进化计算(Evolutionary computation (EC) )是一种从自然进化和群体智能行为(swarm intelligence behaviors)中汲取灵感的元启发式算法。
目前,EC以其解决优化问题的有效性和高效性得到了迅速的发展,EC算法主要有两个分支:
1、进化算法(EA)
差分进化(differential evolution (DE))
遗传算法(genetic algorithm)
2、群体智能(swarm intelligence)
粒子群优化particle swarm optimization (PSO)
蚁群算法(ant colony optimization)
在EC算法的进化过程中,会产生大量数据,这些数据可以显式或隐式地揭示个体的进化行为。例如,在DE的进化过程中,成功的微分向量揭示了每个个体的成功行为。在粒子群中,成功的速度可以引导粒子接近全局最优。
Data(数据)通常表示揭示种群在进化过程中的进化行为的信息。例如,位置信息、方向信息、适应度信息都是数据。
A successful experience(成功的经验)是在一个位置成功进化的方向。例如,假设一个个体位于位置P1,适应度值为F1,跳到位置P2,适应度值为F2。如果F2优于F1,即该个体进化成功,则将位置P1与成功方向D = P2 - P1配对为一次成功经验,记为(P1, D)。
knowledge(知识)知识定义为一种如何从成功经验中挖掘出成功进化方向的规则。因此,成功经验是进化计算EC过程中产生的一种特殊数据,可以用来挖掘知识,从而指导EC算法的进化。
本文分为两步:
1、“learning from experiences to obtain knowledge(从经验中获取知识)” :首先,在从经验中学习获取知识的过程中,KL框架维护一个基于前馈神经网络(FNN)的知识库模型(KLM)来保存知识。在进化过程中,KLM收集所有个体获得的成功经验,并对这些经验进行挖掘和学习,以获得关于个体与成功经验之间关系的一般知识。
2、“utilizing knowledge to guide evolution(利用知识来指代进化)”:其次,在利用知识引导进化的过程中,个体可以向KLM(知识库模型)查询指导信息,KLM根据学习到的知识和个体所处的位置,给每个个体一个合适的进化方向。
建议的KL框架的特点和贡献总结如下:
1) 本文提出了一个新颖而有效的KL框架。KL框架可以深入挖掘进化过程中产生的成功经验以获得知识,并可以根据个体的位置正确利用知识来指导个体。首先,由于知识是通过挖掘大量的成功经验获得的,因此KL模型中的知识在指导进化方面更为普遍和有效。其次,KL框架可以为每个个体提供相对有效的进化方向指导,因为所提供的方向是根据知识和个体的当前状态计算出来的。
2)KL框架是一个通用的EC算法框架,可以很容易地与许多EC算法嵌入。为了清楚地表明如何将KL框架和EC算法结合起来,我们将KL框架与两种有代表性的EC算法DE和PSO结合起来,提出了基于KL的DE(表示为KLDE)和基于KL的PSO(表示为KLPSO)。根据实验结果,这两种基于KL的EC算法比它们的经典版本更加有效和高效。
3) 为了进一步评估KL框架的效果,我们将KL框架与几个最先进的甚至是冠军的EC算法相结合,并展示了基于KL的算法与原始算法相比的性能改进。在基准函数和现实世界的优化问题上的实验结果表明,我们提出的KL框架可以显著提高这些EC算法的性能。
基于知识的进化计算(KLEC)
A、知识学习(KL)的架构
B、从经验中学习来获取知识
1、知识库模型KLM(knowledge library model)
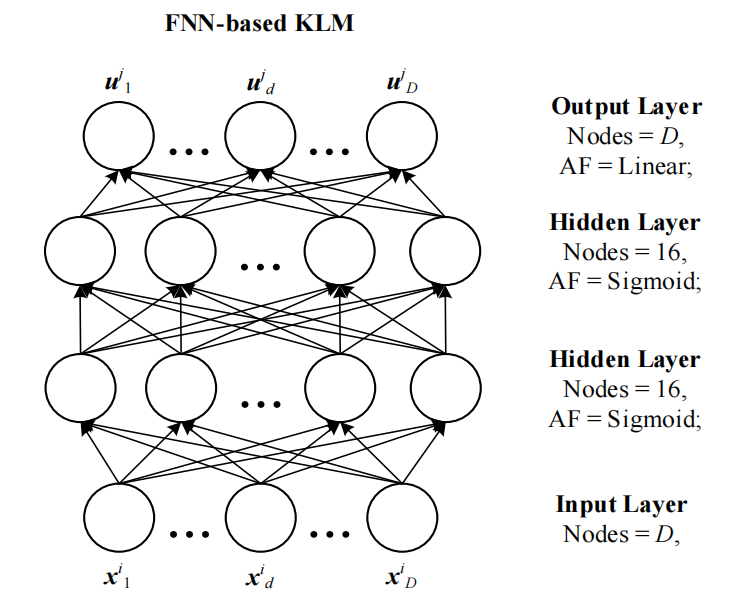
KLM 应该是可以储存大量知识、快速检索到知识。本文使用的KLM是一个FNN模型,训练是一对数据,(个体的“位置”,该“位置”对应的“成功方向”)
2、从经验中学习来更新知识库模型
在KL框架中,在从经验中学习更新KLM的过程之前,应该首先收集成功的经验。为了收集成功的经验,我们创建了一个列表Q来存储成功的经验。具体来说,在每一代中(generation),一旦某个个体的适应度得到提高,这个成功的经验就会被收集到Q中。在收集完这一代中所有的成功经验之前,这个经验不会立即被KLM学习。也就是说,该经验被暂时储存在经验列表Q中,等待被KLM学习。
然后,收集在Q中的成功经验被KLM学习,以获得关于位置和成功方向之间关系的知识。具体来说,列表Q中每个经验的位置作为输入输入给KLM,相应的方向作为预期输出来训练基于FNN的KLM。在训练过程中,采用反向传播算法来调整KLM的权重。在KLM的学习过程中,列表Q中的所有经验都被丢弃(即在每一代结束时清除列表Q中的所有经验),以便为下一代的新经验留出空间。需要注意的是,在每一代中,KLM并没有被重新初始化,而是根据KLM在上一代中的权重,由这一代中新收集的经验不断进行训练。因此,KLM实际上可以通过学习整个历史中产生的成功经验来获得知识。如果在Q中没有收集到成功的经验,即没有个体实现成功的进化,那么KLM将不会在当前一代中被更新。
C、利用知识来指导进化

利用知识指导进化的过程旨在根据个体的当前位置和学到的知识为其提供适当的进化方向。由于KLM根据历史上的成功经验学会了从位置到方向的映射,我们只需要把个体的当前位置作为输入给KLM,KLM的输出就是这个个体的进化方向的查询。这样,KLM的利用操作就可以根据每个个体的当前位置为其提供一个合适的进化方向。此外,为了清晰起见,我们给出了图4,以更好地说明成功经验和KLEC知识之间的关系,同时也更好地说明KLEC的知识学习和利用过程。
D、KLDE(知识学习的差分进化)
将KL与DE做了一个实例给大家看怎么结合到一起的:

读者有话说:
感觉整个文章读起来没有什么营养,没有搞懂到底这个怎么利用知识的,代码也没有...