2023最新广西大学计算机电子信息考研复试之计算机网络和软件工程 828数据结构与程序设计上岸冲刺复试宝典(复试版/复试资料)+线下笔试真题
适用专业:计算机科学与技术(学硕)
计算机技术(专硕)、人工智能(专硕)
前言
首先恭喜大家完成了第一阶段的考验,也就是初试。过完年后,应该要慢慢的开始准备复试了,广西大学计算机与电子信息学院的复试还是非常重要的,官网有换算公式,我直接说的实际点,告诉你们算完之后是什么样子的。复试1分==初试5分。就是这个比例,换句话也就是说假如你和你的竞争对手考了一样的初试成绩,你的复试成绩是70分,别人的复试成绩是80分,相当于人家初试比你多考了5*10=50分,可见复试的重要性。
这边建议能过B区国家线就去好好准备复试,即使分数较低也一定要争取一下,过去两年很不少总分260-280的同学成功录取的。存在有复试没有好好准备,初试分数还可以的同学被刷下去的情况。
本文档包括:复试分数占比、复试具体流程、必背抽题知识点(按考纲整理版)、综面内容和答题模板、避免原则错误提醒。
复试分数占比
复试分数占比:20+30+50
英语口语:20分
专业抽题面试:30分(3-4道,一般为3道,每道10分)
综合素质面试:50分
调剂的初试取公共课成绩除以350,转变为百分制,后与复试成绩,各算50%,一志愿的取全部科目分数除以400.
具体换算后怎么样的可以直接看前言,我算好的了。
最后按照总成绩排名录取,总成绩为百分制。2022年的情况是这样子的,23年估计也差不多。一志愿和调剂的同学分开计算分数,专硕全日制没有调剂名额,学硕有调剂名额,非全有调剂名额,调剂的不算专业课分数,进行调剂同学内部排名。
所以公共课(数+英+政)偏低的,要在复试中好好表现,因为专业课抽题如果运气不好会拿到比较偏门的题目。在现在时间紧张的情况下,我们在专业题方面只看常考的或者重点内容,另外综合面试好好准备,这是大头分数并且最容易准备。
复试具体流程
复试前期材料准备:
考生报到所需材料如下(在每份材料扫描件右上角均注明拟复试学科专业名称、研究方向或者专业学位领域、考生编号、考生姓名,打*号为必须提供的材料):
(1)*参加复试考生需提交1份《学业研修规划报告》(简称《报告》,模板见附录)。 PS:学业研修报告是22年广西大学所有人在复试前都要准备的东西,也是22年才有的,重要性不要多说。23年百分之99也会有。需要指导怎么写可以后台私。
《报告》内容应体现个人对研究生阶段学习的目标,课题研究的思考和准备,完成研究生阶段学习预期取得的学术成就等内容。复试考生的《报告》需本人签字,扫描件于复试前提交至学院。一旦录取,《学业研修规划报告》作为研究生培养要求予以执行。未提交《学业研修规划报告》的考生,学校有权拒绝其复试资格;
(2)*本人准考证以及第二代居民身份证扫描件;
(3)*准考证、学历证书、学位证书或者学生证扫描件各一份(凡在国外获得毕业证书或学位证书的考生,提供由教育部留学服务中心出具的国外学历学位认证证书原件和复印件);
(4)*学籍学历校验未获通过的考生,须准备好学历或学籍认证报告。具体要求:应届本科毕业生提供《教育部学籍在线验证报告》;往届生提供《教育部学历证书电子注册备案表》或《中国高等教育学历认证报告》;
(5)大学期间成绩单原件(加盖学校教务部门公章)或档案中成绩单扫描件(加盖档案单位公章);
(6)各项获奖证书、考级证书、发表的论文及证明考生业绩能力的材料;
(7)*享受少数民族政策的考生须提供户口本扫描件,且以现场报名时的查验的身份为准;
(8)*享受专项计划考生的相关证明材料原件、复印件,如报考“少数民族高层次骨干人才计划”的考生需提交生源地教育厅盖章的《报考2022年少数民族高层次骨干人才计划硕士研究生考生登记表》供查验,并交复印件留存学院;报考“退役大学生士兵”计划的考生需提交本人的《入伍批准书》和《退出现役证》原件供查验,并交复印件留存学院。其他如符合“大学生志愿服务西部计划”等项目可以加分的考生还需提供相关证明材料进行认证(可先提交电子文件,入学时交原件);
(9)通过相关外国语水平测试(如托福、雅思、英语专业八级、CET6等测试)的相关成绩单扫描件;
(10)*非全日制研究生提供已签字的《广西大学2022年参加非全日制学习方式复试承诺书》扫描件。非全日制硕士考生列入拟录取名单后须提交签订的定向协议书。
(11)考生所在单位出具的政审情况调查表1份(扫描版)。(在我校研究生院→下载专区→业务表格下载,纸质版在入学的时候提供);
考生将上述材料的电子文件按顺序合并制作为一个PDF文件。
复试具体流程概述:英语口语,专业抽题面试,综合面试(占比分数最多,要给老师留下印象)。
1:英语口语
这个不同组里面的不同老师问的顺序可能会不太一样。有的老师是进去就让你做自我介绍,一般是这么问:can you introduce youself?
你会答一下sure,然后开始表演你提前背诵的英文自我介绍就OK了。
还有的老师是进去先让你抽题目,大概会这么说:同学你好,现在是英语口语考察,我这里现在没有被抽到的题号还剩下1号、6号、8号,请问你要抽哪一个?你选择一个号然后仔细听问题,认真回答即可。一般都是介绍自己,学校经历,爱好,家乡,生活,梦想,为什么报考广西大学等问题,不会很难。如果出现老师提问,你无法听清,可以让老师重复一遍,如果还没有听清楚问什么,就强行作答,一定不要不说。这个环节最忌讳的就是你不说。
2:专业抽题面试
这个环节没什么好说的,就是按考纲那样子背诵,我已经按考纲要求的整理好了,放在后面,你们直接打印出来背诵就OK。一定要全部都背诵下来,这很重要。
这个我是过了一遍知识点,并且把各章知识点罗列在一张纸上,方便自己背诵(已经帮助大家整理好,见完整版资料和后文)。因为是线上复试,所以要更加注重概念、协议的理解。那如果是线下复试,根据往年的复试真题,计算问题的难度也不高。整体来说,比较简单。
3:综合面试
这个环节就比较随机了,老师爱问你什么就问你什么。可以给大家描述一下我和我舍友去年的情况,大概就是看着你的成绩单上面学过的课程,然后问你相关的内容,比如说看你学过人工智能理论,就会问你对这门课程的理解,大概率不会具体到一个特别大范围的东西。能说出个大概所以然就行。这一部分其实也是很靠运气了,有的老师问到的问题很简单,有的老师确实会问的比较难一点。
这个除了自己的本科学习经历以及获奖情况意外,有两个注意点。1、读问题不要太直(要揣测他在考你什么,问题本身有没有问题)2、回答问题不要太快。以下为举例子(更多真题和考纲必背题见后文或者获取完整版广西大学828计算机考研复试宝典):
附注:对于以上问到,某个东西比较好?它的问题等于,以上各个东西的优缺点!而不是,就让你回答某个东西比较好。比如,对于排序算法,我会回答 xxx 排序算法适用于 xxx 场合,它不适合 xxx 场合…(从思辨的角度去回答,而不是一棍子打死哪个算法比较好)。而且院长的问题很不精准,大家一定要注意,虽然说话笑嘻嘻。 再比如,对于问题 4,这个问题原本就是不清楚的,他没有限定是同一个局域网还是非同一个局域网,你得分情况讨论。总而言之,院长这组让我感觉是一定要有“思辨”的想法。整个过程没有刁难的情况,很顺利。但是,考后细想,坑很多。(这个是我去年复试的时候从前年学长那买来的资料,虽然最后我没用上,但是思想你们可以看看,好好理解问题之后再作答,保持冷静)。
更多内容/获取完整版复试宝典请可以后台踢我
必背抽题知识点(按考纲整理版)
这个部分是按考纲整理的,一定要背下来。
一:计算机网络
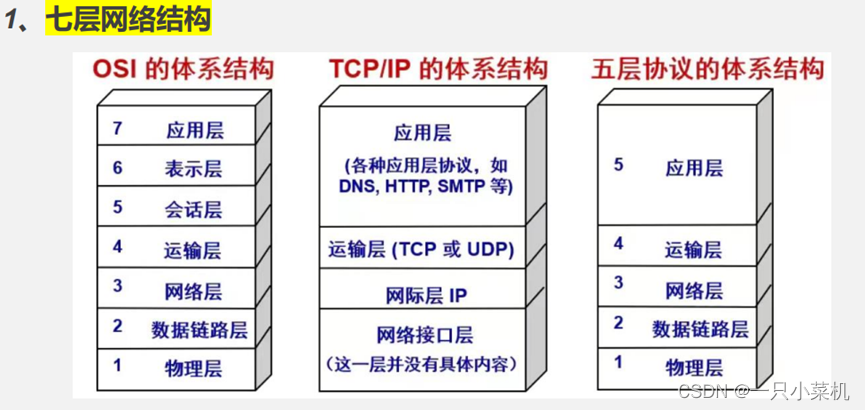
1 、简单说说计算机网络的体系结
2、单工、半双工、全双工 (属于网络传输方式的一种 还有同步和异步、串行和并行)

3、简述一下停止等待协议(stop-and-wait) 数据链路层的可靠传输
停止等待协议是数据链路层的协议,是一个保证可靠传输,以流量控制为目的的一个协议。其工作原理简单的说就是:每发送一个分组就停止发送,等待对方的确认,在收到确认后再发送下一个分组。 细节描述: ① 如果发送方如果一段时间仍没有收到确认,就认为刚才发送的分组丢失了,因而重传前面发送过的分组。 ② 如果接收方的确认分组丢失或者因其他原因,收到了重传分组,则:丢弃这个重传分组,并且再次向发送方发送确认分组。
4、滑动窗口协议
滑动窗口协议(Sliding Window Protocol),属于TCP协议的一种应用,用于网络数据传输时的流量控制,以避免拥塞的发生。该协议允许发送方在停止并等待确认前发送多个数据分组。由于发送方不必每发一个分组就停下来等待确认。因此该协议可以加速数据的传输,提高网络吞吐量。
5、网络各层的设备分别是什么?

6、谈一下CSMA/CD协议

7、谈一下PPP协议
PPP(点对点协议),面向字节,只支持全双工链路。优点1:动态的分配IP地址 2:支持多种网络协议 3:错误检测 4:无重传机制,网络开销小 5:支持身份验证,更加安全 6:可以工作在异步方式下。
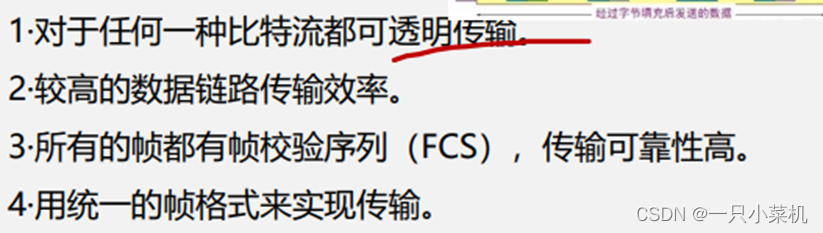
8、谈一下HDLC(高级数据链路控制协议)
HDLC(高级数据链路控制协议),面向比特。 特点如下
9、多路复用技术(频分复用 时分复用 波分复用 码分复用)
频分复用(FDM):按频率划分的不同信道,用户分到一定的频带后,在通信过程中自始至终都占用这个频带,所有用户在同样的时间占用不同的带宽资源(带宽指频率带)
时分复用(TDM):把多个信号复用到单个硬件传输信道,它允许每个信号在一个很短的时间使用信道,接着再让下一个信号使用。
波分复用:就是光的频分复用。用一根光纤同时传输多个频率很接近的光载波信号。
码分复用:码分复用是用一组包含互相正交的码字的码组携带多路信号。每一个用户可以在同样的时间使用同样的频带进行通信。由于各用户使用经过特殊挑选的不同码型,各用户之间不会造成干扰,因此这种系统发送的信号有很强的抗干扰能力。
10、说一下路由器
定义:路由器(router)是互联网的枢纽,是连接英特网中各局域网、广域网的设备,它会根据信道的情况自动选择和设定路由,以最佳路径,按前后顺序发送数据。
其作用在OSI模型的第三层,提供了路由(路由器控制层面的工作,决定数据包从来源端到目的端所经过的路由路径)与转发(路由器数据层面的工作,将路由器输入端的数据包移送至适当的路由器输出端)两种重要机制
原理:传统地,路由器工作OSI 七层协议中的第三层(网络层),其主要任务是接收来自一个网络接口的数据包,根据其中所含的目的地址,来决定转发到下一个目的地址。因此,路由器首先去掉数据包的二层头,取出目的IP 地址,在转发路由表中查找它对应的下一跳地址,若找到,就在数据包的帧格前添加下一个 MAC 地址,同时 IP 数据包头的 TTL(Time To Live)域也减一,并重新计算校验和。
功能:

11、说一下网络里时延和带宽的概念

。
12、可靠服务与不可靠服务

13、数据链路层的主要工作
数据链路层是ISO参考模型的第2层,为网络层提供服务、链路管理、帧定界、帧同步与透明传输、流量控制和差错控制。
透明传输:无论什么样的比特组合的数据,都能够按照原样没有差错地通过这个数据链路层,用户不必关心数据是如何传输的,如何进行差错检验的,而是数据发出时是怎样,用户接收时便是怎样,而不去关心数据如何加上控制等各类字符。
流量控制:流量控制是对控制链路上的帧的发送速率,使接收方有足够的缓冲空间来接收帧,主要方法有两种,停止-等待协议和滑动窗口协议,滑动窗口协议又分为后退N帧协议和选择重传协议;停止-等待协议是一种特殊的滑动窗口协议,相当于发送窗口和接收窗口大小为1的滑动窗口协议。
差错控制:传输中的差错一般是由噪声引起的,噪声分为随机热噪声和冲击噪声,前者可以通过提高信噪比来减少干扰,后者通过编码技术来进行差错控制。差错编码又可分为检错编码和纠错编码。
检错编码:主要有奇偶校验码和循环冗余码
14、谈一下电路交换、报文交换、分组交换
电路交换:电路交换在通信之前要在通信双方之间建立一条被双方独占的物理通路


报文交换:数据交换的单位是报文,报文携带有目的地址、源地址等信息。报文交换在交换节点釆用存储转发的传输方式。


分组交换:分组交换仍采用存储转发传输方式,但将一个长报文先分割为若干个较短的分组, 然后把这些分组(携带源地址、目的地址和编号信息)逐个地发送出去。


15、TCP 和 UDP 的区别

16、简单说一下三次握手的过程
三次握手是建立连接的过程,当客户端向服务端发起连接时,会先发一包连接请求数据,也就是SYN包,并置为1,接下来客户端查看能否与服务端建立连接,如果服务端同意连接,则服务端回复SYN和ACK包,并都置为1,客户端收到后,回复一包ACK包,连接建立。
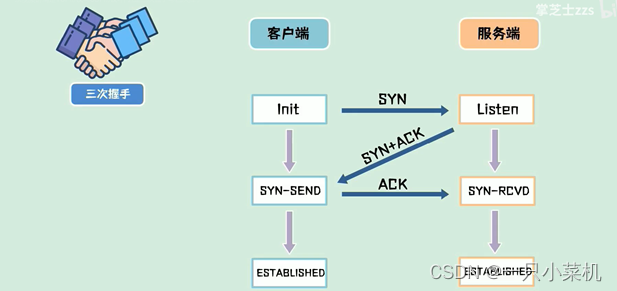
17、建立连接时两次握手为什么不行?
假设采用两次握手建立连接,客户端向服务端发数了个SYN包来请求建立连接,因为某些原因没有到达服务器,在中间某个网络节点产生了滞留,为了建立连接客户端会重新发送SYN包,假如这次的数据包正常送达,服务端回复SYN和ACK包之后建立起了连接,但是第一包数据阻塞的网络节点突然恢复,第一包SYN包又送达服务端,这时服务端又认为是客户端又发起了一个新的连接,从而在两次握手之后,服务端进入等待数据状态,服务端此时认为是两个连接,而客户端认为是一个连接,照成了状态不一致,从而照成了资源的浪费。如果在三次握手的情况下,服务端收不到最后的ACK包,自然不会认为连接建立成功,所以三次握手本质上来说,就是为了解决网络信道不可靠的问题,为了能够在不可靠的信道上建立起可靠的连接。
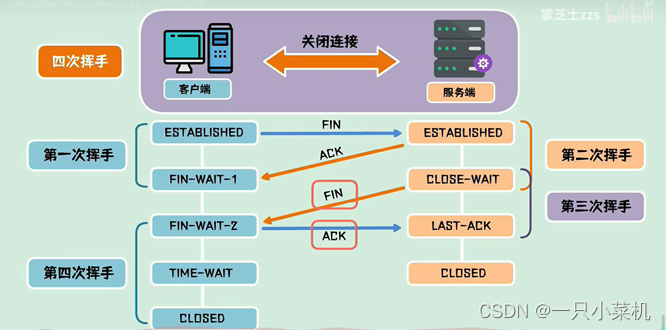
18、简单说一下四次挥手的过程
处于连接状态的客户端和服务端都可以发起关闭连接请求,此时需要四次挥手来进行连接关闭,假设客户端主动发起连接关闭请求,他需要向服务端自动发起一包FIN包,表示要关闭连接,自己进入终止等待1状态,这是第一次挥手。服务端收到FIN包,发送一包ACK包,表示自己加入了关闭等待状态,客户端进入终止等待2状态,这是第二次挥手。服务端此时还可以发送未发送的数据,客户端也可以接收数据,待服务端发送完数据之后,服务端向客户端发送一包FIN包,进入最后确认状态,这是第三次挥手。客户端收到后发送FIN包,进入超时等待状态,经过超时时间后关闭连接,而服务端收到ACK包后,立即关闭连接,这是第四次挥手。
19、在浏览器中输入一串url后发生的过程
○1:DNS域名解析
浏览器搜索自己的DNS缓存(维护一张域名与IP地址的对应表)
若没有,则搜索操作系统中的DNS缓存(维护一张域名与IP地址的对应表)
若没有,则搜索操作系统的hosts文件
若没有,则操作系统将域名发送至 本地域名服务器- -(递归查询方式),本地域名服务器 查询自己的DNS缓存,查找成功则返回结果,否则,(以下是迭代查询方式)
4.1 本地域名服务器 向根域名服务器(其虽然没有每个域名的具体信息,但存储了负责每个域,如com、net、org等的解析的顶级域名服务器的地址)发起请求,此处,根域名服务器返回com域的顶级域名服务器的地址
4.2 本地域名服务器 向com域的顶级域名服务器发起请求,返回baidu.com权限域名服务器(权限域名服务器,用来保存该区中的所有主机域名到IP地址的映射)地址
4.3 本地域名服务器 向baidu.com权限域名服务器发起请求,得到www.baidu.com的IP地址
本地域名服务器 将得到的IP地址返回给操作系统,同时自己也将IP地址缓存起来
操作系统将 IP 地址返回给浏览器,同时自己也将IP地址缓存起来
至此,浏览器已经得到了域名对应的IP地址
○2:应用层-浏览器发送HTTP请求
作为发送端的客户端在应用层(HTTP协议)发送了一个HTTP请求
○3:传输层-TCP或者UDP封装数据(HTTP请求报文)
为了传输方便,传输层选择协议(TCP协议或者UDP协议)对从应用层收到的数据(HTTP请求报文)进行封装(对收到的数据进行分割,并在各个报文上打上标记序号及端口号)后转发给网络层
○4:网络层-IP协议封装IP地址,获取目的MAC(media access control address)地址
通过IP协议将IP地址封装为IP数据报,此时会使用ARP协议(ARP是一种用以解析地址的协议,根据通信方的IP就可以反查对应的MAC地址)主机发送信息时会将包含目标IP地址信息ARP请求广播到网络上所有的主机,并接受返回消息,以此确定目标的物理地址,找到目的的MAC地址
○5:链路层-(又名数据链路层、网络接口层)建立TCP连接
把网络层交下来的IP数据添加首部和尾部,封装为MAC帧,根据目的MAC地址建立TCP连接(三次握手)
○6:服务器收到请求并响应HTTP请求
○7:浏览器解析htm代码,并请求htm代码中的资源(如js、css图片等)
○8:四次挥手断开TCP连接
20、ARP协议的工作过程 (ARP协议是通过目标IP地址来解析目标主机的MAC地址)
首先,每个主机都会在自己的 ARP 缓冲区中建立一个 ARP 列表,以表示 IP 地址 和 MAC 地址之间的对应关系。
当源主机要发送数据时,首先检查 ARP 列表中是否有对应 IP 地址的目的主机的 MAC 地址,如果有,则直接发送数据,如果没有,就向本网段的所有主机发送 ARP 数 据包,该数据包包括的内容有:源主机 IP 地址 ,源主机 MAC 地址,目的主机的 IP 地 址。
当本网络的所有主机收到该 ARP 数据包时,首先检查数据包中的 IP 地址是否是自 己的 IP 地址,如果不是,则忽略该数据包,如果是,则首先从数据包中取出源主机 的 IP 和 MAC 地址写入到 ARP 列表中,如果已经存在,则覆盖,然后将自己的 MAC 地址写入 ARP 响应包中,告诉源主机自己是它想要找的 MAC 地址。
源主机收到 ARP 响应包后。将目的主机的 IP 和 MAC 地址写入 ARP 列表,并利用此信息发送数据。 如果源主机一直没有收到 ARP 响应数据包,表示 ARP 查询失败。
21、谈一下TCP 的流量控制和拥塞控制

22、谈一下拥塞控制的四种算法
① 慢开始算法 ② 拥塞避免算法 ③ 快重传算法 ④ 快恢复算法
23、数据被重传的三种情况
帧破坏、帧丢失和应答帧丢失。
计算机网络部分暂时先暂时这么多题目,如果觉得自己有需要的话话/需要完整版的后台T我。
二:软件工程
1 、什么是软件?
软件是一系列按照特定顺序组织的计算机数据和指令的集合。
2 、什么是软件危机?
软件危机是指在计算机软件的开发和维护过程中所遇到的一系列严重问题。
3 、软件危机的典型表现
○1:对软件开发成本和进度的估计常常很不准确
○2:用户对“已完成的”软件系统不满意的现象经常发生
○3:软件产品的质量往往靠不住
○4:软件产品可维护性差
○5:软件没有合适的文档资料
○6:软件成本在计算机系统总成本中所占比例逐年上升
○7:软件开发生产率滞后于硬件和计算机应用普及
4 、软件危机产生的原因
○1:软件本身特性,软件不同与硬件,管理和控制软件开发过程相当困难,缺乏可见性、无制造过程、规模庞大且软件的开发复杂度越来越高。
○2:对软件开发错误的认识和做法,例如许多开发者认为软件就只是一般的程序,认为开发软件就是编程序、轻视文档、不懂测试、不想维护 、轻视管理等等一系列错误观念导致了软件危机。
○3:开发与维护的方法不正确。
5 、消除软件危机的途径
○1:首先应该对计算机软件有一个正确的认识。
○2:使用好的软件开发技术和方法。
○3:使用好的软件开发工具
○4:软件开发团队要有良好的组织,严密的管理,各类人员要互相协同配合,共同完成项目。
6 、软件工程的概念
首先,软件工程是解决软件危机的途径,同时也是指导计算机软件开发和维护的一门工程学科。采用工程的概念、原理、技术和方法来开发与维护软件,把正确的管理技术和正确的技术方法结合起来,高效且经济的按时开发出高质量的软件并有效地维护它。
7 、软件工程基本原理
○1:用分阶段的生命周期计划严格管理
○2:坚持进行阶段评审
○3:实行严格的产品控制
○4:采用现代程序设计技术
○5:结果应能清楚的审查
○6:开发小组的人员应该少而精
○7:承认不断改进软件工程实践的重要性
8 、软件生命周期

9 、常用软件开发模型
○1瀑布模型
概念:瀑布模型一直是唯一被广泛采用的生命周期模型,把一个开发过程分成收集需求,分析,设计,编码,测试,维护六部分。只有完成前面一步才能开始后面一步,上一步的输出的文档就是这一步的输入文档,每一步完成都要交出合格的文档,一步都会有反馈,如果反馈有错误就退回前一步解决问题。
特点:(1)是一种理想化模型,瀑布模型要求有明确的需求分析,所以在现实中基本不可能实现(可在迭代模型中应用瀑布模型) (2)各阶段划分完全固定且是线性的,只有到整个过程的后期才能看到开发成果,由此增加了开发风险 (3)不适应用户需求的变化
○2快速原型模型
概念:快速原型是快速建立起来的可以在计算机上运行的程序,它所完成的功能往往是最终产品能完成功能的一个子集。
特点:(1)快速原型模型是不带反馈环的,软件产品的开发基本上是线性顺序进行的。
(2)原型系统通过与用户的交互得到验证,在设计编码阶段发生错误的可能性小,有助于保证用户的真实需要得到满足。
○3增量模型
概念:把软件产品作为一系列的增量构件来设计、编码、集成和测试。每个构建由多个相互作用的模块构成,并且能够完成特定的功能。
特点:(1)能够在短时间内向用户提交可完成部分工作的产品。
(2)逐步增加产品功能可以使用户有充裕的时间学习和适应新产品。
(3)在把每个新的增量构建集成到现有软件体系中时,必须不破坏原来已经开发出的产品。
○4螺旋模型
概念:为了降低风险,螺旋模型就是在每个阶段之前都增加了风险分析过程的快速原型模型,是风险驱动的。
○5喷泉模型
概念:适用于面向对象的开发,"喷泉”这个词也体现了面向对象软件开发过程迭代和无缝的特性。
○6Rational统一过程(适用于面向对象的开发)
○7敏捷开发与极限编程
10 、需求分析的目标和方法
定义:开发人员准确地理解用户的需求,进行细致的调查分析,将用户非形式的需求陈述转化为完 整的需求定义,再由需求定义转换到相应的需求规格说明的过程。
任务目标:确定对系统的综合要求
分析系统的系统的数据要求
导出数据的逻辑模型
修正开发计划
方法:与用户进行沟通获得需求,也就是访谈。我们只有从实际出发,切切实实地把握用户需求,把握用户需求目标,把握用户将来功能界定,保证我们开发工作正确性方向。
11 、程序流程图(顺序、选择、循环)与数据流图有什么主要区别?
数据流图以图形的方式描绘数据在系统中流动和处理的过程,它只反映系统必须完成的逻辑功能,所以他是一种功能模型,从数据的角度来描述系统,而流程图是从数据加工的角度来描述系统。| 数据流图基本组成部分:数据的源点和终点、数据流、加工、数据文件
数据流图则是描述模块之间的关系。程序流程图重点描述的是模块内数据加工的过程。
12 、E-R图的概念及三要素
概念:E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体、属性和联系的方法,用来描述现实世界的概念模型。 三要素:实体、属性、联系

13 、状态转移图
状态转移图通过描绘系统的状态及引起系统状态转换的事件,来表示系统的行为。
14 、uml用例图



15 、UML
UML统一建模语言,基于面向对象技术的标准建模语言
uml包括三个重要的模型:对象模型、动态模型、功能模型
16 、需求规格说明
为明确软件需求、规划项目、确认进度、组织软件开发并测试而撰写本文档。同时,详细分析项目总体需求,可以作为软件开发工作的基础和依据以及确认测试和验收的依据。
17 、软件设计的目标和过程
目标:获取能够满足软件需求的、明确的、可行的高质量解决方案。
过程: ○1:设想合理的方案
○2:选取合理的方案
○3:推荐最佳方案
○4:功能分解
○5:设计软件结构
○6:设计数据库 ○7:制定测试计划 ○8书写文档 ○9审查和复审
18 、软件设计的原则/原理是什么?
○1模块化:把程序划分成独立命名且可独立访问的模块,每个模块完成一个子功能,把这些模块集成起来构成一个整体。
○2抽象:只考虑事物本质的共同特性,忽略细节和其它因素。通过抽象确定组成软件的过程实体。
○3信息屏蔽:将模块实现自身功能的细节与数据”隐蔽”起来。模块间仅交换系统所需要的必须信息。
○4模块独立:每个模块只完成系统要求的独立的子功能。
19 、面向对象设计方法
面向对象方法:把对象作为由数据及对数据操作所构成的统一体。
优点:与人类的思维习惯一致、稳定性好、可重用性好、可以更好的开发大型软件产品、可维护性好。
20 、程序复杂度的度量
代码行度量法、环路度量法
21 、软件测试的定义
软件测试的经典定义是:在规定的条件下对程序进行操作,以发现程序错误,衡量软件质量,并对其是否能满足设计要求进行评估的过程
22 、软件测试的目的
软件测试的目的就是评估和验证软件产品是否完成需求的过程,发现软件的缺陷,并且确保缺陷能够得到修复。测试的好处包括防止错误、降低开发成本和提高性能。
23 、软件测试的步骤
分析测试需求、制定测试计划、设计测试用例、执行测试(如下)、编写测试报告
单元测试:把每个模块作为一个单独的实体来测试
集成测试:在单元测试的基础上,需要将所有模块按照概要设计说明书和详细设计说明书的要求进行组装测试
系统测试:软件作为计算机系统的一部分,与硬件、网络、外设、支撑软件、数据以及人员结合在一起,在实际或模拟环境下进行测试,发现问题
验收测试:以用户为主的测试,软件开发人员和质量保证人员参加,由用户设计测试用例进行测试。其目的是确保软件准备就绪, 验证软件的功能和性能以及其他特性是否与用户的要求一致
PS:验收测试包括alpha测试和beta测试,alpha测试是指把用户请到开发方的场所来测试,也就是说alpha测试是在受控的环境中进行的。beta测试是由用户在脱离开发环境下进行的软件测试,测试过程由用户自己进行,开发者并不会对测试过程进行指导
24 、黑盒测试
黑盒测试也称功能测试,测试者把程序看作装在一个黑盒子里,只看程序的外部特征,而不关系程序的内部逻辑结构。它只检查程序功能能否按照规格说明书的规定正常使用,程序能否正常的接收输入数据并输出正确的信息,并且保持外部信息(如文件、数据库)的完整性。
优点:比较简单,无需了解内部的代码以及实现
从用户角度出发,很容易发现用户会遇到哪些问题
在做自动化测试时较为方便
基于开发文档,所以也能够知道软件实现了文档中的哪些功能
缺点:不能覆盖到所有的代码,代码覆盖率低
自动化测试的复用性较低
黑盒测试主要采用的技术(测试用例):等价类划分法、边界值法、错误推测法、因果图法。
等价类划分法:把输入域划分成若干部分,每一部分的代表性数据在测试中的作用等价于这一类中的其它值
边界值法:对输入或输出的边界值进行测试,通常作为对等价类划分法的补充
25 、白盒测试
白盒测试也称结构测试,测试者把程序看作装在一个白盒子里,完全知道程序的结构和算法,白盒测试按照程序内部的逻辑测试程序,检测程序中的代码能否按照预期的要求正常工作,通过对内部结构的分析、检测来寻找问题。
优点:可以比较彻底的进行测试,可以测试出一些严重的bug
缺点:不能正确验证规约的正确性,也就是说,白盒测试仅仅侧重于测试内部的处理逻辑,而不去验证逻辑是否满足需求规约。
白盒测试主要采用的技术(测试用例):语句覆盖、判定覆盖、判定-条件覆盖、条件-组合覆盖、路径覆盖等
26 、调试技术
概念:调试是在测试发现错误之后排除错误的过程
为什么要调试:软件错误的外部表现和它的内在原因之间可能没有明显的联系。调试就是把症状和原因联系起来的过程。
调试途径
○1蛮干法:在程序中到处写上输出语句,寻找错误原因的线索
○2回溯法:从发现错误的地方开始,人工沿程序的控制流往回分析代码,找到错误
○3原因排错法:对分查找法、归纳法、演绎法
27 、软件可靠性
概念:程序在给定时间间隔内,按照规格说明书的规定成功地运行的概率
28 、软件维护的概念
在软件已经交付使用之后,为改正错误或满足新的需要而修改软件的过程
29 、软件维护的过程
修改软件的设计、复查、必要的代码修改、单元测试和集成测试、验收测试和复审
30 、软件的可维护性
软件可维护性指的是维护人员对该软件进行维护的难易程度,具体包括理解、改正、改动和改进该软件的难易程度。
决定可维护性的因素:1、系统的大小 2、系统的年龄 3、结构合理性
31 、软件再工程
软件再工程就是将新技术和新工具应用于老的软件的一种较彻底的一种预防性维护,最大限度地重用既存系统的各种资源对旧的软件进行重构。
32 、DevOps (Development和Operations)概念
DevOps(Development和Operations的组合词)是一组过程、方法与系统的统称,用于促进开发、技术运营和质量保障(QA)部门之间的沟通、协作与整合。
33 、数据字典的用途
概念:数据字典是对数据的数据项、数据结构、数据流、数据存储、处理逻辑等进行定义和描述;目的是对数据流程图中的各个元素做出详细的说明。
用途:作为分析阶段的工具;估计由于变更产生的影响;作为数据库开发的基础。
软件工程部分暂时先暂时这么多题目,如果觉得自己有需要的话话/需要完整版的后台T我。
综合面试
这个部分老师会问的比较随机,也很看运气了。问的问题比较广泛,包括所有计算机相关的知识。这边给大家整理好了,背诵即可。综合面试:还会问一下本科项目经历,毕设,科技比赛,未来研究生计划,为什么报考西大,一些框架原理介绍,内容比较宽泛。看仔细自己的毕设和项目,尤其逻辑原理,开发流程。都去准备一下
数据结构
1 、什么是算法的时间复杂度和空间复杂度
算法的时间复杂度是一个函数,用大O符号表示,它定性描述该算法的运行时间,指执行算法所需要的计算工作量,一般情况下,按照基本操作次数最多的语句来计算时间复杂度。 空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度,记做S(n)=O(f(n))。 一个算法的优劣主要也是从算法的时间复杂度和空间复杂度两个方面衡量。
2 、简述数据的逻辑结构和物理结构的概念和两者的关系
○1.逻辑结构:数据元素之间的逻辑关系,即人对数据的理解,而进行抽象的模型 .
○2.物理结构:数据元素在计算机中的存储方法,即计算机对数据的理解,逻辑结构在计算机语言中的映射.
3 、什么是算法,算法的性质有哪些
算法:为解决某个特定任务规定的指令序列
算法有5个基本特性 输入 输出 确定性 有穷性 可行性
4 、快速排序在什么情况下效率最高,在上面情况下效率最差
快速排序在已经有序的情况下效率最差,复杂度为O(n2)
在各个元素乱序的情况下,快速排序相对于其它排序算法来说,效率较高,对快速排序算法速度快慢的影响还取决于基准元素的选取方式,如果每次能均匀划分序列,可以做到效率最高。
5 、有哪些排序方法,有什么区别,优缺点
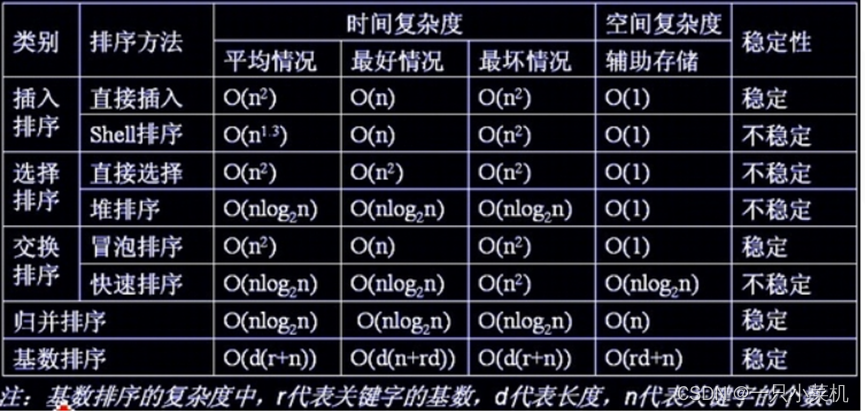
插入排序
优点:稳定,快;
缺点:比较次数不一定,比较次数越少,插入点后的数据移动越多,特别是当数据总量庞大的时候,但用链表可以解决 这个问题。
Shell排序
优点:快,数据移动少;=“”
缺点:不稳定,d=“” 的取值是多少,应取多少个不同的值,都无法确切知道,只能凭经验来取。=“”
选择排序
优点:移动数据的次数已知(n-1 次);
缺点:比较次数多。
推排序
优点:高效率
缺点:堆的维护问题,实际场景中的数据是频繁发生变动的,需要频繁对堆进行维护
冒泡排序
优点:稳定
缺点:慢,每次只能移动两个相邻的数据;
快速排序
优点:快速排序最快的排序算法
缺点:不稳定,不适合对象排序
归并排序
优点:排序速度快,(紧紧次与快速排序)稳定
缺点:需要较大的辅助存储空间
基数排序
它是一种稳定的排序算法,但有一定的局限性:
要求关键字可分解。
6 、有哪几种查找算法,优缺点?
顺序查找
优点:算法简单而且使用面广。表中记录的存储结构没有任何要求,顺序存储和链式存储均可;对表中记录的有序性也没有要求,无论记录是否按关键码有序均可。
缺点:平均查找长度较大,特别是当待查找集合中元素较多时,查找效率较低。
二分查找(折半查找)
优点:比较次数少,查找速度快,平均性能好
缺点: 要求待查表为有序表,且插入删除困难
二叉查找树
优点:二叉排序树是一种比较有用的查找方案,数组的搜索比较方便,可以用下标,但删除或者插入元素就比较麻烦,链表与之相反,删除和插入元素很快,但查找很慢
缺点:顺序存储可能会浪费空间(在非完全二叉树的时候),但是读取某个指定的节点的时候效率比较高O(0) 链式存储相对二叉树比较大的时候浪费空间较少,但是读取某个指定节点的时候效率偏低O(nlogn)
分块查找
优点:适用范围大,顺序存储和链式存储都适用;查找效率高
缺点:需要将待查表分块排序,并且要增加一个存储空间用来存储索引表
哈希查找
优点:可以提供快速的插入操作和查找操作
缺点:哈希表是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,可能会照成大量冲突,性能下降得非常严重
散列函数的构造方法:直接定址法、数字分析法、平方取中法、除留余数法
处理冲突:开放定址法(如线性探测和平方探测)、再散列法、链地址法
7 、图的遍历有哪几种方法
深度优先搜索(DFS)和广度优先搜索(BFS)
综合面试之数据结构部分暂时先暂时这么多题目,如果觉得自己有需要的话话/需要完整版的后台T我。
综合面试之计算机网络
1 、PPP协议(点对点协议)
点对点协议PPP(Point-to-Point Protocol)是目前使用最广泛的面向字节的数据链路层协议,这种链路提供全双工操作,并按照顺序传递数据包。设计目的主要是用来通过拨号或专线方式建立点对点连接发送数据,使其成为各种主机、网桥和路由器之间简单连接的一种共通的解决方案。
优点如下
○1:动态分配IP地址
○2:支持多种网络协议
○3:PPP具有差错检测能力,但不具备纠错能力,所以ppp是不可靠传输协议
○4:无重传的机制,网络开销小,速度快
○5:支持身份验证,更加安全
○6:可以工作在异步方式下
○7:PPP可以用于多种类型的物理介质上,包括串口线、电话线、移动电话和光纤
2 、HDLC协议(高级数据链路控制协议)
HDLC是一种面向比特的网络节点之间同步传输数据的数据链路层协议。优点如下
• 1·对于任何一种比特流都可透明传输。
• 2·较高的数据链路传输效率。
• 3·所有的帧都有帧校验序列(FCS),传输可靠性高。
• 4·用统一的帧格式来实现传输。
3 、VLAN
“vlan是虚拟局域网,是一组逻辑上的设备和用户,可以根据功能、部门及应用等因素将它们组织起来,相互之间的通信就好像它们在同一个网段中一样。由此得名虚拟局域网。”
作用:广播风暴防范、增强局域网的安全性、增加了网络连接的灵活性、性能提高
4 、IP协议
IP协议是一种面向无连接的数据报协议,它是一种不可靠的协议,它不提供任何差错检验。 ip协议的作用能使连接到网上的所有计算机网络实现相互通信的一套规则,规定了计算机在因特网上进行通信时应当遵守的规则。任何厂家生产的计算机系统,只要遵守IP协议就可以与因特网互连互通。
5 、ICMP协议(网际报文控制协议) 和IGMP协议(Internet工作组管理协议)
IP协议是一种面向无连接的数据报协议,它是一种不可靠的协议,它不提供任何差错检验。因此网际报文控制协议(Internet Control Message Protocol)ICMP出现了,ICMP协议用于IP主机、路由器之间传递控制消息,这里的控制消息可以包括很多种:数据报错误信息、网络状况信息、主机状况信息等,虽然这些控制消息虽然并不传输用户数据,但对于用户数据报的有效递交起着重要作用,从TCP/IP的分层结构看ICMP属于网络层,它配合着IP数据报的提交,提高IP数据报递交的可靠性。ICMP是封装在IP数据报中进行发送的,简单的来说,ICMP协议就像奔波于网络中的一名医生,它能及时检测并汇报网络中可能存在的问题,为解决网络错误或拥塞提供了最有效的手段
IGMP即Internet工作组管理协议(Internet Group Management Protocol),IGMP主要用来解决网络上广播时占用带宽的问题
6 、RARP协议(Reverse Address Resolution Protocol反向地址转换协议)
它应用于无盘机,用于实现MAC地址到IP地址的映射。
首先需要介绍一下无盘机的概念。一个网络中的所有主机都不安装硬盘,通过网络服务来启动,这些主机都不保存自己的IP地址,这样的网络叫做无盘网络,这些机器叫做无盘机或者无盘工作站,无盘网络主要为方便管理维护无盘机而存在。
在具有广播能力的网络中设置一个RARP服务器,里边保存着MAC-IP的映射,一台主机启动后获得自己的MAC地址,向网络中广播RARP请求报文,RARP服务器接收到请求报文后查询到该工作站的MAC-IP映射,封装到响应报文中返回给请求者。
7 、OSPF协议(开放式最短路径优先协议)
开放式最短路径优先(Open Shortest Path First,OSPF)是广泛使用的一种动态路由协议,在网络中使用OSPF协议后,大部分路由将由OSPF协议自行计算和生成,无须网络管理员人工配置,当网络拓扑发生变化时,协议可以自动计算、更正路由,极大地方便了网络管理。
8 、RIP协议(路由信息协议)
RIP(Routing Information Protocol,路由信息协议)是使用最久的协议之一。RIP是一种分布式的基于距离向量的路由选择协议,RIP协议是施乐公司20世纪80年代推出的,主要适用于小规模的网络环境。RIP协议主要用于一个AS(自治系统)内的路由信息的传递,每30s发送一次路由信息更新。
9 、TCP协议
传输控制协议(TCP,Transmission Control Protocol)是一种面向连接的、可靠的、基于字节流的传输层通信协议。
10 、UDP协议
用户数据报协议(UDP,User Datagram Protocol)是一种面向非连接的、传输速度快、基于报文的传输层通信协议。
11 、FTP文件传输协议
FTP采用客户/服务器方式,是因特网上使用最广泛的文件传输协议
FTP协议的主要工作过程:在进行文件传输时,FTP的客户端和服务器之间要建立两个并行的TCP连接,分别是控制连接(21端口)和数据连接(主动模式下20端口)。
控制连接在整个会话期间一直保持打开,用于传送FTP相关控制命令,但是控制连接并不用来传输文件。用于传输文件的是数据连接,数据连接在每次传输文件时才建立,传输结束就关闭。
在建立FTP数据连接通道时,又可以分为主动模式和被动模式
主动模式:建立数据连接通道时,FTP服务器主动连接FTP客户
被动模式:建立数据连接通道时,FTP服务器被动等待FTP客户的连接
12 、域名系统DNS
DNS协议通过域名来解析出对应的IP地址,使得人们更方便的访问互联网。
域名解析过程分为递归查询和迭代查询
递归查询:主机—本地—根—顶级—权限 迭代查询:主机–本地—根、顶级、权限
13 、Telnet协议
Telnet协议是TCP/IP协议族中的一员,是Internet远程登录服务的标准协议和主要方式。它为用户提供了在B本地计算机上完成远程主机工作的能力。Telnet是常用的远程控制Web服务器的方法
14 、SMTP协议(simple mail transfer protocol 简单邮件传输协议)
SMTP称为简单邮件传输协议,目的是向用户提供高效、可靠的邮件传输服务。Smtp的一个重要特点是它能够在传送中接力传送文件,也就是说邮件可以通过不同网络上的主机接力式传送。工作在两种情况下:一是电子邮件从客户端传输到服务器。二是从某一个服务器传输到另一个服务器。尽管邮件服务器可以用SMTP发送、接收邮件,但是邮件客户端只能用SMTP发送邮件,接收邮件一般用IMAP(交互邮件访问协议) 或者 POP3(邮局协议3) 。SMTP是一个请求/响应式协议,它监听的端口号为25,用于接收用户的邮件请求,并与远端邮件服务器建立smtp连接。
SMTP通信的三个阶段:连接建立、邮件传送、连接释放。
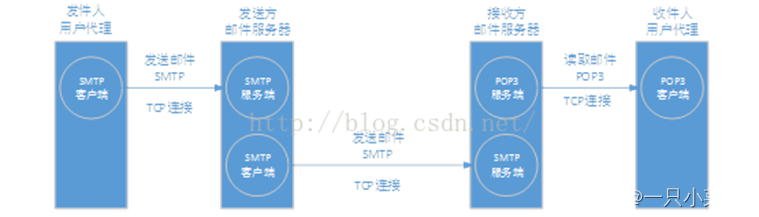
15 、HTTP协议(超文本传输协议)
HTTP是超文本传输协议,是属于应用层的协议。是用于从万维网服务器传输超文本到本地浏览器的传送协议。HTTP是一个基于TCP/IP通信协议来传递数据,它不涉及数据包的传输,主要规定了客户端和服务器之间的通信格式,默认使用80端口。HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
16 、简述信道极限容量(奈奎斯特定理和香农定理)
奈奎斯特定理:又称为奈氏准则,指在理想低通(无噪声,带宽受限)的信道中,为了避免码间串扰,码元极限传输率为2W波特。W为理想低通信道的带宽,单位为HZ。
结论:○1码元的传输速率是有限的
○2信道频带越宽,就可以用更高的速率进行码元的有效传输
○3要提高数据的传输速率,可以使用多元调制的方法
○4奈氏准则给出了码元传输速率的限制,并没有对信息传输速率给出限制
香农定理:在带宽受限且有噪声的信道中,为了不产生误差,信息的传输速率有上限值
结论:○1信道的带宽或信噪比越大,则信息的极限传输速率越高
○2只要确定了带宽和信噪比,信息的传输速率就确定了
○3只要信息的传输速率低于信道的传输速率,就一定能找到某种方法来实现无差错的传输
○4香农定理得出的为极限传输速率,实际信道能够达到的速率比它低
17 、哪些措施可以提高软件的可维护性
1建立明确的软件质量目标和工作
2利用先进的软件开发技术和工具
3使用可维护性的程序设计语言
4按照软件工程的要求,建立完整、准确的开发文档
5所有的程序员遵从一定的编程规范
6在编写程序时增加适当的注释
7程序模块内部做到“高内聚”,模块间做到“低耦合”。
18 、简单说说ARP协议
作用:ARP协议是通过目标IP地址来解析目标主机的MAC地址
工作流程:首先,每个主机都会在自己的 ARP 缓冲区中建立一个 ARP 列表,以表示 IP 地址 和 MAC 地址之间的对应关系。
当源主机要发送数据时,首先检查 ARP 列表中是否有对应 IP 地址的目的主机的 MAC 地址,如果有,则直接发送数据,如果没有,就向本网段的所有主机发送 ARP 数 据包,该数据包包括的内容有:源主机 IP 地址 ,源主机 MAC 地址,目的主机的 IP 地 址。
当本网络的所有主机收到该 ARP 数据包时,首先检查数据包中的 IP 地址是否是自 己的 IP 地址,如果不是,则忽略该数据包,如果是,则首先从数据包中取出源主机 的 IP 和 MAC 地址写入到 ARP 列表中,如果已经存在,则覆盖,然后将自己的 MAC 地址写入 ARP 响应包中,告诉源主机自己是它想要找的 MAC 地址。
源主机收到 ARP 响应包后。将目的主机的 IP 和 MAC 地址写入 ARP 列表,并利用此信息发送数据。 如果源主机一直没有收到 ARP 响应数据包,表示 ARP 查询失败。
19 、说说内聚和耦合
内聚指的是模块内部间聚集、关联的程度。高内聚则是内部模块要做到高度的聚集,做到功能内聚,模块内的各个组成部分都是为了完成某个大的功能而存在。例如JDK中的math类,它就是为了完成数学运算而设计的类。做到高内聚可以提高软件的可靠性、可重用性、可读性。
耦合是指模块间的关联程度。模块之间的耦合度是指模块之间的依赖关系的强弱,模块间的依赖关系越强,则耦合性越强,同时表明其独立性越差。所以我们在设计程序的时候要尽可能做到“低耦合”,因为一旦模块间耦合度过高,软件的维护就会变得非常困难,会引发牵一发而动全身的水波效应。
20 、简述TCP的流量控制和 拥塞控制(慢开始/拥塞避免/快重传/快恢复 算法)
目的:流量控制是为了控制发送端的发送速率,保证接收端能正常的收到分组,否则会触发自动重传机制照成资源的浪费。如果在一开始就把大量的数据注入到网络,可能会引起网络的拥塞,甚至带来网络瘫痪。
解决方案:利用滑动窗口机制可以实现流量的控制。在任意时刻,发送方都维持一组连续的允许发送帧的序号,称为发送窗口。同时接收方也维持着一组连续的允许接收帧的序号,称为接收窗口。发送端每收到一个确认帧,发送窗口就向前移动一个帧的位置,当发送窗口没有可发送的帧时,发送方就停止发送,直到收到接收方的确认帧后才开始继续发送帧。
滑动窗口协议是TCP协议的一种应用,允许发送方一次性发送多个分组,无需向停止等待协议一样发送完一组分组,就停止下来,等待收到确认分组后再进行下一个分组的发送。因此,滑动窗口协议不仅仅起到了流量控制的作用,相比与停等协议,也加速了数据的传输。
综合面试之计算机网络部分暂时先暂时这么多题目,如果觉得自己有需要的话话/需要完整版的后台T我。
综合面试之其它问题(超级重点!一定要好好看看)
-
学过哪些计算机相关课程
数据结构、软件工程、java程序设计、c程序设计、计算机网络、云计算、大数据等 -
软件开发的步骤/流程/生命周期
可以分为3个时期8个阶段
三个时期:软件定义、软件开发、软件运行
8个阶段:问题定义、可行性研究、需求分析、概要设计、详细设计、编码、测试、维护 -
软件测试的方法
软件的基本测试方法主要有静态测试、动态测试、黑盒测试、白盒测试、灰盒测试等等。
在静态测试中, 我们将在不执行代码的情况下检查代码或应用程序。
在动态测试中, 我们将通过执行代码来检查代码/应用程序。
黑盒测试也称功能测试,测试者把程序看作装在一个黑盒子里,只看程序的外部特征,而不关心程序的内部逻辑结构。它只检查程序能否按照规格说明书的规定正常使用,程序能否正常的接收输入数据并输出正确的信息,并且保存外部信息的完整性。(等价类划分法、边界值法、因果图法)
白盒测试也称结构测试,测试者把程序看作装在一个白盒子里,完全知道程序的内部逻辑结构和算法,白盒测试按照程序的内部代码逻辑测试程序,检测程序中的代码能否按预期的要求正常工作,通过对内部结构的分析、检测来寻找问题。(语句覆盖、条件覆盖、路径覆盖)
灰盒测试,是介于白盒测试与黑盒测试之间的一种测试,灰盒测试多用于集成测试阶段,不仅关注输出、输入的正确性,同时也关注程序内部的情况。 -
Java和c的区别
Java是面向对象的,c是面向过程的
Java无指针,c有指针
Java不能直接操作内存,c可以直接操作内存
Java跨平台容易,c不容易跨平台
Java的开源包多,生态也好,有许多优秀的框架。C语言也有但是偏少 -
什么是死锁,遇到怎么解决
死锁是指两个或者两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造
成的一种阻塞现象,若无外力做用,它们将永远无法推进下去。此时称系统是死锁状态。
解决方案:剥夺资源、撤销进程
剥夺资源:从其它进程剥夺足够数量的资源给死锁进程,以解除死锁状态。
撤销进程:可以直接撤销死锁进程或撤销代价最小的进程,直至有足够的资源可用,死锁状态解除为止。 -
软件管理工具有哪些
华为软件开发云、JIRA和禅道 -
介绍下你的项目(期末设计/毕业设计/比赛)
自己根据自己的项目发挥 -
数据库有哪些模型
数据模型按不同的应用层次分成三种类型
概念数据模型:面向用户、面向现实世界的数据模型,描述一个单位的概念化结构
逻辑数据模型:可以通过实体和关系勾勒出企业的数据蓝图
物理数据模型:具有以实物或图画形式直观的表达认识对象的特征 -
Uml都有什么图
类图(参与者什么的)、对象图、活动图、状态图、用例图、时序图、时间图 -
操作系统是干什么的
操作系统是管理计算机硬件与软件资源的计算机程序,同时也是计算机系统的内核与基
石。操作系统也提供一个让用户与系统交互的操作界面,位于底层硬件与用户之间,是两者沟通的桥梁。 -
TCP和UDP有什么不同
TCP面向连接,UDP面向非连接。
TCP面向字节,UDP面向报文。
TCP提供可靠的传输,UDP不提供可靠传输。
TCP传输速率慢,UDP传输速率快。 -
什么是大数据
大数据一般是指海量数据或巨量数据,其规模巨大到无法通过目前主流的计算机系统在合理时间内获取、存储、管理、处理并提炼以帮助使用者决策。
大数据具备如下关键特征,简称4V:
1) 大量化(Volume)。数据量大,包括采集、存贮和计算的量都比较大,起始规模至少是PB、EB或者ZB。
2) 多样化(Variety)。数据来自多种数据源,数据种类和格式多种多样。这为数据处理提出了更高的要求。
3) 快速化(Velocity)。数据增长速度快,处理速度也快,时效性要求高。
4) 价值密度低(Value)。数据呈海量,价值密度低,但通过挖掘产生出的分析数据商业价值大。
从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分,大数据必然
无法用单台计算机进行处理,必须采用分布式架构。它的特色在于对海量数据进行分布式数据挖掘,但它必须依托于云计算的分布式处理、分布式数据库和云存储、虚拟化技术。
- 介绍大数据平台
Hadoop系列(例如hdfs、mapreduce)、spark、以及flume/kafka等集群
Hadoop
Hadoop是一种分布式系统的平台,通过它可以很轻松的搭建一个高效、高质量的分布式系统。、hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框,就是mapreduce。
MapReduce是hadoop的核心组件之一,MapReduce是用来做大规模并行数据处理的数据模型。方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
HDFS定位是提供高容错性、高扩展性、高可靠性的分布式存贮服务。并提供服务访问接口(如API接口、管理员接口等)。
HDFS采用master/slave体系来构建分布式存储服务,提高了HDFS的可扩展性又简化了架构设计。
HDFS的体系架构:主控制服务器(NameNode)、DataNode。
Spark
Spark是一种快速、通用、可扩展的大数据分析引擎,Spark是MapReduce的替代方案,与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG(有向无环图)执行引擎,可以通过基于内存来高效处理数据流。
Flume
Flume是由Cloudera公司开源的一个分布式、可靠和高可用的海量日志采集、聚合和传输的系统。他支持定制各种数据发送方,同时还能对数据做简单处理,并写入各种数据。
Flume的核心是Agent(代理)。,一个独立的进程,包含Source、Channel和sink组件。Agent运行在JVM上。每台机器运行一个Agent,每个Agent可以包含多个Source和sink。各个部件具体功能如下:
1) Source:数据的收集端,负责将数据捕获后进行特殊格式化,将数据封装到Event中,然后将事件发送给Channel。
2) Channel:位于Source和Sink之间,用于缓存进来的Event,当Sink成功的将events发送到下一跳的channel或最终目的,events从Channel移除。Channel 可以是内存、硬盘或者数据库。
3) Sink: 负责将events传输到下一跳或最终目的,成功完成后将events从channel移除。
Kafka
Kafka 是开源领域应用最广泛的分布式基于发布/订阅模式的消息中间系统之一。
整个架构中包括三个角色。
生产者(Producer): 消息和数据生产者
代理者(Broker): 缓存代理,Kafka的核心功能
消费者(Consumer): 消息和数据消费者
Kafka给Producer和Consumer提供注册的接口,数据从Producer发送到Broker,Broker承担一个中间缓存和分发的作用,负责分发注册到系统中的Consumer。
Kafka具有如下特点和优势:
- 同时为发布和订阅提供高吞吐量。
- 可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费; 此外,通过将数据持久化到硬盘以及 replication 防止数据丢失.
- 易于向外扩展。所有的 producer、broker 和 consumer 都会有多个,均为分布式的。无需停机即可扩展机器。
-
大数据处理的一般过程
大数据处理的一般流程包括大数据采集与分发、大数据的预处理与导入、大数据分析与计算、大数据可视化与应用等环节与步骤。具体如下:
1) 大数据采集与分发:从各种异构数据源中收集数据并转换成相应格式,并根据要求分发到不同的数据目的地。
2) 大数据预处理与导入:对采集来的数据进行过滤和清洗处理,以保证数据质量;完成数据过滤清洗之后,把数据导入到分布式存贮集群或者分布式数据库中,或者其他存贮系统中。
3) 大数据分析与计算。基于现有数据进行各种算法的计算分析,既包括基本的数据运算,也包括采用各种数据挖掘算法来发现和创造价值信息。
4) 大数据可视化与应用。通过数据可视化技术辅助更清晰、更容易地理解数据的价值,然后和实际业务结合起来,实现价值落地。
上述过程一般是一个持续迭代、循环的过程,通过不断反馈,从而使数据产生更大的价值。 -
什么是区块链?
区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用
模式。是比特币的一个重要概念,它本质上是一个去中心化的数据库,同时作为比特币的底层技术,是一串使用密码学方法相关联产生的数据库。每一个数据块中包含了一批次比特币网络交易的信息,用于验证其信息的有效性防伪和生成下一个区块。是一套几乎无法伪造或篡改的反式构建而成的数据存储数学架构,可用于存储各类有价值数据。 -
Java开发工具
免费的Eclipse 收费商用的idea、myeclipse -
什么是元宇宙
元宇宙是利用科技手段进行链接与创造的,和现实世界映射与交互的虚拟世界,具备新型社会体系的数字生活空间。
元宇宙主要有以下几项核心技术
一:扩展现实技术,包括AR和VR。
二:数字孪生,能够把现实世界镜像到虚拟世界里面去。
三:用区块链来构建体系。 -
开源软件的优点和缺点
优点:免费、灵活性高,可以根据具体的业务需求来对开源产品做一定的修改、
缺点:具有安全隐患,大家都可以看到代码,可能会用某些漏洞进行攻击。 -
数据库范式
数据库常见的有三大范式,分别是第一范式、第二范式、第三范式。除了常见的三大
范式外,还有BCNF(巴斯-科德范式)、第四范式和第五范式(完美范式)。一般来说,数据库的设计满足三范式就够了。范式只是一种标准,凡是有利也有弊,满足的范式越高,数据间的关系复杂度就越高,对数据的操作就越复杂,数据库的整体性能会下降且维护起来也比较困难。故在对性能有要求的情况下,要适当的做取舍,必要时牺牲范式化的要求,来提高数据库的性能。
第一范式:数据表的所有字段都是不可分割的原子。
第二范式:在满足第一范式的情况下,除了主键外的每一列都要依赖于主键。
第三范式:在满足第二范式的情况下,除了主键以外其它列都不能有传递依赖。 -
开发中数据库要怎么设计,为什么
需求分析阶段:准确了解并分析用户需求。
概念结构设计阶段:通过用户需求进行综合、归纳与抽象,形成一个具体的概念模型。
逻辑结构设计阶段:将概念结构转化为某个DBMS所支持的数据模型
数据库物理设计阶段:为逻辑数据模型选取一个最适合应用环境的物理结构
数据库实施阶段:运用DBMS提供的数据语言、工具及宿主语言,根据逻辑设计和物理设计的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行
综合面试之其它问题(重点)部分暂时先暂时这么多题目,如果觉得自己有需要的话话/需要完整版的后台T我。
重点问题回答模板(这边展示部分)
1.介绍一下自己的本科经历?(回答模板)
我叫XXX,来自XX省XX市,本科毕业于XX大学XX专业。主修课程包括A,B,C,D,E(说5个专业方面的主要科目,比如软件工程,Java编程,数据库,数据挖掘这种,不是计算机出身的就可以不说)。
在学习方面,我的专业成绩排名X%,曾获XXX奖学金XX次
在项目方面,参与开发项目XX项,独立开发XX项
在荣誉方面,荣获优秀共青团员之类的
在专业技能方面,我申请了软件著作权1项,考取了中级软件设计师、程序员资格认证,参与过学校XXX实验室,参加过XXX公司的XXX项目,担任XXX职位,主要负责XXX(这个内容可以简略一点,老师有你的简历,在综合面试中拿比较突出的项目简单一点介绍)
2你印象中最深刻的项目或者遇到的最难的项目?
XXX项目是我遇到的最难/最深刻的项目,它涉及XXX领域,技术栈为XXX,编程语言为XXX,开发环境或者工具为XXX。在其中,解决什么问题的时候比较困难。。。。。。。。我自主学习了XXX内容,通过XXX的方法解决了这个问题。
3谈谈你感兴趣的领域?
这个是开放性问题,你最好结合你的项目回答,最好这个领域是计算机图像、数据可视化、大数据、数据挖掘、人工智能、神经网络方面的
4在XXX项目中开发XXX,你使用了什么工具,采用了什么方法,为什么这样做?
开放性问题,所以最好把自己简历上各个项目好好看一遍,回忆一遍,这个可以临场发挥
5关于你的毕业设计?
我的毕业设计题目是XX,涉及XX领域,编程语言为XX,开发工具为XX,采用了XX模型(软件工程里的那几个模型),主要功能点包括XXX,关键技术在于XXX,目前开发到了什么程度。
需要模板完整版后台T获取完整版复试宝典
人工智能回答模板
下面这一部分是给初试是人工智能的重点准备的。当然复试科目为计算机网络和软件工程的也可以看看。先参考计算机版本中综合面试部分,西大的考纲中说明人工智能方向复试“人工智能”,但个人觉得依旧可以看看计算机版本中的软件工程和计算机网络。人工智能版在此基础上补充一些专业题和综合面试的内容。
复试科目:1308人工智能理论
西大的老师一般研究方向:点云深度学习、基于深度学习的计算机视觉、数据挖掘、生物信息、图像处理、聚类、高可信计算、大数据。基本与人工智能相关,因此要针对性去了解一些项目。没有学过人工智能的
同学,建议拿基于深度学习的图像分类、基于深度学习的数据特征工程作为一个小课题去研究一下。
专业抽题:
没有往年资料借鉴,这些是根据西大的老师特点进行预测。本科没有接触人工智能的同学,现在开始学人工智能,建议通过CSDN和B站视频去了解基础知识,避免发生重大失误。
-
人工智能基础概念:比如什么是张量、什么是学习率、什么是方向传播
CSDN链接:人工智能基础知识_李玉坤的博客-CSDN博客_人工智能基础 -
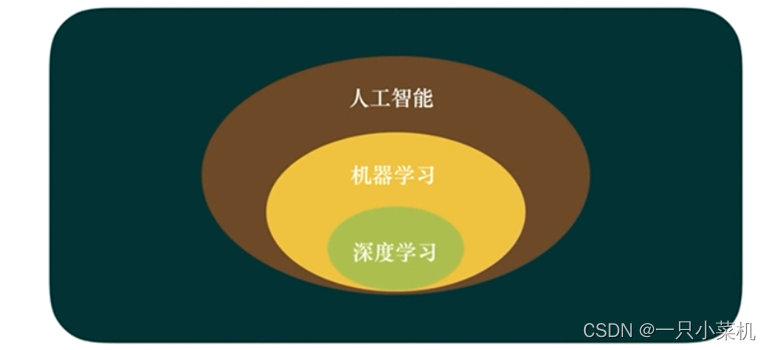
简要描述人工智能、机器学习、深度学习这几者区别和联系:
机器学习是实现人工智能的一种方法,深度学习是机器学习一个分支
-
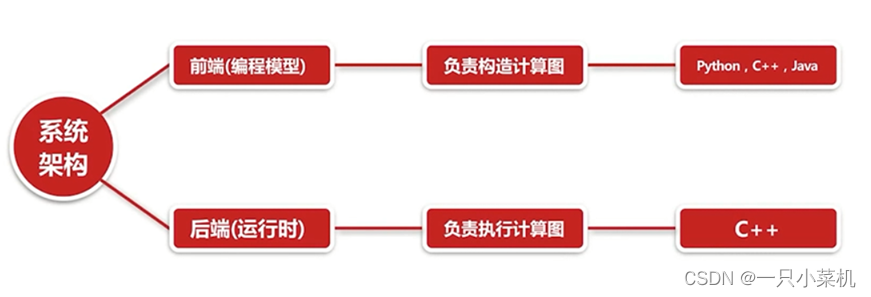
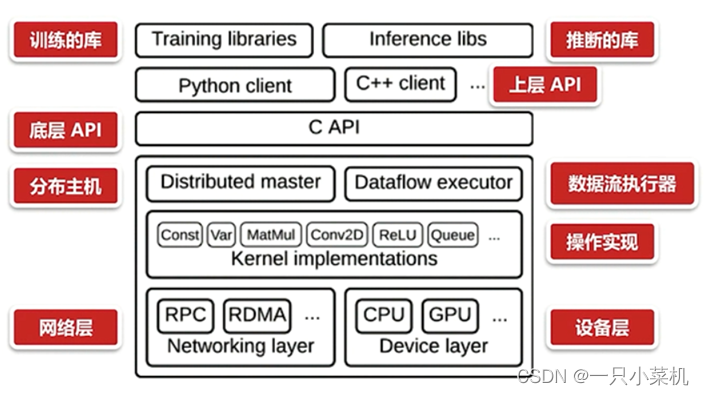
简要描述TensorFlow架构
TensorFlow是:Google开源的基于数据流图的科学计算库,适合用于机器学习
-
简要描述一下深度卷积神经网络CNN
一般回答的套路是:CNN是由网络结构、激活函数以及参数学习算法组成的神经网络,主要用于图像处理、自然语言处理、视频处理等领域,CNN可以有效的降低反馈神经网络(传统神经网络)的复杂性,常见的CNN结构有LeNet-5、VGGNet、GoogleNet等…(是什么+组成成分+优点缺点+用途)
深度学习之卷积神经网络(Convolutional Neural Networks, CNN)_fenglepeng的博客-CSDN博客
自行学习以下概念和作用
• 数据输入层:Input Layer
• 卷积计算层:CONV Layer
• ReLU激励层:ReLU Incentive Layer
• 池化层:Pooling Layer
• 全连接层:FC Layer
5.目标检测可以分为两大类,分别是什么,他们的优缺点是什么呢?
目标检测算法分为单阶段和双阶段两大类。
单阶段目标验测算法(one-stage),代表算法有 yolo 系列,SSD 系列;直接对图像进行计算生成检测结果,检测速度快,但检测精度低。
双阶段目标验测算法(two-stage),代表算法 RCNN 系列;先对图像提取候选框,然后基于候选区域做二次修正得到检测点结果,检测精度较高,但检测速度较慢。
【单阶段偏应用,因为在精度没有差很多的情况下,速度很快,就会选择单阶段目标检测算法;双阶段偏比赛,只注重精度高低,速度不考虑】
6.深度学习框架TensorFlow中都有哪些优化方法?
答:GradientDescentOptimizer
AdagradOptimizer
Optimizer
优化最小代价函数
- 深度学习框架TensorFlow中常见的激活函数都有哪些?
答:relu,sigmoid,tanh
8.深度学习框架TensorFlow中有哪四种常用交叉熵?
答: tf.nn.weighted_cross_entropy_with_logits
tf.nn.sigmoid_cross_entropy_with_logits
tf.nn.softmax_cross_entropy_with_logits
tf.nn.sparse_softmax_cross_entropy_with_logits
9.什么叫过拟合,产生过拟合的原因?避免过拟合方法?
答:过拟合简单说,就是在机器学习中,模型训练效果好,但对新的测试数据预测很差。
产生过拟合原因:
• 数据有噪声
• 训练数据不足,有限的训练数据
• 训练模型过度导致模型非常复杂
避免过拟合方法(常见):
• early stopping,在发生拟合之前提前结束训练。
• 数据集扩增,最大的满足全样本。
• 正则化,引入范数概念,增强模型泛化能力。
• droput,每次训练时丢弃一些节点,增强泛化能力
• batch normalization
• 减小模型复杂度
10.朴素贝叶斯方法的优势是什么?
朴素贝叶斯有稳定的分类效率,对于小规模的数据表现很好,能处理多分类问题,可以再数据超出内存时,去增量训练。对缺失数据不太敏感,算法比较简单,常用于文本分类。
11.什么是监督学习的标准方法?
所有的回归算法和分类算法都属于监督学习。并且明确的给给出初始值,在训练集中有特征和标签,并且通过训练获得一个模型,在面对只有特征而没有标签的数据时,能进行预测。
监督学习和非监督学习?
监督学习:通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如 分类。
非监督学习:直接对输入数据集进行建模,例如聚类。
半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。
目前最广泛被使用的分类器有人工神经网络、支持向量机、最近邻居法、高斯混合模型、朴素贝叶斯方法、决策树和径向基函数分类。
无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
12.在机器学习中,模型的选择是指什么?
根据一组不同复杂度的模型表现,从某个模型中挑选最好的模型。选择一个最好模型后,在新的数据上来评价其预测误差等评价和指标。
13.谈谈判别式模型和生成式模型?
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场。通过决策函数来进行判别。
常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机。通过联合概率密度分布函数来进行预测。
13.什么是聚类,聚类的应用场景?
聚类是指根据一定的准则,把一份事物按照这个准则归纳成互不重合的几份,机器学习中,聚类指按照一个标准,这个标准通常是相似性,把样本分成几份,是得相似程度高的聚在一起,相似程度低的互相分开。
聚类的应用场景,求职信息完善(有大约10万份优质简历,其中部分简历包含完整的字段,部分简历在学历,公司规模,薪水,等字段有些置空顶。希望对数据进行学习,编码与测试,挖掘出职位路径的走向与规律,形成算法模型,在对数据中置空的信息进行预测。)
15.机器学习中,为何要经常对数据做归一化?
归一化后加快的梯度下降对最优解的速度。
归一化有可能提高精度。
16.归一化的好处
• 归一化加快了梯度下降求解最优解的速度
• 归一化还可能会提高精度。
17.归一化的种类
• 线性归一化。利用max和min进行归一化,如果max和min不稳定,则常用经验值来替代max和min。
• 标准差归一化。利用所有样本的均值和方差将样本归一化为正态分布。
• 非线性归一化。比如指数、对数、三角函数等。
18.归一化和标准化的区别
标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下。归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。
对于深度网络而言,归一化的目的是方便比较,可以加快网络的收敛速度;标准化是将数据利用z-score(均值、方差)的方法转化为符合特定分布的数据,方便进行下一步处理,不为比较。
19.熵
熵是指样本的随机程度。样本越无序,熵越大, 信息越多。
20.SGD 中 S(stochastic)代表什么
Stochastic Gradient Descent 随机梯度下降。GD即Full-Batch,SGD即为Mini-Batch。随机性表现在训练数据的shuffle。
21.引入非线性激活函数的原因?
(1)指数函数运算量大。ReLU节省运算量。(计算量小)
(2)Sigmoid容易引发梯度消失问题,因为Sigmoid函数在两端的导数趋近于0.(解决梯度消失问题)
(3)ReLU使得一部分神经元死亡,这样可以使得网络变得比较稀疏,缓解了过拟合的发生。(避免过拟合)
22.若使用线性激活函数,则无论神经网络有多少层,输出都是输入的线性组合。
好的激活函数有以下特点:
非线性:即导数不是常数。
几乎处处可微:可微性保证了在优化中梯度的可计算性。
计算简单。
非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。
单调性(monotonic):即导数符号不变。
输出范围有限:有限的输出范围使得网络对于一些比较大的输入也会比较稳定
接近恒等变换(identity):即约等于x。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加
参数少:大部分激活函数都是没有参数的。
归一化(normalization):这个是最近才出来的概念,对应的激活函数是SELU。类似于Batch Normalization
23、什么造成了梯度消失和梯度膨胀?
深度网络的链式连乘法则,使得反向传播时到达前几层时,权值更新值非常小或非常大。可以通过ReLU解决一部分。
综合面试:大致问题参考计算机版本
6. 使用“针对这个问题、基于该问题”“第一、第二、第三”“首先、其次、然后、最后”,这种逻辑性字眼,表现条理性。
7. 一定准备有人工智能或深度学习项目的简历:区别于电子信息-计算机技术,人工智能综合面试老师会随机提问一些关于人工智能的问题,这种比较难以预测。建议一定准备个人简历,在里面项目经历那里写上一些人工智能的项目,最简单的是人脸识别、图像分类,把基础的神经网络、特征函数搞清楚即可,便于老师发问,引导老师问你问题。这个项目以简单为主,不要太高大上,否则会露馅。
8. 没学过人工智能的,最保险方法是看博客和视频,自行搜索,可以参考本文档的内容一点点去学习,最好下载一个人脸识别或者图像处理的项目代码(python语言、PyCharm编辑器、TensorFlow框架)自己试着搭建环境运行一下。避免老师一问你,就露馅。
9. 没有项目的,现在可以购买软件著作权,自己申请要2个月来不及了,淘宝上有几百块代理的。
10. 自信+冷静+逻辑性回答+不要使用偏激字眼,注意礼貌,一般每人15-20分钟,回答过长,老师叫你停止回答就立马停止。
最后要注意的
切记放轻松,不要太紧张,也不要狂妄,尤其不要不懂装懂,这是原则问题
你不懂可以委婉地表达自己的理解,比如我认为这个技术属于什么领域,应用于什么场景,但是没有具体了解
希望以后有机会深入了解,表达出你是个可塑之才,但是你强行不懂装懂,说大谎,这就是原则问题
最后大家记住自信+冷静+逻辑性回答+不要使用偏激字眼,注意礼貌。
希望大家可以成功上岸,加油!
注意 以上为试看参考版本的复试宝典,若有需要完整版资料可联系我。
真题资料

注意 所有提供的资料都仅供参考 大家切记还是要多多锻炼自己 不要想着走捷径