
前言
本项目旨在通过应用TF-IDF算法,将新下载的课件进行自动分类整理。我们的方法是通过比较新文件中的词频与已构建的各学科语料库的词频,利用余弦相似度计算高频词的相关系数,从而匹配到最相近的学科。
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征提取方法,它通过计算词语在文本中的频率和在整个语料库中的逆文档频率,来评估词语的重要性。
这个项目的应用非常广泛。无论是学生、教师还是研究人员,都可以受益于这个自动分类整理的功能。它可以帮助用户节省大量的时间和精力,提高工作效率,并确保课件文件被准确地整理到相关的学科文件夹中。
总体设计
本部分包括系统整体结构图和系统流程图。
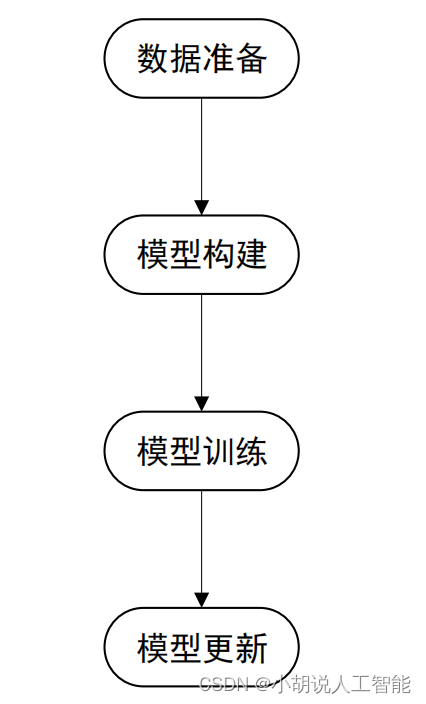
系统整体结构图
系统整体结构如图所示。
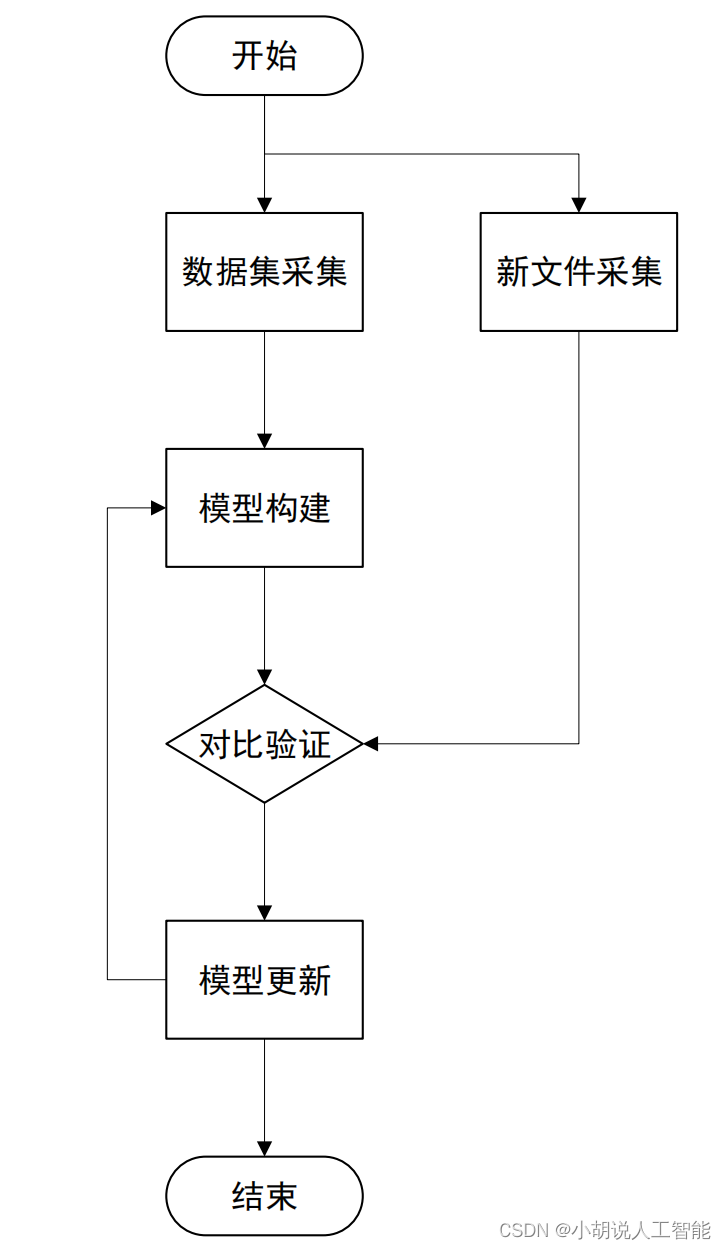
系统流程图
系统流程如图所示。
运行环境
需要 Python 3.8 及以上配置。
模块实现
本项目包括 3 个模块:数据预处理、词频计算与数据处理、数据计算与对比验证,下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
语料库从已经分好类的文件夹中采集,提取所有文件的内容汇总至一个文件并转化为txt,便于词频统计操作。
1)文档内容汇总
import win32com.client as win32
import os
word = win32.gencache.EnsureDispatch('Word.Application')
#启动word对象应用
word.Visible = False
def combine(path1,path2,n):
path = path1
files = []
for filename in os.listdir(path):
filename = os.path.join(path,filename)
files.append(filename)
#新建合并后的文档
output = word.Documents.Add()
for file in files:
output.Application.Selection.InsertFile(file)#拼接文档
#获取合并后文档内容
doc = output.Range(output.Content.Start, output.Content.End)
output.SaveAs(path2) #保存
output.Close()
print ("已合并第"+ str(n) +"科目")
#执行合并,分别将各科目的课件合并成docx保存至combine文件夹
path11 = r'D://i/样例之第一学科(通原实验)'
path12 = r'D://i/combine/combine1.docx'
path21 = r'D://i/样例之第二学科(通信网理论)'
path22 = r'D://i/combine/combine2.docx'
combine(path11,path12,1)
combine(path21,path22,2)
2)格式转化
#-*- coding: ANSI -*-
import os
import sys
import fnmatch
import win32com.client
PATH_DATA = r'D://i/combine'
#主要执行函数
def main():
wordapp=win32com.client.gencache.EnsureDispatch("Word.Application")try:
for root, dirs,files in os.walk(PATH_DATA):
for _dir in dirs:
pass
for _file in files:
if not fnmatch.fnmatch(_file,'*.docx'):
continue
word_file = os.path.join(root, _file)
wordapp.Documents.Open(word_file)
docastxt = word_file[:-4] +'txt'
wordapp.ActiveDocument.SaveAs(docastxt,FileFormat= win32com.client.constants.wdFormatText)
wordapp.ActiveDocument.Close()
finally:
wordapp.Quit()
print ("已转换成txt格式!")
if __name__ == '__main__':
main()
2. 词频计算与数据处理
将各语料库与新文件的内容进行分词并计算,数据写入 excel 文档进行数据处理。其中,词频部分使用 jieba 库进行分词,数据处理部分对 xlsx 文件进行操作 openpyxl 库。
1)分词并统计词频
分词部分使用 jieba 库,这里提取出最高频的 50 个词,以下代码是以 1 个新文件和两个语料库为例。
with codecs.open(txt, 'r', 'ANSI') as f:
txt = f.read()
seg_list = jieba.cut(txt) #对文本进行分词
c = Counter()
for x in seg_list: #进行词频统计
if x not in stop_word:
if len(x)>1 and x != '\r\n':
c[x] += 1
2)数据写入 excel
将分词的结果,即高频词词名和频数分别写入 excel,使用 openpyxl 库,结果如下图所示。
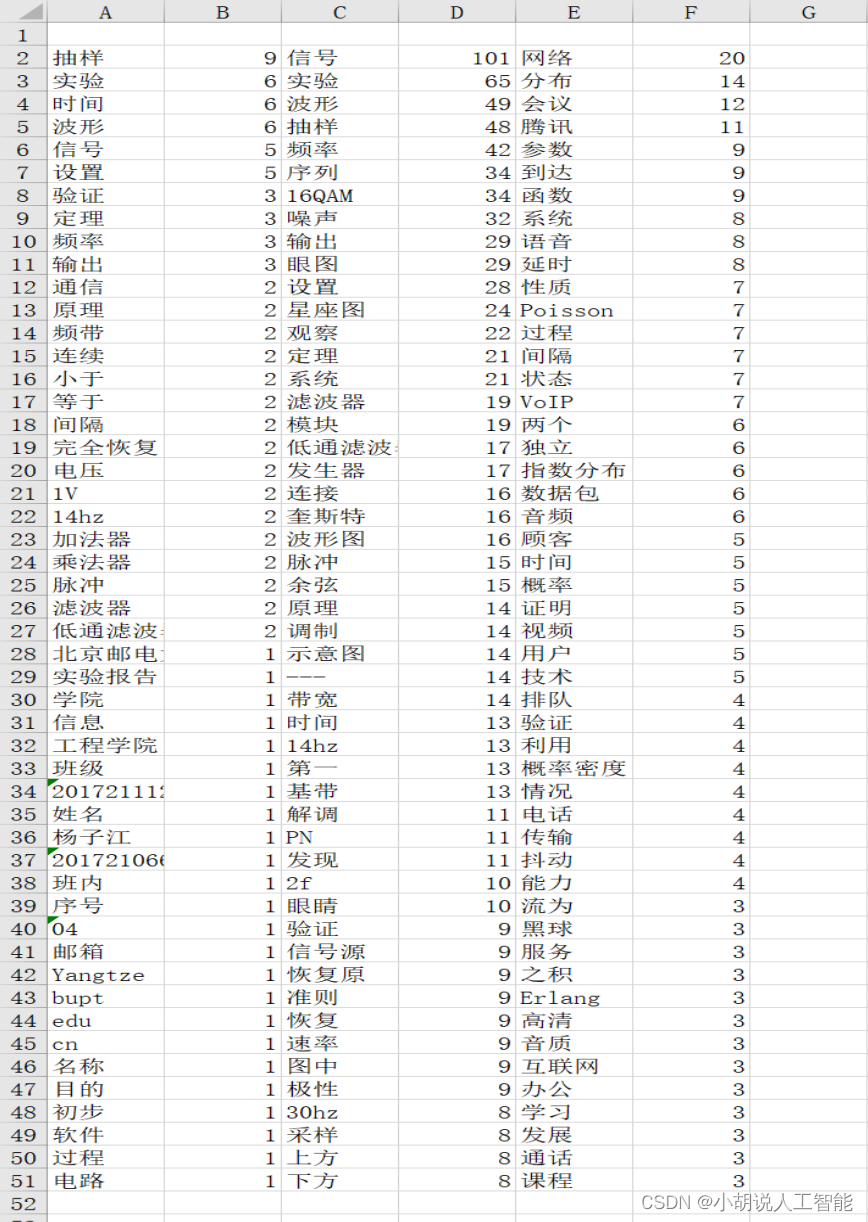
相关代码如下:
#! Python3
#-*- coding: utf-8 -*-
import os, codecs
import jieba
import openpyxl
from collections import Counter
stop_word = [line.strip() for line in open('D:/i/chinese_stopword.txt',encoding='UTF-8').readlines()]
def create_xlsx():
workbook=openpyxl.Workbook()
workbook.save('D:\\i\文件管理.xlsx')
def get_words_write_xlsx(txt, path ,n):
workbook=openpyxl.load_workbook(path)
sheet = workbook.active
with codecs.open(txt, 'r', 'ansi') as f:
txt = f.read()
seg_list = jieba.cut(txt) #对文本进行分词
c = Counter()
for x in seg_list: #进行词频统计
if x not in stop_word:
if len(x)>1 and x != '\r\n':
c[x] += 1
r=2 #从第二行开始写入excel
for (k,v) in c.most_common(50): #遍历输出高频词
#print('%s%s %d' % (' '*(5-len(k)), k, v))
sheet.cell(r, 2*n-1, k)
sheet.cell(r, 2*n, v)
r+=1
workbook.save(path)
print('已成功写入excel!')
path1 = 'D:\\i\文件管理.xlsx'
txt0 = 'D:\\i\new.txt'
txt1 = 'D:\\i\combine\combine1.txt'
txt2 = 'D:\\i\combine\combine2.txt'
if __name__ == '__main__':
create_xlsx()#如果不是第一次使用,不需要创建excel文件,将此行注释
get_words_write_xlsx(txt0, path1, 1)
get_words_write_xlsx(txt1, path1, 2)
get_words_write_xlsx(txt2, path1, 3)
3. 数据计算与对比验证
在得到新文档与各语料库词频数据后,使用 excel 中的函数,将数据进行再加工后,新文档词与每一个语料库对比,计算相关系数,并得到属于新文件的正确类别。
1)Python 控制 excel 函数
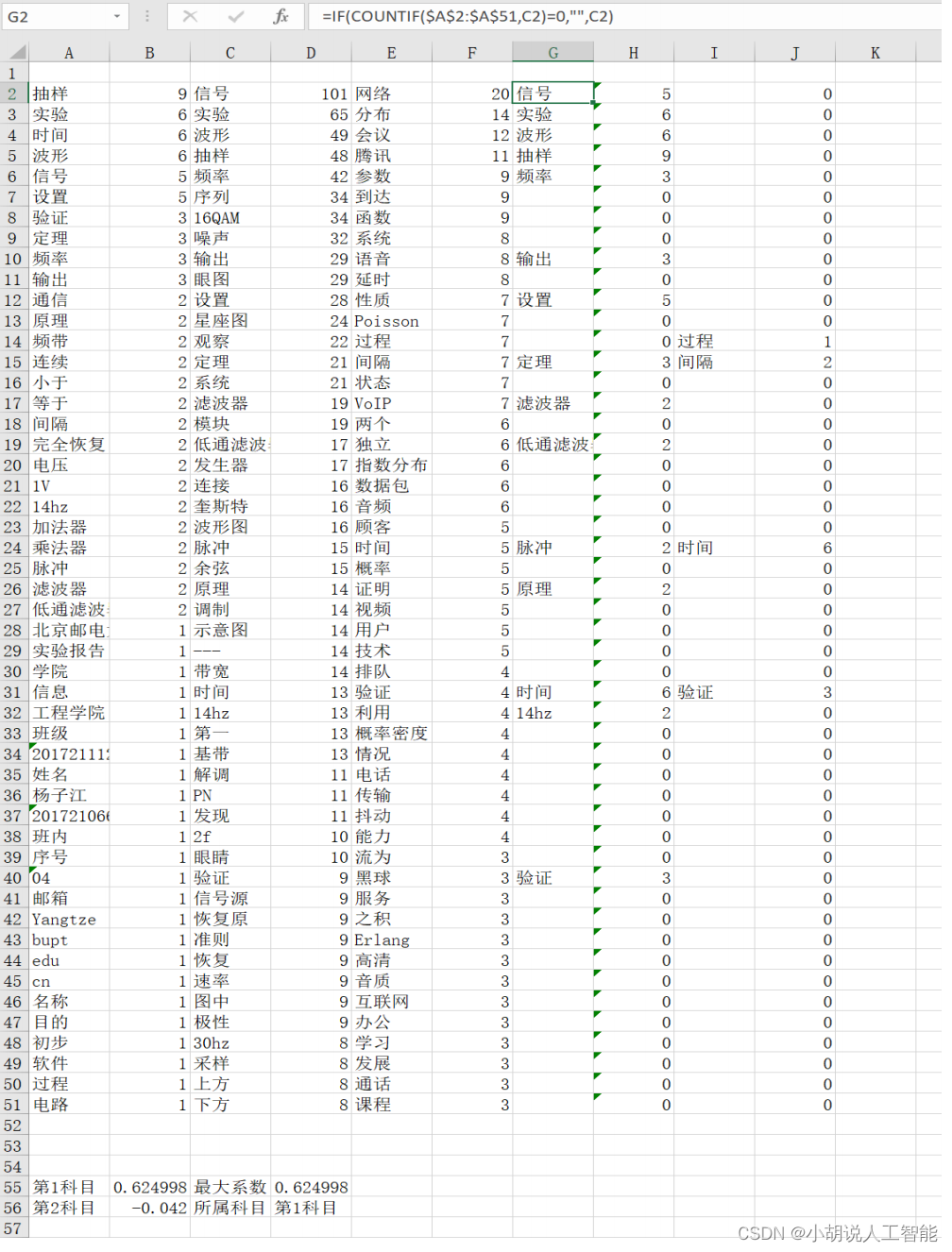
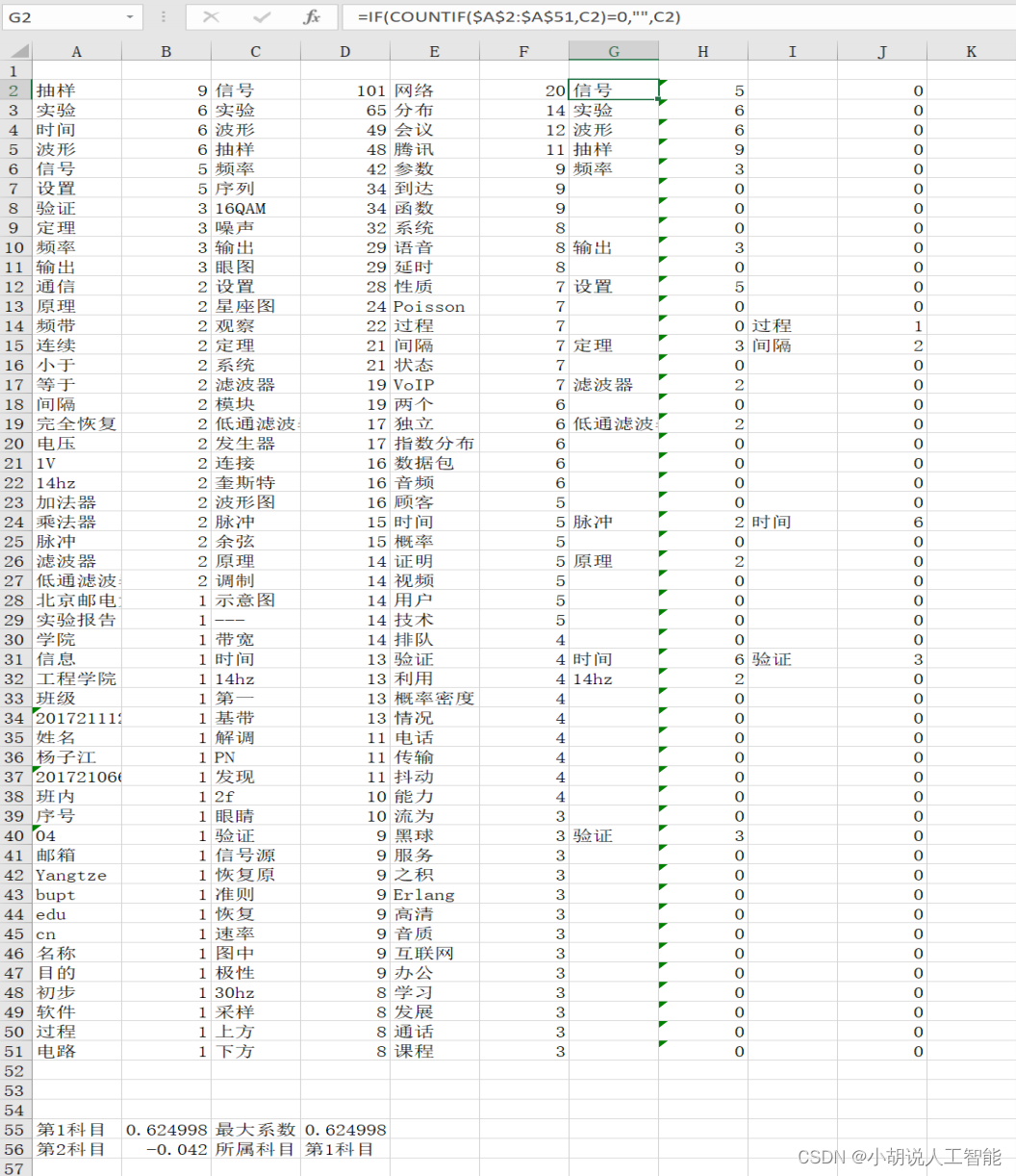
在 excel 中使用 countif、vlookup 和 correl 三个函数进行数据处理。其中 countif 函数将两列中相同的词横行对齐,vlookup 将词频频数与词相匹配。Correl 用来计算两列数据的相关系数,使用 index、match 函数找到相关系数最大的科目并返回所属科目的名称和系数数值,如图 8-4 所示。
import openpyxl
def count_if(a):
for n in range (a):
for i in range(50):
worksheet.cell(i+2,2*n+2*a+3,'=IF(COUNTIF($A$2:$A$51,'+chr(ord("C")+2*n) + str(i+2)+ ')=0,"",'+chr(ord("C")+2*n) + str(i+2)+')')
print('count_if已完成!')
def vlookup(a):
for n in range (a):
for i in range(50):
worksheet.cell(i+2,2*n+2*a+4,'=IFERROR(VLOOKUP('+chr(ord("G")+2*n) + str(i+2)+ ',$A$2:$B$51,2,0),0)')
print('vlookup已完成!')
def correl(a):
for n in range (a):
worksheet.cell(55+n,1,"第"+ str(n+1)+ "科目")
worksheet.cell(55+n,2,'=CORREL('+chr(ord("D")+2*n)+'2:'+chr(ord("D")+2*n)+'51,'+chr(ord("H")+2*n)+'2:'+chr(ord("H")+2*n)+'51)')
print('correl已完成!')
path1=r"D:\\i\文件管理.xlsx"
def rank(a):
worksheet.cell(55,3,"最大系数")
worksheet.cell(56,3,"所属科目")
worksheet.cell(55,4,"=MAX(B55:B"+str(55+a-1)+")")
worksheet.cell(56,4,"=INDEX(A55:A"+str(55+a-1)+",MATCH(D55,B55:B"+str(55+a-1)+",0))")
print('rank已完成!')
def cal(a):
count_if(a)
vlookup(a)
correl(a)
rank(a)
if __name__ == '__main__':
workbook=openpyxl.load_workbook(path1)
worksheet=workbook.active
cal(2)
workbook.save(filename=path1)
2)excel 示意
科目名称和系数数值如下图所示。
系统测试
如图所示,前两列为新文档,3、4 列为之前所有的通信原理实验报告,5、6 列为通信网理论相关资料。通过计算可以发现,新文档与通信原理实验报告相关系数(0.568879)高于通信网理论资料的相关系数(0.000954)。可以判断,新文档属于通信原理实验科目。
工程源代码下载
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。