1、题目
某年各省级行政区环境污染状况的统计数据(已经过标准化处理),包括生活污水排放量(x),生活二氧化硫排放量(x2),生活烟尘排放量(x3),工业固体废物排放量(x4),工业废气排放总量(x5),工业废水排放量(x6),GDP水平(gdp)以及地理位置(geo)等。
现采用K均值聚类方法,编写Python程序将省级行政区分成4类。
2、课本参考答案
(1)函数见第一题
(2)运用
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#请注意原始数据文件的编码方式及分隔符
origData = pd.read_csv("环境污染数据.txt",encoding='ANSI',sep='\t')
print(origData.head())
#KMean可以支持高维数据聚类,但是本章节用于绘制图形的函数showCluster()只支持2维图像
#故使用PCA将本案例的数据将为2维聚类。读者可以自行尝试不降维聚类。
X = origData.drop(['province'],axis=1)
from sklearn import preprocessing
X_scaled = preprocessing.scale(X)
print('规格化转换后数据:')
print(X_scaled_frame.head())
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
X_pca = pca.fit_transform(X_scaled)
X_pca_frame = pd.DataFrame(X_pca,columns=['pca_1','pca_2'])
print(X_pca_frame.head())
k=3
print("K均值聚类:")
case_cen, case_clusterAssment = kmeans(X_pca, k)
showCluster(X_pca, k, case_cen, case_clusterAssment)
#将case_clusterAssment中的聚类结果写回原始DataFrame
origData['聚类结果']=clusterAssment[:,0]
print('聚类结果:')
print(origData)3、结果
province x1 x2 x3 x4 x5 x6 gdp geo
0 北京 21.76 15.01 12.23 0.02 10.69 3.09 2 1
1 天津 7.47 4.19 4.80 0.00 11.44 7.68 3 1
2 河北 21.92 43.49 69.43 9.40 100.00 45.79 2 1
3 山西 13.79 58.94 93.45 100.00 44.60 15.04 3 1
4 内蒙古 7.44 37.97 69.87 2.16 37.87 9.02 3 1
规格化转换后数据:
atr1 atr2 atr3
0 -1.424569 -1.738999 -0.434801
1 -1.281035 -1.738999 1.195704
2 -1.352802 -1.700830 -1.715913
3 -1.137502 -1.700830 1.040418
4 -0.563369 -1.662660 -0.395980
pca_1 pca_2
0 -0.291071 -0.549709
1 -1.182082 -0.543312
2 3.303118 1.699791
3 1.594474 4.899828
4 0.403719 1.813386
K均值聚类:
KMN聚类完成!
聚类结果:
province x1 x2 x3 x4 x5 x6 gdp geo 聚类结果
0 北京 21.76 15.01 12.23 0.02 10.69 3.09 2 1 3.0
1 天津 7.47 4.19 4.80 0.00 11.44 7.68 3 1 0.0
2 河北 21.92 43.49 69.43 9.40 100.00 45.79 2 1 1.0
3 山西 13.79 58.94 93.45 100.00 44.60 15.04 3 1 3.0
4 内蒙古 7.44 37.97 69.87 2.16 37.87 9.02 3 1 3.0
5 辽宁 27.90 36.64 100.00 1.08 49.84 35.21 2 2 1.0
6 吉林 12.60 13.47 41.05 0.32 11.90 14.49 3 2 3.0
7 黑龙江 15.41 16.34 43.23 0.01 15.14 14.01 3 2 3.0
8 上海 39.94 29.14 28.82 0.04 19.94 17.44 2 3 3.0
9 江苏 53.01 12.58 13.10 0.06 49.08 100.00 1 3 1.0
10 浙江 30.40 4.64 4.37 0.35 36.35 74.79 1 3 1.0
11 安徽 22.46 11.92 22.71 0.00 27.57 27.14 3 3 1.0
12 福建 19.93 3.97 15.72 0.67 19.03 50.60 2 3 3.0
13 江西 15.24 14.79 10.04 1.99 12.68 26.34 3 3 3.0
14 山东 37.37 52.54 53.28 0.02 65.24 61.86 1 3 3.0
15 河南 36.11 33.77 33.19 0.54 39.31 49.83 2 4 3.0
16 湖北 34.63 22.74 16.16 1.93 21.57 33.65 2 4 2.0
17 湖南 33.81 36.20 30.57 7.68 18.22 37.05 2 4 2.0
18 广东 100.00 5.74 9.17 2.78 35.25 91.63 1 4 1.0
19 广西 30.16 10.38 5.24 2.50 26.47 68.35 3 4 1.0
20 海南 6.04 0.00 0.44 0.03 2.29 1.91 4 4 2.0
21 重庆 14.20 31.35 35.81 33.34 15.83 25.44 3 5 3.0
22 四川 30.72 34.22 56.33 49.37 47.80 42.49 2 5 0.0
23 贵州 9.17 100.00 45.41 19.76 21.54 4.20 4 5 3.0
24 云南 10.39 19.21 24.89 19.95 16.80 12.88 3 5 1.0
25 西藏 0.00 0.00 0.00 0.95 0.00 0.00 4 5 3.0
26 陕西 10.94 17.88 28.38 10.20 13.44 17.79 3 6 3.0
27 甘肃 5.88 18.98 18.78 5.99 12.09 5.60 4 6 3.0
28 青海 2.30 1.77 10.92 0.20 5.16 2.41 4 6 3.0
29 宁夏 3.09 6.40 6.99 1.15 8.26 7.55 4 6 3.0
30 新疆 10.22 23.40 36.68 16.42 12.04 7.50 4 6 3.0
3、非答案
print("step1:读入数据:")
dataSetKNN=[]
fileIn = open('环境污染数据.txt',encoding='gbk')
# fileIn=open('population.txt')
for line in fileIn.readlines(): #按行逐行读取数据
lineArr=line.strip().split('\t') #对于每行数据,以空格分隔开,并删除分割开后的数据中的前后空白
dataSetKNN.append(lineArr[:])
# # dataSetKNN.append([float(lineArr[0]),float(lineArr[1])])
dataSetKNN = [[s.strip() for s in inner] for inner in dataSetKNN]
# print(result)
dataSetKNNSize=len(dataSetKNN) #获取数据样本数量
dataSetKNN1=np.mat(dataSetKNN) #将列表数据转换为数组数据
df = pd.DataFrame(dataSetKNN1)
print(dataSetKNN1[:1])
df2 = df.iloc[1:33]
index_low = df2.iloc[:,0]
# print(index_low)
index_columns = ['province','x1','x2','x3','x4','x5','x6','gdp','geo']
df3 = pd.DataFrame(df2.values,columns = index_columns)
# 规格化
from sklearn import preprocessing
df_scaled = preprocessing.scale(df3[['x1','x2','x3','x4','x5','x6','gdp','geo']])
df_scaled_frame = pd.DataFrame(df_scaled,columns=['x1','x2','x3','x4','x5','x6','gdp','geo'])
df_scaled_frame.insert(0, 'province', df3['province'].values)
# 数据降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
df_pca = pca.fit_transform(df_scaled)
df_pca_frame = pd.DataFrame(df_pca,columns=['pca_1','pca_2'])
df_pca_frame.insert(0, 'province', df3['province'].values)
print(df_pca_frame.head())
# 二维图
print('绘制二维图')
fig_2d = plt.figure()
ax2d = fig_2d.add_subplot(111)
ax2d.plot(df_pca_frame['pca_1'],df_pca_frame['pca_2'],'bo')
fig_2d.savefig('二维图.png',dpi = 300,bbox_inches = 'tight')
fig_2d.show()
# 二维平面显示聚类结果
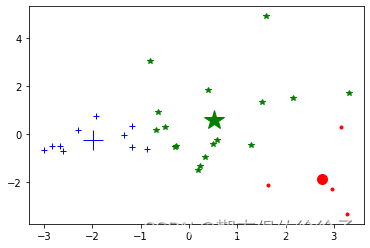
def showCluster(dataSet,k,centroids,clusterAssment):
fig_2d_clustered=plt.figure()
ax2d_clustered=fig_2d_clustered.add_subplot(111)
numSamples,dim=dataSet.shape
if dim!=2:
print("只能绘制二维图形:")
return 1
mark=['.r','+b','*g','k','^r','vr','sr','dr','<r','pr']
if k>len(mark):
print("K值过大!")
return 1
for i in range(numSamples):
markIndex=int(clusterAssment[i,0])
ax2d_clustered.plot(dataSet[i,0],dataSet[i,1],mark[markIndex])
for i in range(k):
ax2d_clustered.plot(centroids[i,0],centroids[i,1],mark[i],markersize=20)
fig_2d_clustered.savefig('11.3题聚类图.png',dpi=300,bbox_inches='tight')
fig_2d_clustered.show()
# K取值4
print("step2.1:聚类")
k=4
centroids,clusterAssment=kmeans(df_pca,k)
print("聚类图:见''11.3题聚类图.png'")
showCluster(df_pca,k,centroids,clusterAssment)