[4]PowerNet: Transferable Dynamic IR Drop Estimation via Maximum Convolutional Neural Network论文翻译
摘要
IR drop是几乎所有芯片设计所需的基本约束。然而,其评估通常需要很长时间,这妨碍了修复其违规行为的缓解技术。在这项工作中,我们开发了一种基于卷积神经网络(CNN)的快速动态IR drop估计技术,称为PowerNet。它可以处理基于矢量和无矢量的IR分析。此外,所提出的CNN模型具有通用性,可适用于不同的设计。这与大多数现有的机器学习(ML)方法形成对比,其中模型仅适用于特定的设计。实验结果表明,对于具有挑战性的无矢量IR drop情况,PowerNet的准确率比最新的ML方法高出9%,与精确的IR drop商用工具相比,其速度提高了30倍。此外,由PowerNet指导的缓解工具在两种工业设计中分别减少了26%和31%的IR drop hotspots,对其电网进行了非常有限的修改
1.INTRODUCTION
动态IR drop降是由局部功率需求和开关模式引起的电源电平偏离其规格。为了使电路满足其定时目标并正常工作,必须对其进行限制。因此,验证IR drop是否满足设计约束并识别约束违反区域(即hotspots.)是至关重要的。随着芯片复杂性的不断增长,IR drop评估变得越来越具有挑战性 。
在工业设计中,动态IR drop估计通常是通过运行基于仿真的商业工具来获得的,众所周知,这种方法是准确的,但非常耗时。为了实现更快的估计,已经探索了基于机器学习(ML)的方法。表1总结了许多这些先前的工作。这些工作学习通过诸如cell position,定时窗口,路径阻力等特征来预测每个细胞的动态IR drop,并使用监督机器学习技术。
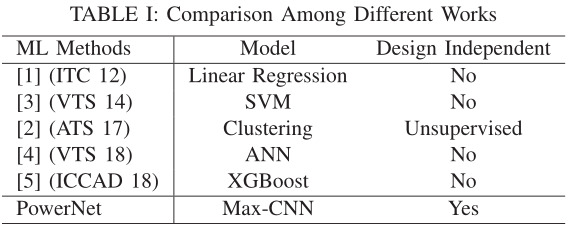
大多数之前的作品的一个主要缺点是它们不是“设计独立的”。“设计独立的“是说,可以转移到训练数据集中没有出现过的新设计。换句话说,这些以前的工作大多需要为每个不同的设计训练一个新的模型。一些工作[1]甚至为每个单元格指定一个模型。使用新标签训练新模型需要较长的仿真和训练时间,这违背了快速估计的初衷。唯一的例外是[2],它基于无监督学习,不学习任何先前的知识。
此外,大多数先前的机器学习方法仅关注基于向量的分析,而忽略了无向量的IR drop。对于动态IR drop,设计中的峰值IR drop可以使用无矢量分析或使用来自值变化转储(VCD)文件的模拟模式进行基于矢量的分析。由于两个主要原因,在物理设计期间,无矢量IR drop分析非常适合IR缓解。首先,对于一个大的芯片,基于矢量的IR drop分析需要大量的模拟模式来覆盖大部分区域,因此速度慢得令人难以忍受。其次,设计人员无法在设计过程的早期获得准确的功率模拟模式。对于大型工业设计,多个团队并行地在不同的RTL单元上工作,并且在整个设计过程中,整个模拟模式都会发生变化。在这种情况下,无矢量IR drop提供了更快和更早的估计,然而,由于开关活动分布的多样性增加,准确的估计比基于矢量的更难。我们将在第V-E节中演示基于矢量和无矢量IR drop分析之间的精度差异
我们基于cnn的方法PowerNet为无矢量和基于矢量的IR drop估计提供了一个可转移的ML模型。考虑到无矢量估计的难度和可用性,我们在实验中更加重视无矢量估计。PowerNet通过其创新的预处理功能和CNN架构解决了这些挑战。在之前的工作[5]中,每个单元格的坐标和时间信息等与设计相关的特征被直接输入到ML模型中。由于位置和时间不会直接导致IR下降,因此直接基于这些特征拟合模型可能会引入过拟合问题,使模型在未见过的设计上不准确。相反,设计相关的信息应该在输入到ML模型之前进行预处理,以与IR drop相关联。众所周知,IR drop与电池功耗直接相关。因此,PowerNet在预处理过程中仔细地将这些与设计相关的功能纳入功率图中。它还利用创新的CNN架构来捕获最大的瞬态IR drop。我们工作的主要贡献包括:
- 我们提出了PowerNet,一种创新的CNN方法,它同时针对无矢量和基于矢量的IR drop估计。这是第一个声称可以执行独立于设计的快速IR drop估计的方法
- 对于无矢量和基于矢量的IR drop估计的实验,PowerNet在每个测试的工业设计上都优于所有其他ML方法。特别是对于无矢量预测,PowerNet的准确率提高了9%。
- PowerNet比基于精确仿真的商用IR drop分析工具快30倍。
- PowerNet指导的IR drop缓解工具在两种新的工业设计中减少了26%和31%的IR drop热点,对电网进行了非常有限的修改。
- 通过两个具有代表性的实例,详细分析了PowerNet的工作原理。
2.PROBLEM FORMULA TION
这项工作的目的是检测IR drop热点的位置。热点是指IR drop大于指定阈值的区域。为了估计IR drop,每个设计都被镶嵌成一个tile数组,每个tile都是一个 l × l l×l l×l正方形。tile大小 l l l控制我们的解决方案的粒度。这样,尺寸为 W × H W × H W×H的设计用 W × H W × H W×H矩阵表示,其中 W = W / l , H = H / l W = W/l, H = H/l W=W/l,H=H/l。每个tile的IR drop值是其中所有单元的IR drop值的平均值。则整个设计的IR drop为 I R ∈ R w × h IR∈R^{w×h} IR∈Rw×h。在本文中,ground-truth IR也被称为标签。对于输入特征,每个tile计算不同类型的功耗值。我们将每个 w × h w × h w×h功率矩阵称为功率图。本质上,功率图是功率密度的分布。PowerNet F试图基于所有G个不同的功率映射{
P m a p 1 … P m a p G P_{map1}…P_{mapG} Pmap1…PmapG} 给出最接近的估计 F ∗ F^ ∗ F∗。
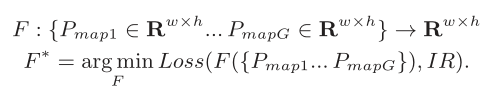
3.ALGORITHM
A.Feature Extraction特征提取
根据欧姆定律,大电流或高电阻都可能导致IR下降过大。在最先进的VLSI设计中,我们假设电力输送网络(PDN)中的电网是均匀的,这意味着整个设计中的电阻分布也相当均匀。因此,在PowerNet中,我们选择不花费额外的时间计算每个单元的电阻。对于非均匀PDN的设计,每个单元的功率值可以通过其电阻进行缩放。阻力的影响在V-D节进一步阐述。当电阻被认为是一致的,电流成为唯一的关键问题,在红外降估计。由于本地功耗与本地电流成正比,因此PowerNet利用电池功率作为其输入特性。
对于每个单元c,我们没有穷尽所有可能的相关特征,这使得模型过于复杂和过拟合。相反,我们选择那些被证明为IR下降估计提供必要信息的特征。不包括硬宏。下面是所有特征的详细信息以及从中提取的标签
-
功率:提取三种类型的功率值。
-内部功率(pi)
-开关功率(ps)
-泄漏功率(pl)
-
信号到达时间:在一个时钟周期内信号到达cell的最小和最大时间。
-最小到达时间(tmin)
-最大到达时间(tmax)
-
坐标:单元格放置后的位置。
-最小和最大x轴(xmin, xmax)
-最小和最大y轴(ymin, ymax)
-
切换率:描述相对于给定时钟输入,输出变化的频率。
-比率(rtog)
-
IR drop:标称电源电压与到达每个cell的实际电压之间的差值。(ir)
以上所有特征都是标量值。对于这些功率类型,内部功率 p i p_i pi表示每个电池内部电容耗散的功率;开关功率 p s p_s ps是由电池输出端的负载电容耗散的功率;泄漏功率 p l p_l pl,在实验中相对较小,被无意的泄漏所消耗,对功能没有贡献。基于这些基本的功率类型,我们可以为每个单元生成更多的功率信息
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ATmR1HiS-1682331652488)(img/1682330554842.png)]
p s c a p_{sca} psca和 p a l l p_{all} pall都反映了单元耗散的总功率,但 p s c a p_{sca} psca根据每个单元的切换速率缩放总功率。PowerNet学会了将这些不同的功耗来源的总功率结合起来
B.Preprocessing by Decomposition分解预处理
在功率被提取后,在每个cell上看到的IR drop不仅仅是简单地与它自己的cell功率成正比,而且还取决于它的邻居,由于空间和时间的电流分布。在空间上,局部电流与局部区域内所有cell的功率需求之和成正比。因此,邻近cell的功率也有助于分析cell的IR drop。我们通过空间分解将cell能量平摊成网格块。这也促使我们在PowerNet中采用CNN模型,该模型天生就是为学习可扩展的二维模式而设计的。即使考虑空间信息,总功率需求高的区域仍可能不是IR drop热点。当该区域的cell没有同时切换时,就会出现这种情况。这种异步开关将电压降分散到更大的定时窗口中。因此,最大动态IR drop,即最高瞬态电压降,仍然可以很低。PowerNet在预处理过程中通过时间分解来测量这种影响。
算法1给出了我们的预处理方法。它根据细胞信息生成能量图。对于每种设计,生成两种类型的功率图。第一种类型包括{ P i , P s , P s c a , P a l l P_i, P_s, P_{sca}, P_{all} Pi,Ps,Psca,Pall}。它们只经过空间分解,不携带时间信息。第二类{ P t [ j ] ∈ R w × h ∣ j ∈ [ 1 , N ] P_t[j]∈R^{w×h} | j∈[1,N] Pt[j]∈Rw×h∣j∈[1,N]}既经过空间分解,又经过时间分解。

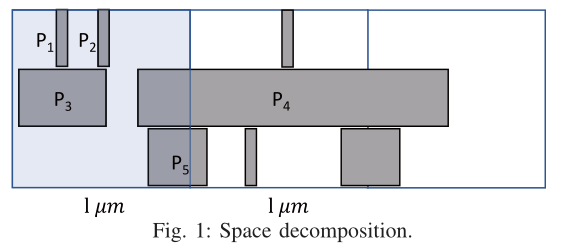
如图1所示,空间分解(第7至14行)将单元的功率分摊到单元占用的任何网格块中。假设规则正方形是网格块,灰色矩形是单元格。P1 ~ P5为细胞功率。对于最左边突出显示的贴图,它的功率等于P1 + P2 + P3 + P4/3 + P5/2。功率为P4的长cell仅将其功率贡献给高亮显示的tile的三分之一,因为它总共与三个tile重叠。类似地,在第7行到第14行中,每个单元格贡献p/s,其中s是重叠块的数量。
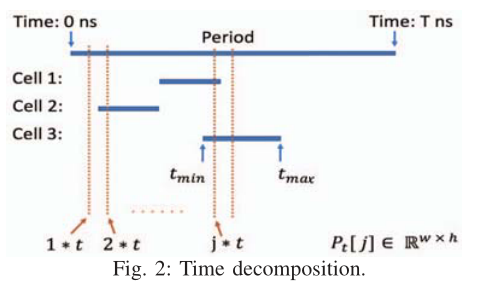
第15到17行执行时间分解。每个功率映射Pt[j]对应于一个时间瞬间j∗t。对于j∗t的每个cell,只有当j∗t落在其信号到达时间[tmin, tmax]之间时,它才为相应的功率映射Pt[j]贡献功率。换句话说,只考虑那些可能在那一刻切换的cell。图2演示了该机制。垂直虚线表示从1 * t到j * t的时间间隔,横线表示cell的信号到达时间间隔。在本例中,只有单元格1和3被Pt[j]计算,没有单元格被Pt[1]计算。
C. PowerNet Model
算法2展示了PowerNet F如何使用其CNN模型 f f f处理功率图。对于每个训练epoch,它迭代训练设计中的每个tile (x, y)。对于每个tile,它通过GETINPUT函数从所有相关的w × h功率映射中裁剪出周围的k × k个输入窗口。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aJWqc32n-1682331652490)(img/1682331413955.png)]](https://img-blog.csdnimg.cn/b6f603714cbe48e68bea8c8b3766667a.png)
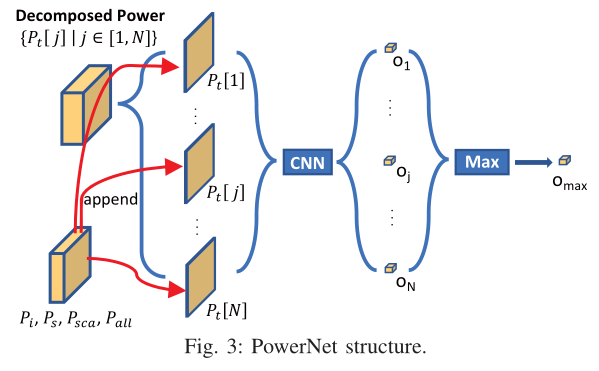
如第11 ~ 12行和图3所示,对于所有N个时间分解的功率图{
P t [ j ] ∈ R w × h ∣ j ∈ [ 1 , N ] Pt[j]∈R^{w×h} | j∈[1,N] Pt[j]∈Rw×h∣j∈[1,N]},它们与其他所有常见的功率图 P i , P s , P s c a , P a l l P_i, P_s, P_{sca}, P_{all} Pi,Ps,Psca,Pall一起,由同一个CNN模型分别处理。因此,在第2行中,CNN的输入为{
P i , P s , P s c a , P a l l , P t [ j ] P_i, P_s, P_{sca}, P_{all}, P_t[j] Pi,Ps,Psca,Pall,Pt[j]}。总共有N个CNN输出{
o j ∣ j ∈ [ 1 , N ] o_j | j∈[1,N] oj∣j∈[1,N]}。则最大输出omax = Max({
o j ∣ j ∈ [ 1 , N ] o_j | j∈[1,N] oj∣j∈[1,N]})为所分析tile的预测结果。这个最大结构突出了导致IR drop峰值的唯一瞬间。它引导CNN学习这种模式。
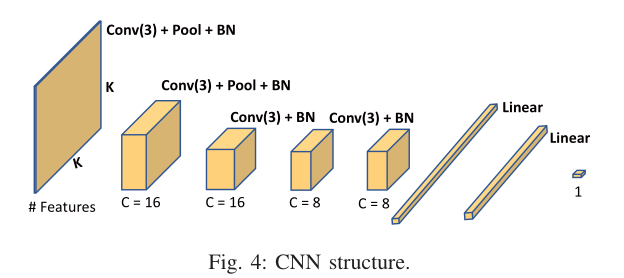
PowerNet中CNN模型的详细情况如图4所示。有四个卷积层,两个池化层和两个完全连接层。卷积核的大小在括号中给出。每个张量下的C给出了每个卷积层中定义的核的数量。这个CNN结构和像N、k这样的超参数是根据交叉验证期间的性能进行调整的。选择更大的输入k,更多的层或核会降低模型泛化并减慢预测速度,而更简单的结构会对数据进行不充分拟合。采用批归一化(Batch normalization, BN)[6]加速模型收敛。采用Adam方法[7]进行优化。我们采用预测与标签之间的平均绝对误差(L1损失)作为损失函数