与参数为改进模型的近两倍ResNet-34相差甚微。在深层网络中表现优秀的ECA注意力模块和CBAM注意力模块在ResNet-18中的对分类精度有提升但不如SE注意力模块。

卷积注意力机制原理(省流版)
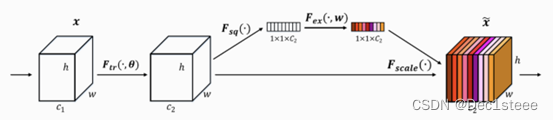
SE注意力机制:特征图(假设为A)后面加一条分支,先全局平均池化,增加全连接层学习特征图每个通道的注意力权重(网络更应该关注哪个通道)然后把学习到的权重经过sigmoid压缩到0-1直接的比重,重新逐个通道对应乘回特征图(A)中。
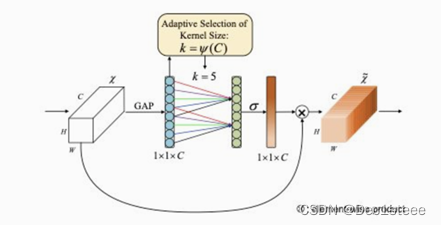
ECA注意力机制:前面步骤与SE一样,但不再是以对每个通道接入全连接层的方式学习每个通道的权重,而是学习一维卷积核,用一维卷积的形式去的方式学习每个通道的权重。优点考虑了位置信息和简化了参数。
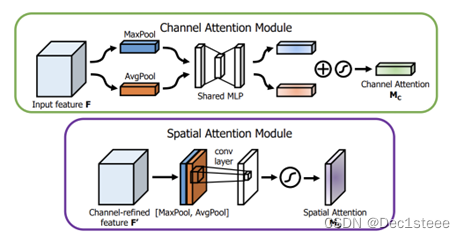
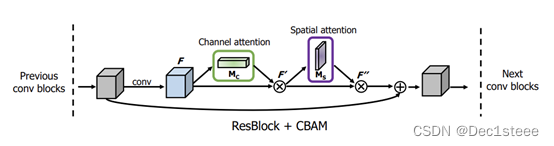
CBAM注意力机制:前面步骤与SE基本一样,先对每个通道接入全连接层的方式学习每个通道的注意力权重。第二步,再学习二维卷积核,用二维卷积的形式去的方式学习特征图每个像素的权重。通道 + 空间
代码实现
导包
import os
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader as DataLoader
from torchinfo import summary
from d2l import torch as d2l
from tqdm import tqdm
ResNet 模型
class ResNet(nn.Module):
def __init__(self, backend='resnet18'):
self.backend = backend # 卷积网络的后端
# 调用父类的初始化方法
super(ResNet, self).__init__()
self.feature_extractor = getattr(torchvision.models, backend)(pretrained=True)
self.cnn = nn.Sequential(
self.feature_extractor.conv1,
self.feature_extractor.bn1,
self.feature_extractor.relu,
self.feature_extractor.maxpool,
self.feature_extractor.layer1,
self.feature_extractor.layer2,
self.feature_extractor.layer3,
self.feature_extractor.layer4,
)
self.softmax = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(self.feature_extractor.fc.in_features, 10)
)
def forward(self, x):
features = self.cnn(x)
y = self.softmax(features)
return y
SE注意力模块
class SEBlock(nn.Module):
def __init__(self, channel, reduction=16):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
EAC注意力模块
class ECA_Layer(nn.Module):
def __init__(self, channels,gamma=2,b=1):
super(ECA_Layer, self).__init__()
k=int(abs((math.log(channels ,2)+b)/gamma))
kernel_size=k if k % 2 else k+1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size // 2), bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
# 变为 [1, 1, channels] 方便进行1d卷积
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y) * x
return y
CBAM注意力模块
class CBAM(nn.Module):
def __init__(self,in_channel,reduction=16,kernel_size=7):
super(CBAM, self).__init__()
#通道注意力机制
self.max_pool=nn.AdaptiveMaxPool2d(output_size=1)
self.avg_pool=nn.AdaptiveAvgPool2d(output_size=1)
self.mlp=nn.Sequential(
nn.Linear(in_features=in_channel,out_features=in_channel//reduction,bias=False),
nn.ReLU(),
nn.Linear(in_features=in_channel//reduction,out_features=in_channel,bias=False)
)
self.sigmoid=nn.Sigmoid()
#空间注意力机制
self.conv=nn.Conv2d(in_channels=2,out_channels=1,kernel_size=kernel_size ,stride=1,padding=kernel_size//2,bias=False)
def forward(self,x):
#通道注意力机制
maxout=self.max_pool(x)
maxout=self.mlp(maxout.view(maxout.size(0),-1))
avgout=self.avg_pool(x)
avgout=self.mlp(avgout.view(avgout.size(0),-1))
channel_out=self.sigmoid(maxout+avgout)
channel_out=channel_out.view(x.size(0),x.size(1),1,1)
channel_out=channel_out*x
#空间注意力机制
max_out,_=torch.max(channel_out,dim=1,keepdim=True)
mean_out=torch.mean(channel_out,dim=1,keepdim=True)
out=torch.cat((max_out,mean_out),dim=1)
out=self.sigmoid(self.conv(out))
out=out*channel_out
return out
注意力模块对ResNet 的改进
下列代码以SE注意力模块对ResNet的改进为例,注意力模块分别插入网络的layer1 - layer4之后。其他注意力模块的改进同理。
class ResNet(nn.Module):
def __init__(self, backend='resnet18'):
self.backend = backend # 卷积网络的后端
# 调用父类的初始化方法
super(ResNet, self).__init__()
self.feature_extractor = getattr(torchvision.models, backend)(pretrained=True)
# SE attention block
self._SE1 = SEBlock(self.feature_extractor.layer2[0].conv1.in_channels)
self._SE2 = SEBlock(self.feature_extractor.layer3[0].conv1.in_channels)
self._SE3 = SEBlock(self.feature_extractor.layer4[0].conv1.in_channels)
self.last_SE = SEBlock(self.feature_extractor.fc.in_features)
self.cnn = nn.Sequential(
self.feature_extractor.conv1,
self.feature_extractor.bn1,
self.feature_extractor.relu,
self.feature_extractor.maxpool,
self.feature_extractor.layer1,
self._SE1,
self.feature_extractor.layer2,
self._SE2,
self.feature_extractor.layer3,
self._SE3,
self.feature_extractor.layer4,
)
self.softmax = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(self.feature_extractor.fc.in_features, 10)
)
def forward(self, x):
features = self.cnn(x)
features = self.last_SE(features)
y = self.softmax(features)
return y
数据集
transform = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomResizedCrop(
(224, 224)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
test_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop((224, 224)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]),
])
def load_cifar10(is_train=True, transform=None, batch_size=128):
dataset = torchvision.datasets.CIFAR10(root="dataset",train=is_train,
transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=is_train)
return dataloader
训练
下列代码以SE注意力模块对ResNet的改进为例,其他注意力模块的改进同理。
def load_model(net, backend):
if os.path.exists('model/' + "cifar10_SE" + backend + ".params"):
info = torch.load('model/' + "cifar10_SE" + backend + ".params")
net.load_state_dict(info['model_state_dict'])
resume_epoch = info['epoch']
if info['best']:
best = info['best']
print('best acc:', best)
else:
best = 0
print('best acc: NA')
print("cifar10_SE" + backend + ": Load Successful.")
else:
print("File not found.")
resume_epoch = 0
best = 0
return net, resume_epoch, best
def train(net, train_iter, test_iter, num_epochs, lr, device, param_group=True):
print('training on', device)
net, resume_epoch, best = load_model(net, backend)
net.to(device)
for name, param in net.named_parameters():
print(name)
params_1x = [param for name, param in net.named_parameters()
if 'SE' not in name and 'softmax' not in name]
params_2x = [param for name, param in net.named_parameters()
if 'SE' in name or 'softmax' in name]
if param_group:
optimizer = torch.optim.Adam([{
'params': params_1x, 'lr': 1e-5},
{
'params': params_2x, 'lr': lr}],
weight_decay=1e-4
)
for param_group in optimizer.param_groups:
param_group["initial_lr"] = param_group["lr"]
else:
optimizer = torch.optim.Adam(net.parameters(), weight_decay=1e-4 ,lr=lr)
# 遍历每个参数组,并手动设置初始的学习率
for param_group in optimizer.param_groups:
param_group["initial_lr"] = lr
loss = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 100, gamma=0.1)
animator = d2l.Animator(xlabel='epoch', xlim=[resume_epoch+1, num_epochs+resume_epoch], ylim=[0, 1.0],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(resume_epoch, num_epochs+resume_epoch):
print('epochs:',epoch+1)
metric = d2l.Accumulator(3)
net.train()
iterator = tqdm(test_iter)
for i, (X, y) in enumerate(iterator):
timer.start()
optimizer.zero_grad()
# print(X.shape)
# print(type(X))
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
status = f"epoch: {
epoch+1}, loss: {
train_l:.3f}, train_acc: {
train_acc:.3f}, lr: {
scheduler.get_lr()}"
iterator.set_description(status)
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
scheduler.step()
print(f'test acc {
test_acc:.3f}')
if test_acc > best:
print('wait a moment...')
best = test_acc
torch.save({
'model_state_dict': net.state_dict(),
'epoch': epoch+1,
'best': best},
os.path.join('model/', "cifar10_SE" + backend + ".params"))
print(f'loss {
train_l:.4f}, train acc {
train_acc:.4f}, '
f'best acc {
best:.4f}')
print(f'{
metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {
str(device)}')
d2l.plt.savefig("Picture_SE.png")
if __name__ == '__main__':
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
lr = 0.01
backend = 'resnet18'
net = ResNet(backend)
batch_size = 128
train_iter = load_cifar10(True, transform, batch_size)
test_iter = load_cifar10(False, test_transform, batch_size)
summary(net, (1, 3, 224, 224), device='cuda')
train(net, train_iter, test_iter, 300, lr, device, True)