目录
方法一:通过xlwings的设置,去掉DataFrame的列和索引

1、背景描述:
基本需求,当前有一个复杂的Excel模板,需要把经过Python处理后的数据写入Excel模板文件。
1、为什么不直接全部通过Python完成全部数据,直接输出?
Excel模板比较复杂,其中很多格式设定,很难直接通过python直接还原;
例如,下面这种表头的模板,里面设定了一些内容,不太方便通过python直接生成,生成的数据直接写到下面。

2、为什么选择xlwings库处理Excel?
Excel数据模板是经过DGS终端进行加密的,目前测试好像只有使用win32com和xlwings这两个库才可以读取和写入,其他库好像不行;(至于为什么要用DGS进行加密……这个一言难尽……)
3、为了简化说明,让大家能够更清晰的理解这个事情,下面是用的数据和模板只是简单的代用数据,实际处理的数据和模板复杂程度远超样例;
2、问题描述:
根据xlwings的使用方法,将DataFrame数据写入excel是很简单的事情,基本是以下这种方式的几行代码:
import pandas as pd
df = pd.DataFrame([[1,2], [3,4]], columns=['a', 'b'])
sheet.range('A1').value = df此时的df是最简单的一个举例,显示的如下的效果

实际写入到excel文件后的效果是这样的:

刚才说了,实际数据是要写入到一个excel的模板中,在这个模板中已经有列名称和索引的序号内容,不要再次写入这部分内容。

3、解决方案:
为了在写入数据的时候不附带写入列和索引,尝试过几种方法,比如切片,重置索引等……
当然,也可能是还有更好的方法,只是还不知道……也尝试去百度查找解决方案,但是好像类似的需要不多,没看见有现成的解决方案,于是只能到官方文档里面去找:
方法一:通过xlwings的设置,去掉DataFrame的列和索引
sheet.range('A1').options(index=False, header=False).value = df
# 其中,index=False, 代表去掉索引数据;
# header=False, 代表去掉列明# 其中,index=False, 代表去掉索引数据;# header=False, 代表去掉列明
方法二:通过把DataFrame数据变为NumPy数组
sheet.range('A1').value = df.to_numpy()
# 通过to_numpy()把DataFrame的正文数据变为numpy数组通过to_numpy()把DataFrame的正文数据变为numpy数组,不包含列明和索引的数据。
以下是官方文档中的说明信息:
pandas.DataFrame.to_numpy
DataFrame.to_numpy(dtype=None, copy=False, na_value=_NoDefault.no_default)
Convert the DataFrame to a NumPy array.
By default, the dtype of the returned array will be the common NumPy dtype of all types in the DataFrame. For example, if the dtypes are float16 and float32, the results dtype will be float32. This may require copying data and coercing values, which may be expensive.
Parameters
dtypestr or numpy.dtype, optional
The dtype to pass to numpy.asarray().
copybool, default False
Whether to ensure that the returned value is not a view on another array. Note that copy=False does not ensure that to_numpy() is no-copy. Rather, copy=True ensure that a copy is made, even if not strictly necessary.
na_valueAny, optional
The value to use for missing values. The default value depends on dtype and the dtypes of the DataFrame columns.
Returns
numpy.ndarray于是通过以上两种方法就基本达到了需求,能解决当前遇到的问题。
4、整体回顾:
1、模板文件:
模板excel文件格式为:

2、数据文件:
处理好的数据文件 在DataFrame中为:
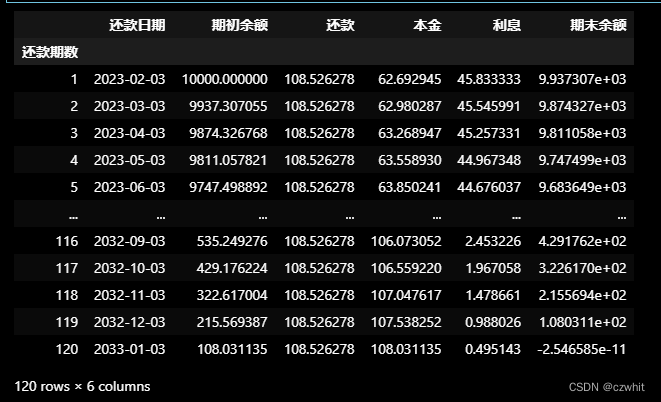
3、数据文件:
把DataFrame数据,去掉列和索引后,写入excel模板中,最终文件为:
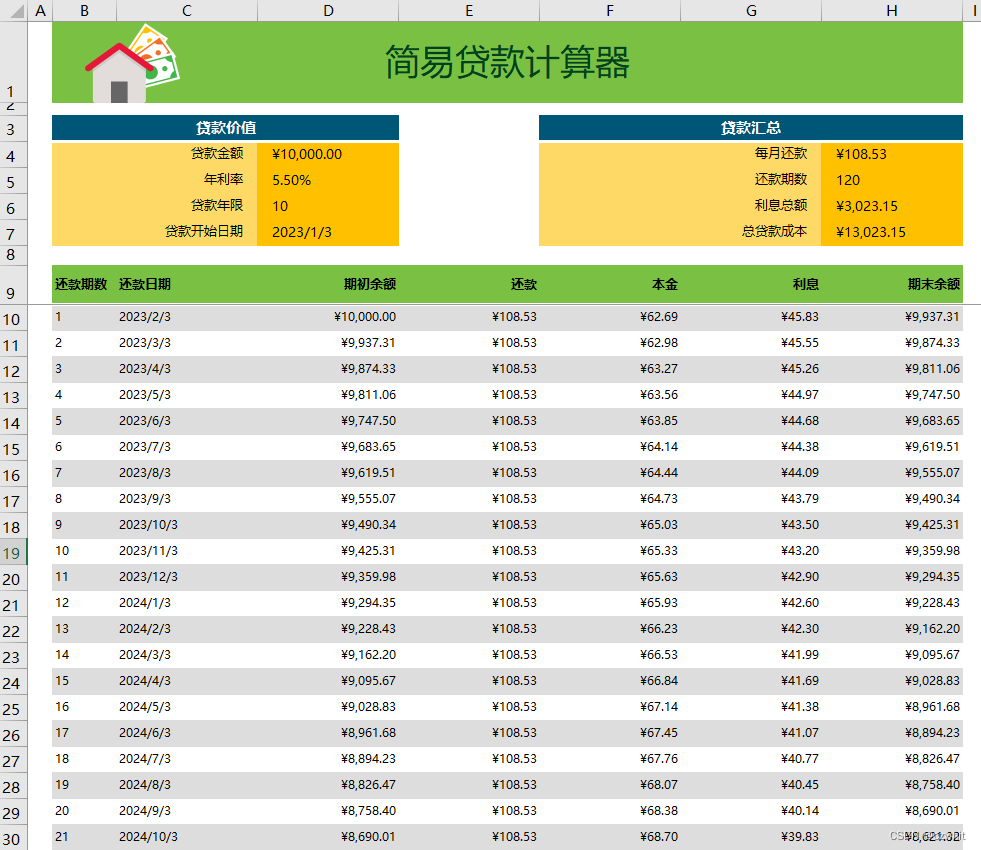
4、主要代码:
# 模板文件所在地址
mb_path = f'files\模板文件.xlsx'
# 最终保存的文件地址
file_path = f'files\datatest_{today_time}.xlsx'
with xw.App(visible=True,add_book=False) as app:
# 打开模板文件
wb = app.books.open(mb_path)
sht = wb.sheets[0]
# 向表格的B10单元格写入数据,处理好的DataFrame数据
sht.range('B10').value = df.to_numpy()
# 此处可以进行切片处理,如果有必要 df.iloc[4:,1:]
# 保存
wb.save(file_path)