点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:AI Around
本文将为大家介绍CVPR 2023年最佳论文两篇中的Visual Programming: Compositional visual reasoning without training (视觉编程:无需训练的组合式视觉推理),代码已开源。

Title:
Visual Programming: Compositional visual reasoning without training
Paper:
https://openaccess.thecvf.com/content/CVPR2023/html/Gupta_Visual_Programming_Compositional_Visual_Reasoning_Without_Training_CVPR_2023_paper.html
Code:
https://github.com/allenai/visprog
01
/导读/
VISPROG是一种神经符号方法,可利用自然语言指令解决复杂的组合式视觉任务。VISPROG避免了任何特定于任务的训练需求。相反,它利用大型语言模型的上下文学习能力生成类似Python的可组合程序,这些程序将被执行以获得解决方案和全面可解释的推理结果。生成的程序的每一行可以调用多个现成的计算机视觉模型、图像处理子程序或Python函数以生成中间输出,后续程序部分可以使用这些中间输出。在四项不同的任务中展示了VISPROG的灵活性:组合式视觉问答、基于图像对的零样本推理、实际知识对象标注和语言引导图像编辑。类似VISPROG这样的神经符号方法是扩展人工智能系统范围、为人们提供执行复杂任务的有效途径。

VISPROG是一种可组合和可解释的神经符号系统,用于进行组合式视觉推理。给定自然语言指令和高层次程序的几个示例,VISPROG利用GPT-3的上下文学习功能针对任何新指令生成程序,并在输入的图像上执行程序以获取预测结果。VISPROG还将中间输出总结为可以解释的视觉说明。
02
/模块/
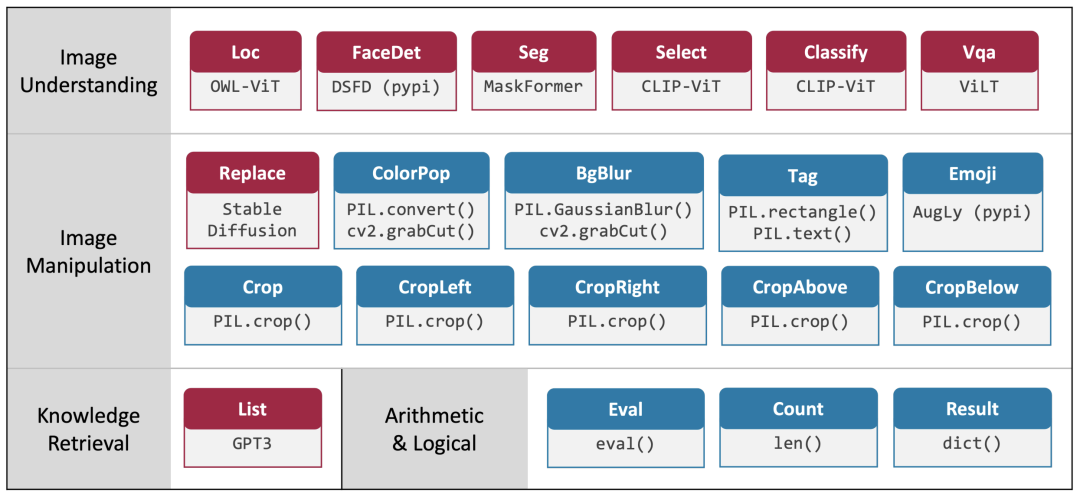
VisProg目前支持20个模块,可实现图像理解、图像操作(包括生成)、知识检索和算术和逻辑操作等能力。在这里显示的红色模块是使用经过训练的最先进神经模型实现的,而蓝色模块是使用多种Python库(如PIL、OpenCV和AugLy)实现的非神经Python函数。
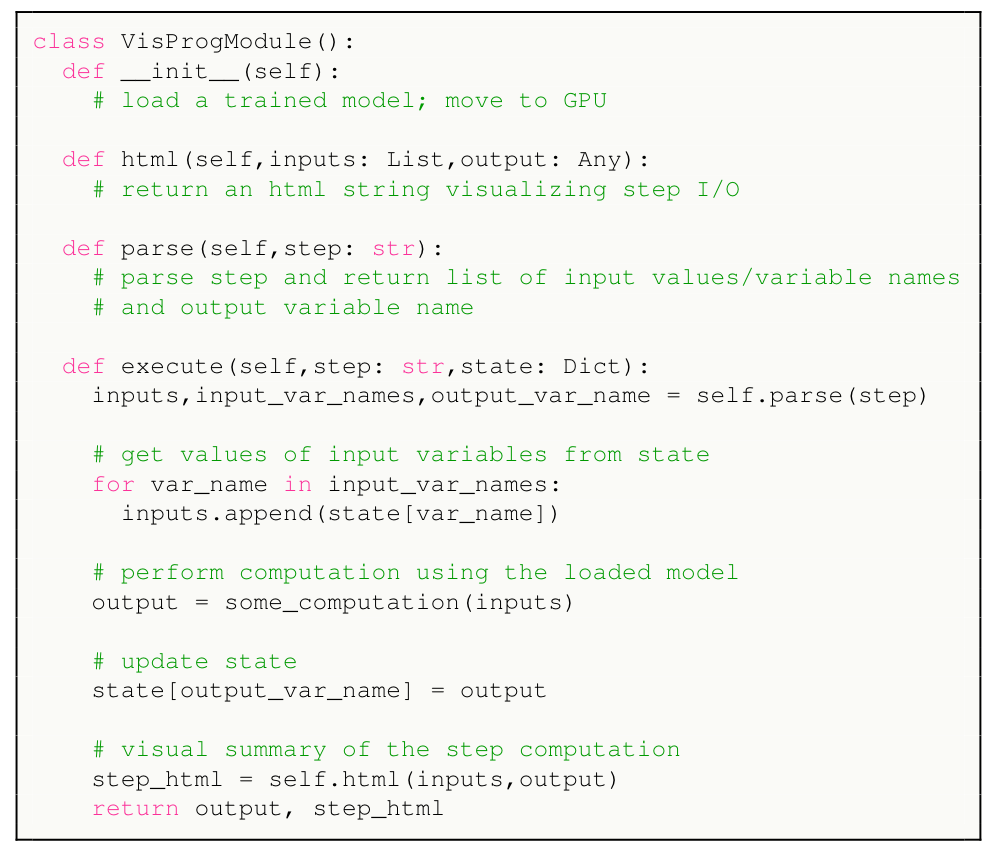
在VISPROG中,每个模块都被实现为一个Python类,见下述代码,其具有以下方法:
(i)解析行以提取输入参数的名称和值以及输出变量的名称;
(ii)执行必要的计算,可能涉及训练过的神经模型,并更新程序状态以获得输出变量的名称和值;
(iii)使用HTML方式以可视方式总结该步骤的计算(用于创建visual rationales)。
要向VISPROG添加新模块,只需要实现并注册一个模块类,程序的执行使用该模块将由VISPROG解释器自动处理。
03
/VISPROG中的程序生成/
VisProg通过向LLM GPT-3提供指令及其相关的示例指令和对应程序,来生成程序。与以前的方法如神经模块网络(Neural Module Network)不同,VisProg利用大规模语言模型的上下文学习能力来生成程序,而不是使用预先定义的模块。这使生成的程序更加灵活且能够处理更多的组合式视觉任务。

04
/可解释性/
VisProg不仅生成高度可解释的程序,还通过将每个步骤的输入和输出的摘要拼接在一起生成visual rationales,以帮助理解和调试程序执行期间的信息流。下面是两个visual rationales的示例。
使用自然语言进行图像编辑

关于图像对的推理(自然语言视觉推理)

04
/结果可视化/
在组合式视觉问答、基于零样本的图像对推理(仅使用单张图像VQA模型)、实际知识对象标记和语言引导的图像编辑等复杂视觉任务上展示了VisProg。下图展示了VisProg在对象标记和图像编辑任务上的能力。

更多关于所有任务的定性结果以及相应的视觉说明,包括由于程序生成中的逻辑错误或模块预测错误而导致的失败案例,请根据下面链接下载查阅:https://openaccess.thecvf.com/content/CVPR2023/supplemental/Gupta_Visual_Programming_Compositional_CVPR_2023_supplemental.zip
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()