ISCA,全称International Symposium on Computer Architecture,体系结构领域的顶级会议,由ACM SIGARCH(计算机系统结构特殊兴趣组)和IEEE TCCA(计算机架构技术委员会)联合举办。ISCA创办于1973 年,历史悠久的老牌体系结构顶会,在计算机领域的各种应用和人才遍地开花、大数据与深度学习引发新的发展浪潮的当代,其规模也有所扩大 。ISCA是CCF 推荐A类会议,Core Conference Ranking推荐A*类会议,H5 index为56。ISCA是计算机系统结构领域最顶级的会议之一,包括谷歌、英特尔、英伟达等企业在ISCA上发表的多项研究成果都已在半导体行业广泛应用。
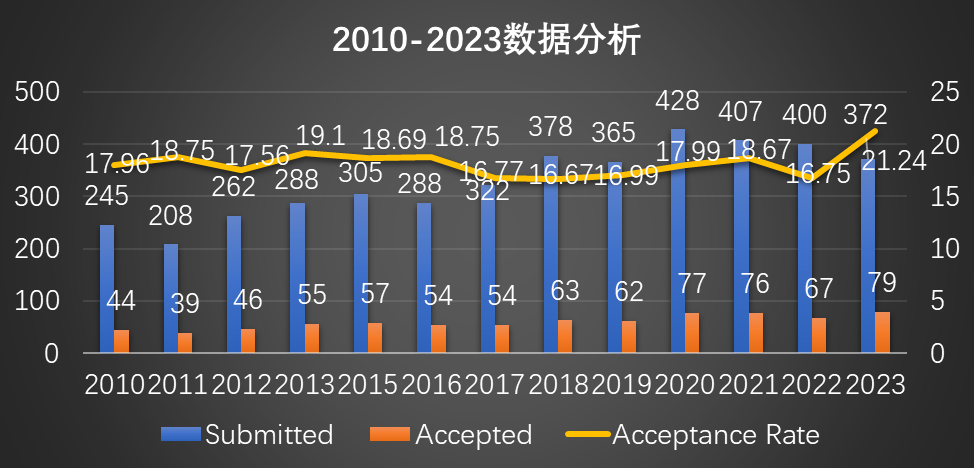
ISCA的投稿量有波动上升趋势,近两年已经超过400篇。但是录取文章变化不大,2020录取量上升到77篇,为历史最高,2022年则下降至67篇。就录取率来看,ISCA一直都非常低,近几年虽有上升趋势,但是从没超过20%的关口,难度可想而知。但是今年ISCA的录取率飙升至21.24%,创下历史新高。
组委会信息
国际计算机体系结构研讨会(ISCA)是讨论计算机体系结构新思想和实验结果的主要论坛。会议特别寻求特别具有前瞻性和新颖的提案。2023年,第50届ISCA将于2023年6月17日至21日在美国奥兰多万豪世界中心举行。ISCA 2023是FCRC的一项活动,将于2023年6月17日至23日与其他13场会议一起举行。此外,ISCA的组委会当中Steering Committee和Program Committee当中都没国内学者,只有在Organizing Committee中,来自华中科大的Chencheng Ye担任Publicity Co-Chairs。

ISCA 2023大会官网:https://iscaconf.org/isca2023/
注册费信息
ISCA的注册分为线上和线下两种,线上注册费为100刀,线下注册则要430刀起步,具体的注册费信息如下:
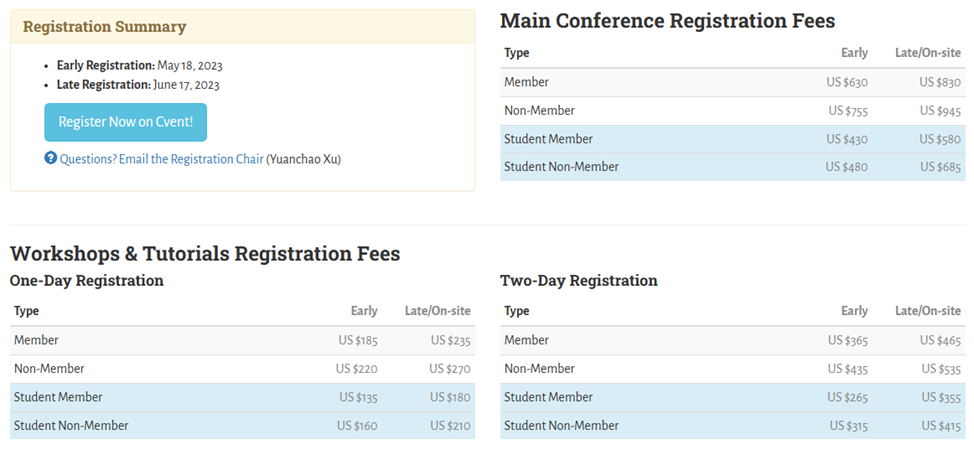
For those who cannot attend ISCA in person, the registration fee is US $100.
录用信息
ISCA今年一共收到投稿372篇,录用79篇,录取率为21.24%,录用论文如下
ML Systems
-
OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization
-
FACT: FFN-Attention Co-optimized Transformer Architecture with Eager Correlation Prediction
-
Mystique: Enabling Accurate and Scalable Generation of Production AI Benchmarks
-
Accelerating Personalized Recommendation with Cross-level Near-Memory Processing
-
Understanding and Mitigating Hardware Failures in Deep Learning Training Systems
-
LAORAM: A Look Ahead ORAM Architecture for Training Large Embedding Tables
-
Optimizing CPU Performance for Recommendation Systems At-Scale
CPU Mircoarchitecture
-
Orinoco: Ordered Issue and Unordered Commit with Non-Collapsible Queues
-
SPADE: A Flexible and Scalable Accelerator for SpMM and SDDMM
-
DynAMO: Improving Parallelism Through Dynamic Placement of Atomic Memory Operations
-
μManycore: A Cloud-Native CPU for Tail at Scale
-
MESA: Microarchitecture Extensions for Spatial Architecture Generation
-
Imprecise Store Exceptions
-
Supply Chain Aware Computer Architecture
Security
-
ISA-Grid: Architecture of Fine-grained Privilege Control for Instructions and Registers
-
TEESec: Pre-Silicon Vulnerability Discovery for Trusted Execution Environments
-
Metior: A Comprehensive Model to Evaluate Obfuscating Side-Channel Defense Schemes
-
Spy in the GPU-box: Covert and Side Channel Attacks on Multi-GPU Systems
-
Doppelganger Loads: A Safe, Complexity-Effective Optimization for Secure Speculation Schemes
-
Pensieve: Microarchitectural Modeling for Security Evaluation
-
All your PC are belong to us: Exploiting Non-control-transfer Instruction BTB Updates for Dynamic PC Extraction
Domain Specific Accelerators
-
HAAC: A Hardware-Software Co-Design to Accelerate Garbled Circuits
-
An Algorithm and Architecture Co-design for Accelerating Smart Contracts in Blockchain
-
FDMAX: An Elastic Accelerator Architecture for Solving Partial Differential Equations
-
MetaNMP: Leveraging Cartesian-Like Product to Accelerate HGNNs with Near-Memory Processing
-
RSQP: Problem-specific Architectural Customization for Accelerated Convex Quadratic Optimization
-
Flumen: Dynamic Processing in the Photonic Interconnect
Memory Systems
-
DRAM Translation Layer: Software-Transparent DRAM Power Savings for Disaggregated Memory
-
RowPress: Amplifying Read-Disturbance in Modern DRAM Chips
-
EMISSARY: Enhanced Miss Awareness Replacement Policy for L2 Instruction Caching
-
Write-Light Cache for Energy Harvesting Systems
-
Implicit Memory Tagging: No-Overhead Memory Safety Using Alias-Free Tagged ECC
-
On Endurance of Processing in (Nonvolatile) Memory
Emerging-Vision/Graphics/AR-VR
-
Instant-3D: Instant Neural Radiance Field Training Towards On-Device AR/VR 3D Reconstruction
-
K-D Bonsai: ISA-Extensions to Compress K-D Trees for Autonomous Driving Tasks
-
NeuRex: A Case for Neural Rendering Acceleration
-
Hardware Acceleration of Neural Graphics
-
Gen-NeRF: Efficient and Generalizable Neural Radiance Fields via Algorithm-Hardware Co-Design
-
EdgePC: Efficient Deep Learning Analytics for Point Clouds on Edge Devices
Emerging-Robotics
-
Energy-Efficient Realtime Motion Planning
-
RoSÉ: A Hardware-Software Co-Simulation Infrastructure Enabling Pre-Silicon Full-Stack Robotics SoC Evaluation
-
RoboShape: Using Topology Patterns to Scalably and Flexibly Deploy Accelerators Across Robots
SSD
-
Venice: Improving Solid-State Drive Parallelism at Low Cost via Conflict-Free Accesses
-
ECSSD: Hardware/Data Layout Co-Designed In-Storage-Computing Architecture for Extreme Classification
-
Decoupled SSD: Rethinking SSD Architecture through Network-based Flash Controllers
GPU
-
R2D2: Removing ReDunDancy Utilizing Linearity of Address Generation in GPUs
-
SAC: Sharin g-Aware Caching in Multi-Chip GPUs