- 尚硅谷大数据技术Spark教程-笔记01【SparkCore(概述、快速上手、运行环境、运行架构)】
- 尚硅谷大数据技术Spark教程-笔记02【SparkCore(核心编程,RDD-核心属性-执行原理-基础编程-并行度与分区-转换算子)】
- 尚硅谷大数据技术Spark教程-笔记03【SparkCore(核心编程,RDD-转换算子-案例实操)】
- 尚硅谷大数据技术Spark教程-笔记04【SparkCore(核心编程,RDD-行动算子-序列化-依赖关系-持久化-分区器-文件读取与保存)】
- 尚硅谷大数据技术Spark教程-笔记05【SparkCore(核心编程,累加器、广播变量)】
- 尚硅谷大数据技术Spark教程-笔记06【SparkCore(案例实操,电商网站)】
- 尚硅谷大数据技术Spark教程-笔记07【Spark内核&源码(环境准备、通信环境、应用程序执行、shuffle、内存管理)】
- 尚硅谷大数据技术Spark教程-笔记08【SparkSQL(介绍、特点、数据模型、核心编程、案例实操、总结)】
- 尚硅谷大数据技术Spark教程-笔记09【SparkStreaming(概念、入门、DStream入门、案例实操、总结)】
目录
P153【153.尚硅谷_SparkSQL - 介绍】05:37
P154【154.尚硅谷_SparkSQL - 特点】02:39
P155【155.尚硅谷_SparkSQL - 数据模型 - DataFrame & DataSet】06:44
P156【156.尚硅谷_SparkSQL - 核心编程 - DataFrame - 简单演示】07:21
P157【157.尚硅谷_SparkSQL - 核心编程 - DataFrame - SQL的基本使用】10:27
P158【158.尚硅谷_SparkSQL - 核心编程 - DataFrame - DSL语法的基本使用】06:36
P159【159.尚硅谷_SparkSQL - 核心编程 - DataFrame - RDD之间的转换】07:01
P160【160.尚硅谷_SparkSQL - 核心编程 - DataSet - 介绍】04:06
P161【161.尚硅谷_SparkSQL - 核心编程 - DataSet - DataFrame的转换】03:28
P162【162.尚硅谷_SparkSQL - 核心编程 - DataSet - RDD的转换】05:05
P163【163.尚硅谷_SparkSQL - 核心编程 - DataSet & DataFrame & RDD之间的关系】04:51
P164【164.尚硅谷_SparkSQL - 核心编程 - IDEA创建SparkSQL环境对象】07:21
P165【165.尚硅谷_SparkSQL - 核心编程 - IDEA - DataFrame基本操作】07:50
P166【166.尚硅谷_SparkSQL - 核心编程 - IDEA - DataSet基本操作】03:18
P167【167.尚硅谷_SparkSQL - 核心编程 - IDEA - RDD & DataFrame & DataSet互相转换】05:48
P168【168.尚硅谷_SparkSQL - 核心编程 - IDEA - UDF函数】04:18
P169【169.尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 实现原理】05:11
P170【170.尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 弱类型函数实现】16:14
P171【171.尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 强类型函数实现】10:58
P172【172.尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 早期强类型函数实现】06:24
P173【173.尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 课件梳理】03:23
P174【174.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 通用方法】06:36
P175【175.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作JSON & CSV】08:30
P176【176.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作MySQL】04:22
P177【177.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作内置Hive】05:40
P178【178.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作外置Hive】03:53
P179【179.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 代码操作外置Hive】04:28
P180【180.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - beeline操作Hive】04:15
P181【181.尚硅谷_SparkSQL - 案例实操 - 数据准备】06:37
P182【182.尚硅谷_SparkSQL - 案例实操 - 需求部分实现】12:56
P183【183.尚硅谷_SparkSQL - 案例实操 - 需求完整实现】26:54
P184【184.尚硅谷_SparkSQL - 总结 - 课件梳理】13:39
02_尚硅谷大数据技术之SparkSql.pdf
第1章 SparkSQL概述
P153【153.尚硅谷_SparkSQL - 介绍】05:37
Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块。
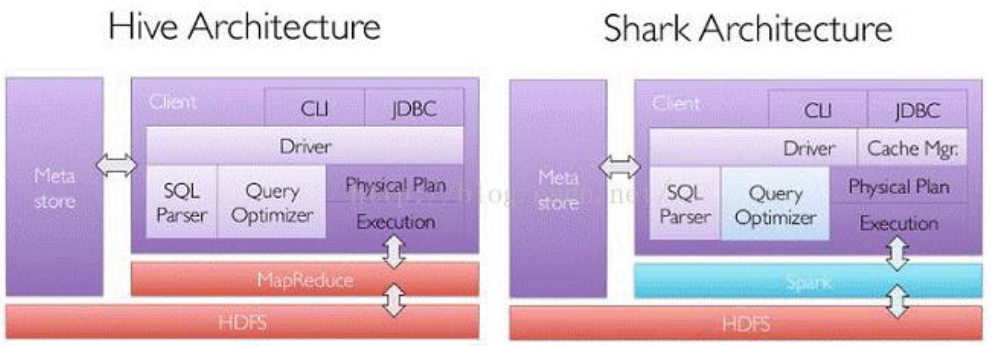
对于开发人员来讲,SparkSQL 可以简化 RDD 的开发,提高开发效率,且执行效率非常快,所以实际工作中,基本上采用的就是 SparkSQL。Spark SQL 为了简化 RDD 的开发, 提高开发效率,提供了 2 个编程抽象,类似 Spark Core 中的 RDD:DataFrame、DataSet。
P154【154.尚硅谷_SparkSQL - 特点】02:39
1.3 SparkSQL特点
- 1.3.1 易整合,无缝的整合了 SQL 查询和 Spark 编程。
- 1.3.2 统一的数据访问,使用相同的方式连接不同的数据源。
- 1.3.3 兼容Hive,在已有的仓库上直接运行 SQL 或者 HiveQL。
- 1.3.4 标准数据连接,通过 JDBC 或者 ODBC 来连接。
P155【155.尚硅谷_SparkSQL - 数据模型 - DataFrame & DataSet】06:44
1.4 DataFrame是什么
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维表格。
1.5 DataSet是什么
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame 的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter 等等)。
第2章 SparkSQL核心编程
P156【156.尚硅谷_SparkSQL - 核心编程 - DataFrame - 简单演示】07:21
{"username": "宋壹", "age": 11}
{"username": "丁二", "age": 22}
{"username": "zhangsan", "age": 33}
{"username": "lisi", "age": 44}

Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://upward:4040
Spark context available as 'sc' (master = local[*], app id = local-1684479289447).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_201)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 23/05/19 14:55:03 WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped
scala>
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@20ca2c3f
scala> spark
res1: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@631990cc
scala> spark.read.
csv format jdbc json load option options orc parquet schema table text textFile
scala> spark.read.
!= == eq getClass json notifyAll parquet text →
## asInstanceOf equals hashCode load option schema textFile
+ csv format isInstanceOf ne options synchronized toString
-> ensuring formatted jdbc notify orc table wait
scala> spark.read.json("input/user.json")
res2: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> val df = spark.read.json("input/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> df.show
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
scala> //单行注释
scala> df.createTempView("user") //创建一个临时的user视图
scala> spark.sql("select * from user").show
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
scala> spark.sql("select age from user").show
+---+
|age|
+---+
| 11|
| 22|
| 33|
| 44|
+---+
scala> spark.sql("select avg(age) from user").show
+--------+
|avg(age)|
+--------+
| 27.5|
+--------+
scala>P157【157.尚硅谷_SparkSQL - 核心编程 - DataFrame - SQL的基本使用】10:27
2.2 DataFrame
2.2.2 SQL语法
注意:普通临时表是 Session 范围内的,如果想应用范围内有效,可以使用全局临时表。使 用全局临时表时需要全路径访问,如:global_temp.people。
scala> spark.newSession.sql("select age from user").show
23/05/19 15:52:44 WARN NativeIO: NativeIO.getStat error (3): 系统找不到指定的路径。
-- file path: tmp/hive
23/05/19 15:52:44 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
23/05/19 15:52:44 WARN HiveConf: HiveConf of name hive.stats.retries.wait does not exist
23/05/19 15:52:44 WARN General: Plugin (Bundle) "org.datanucleus.api.jdo" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/D:/bigData/spark/spark-3.0.0-bin-hadoop3.2/jars/datanucleus-api-jdo-4.2.4.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/D:/bigData/spark/spark-3.0.0-bin-hadoop3.2/bin/../jars/datanucleus-api-jdo-4.2.4.jar."
23/05/19 15:52:44 WARN General: Plugin (Bundle) "org.datanucleus" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/D:/bigData/spark/spark-3.0.0-bin-hadoop3.2/jars/datanucleus-core-4.1.17.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/D:/bigData/spark/spark-3.0.0-bin-hadoop3.2/bin/../jars/datanucleus-core-4.1.17.jar."
23/05/19 15:52:44 WARN General: Plugin (Bundle) "org.datanucleus.store.rdbms" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/D:/bigData/spark/spark-3.0.0-bin-hadoop3.2/jars/datanucleus-rdbms-4.1.19.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/D:/bigData/spark/spark-3.0.0-bin-hadoop3.2/bin/../jars/datanucleus-rdbms-4.1.19.jar."
23/05/19 15:52:47 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 2.3.0
23/05/19 15:52:47 WARN ObjectStore: setMetaStoreSchemaVersion called but recording version is disabled: version = 2.3.0, comment = Set by MetaStore [email protected]
23/05/19 15:52:47 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
org.apache.spark.sql.AnalysisException: Table or view not found: user; line 1 pos 16;
'Project ['age]
+- 'UnresolvedRelation [user]
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$1(CheckAnalysis.scala:106)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$1$adapted(CheckAnalysis.scala:92)
at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:177)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$foreachUp$1(TreeNode.scala:176)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$foreachUp$1$adapted(TreeNode.scala:176)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:176)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.checkAnalysis(CheckAnalysis.scala:92)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.checkAnalysis$(CheckAnalysis.scala:89)
at org.apache.spark.sql.catalyst.analysis.Analyzer.checkAnalysis(Analyzer.scala:130)
at org.apache.spark.sql.catalyst.analysis.Analyzer.$anonfun$executeAndCheck$1(Analyzer.scala:156)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:153)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$analyzed$1(QueryExecution.scala:68)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:133)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:133)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:68)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:66)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:58)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:99)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:97)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:606)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:601)
... 47 elided
scala> df.createOrReplaceGlobalTempView("emp")
23/05/19 15:58:15 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
scala> spark.newSession.sql("select * from global_temp.emp").show
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
scala>P158【158.尚硅谷_SparkSQL - 核心编程 - DataFrame - DSL语法的基本使用】06:36
2.2.3 DSL语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。 可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了。
scala> df.printSchema
root
|-- age: long (nullable = true)
|-- username: string (nullable = true)
scala> df.
agg foreachPartition schema
alias groupBy select
apply groupByKey selectExpr
as head show
cache hint sort
checkpoint inputFiles sortWithinPartitions
coalesce intersect sparkSession
col intersectAll sqlContext
colRegex isEmpty stat
collect isLocal storageLevel
collectAsList isStreaming summary
columns javaRDD tail
count join take
createGlobalTempView joinWith takeAsList
createOrReplaceGlobalTempView limit toDF
createOrReplaceTempView localCheckpoint toJSON
createTempView map toJavaRDD
crossJoin mapPartitions toLocalIterator
cube na toString
describe observe transform
distinct orderBy union
drop persist unionAll
dropDuplicates printSchema unionByName
dtypes queryExecution unpersist
encoder randomSplit where
except randomSplitAsList withColumn
exceptAll rdd withColumnRenamed
explain reduce withWatermark
explode registerTempTable write
filter repartition writeStream
first repartitionByRange writeTo
flatMap rollup
foreach sample
scala> df.s
sample selectExpr sortWithinPartitions stat synchronized
schema show sparkSession storageLevel
select sort sqlContext summary
scala> df.select
select selectExpr
scala> df.select("age").show
+---+
|age|
+---+
| 11|
| 22|
| 33|
| 44|
+---+
scala> df.select("age" + 1).show
org.apache.spark.sql.AnalysisException: cannot resolve '`age1`' given input columns: [age, username];;
'Project ['age1]
+- Relation[age#18L,username#19] json
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$$nestedInanonfun$checkAnalysis$1$2.applyOrElse(CheckAnalysis.scala:143)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$$nestedInanonfun$checkAnalysis$1$2.applyOrElse(CheckAnalysis.scala:140)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformUp$2(TreeNode.scala:333)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:333)
at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$transformExpressionsUp$1(QueryPlan.scala:106)
at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$1(QueryPlan.scala:118)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:72)
at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpression$1(QueryPlan.scala:118)
at org.apache.spark.sql.catalyst.plans.QueryPlan.recursiveTransform$1(QueryPlan.scala:129)
at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$3(QueryPlan.scala:134)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at scala.collection.AbstractTraversable.map(Traversable.scala:108)
at org.apache.spark.sql.catalyst.plans.QueryPlan.recursiveTransform$1(QueryPlan.scala:134)
at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$4(QueryPlan.scala:139)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:237)
at org.apache.spark.sql.catalyst.plans.QueryPlan.mapExpressions(QueryPlan.scala:139)
at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressionsUp(QueryPlan.scala:106)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$1(CheckAnalysis.scala:140)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$1$adapted(CheckAnalysis.scala:92)
at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:177)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.checkAnalysis(CheckAnalysis.scala:92)
at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.checkAnalysis$(CheckAnalysis.scala:89)
at org.apache.spark.sql.catalyst.analysis.Analyzer.checkAnalysis(Analyzer.scala:130)
at org.apache.spark.sql.catalyst.analysis.Analyzer.$anonfun$executeAndCheck$1(Analyzer.scala:156)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:153)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$analyzed$1(QueryExecution.scala:68)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:133)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:133)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:68)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:66)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:58)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$1(Dataset.scala:91)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:89)
at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$withPlan(Dataset.scala:3644)
at org.apache.spark.sql.Dataset.select(Dataset.scala:1456)
at org.apache.spark.sql.Dataset.select(Dataset.scala:1473)
... 47 elided
scala> df.select($"age" + 1).show
+---------+
|(age + 1)|
+---------+
| 12|
| 23|
| 34|
| 45|
+---------+
scala> df.select('age + 1).show
+---------+
|(age + 1)|
+---------+
| 12|
| 23|
| 34|
| 45|
+---------+
scala> df.filter('age > 11).show
+---+--------+
|age|username|
+---+--------+
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
scala> df.groupBy("age").count.show
+---+-----+
|age|count|
+---+-----+
| 22| 1|
| 33| 1|
| 44| 1|
| 11| 1|
+---+-----+
scala>P159【159.尚硅谷_SparkSQL - 核心编程 - DataFrame - RDD之间的转换】07:01

scala> val rdd = sc.makeRDD(List(1, 2, 3, 4))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> rdd.
!= equals max sparkContext
## filter mean stats
+ first meanApprox stdev
++ flatMap min subtract
-> fold name sum
== foreach ne sumApprox
aggregate foreachAsync notify synchronized
asInstanceOf foreachPartition notifyAll take
barrier foreachPartitionAsync partitioner takeAsync
cache formatted partitions takeOrdered
canEqual getCheckpointFile persist takeSample
cartesian getClass pipe toDF
checkpoint getNumPartitions popStdev toDS
coalesce getStorageLevel popVariance toDebugString
collect glom preferredLocations toJavaRDD
collectAsync groupBy productArity toLocalIterator
compute hashCode productElement toString
context histogram productIterator top
copy id productPrefix treeAggregate
count intersection randomSplit treeReduce
countApprox isCheckpointed reduce union
countApproxDistinct isEmpty repartition unpersist
countAsync isInstanceOf sample variance
countByValue iterator sampleStdev wait
countByValueApprox keyBy sampleVariance zip
dependencies localCheckpoint saveAsObjectFile zipPartitions
distinct map saveAsTextFile zipWithIndex
ensuring mapPartitions setName zipWithUniqueId
eq mapPartitionsWithIndex sortBy →
scala> rdd.toDF
res0: org.apache.spark.sql.DataFrame = [value: int]
scala> val df = rdd.toDF("id")
df: org.apache.spark.sql.DataFrame = [id: int]
scala> df.show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+
scala> df.rdd
lazy val rdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row]
scala>P160【160.尚硅谷_SparkSQL - 核心编程 - DataSet - 介绍】04:06
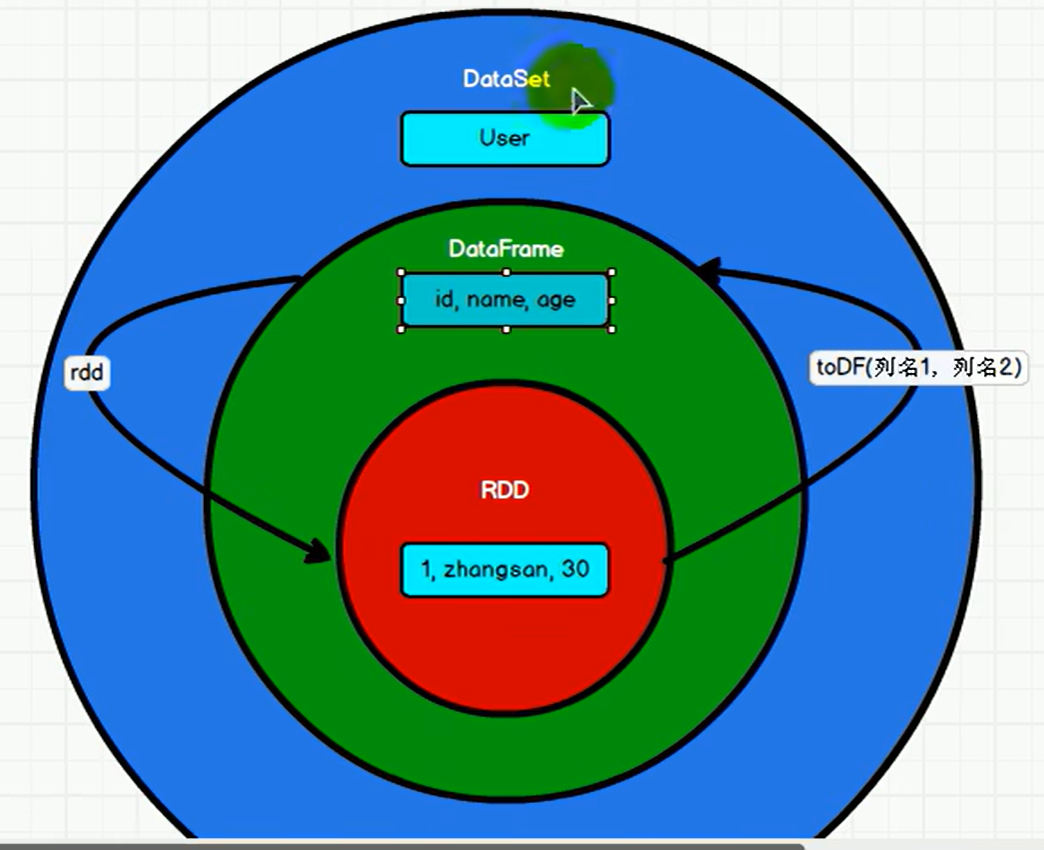
2.3 DataSet
DataSet是具有强类型的数据集合,需要提供对应的类型信息。
scala> case class Person(name: String, age: Long)
defined class Person
scala> val caseClassDS = Seq(Person("zhangsan",2)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
scala> caseClassDS.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 2|
+--------+---+
scala> val list = List(Person("zhangsan", 30), Person("lisi", 40))
list: List[Person] = List(Person(zhangsan,30), Person(lisi,40))
scala> list.to
to toDF toIterable toMap toSet toTraversable
toArray toDS toIterator toParArray toStream toVector
toBuffer toIndexedSeq toList toSeq toString
scala> list.toDS
res1: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
scala> val ds = list.toDS
ds: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
scala> ds.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 30|
| lisi| 40|
+--------+---+
scala>P161【161.尚硅谷_SparkSQL - 核心编程 - DataSet - DataFrame的转换】03:28

scala> val df = spark.read.json("input/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> df.createOrReplaceTempView("people")
scala> val sqlDF = spark.sql("SELECT * FROM people")
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> sqlDF.show
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
scala> sqlDF
res2: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> case class Emp(age:Long, username:String)
defined class Emp
scala> val ds = df.as[Emp]
ds: org.apache.spark.sql.Dataset[Emp] = [age: bigint, username: string]
scala> ds.show
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
scala> ds.
!= cube head queryExecution takeAsList
## describe hint randomSplit toDF
+ distinct inputFiles randomSplitAsList toJSON
-> drop intersect rdd toJavaRDD
== dropDuplicates intersectAll reduce toLocalIterator
agg dtypes isEmpty registerTempTable toString
alias encoder isInstanceOf repartition transform
apply ensuring isLocal repartitionByRange union
as eq isStreaming rollup unionAll
asInstanceOf equals javaRDD sample unionByName
cache except join schema unpersist
checkpoint exceptAll joinWith select wait
coalesce explain limit selectExpr where
col explode localCheckpoint show withColumn
colRegex filter map sort withColumnRenamed
collect first mapPartitions sortWithinPartitions withWatermark
collectAsList flatMap na sparkSession write
columns foreach ne sqlContext writeStream
count foreachPartition notify stat writeTo
createGlobalTempView formatted notifyAll storageLevel →
createOrReplaceGlobalTempView getClass observe summary
createOrReplaceTempView groupBy orderBy synchronized
createTempView groupByKey persist tail
crossJoin hashCode printSchema take
scala> ds.to
toDF toJSON toJavaRDD toLocalIterator toString
scala> ds.toDF
res4: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala>P162【162.尚硅谷_SparkSQL - 核心编程 - DataSet - RDD的转换】05:05

scala> val rdd = sc.makeRDD(List(Emp(10, "宋壹"), Emp(20, "dinger")))
rdd: org.apache.spark.rdd.RDD[Emp] = ParallelCollectionRDD[12] at makeRDD at <console>:26
scala> rdd.toDS
res5: org.apache.spark.sql.Dataset[Emp] = [age: bigint, username: string]
scala> val rdd = sc.makeRDD(List(1,2,3,4))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[13] at makeRDD at <console>:24
scala> rdd.toDS
res6: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> val ds = rdd.toDS
ds: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> val rdd = sc.makeRDD(List(Emp(10, "宋壹"), Emp(20, "dinger")))
rdd: org.apache.spark.rdd.RDD[Emp] = ParallelCollectionRDD[14] at makeRDD at <console>:26
scala> val ds = rdd.toDS
ds: org.apache.spark.sql.Dataset[Emp] = [age: bigint, username: string]
scala> val rdd1 = ds.rdd
rdd1: org.apache.spark.rdd.RDD[Emp] = MapPartitionsRDD[17] at rdd at <console>:25
scala>P163【163.尚硅谷_SparkSQL - 核心编程 - DataSet & DataFrame & RDD之间的关系】04:51
2.5 RDD、DataFrame、DataSet 三者的关系
- 2.5.1 三者的共性
- 2.5.2 三者的区别
- 2.5.3 三者的互相转换
P164【164.尚硅谷_SparkSQL - 核心编程 - IDEA创建SparkSQL环境对象】07:21
2.6 IDEA开发SparkSQL
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object Spark00_context {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// TODO 执行逻辑操作
// TODO 关闭环境
spark.close()
}
}P165【165.尚硅谷_SparkSQL - 核心编程 - IDEA - DataFrame基本操作】07:50
{"username": "宋壹", "age": 11}
{"username": "丁二", "age": 22}
{"username": "zhangsan", "age": 33}
{"username": "lisi", "age": 44}D:\Java\jdk1.8\jdk1.8.0_201\bin\java.exe ...
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
+--------+
|avg(age)|
+--------+
| 27.5|
+--------+
Process finished with exit code 0package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object Spark00_context {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// TODO 执行逻辑操作
// TODO DataFrame
val df: DataFrame = spark.read.json("datas/user.json")
df.show()
// DataFrame => SQL
df.createOrReplaceTempView("user")
spark.sql("select * from user").show
spark.sql("select age, username from user").show
spark.sql("select avg(age) from user").show
// DataFrame => DSL
// DataSet
// RDD <=> DataFrame
// DataFrame <=> DataSet
// RDD <=> DataSet
// TODO 关闭环境
spark.close()
}
}D:\Java\jdk1.8\jdk1.8.0_201\bin\java.exe ...
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
+---------+
|(age + 1)|
+---------+
| 12|
| 23|
| 34|
| 45|
+---------+
+---------+
|(age + 1)|
+---------+
| 12|
| 23|
| 34|
| 45|
+---------+
Process finished with exit code 0package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object Spark00_context {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// TODO 执行逻辑操作
// TODO DataFrame
val df: DataFrame = spark.read.json("datas/user.json")
// df.show()
// DataFrame => SQL
// df.createOrReplaceTempView("user")
// spark.sql("select * from user").show
// spark.sql("select age, username from user").show
// spark.sql("select avg(age) from user").show
// DataFrame => DSL
// 在使用DataFrame时,如果涉及到转换操作,需要引入转换规则
import spark.implicits._
df.select("age", "username").show
df.select($"age" + 1).show
df.select('age + 1).show
// DataSet
// RDD <=> DataFrame
// DataFrame <=> DataSet
// RDD <=> DataSet
// TODO 关闭环境
spark.close()
}
}P166【166.尚硅谷_SparkSQL - 核心编程 - IDEA - DataSet基本操作】03:18
D:\Java\jdk1.8\jdk1.8.0_201\bin\java.exe ...
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
| 4|
+-----+
Process finished with exit code 0package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object Spark00_context {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
// TODO 执行逻辑操作
// TODO DataFrame
// val df: DataFrame = spark.read.json("datas/user.json")
// df.show()
// DataFrame => SQL
// df.createOrReplaceTempView("user")
// spark.sql("select * from user").show
// spark.sql("select age, username from user").show
// spark.sql("select avg(age) from user").show
// DataFrame => DSL
// 在使用DataFrame时,如果涉及到转换操作,需要引入转换规则
// df.select("age", "username").show
// df.select($"age" + 1).show
// df.select('age + 1).show
// TODO DataSet
// DataFrame其实是特定泛型的DataSet
val seq = Seq(1, 2, 3, 4)
var ds: Dataset[Int] = seq.toDS()
ds.show()
// RDD <=> DataFrame
// DataFrame <=> DataSet
// RDD <=> DataSet
// TODO 关闭环境
spark.close()
}
}P167【167.尚硅谷_SparkSQL - 核心编程 - IDEA - RDD & DataFrame & DataSet互相转换】05:48
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object Spark01_SparkSQL_Basic {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
// TODO 执行逻辑操作
// TODO DataFrame
//val df: DataFrame = spark.read.json("datas/user.json")
//df.show()
// DataFrame => SQL
// df.createOrReplaceTempView("user")
//
// spark.sql("select * from user").show
// spark.sql("select age, username from user").show
// spark.sql("select avg(age) from user").show
// DataFrame => DSL
// 在使用DataFrame时,如果涉及到转换操作,需要引入转换规则
//df.select("age", "username").show
//df.select($"age" + 1).show
//df.select('age + 1).show
// TODO DataSet
// DataFrame其实是特定泛型的DataSet
//val seq = Seq(1,2,3,4)
//val ds: Dataset[Int] = seq.toDS()
//ds.show()
// RDD <=> DataFrame
val rdd = spark.sparkContext.makeRDD(List((1, "zhangsan", 30), (2, "lisi", 40)))
val df: DataFrame = rdd.toDF("id", "name", "age")
val rowRDD: RDD[Row] = df.rdd
// DataFrame <=> DataSet
val ds: Dataset[User] = df.as[User]
val df1: DataFrame = ds.toDF()
// RDD <=> DataSet
val ds1: Dataset[User] = rdd.map {
case (id, name, age) => {
User(id, name, age)
}
}.toDS()
val userRDD: RDD[User] = ds1.rdd
// TODO 关闭环境
spark.close()
}
case class User(id: Int, name: String, age: Int)
}P168【168.尚硅谷_SparkSQL - 核心编程 - IDEA - UDF函数】04:18
2.7 用户自定义函数
D:\Java\jdk1.8\jdk1.8.0_201\bin\java.exe ...
+---+--------------------+
|age|prefixName(username)|
+---+--------------------+
| 11| Name: 宋壹|
| 22| Name: 丁二|
| 33| Name: zhangsan|
| 44| Name: lisi|
+---+--------------------+
Process finished with exit code 0package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object Spark02_SparkSQL_UDF {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val df = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user")
spark.udf.register("prefixName", (name: String) => {
"Name: " + name
})
spark.sql("select age, prefixName(username) from user").show
// TODO 关闭环境
spark.close()
}
}P169【169.尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 实现原理】05:11
计算年龄平均值

P170【170.尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 弱类型函数实现】16:14
D:\Java\jdk1.8\jdk1.8.0_201\bin\java.exe ...
+--------------+
|myavgudaf(age)|
+--------------+
| 27|
+--------------+
Process finished with exit code 0package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}
object Spark03_SparkSQL_UDAF {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val df = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user")
spark.udf.register("ageAvg", new MyAvgUDAF())
spark.sql("select ageAvg(age) from user").show
// TODO 关闭环境
spark.close()
}
/*
自定义聚合函数类:计算年龄的平均值
1. 继承UserDefinedAggregateFunction
2. 重写方法(8)
*/
class MyAvgUDAF extends UserDefinedAggregateFunction {
// 输入数据的结构 : Int
override def inputSchema: StructType = {
StructType(
Array(
StructField("age", LongType)
)
)
}
// 缓冲区数据的结构 : Buffer
override def bufferSchema: StructType = {
StructType(
Array(
StructField("total", LongType),
StructField("count", LongType)
)
)
}
// 函数计算结果的数据类型:Out
override def dataType: DataType = LongType
// 函数的稳定性
override def deterministic: Boolean = true
// 缓冲区初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
//buffer(0) = 0L
//buffer(1) = 0L
buffer.update(0, 0L)
buffer.update(1, 0L)
}
// 根据输入的值更新缓冲区数据
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0, buffer.getLong(0) + input.getLong(0))
buffer.update(1, buffer.getLong(1) + 1)
}
// 缓冲区数据合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0, buffer1.getLong(0) + buffer2.getLong(0))
buffer1.update(1, buffer1.getLong(1) + buffer2.getLong(1))
}
// 计算平均值
override def evaluate(buffer: Row): Any = {
buffer.getLong(0) / buffer.getLong(1)
}
}
}P171【171.尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 强类型函数实现】10:58
D:\Java\jdk1.8\jdk1.8.0_201\bin\java.exe ...
+--------------+
|myavgudaf(age)|
+--------------+
| 25|
+--------------+
Process finished with exit code 0package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.{Aggregator, MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}
import org.apache.spark.sql.{Encoder, Encoders, Row, SparkSession, functions}
object Spark03_SparkSQL_UDAF1 {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val df = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user")
spark.udf.register("ageAvg", functions.udaf(new MyAvgUDAF()))
spark.sql("select ageAvg(age) from user").show
// TODO 关闭环境
spark.close()
}
/*
自定义聚合函数类:计算年龄的平均值
1. 继承org.apache.spark.sql.expressions.Aggregator, 定义泛型
IN : 输入的数据类型 Long
BUF : 缓冲区的数据类型 Buff
OUT : 输出的数据类型 Long
2. 重写方法(6)
*/
case class Buff(var total: Long, var count: Long)
class MyAvgUDAF extends Aggregator[Long, Buff, Long] {
// z & zero : 初始值或零值
// 缓冲区的初始化
override def zero: Buff = {
Buff(0L, 0L)
}
// 根据输入的数据更新缓冲区的数据
override def reduce(buff: Buff, in: Long): Buff = {
buff.total = buff.total + in
buff.count = buff.count + 1
buff
}
// 合并缓冲区
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.total = buff1.total + buff2.total
buff1.count = buff1.count + buff2.count
buff1
}
//计算结果
override def finish(buff: Buff): Long = {
buff.total / buff.count
}
// 缓冲区的编码操作
override def bufferEncoder: Encoder[Buff] = Encoders.product
// 输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}P172【172.尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 早期强类型函数实现】06:24

package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Dataset, Encoder, Encoders, SparkSession, TypedColumn, functions}
object Spark03_SparkSQL_UDAF2 {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val df = spark.read.json("datas/user.json")
// 早期版本中,spark不能在sql中使用强类型UDAF操作
// SQL & DSL
// 早期的UDAF强类型聚合函数使用DSL语法操作
val ds: Dataset[User] = df.as[User]
// 将UDAF函数转换为查询的列对象
val udafCol: TypedColumn[User, Long] = new MyAvgUDAF().toColumn
ds.select(udafCol).show
// TODO 关闭环境
spark.close()
}
/*
自定义聚合函数类:计算年龄的平均值
1. 继承org.apache.spark.sql.expressions.Aggregator, 定义泛型
IN : 输入的数据类型 User
BUF : 缓冲区的数据类型 Buff
OUT : 输出的数据类型 Long
2. 重写方法(6)
*/
case class User(username: String, age: Long)
case class Buff(var total: Long, var count: Long)
class MyAvgUDAF extends Aggregator[User, Buff, Long] {
// z & zero : 初始值或零值
// 缓冲区的初始化
override def zero: Buff = {
Buff(0L, 0L)
}
// 根据输入的数据更新缓冲区的数据
override def reduce(buff: Buff, in: User): Buff = {
buff.total = buff.total + in.age
buff.count = buff.count + 1
buff
}
// 合并缓冲区
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.total = buff1.total + buff2.total
buff1.count = buff1.count + buff2.count
buff1
}
//计算结果
override def finish(buff: Buff): Long = {
buff.total / buff.count
}
// 缓冲区的编码操作
override def bufferEncoder: Encoder[Buff] = Encoders.product
// 输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}P173【173.尚硅谷_SparkSQL - 核心编程 - IDEA - UDAF函数 - 课件梳理】03:23
2.7.2 UDAF
强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, 如 count(),countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。通过继承 UserDefinedAggregateFunction 来实现用户自定义弱类型聚合函数。从 Spark3.0 版本后,UserDefinedAggregateFunction 已经不推荐使用了,可以统一采用强类型聚合函数Aggregator。
P174【174.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 通用方法】06:36
2.8 数据的加载和保存
2.8.1 通用的加载和保存方式
SparkSQL提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL默认读取和保存的文件格式为parquet。
/opt/module/spark/spark-local/examples/src/main/resources/users.parquet
/examples/src/main/resources/users.parquet


{"username": "宋壹", "age": 11}
{"username": "丁二", "age": 22}
{"username": "zhangsan", "age": 33}
{"username": "lisi", "age": 44}[atguigu@node001 bin]$ ./spark-shell
23/06/12 14:23:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://node001:4040
Spark context available as 'sc' (master = local[*], app id = local-1686551043799).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark
res0: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@71120f9a
scala> spark.read
res1: org.apache.spark.sql.DataFrameReader = org.apache.spark.sql.DataFrameReader@141962b8
scala> spark.read.
csv format jdbc json load option options orc parquet schema table text textFile
scala> val df = spark.read.load("/opt/module/spark/spark-local/examples/src/main/resources/users.parquet")
df: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
scala> df.show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
scala> df.write.save("output")
scala> val df = spark.read.format("json").load("/opt/module/spark/spark-local/data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> df.write.save("/opt/module/spark/spark-local/data/output")
scala> val df = spark.read.format("json").load("/opt/module/spark/spark-local/data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> df.show
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
scala> val df = spark.read.json("/opt/module/spark/spark-local/data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> df.show
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
scala> df.write.save("/opt/module/spark/spark-local/data/output/output001")
scala> df.write.format("json").save("output/output002")
scala> df.write.format("json").save("/opt/module/spark/spark-local/data/output/output002")
scala> P175【175.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作JSON & CSV】08:30

scala> spark.sql("select * from json.'data/user.json'").show
org.apache.spark.sql.catalyst.parser.ParseException:
mismatched input ''data/user.json'' expecting {'ADD', 'AFTER', 'ALL', 'ALTER', 'ANALYZE', 'AND', 'ANTI', 'ANY', 'ARCHIVE', 'ARRAY', 'AS', 'ASC', 'AT', 'AUTHORIZATION', 'BETWEEN', 'BOTH', 'BUCKET', 'BUCKETS', 'BY', 'CACHE', 'CASCADE', 'CASE', 'CAST', 'CHANGE', 'CHECK', 'CLEAR', 'CLUSTER', 'CLUSTERED', 'CODEGEN', 'COLLATE', 'COLLECTION', 'COLUMN', 'COLUMNS', 'COMMENT', 'COMMIT', 'COMPACT', 'COMPACTIONS', 'COMPUTE', 'CONCATENATE', 'CONSTRAINT', 'COST', 'CREATE', 'CROSS', 'CUBE', 'CURRENT', 'CURRENT_DATE', 'CURRENT_TIME', 'CURRENT_TIMESTAMP', 'CURRENT_USER', 'DATA', 'DATABASE', DATABASES, 'DAY', 'DBPROPERTIES', 'DEFINED', 'DELETE', 'DELIMITED', 'DESC', 'DESCRIBE', 'DFS', 'DIRECTORIES', 'DIRECTORY', 'DISTINCT', 'DISTRIBUTE', 'DROP', 'ELSE', 'END', 'ESCAPE', 'ESCAPED', 'EXCEPT', 'EXCHANGE', 'EXISTS', 'EXPLAIN', 'EXPORT', 'EXTENDED', 'EXTERNAL', 'EXTRACT', 'FALSE', 'FETCH', 'FIELDS', 'FILTER', 'FILEFORMAT', 'FIRST', 'FOLLOWING', 'FOR', 'FOREIGN', 'FORMAT', 'FORMATTED', 'FROM', 'FULL', 'FUNCTION', 'FUNCTIONS', 'GLOBAL', 'GRANT', 'GROUP', 'GROUPING', 'HAVING', 'HOUR', 'IF', 'IGNORE', 'IMPORT', 'IN', 'INDEX', 'INDEXES', 'INNER', 'INPATH', 'INPUTFORMAT', 'INSERT', 'INTERSECT', 'INTERVAL', 'INTO', 'IS', 'ITEMS', 'JOIN', 'KEYS', 'LAST', 'LATERAL', 'LAZY', 'LEADING', 'LEFT', 'LIKE', 'LIMIT', 'LINES', 'LIST', 'LOAD', 'LOCAL', 'LOCATION', 'LOCK', 'LOCKS', 'LOGICAL', 'MACRO', 'MAP', 'MATCHED', 'MERGE', 'MINUTE', 'MONTH', 'MSCK', 'NAMESPACE', 'NAMESPACES', 'NATURAL', 'NO', NOT, 'NULL', 'NULLS', 'OF', 'ON', 'ONLY', 'OPTION', 'OPTIONS', 'OR', 'ORDER', 'OUT', 'OUTER', 'OUTPUTFORMAT', 'OVER', 'OVERLAPS', 'OVERLAY', 'OVERWRITE', 'PARTITION', 'PARTITIONED', 'PARTITIONS', 'PERCENT', 'PIVOT', 'PLACING', 'POSITION', 'PRECEDING', 'PRIMARY', 'PRINCIPALS', 'PROPERTIES', 'PURGE', 'QUERY', 'RANGE', 'RECORDREADER', 'RECORDWRITER', 'RECOVER', 'REDUCE', 'REFERENCES', 'REFRESH', 'RENAME', 'REPAIR', 'REPLACE', 'RESET', 'RESTRICT', 'REVOKE', 'RIGHT', RLIKE, 'ROLE', 'ROLES', 'ROLLBACK', 'ROLLUP', 'ROW', 'ROWS', 'SCHEMA', 'SECOND', 'SELECT', 'SEMI', 'SEPARATED', 'SERDE', 'SERDEPROPERTIES', 'SESSION_USER', 'SET', 'MINUS', 'SETS', 'SHOW', 'SKEWED', 'SOME', 'SORT', 'SORTED', 'START', 'STATISTICS', 'STORED', 'STRATIFY', 'STRUCT', 'SUBSTR', 'SUBSTRING', 'TABLE', 'TABLES', 'TABLESAMPLE', 'TBLPROPERTIES', TEMPORARY, 'TERMINATED', 'THEN', 'TO', 'TOUCH', 'TRAILING', 'TRANSACTION', 'TRANSACTIONS', 'TRANSFORM', 'TRIM', 'TRUE', 'TRUNCATE', 'TYPE', 'UNARCHIVE', 'UNBOUNDED', 'UNCACHE', 'UNION', 'UNIQUE', 'UNKNOWN', 'UNLOCK', 'UNSET', 'UPDATE', 'USE', 'USER', 'USING', 'VALUES', 'VIEW', 'VIEWS', 'WHEN', 'WHERE', 'WINDOW', 'WITH', 'YEAR', 'DIV', IDENTIFIER, BACKQUOTED_IDENTIFIER}(line 1, pos 19)
== SQL ==
select * from json.'data/user.json'
-------------------^^^
at org.apache.spark.sql.catalyst.parser.ParseException.withCommand(ParseDriver.scala:266)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:133)
at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:48)
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parsePlan(ParseDriver.scala:81)
at org.apache.spark.sql.SparkSession.$anonfun$sql$2(SparkSession.scala:604)
at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:604)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:601)
... 47 elided
scala> val path = "/opt/module/spark/spark-local/data"
path: String = /opt/module/spark/spark-local/data
scala> val peopleDF = spark.read.json(path)
java.lang.AssertionError: assertion failed: Conflicting directory structures detected. Suspicious paths:?
file:/opt/module/spark/spark-local/data/mllib/images/partitioned
file:/opt/module/spark/spark-local/data/mllib/images/origin/multi-channel
file:/opt/module/spark/spark-local/data/streaming
file:/opt/module/spark/spark-local/data/mllib/images
file:/opt/module/spark/spark-local/data/mllib/ridge-data
file:/opt/module/spark/spark-local/data
file:/opt/module/spark/spark-local/data/mllib
file:/opt/module/spark/spark-local/data/mllib/images/origin
file:/opt/module/spark/spark-local/data/output/output002
file:/opt/module/spark/spark-local/data/mllib/images/origin/kittens
file:/opt/module/spark/spark-local/data/mllib/als
file:/opt/module/spark/spark-local/data/graphx
file:/opt/module/spark/spark-local/data/output/output001
If provided paths are partition directories, please set "basePath" in the options of the data source to specify the root directory of the table. If there are multiple root directories, please load them separately and then union them.
at scala.Predef$.assert(Predef.scala:223)
at org.apache.spark.sql.execution.datasources.PartitioningUtils$.parsePartitions(PartitioningUtils.scala:172)
at org.apache.spark.sql.execution.datasources.PartitioningUtils$.parsePartitions(PartitioningUtils.scala:104)
at org.apache.spark.sql.execution.datasources.PartitioningAwareFileIndex.inferPartitioning(PartitioningAwareFileIndex.scala:158)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.partitionSpec(InMemoryFileIndex.scala:77)
at org.apache.spark.sql.execution.datasources.PartitioningAwareFileIndex.partitionSchema(PartitioningAwareFileIndex.scala:50)
at org.apache.spark.sql.execution.datasources.DataSource.getOrInferFileFormatSchema(DataSource.scala:154)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:401)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:279)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$2(DataFrameReader.scala:268)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:268)
at org.apache.spark.sql.DataFrameReader.json(DataFrameReader.scala:459)
at org.apache.spark.sql.DataFrameReader.json(DataFrameReader.scala:382)
... 47 elided
scala> val path = "/opt/module/spark/spark-local/data/user.json"
path: String = /opt/module/spark/spark-local/data/user.json
scala> val peopleDF = spark.read.json(path)
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> peopleDF.createOrReplaceTempView("people")
scala> spark.sql("select * from people).show
<console>:1: error: unclosed string literal
spark.sql("select * from people).show
^
scala> spark.sql("select * from people").show
+---+--------+
|age|username|
+---+--------+
| 11| 宋壹|
| 22| 丁二|
| 33|zhangsan|
| 44| lisi|
+---+--------+
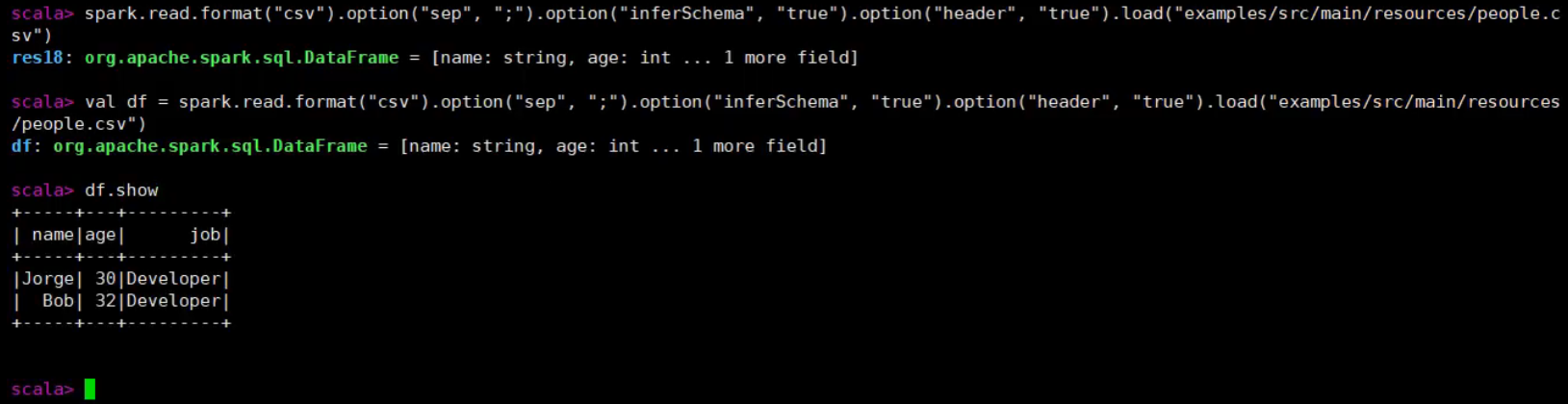
scala> 2.8.4 CSV
spark.read.format("csv").option("sep", ";").option("inferSchema", "true").option("header", "true").load("/opt/module/spark/spark-local/data/user.csv")
P176【176.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作MySQL】04:22
2.8.5 MySQL
Spark SQL 可以通过 JDBC 从关系型数据库中读取数据的方式创建 DataFrame,通过对 DataFrame 一系列的计算后,还可以将数据再写回关系型数据库中。如果使用 spark-shell 操作,可在启动 shell 时指定相关的数据库驱动路径或者将相关的数据库驱动放到 spark 的类路径下。
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql._
object Spark04_SparkSQL_JDBC {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
// 读取MySQL数据
val df = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://linux1:3306/spark-sql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123123")
.option("dbtable", "user")
.load()
//df.show
// 保存数据
df.write
.format("jdbc")
.option("url", "jdbc:mysql://linux1:3306/spark-sql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123123")
.option("dbtable", "user1")
.mode(SaveMode.Append)
.save()
// TODO 关闭环境
spark.close()
}
}P177【177.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作内置Hive】05:40
2.8.6 Hive
内置hive
scala> spark.sql("show tables").show
23/06/12 16:44:07 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
23/06/12 16:44:07 WARN HiveConf: HiveConf of name hive.stats.retries.wait does not exist
23/06/12 16:44:16 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 2.3.0
23/06/12 16:44:16 WARN ObjectStore: setMetaStoreSchemaVersion called but recording version is disabled: version = 2.3.0, comment = Set by MetaStore [email protected]
23/06/12 16:44:16 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
23/06/12 16:44:17 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| | people| true|
+--------+---------+-----------+
scala> spark.read.json("/opt/module/spark/spark-local/data/user.json")
res14: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> val df = spark.read.json("/opt/module/spark/spark-local/data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> df.createOrReplace
createOrReplaceGlobalTempView createOrReplaceTempView
scala> df.createOrReplaceTempView("user")
scala> spark.sql("show tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| | people| true|
| | user| true|
+--------+---------+-----------+
scala> spark.sql("create table atguigu(id int)")
23/06/12 17:26:21 WARN SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
23/06/12 17:26:21 WARN HiveConf: HiveConf of name hive.internal.ss.authz.settings.applied.marker does not exist
23/06/12 17:26:21 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
23/06/12 17:26:21 WARN HiveConf: HiveConf of name hive.stats.retries.wait does not exist
23/06/12 17:26:21 WARN HiveMetaStore: Location: file:/opt/module/spark/spark-local/bin/spark-warehouse/atguigu specified for non-external table:atguigu
res17: org.apache.spark.sql.DataFrame = []
scala> spark.sql("load data local inpath '/opt/module/spark/spark-local/data/id.txt' into table atguigu")
res18: org.apache.spark.sql.DataFrame = []
scala> spark.sql("show tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| default| atguigu| false|
| | people| true|
| | user| true|
+--------+---------+-----------+
scala> spark.sql("select * from atguigu").show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+
scala> P178【178.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 操作外置Hive】03:53
2.8.6 Hive
2)外部的 HIVE
如果想连接外部已经部署好的 Hive,需要通过以下几个步骤:
➢ Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
➢ 把 Mysql 的驱动 copy 到 jars/目录下
➢ 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
➢ 重启 spark-shell
scala> spark.sql("show tables").show
23/06/12 19:47:58 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
23/06/12 19:47:58 WARN HiveConf: HiveConf of name hive.stats.retries.wait does not exist
23/06/12 19:48:06 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 2.3.0
23/06/12 19:48:06 WARN ObjectStore: setMetaStoreSchemaVersion called but recording version is disabled: version = 2.3.0, comment = Set by MetaStore [email protected]
23/06/12 19:48:06 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
23/06/12 19:48:07 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
+--------+---------+-----------+
scala> P179【179.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - 代码操作外置Hive】04:28
2.8.6 Hive
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object Spark05_SparkSQL_Hive {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
// 使用SparkSQL连接外置的Hive
// 1.拷贝Hive-site.xml文件到classpath下
// 2.启用Hive的支持
// 3.增加对应的依赖关系(包含MySQL驱动)
spark.sql("show tables").show
// TODO 关闭环境
spark.close()
}
}P180【180.尚硅谷_SparkSQL - 核心编程 - 数据读取和保存 - beeline操作Hive】04:15
2.8.6 Hive
5)代码操作 Hive
加上这行代码:System.setProperty("HADOOP_USER_NAME", "root")。

4)运行 Spark beeline
[atguigu@node001 spark-local]$ bin/spark-sql
spark-sql> show tables;
[atguigu@node001 spark-local]$ bin/spark-shell
23/06/12 20:07:08 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://node001:4040
Spark context available as 'sc' (master = local[*], app id = local-1686571639816).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala> :quit
[atguigu@node001 spark-local]$ bin/spark-sql
23/06/12 20:07:37 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
log4j:WARN No appenders could be found for logger (org.apache.hadoop.hive.conf.HiveConf).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
23/06/12 20:07:39 INFO SharedState: spark.sql.warehouse.dir is not set, but hive.metastore.warehouse.dir is set. Setting spark.sql.warehouse.dir to the value of hive.metastore.warehouse.dir ('/user/hive/warehouse').
23/06/12 20:07:39 INFO SharedState: Warehouse path is '/user/hive/warehouse'.
23/06/12 20:07:39 INFO SessionState: Created HDFS directory: /tmp/hive/atguigu/1ecd1675-1b84-402c-8793-15292f010fdb
23/06/12 20:07:39 INFO SessionState: Created local directory: /tmp/atguigu/1ecd1675-1b84-402c-8793-15292f010fdb
23/06/12 20:07:39 INFO SessionState: Created HDFS directory: /tmp/hive/atguigu/1ecd1675-1b84-402c-8793-15292f010fdb/_tmp_space.db
23/06/12 20:07:39 INFO SparkContext: Running Spark version 3.0.0
23/06/12 20:07:39 INFO ResourceUtils: ==============================================================
23/06/12 20:07:39 INFO ResourceUtils: Resources for spark.driver:
23/06/12 20:07:39 INFO ResourceUtils: ==============================================================
23/06/12 20:07:39 INFO SparkContext: Submitted application: SparkSQL::192.168.10.101
23/06/12 20:07:39 INFO SecurityManager: Changing view acls to: atguigu
23/06/12 20:07:39 INFO SecurityManager: Changing modify acls to: atguigu
23/06/12 20:07:39 INFO SecurityManager: Changing view acls groups to:
23/06/12 20:07:39 INFO SecurityManager: Changing modify acls groups to:
23/06/12 20:07:39 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(atguigu); groups with view permissions: Set(); users with modify permissions: Set(atguigu); groups with modify permissions: Set()
23/06/12 20:07:40 INFO Utils: Successfully started service 'sparkDriver' on port 33186.
23/06/12 20:07:40 INFO SparkEnv: Registering MapOutputTracker
23/06/12 20:07:40 INFO SparkEnv: Registering BlockManagerMaster
23/06/12 20:07:40 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
23/06/12 20:07:40 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
23/06/12 20:07:40 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
23/06/12 20:07:40 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-b9ecb853-5270-407e-8e8c-4f8f9bc1bce8
23/06/12 20:07:40 INFO MemoryStore: MemoryStore started with capacity 366.3 MiB
23/06/12 20:07:40 INFO SparkEnv: Registering OutputCommitCoordinator
23/06/12 20:07:40 INFO Utils: Successfully started service 'SparkUI' on port 4040.
23/06/12 20:07:41 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://node001:4040
23/06/12 20:07:41 INFO Executor: Starting executor ID driver on host node001
23/06/12 20:07:41 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 37022.
23/06/12 20:07:41 INFO NettyBlockTransferService: Server created on node001:37022
23/06/12 20:07:41 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
23/06/12 20:07:41 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, node001, 37022, None)
23/06/12 20:07:41 INFO BlockManagerMasterEndpoint: Registering block manager node001:37022 with 366.3 MiB RAM, BlockManagerId(driver, node001, 37022, None)
23/06/12 20:07:41 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, node001, 37022, None)
23/06/12 20:07:41 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, node001, 37022, None)
23/06/12 20:07:41 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/opt/module/spark/spark-local/spark-warehouse').
23/06/12 20:07:41 INFO SharedState: Warehouse path is 'file:/opt/module/spark/spark-local/spark-warehouse'.
23/06/12 20:07:43 INFO HiveUtils: Initializing HiveMetastoreConnection version 2.3.7 using Spark classes.
23/06/12 20:07:43 INFO HiveClientImpl: Warehouse location for Hive client (version 2.3.7) is file:/opt/module/spark/spark-local/spark-warehouse
23/06/12 20:07:44 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
23/06/12 20:07:44 WARN HiveConf: HiveConf of name hive.stats.retries.wait does not exist
23/06/12 20:07:44 INFO HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore
23/06/12 20:07:44 INFO ObjectStore: ObjectStore, initialize called
23/06/12 20:07:44 INFO Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
23/06/12 20:07:44 INFO Persistence: Property datanucleus.cache.level2 unknown - will be ignored
23/06/12 20:07:46 INFO ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
23/06/12 20:07:49 INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY
23/06/12 20:07:49 INFO ObjectStore: Initialized ObjectStore
23/06/12 20:07:49 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 2.3.0
23/06/12 20:07:49 WARN ObjectStore: setMetaStoreSchemaVersion called but recording version is disabled: version = 2.3.0, comment = Set by MetaStore [email protected]
23/06/12 20:07:49 INFO HiveMetaStore: Added admin role in metastore
23/06/12 20:07:49 INFO HiveMetaStore: Added public role in metastore
23/06/12 20:07:49 INFO HiveMetaStore: No user is added in admin role, since config is empty
23/06/12 20:07:49 INFO HiveMetaStore: 0: get_all_functions
23/06/12 20:07:49 INFO audit: ugi=atguigu ip=unknown-ip-addr cmd=get_all_functions
23/06/12 20:07:49 INFO HiveMetaStore: 0: get_database: default
23/06/12 20:07:49 INFO audit: ugi=atguigu ip=unknown-ip-addr cmd=get_database: default
Spark master: local[*], Application Id: local-1686571661141
23/06/12 20:07:50 INFO SparkSQLCLIDriver: Spark master: local[*], Application Id: local-1686571661141
spark-sql> show tables;
23/06/12 20:08:34 INFO HiveMetaStore: 0: get_database: global_temp
23/06/12 20:08:34 INFO audit: ugi=atguigu ip=unknown-ip-addr cmd=get_database: global_temp
23/06/12 20:08:34 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
23/06/12 20:08:34 INFO HiveMetaStore: 0: get_database: default
23/06/12 20:08:34 INFO audit: ugi=atguigu ip=unknown-ip-addr cmd=get_database: default
23/06/12 20:08:34 INFO HiveMetaStore: 0: get_database: default
23/06/12 20:08:34 INFO audit: ugi=atguigu ip=unknown-ip-addr cmd=get_database: default
23/06/12 20:08:34 INFO HiveMetaStore: 0: get_tables: db=default pat=*
23/06/12 20:08:34 INFO audit: ugi=atguigu ip=unknown-ip-addr cmd=get_tables: db=default pat=*
Time taken: 4.021 seconds
23/06/12 20:08:34 INFO SparkSQLCLIDriver: Time taken: 4.021 seconds
spark-sql> [atguigu@node001 spark-local]$ sbin/start-thriftserver.sh
starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /opt/module/spark/spark-local/logs/spark-atguigu-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-node001.out
[atguigu@node001 spark-local]$ bin/beeline -u jdbc:hive2://node001:10000 -n root
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Connecting to jdbc:hive2://node001:10000
Connected to: Spark SQL (version 3.0.0)
Driver: Hive JDBC (version 2.3.7)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 2.3.7 by Apache Hive
0: jdbc:hive2://node001:10000> show databases;
+------------+
| namespace |
+------------+
| default |
+------------+
1 row selected (1.357 seconds)
0: jdbc:hive2://node001:10000> show tables;
+-----------+------------+--------------+
| database | tableName | isTemporary |
+-----------+------------+--------------+
+-----------+------------+--------------+
No rows selected (0.325 seconds)
0: jdbc:hive2://node001:10000> 第3章 SparkSQL项目实战
P181【181.尚硅谷_SparkSQL - 案例实操 - 数据准备】06:37
第3章 SparkSQL 项目实战
3.1 数据准备
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object Spark06_SparkSQL_Test {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("use atguigu")
// 准备数据
spark.sql(
"""
|CREATE TABLE `user_visit_action`(
| `date` string,
| `user_id` bigint,
| `session_id` string,
| `page_id` bigint,
| `action_time` string,
| `search_keyword` string,
| `click_category_id` bigint,
| `click_product_id` bigint,
| `order_category_ids` string,
| `order_product_ids` string,
| `pay_category_ids` string,
| `pay_product_ids` string,
| `city_id` bigint)
|row format delimited fields terminated by '\t'
""".stripMargin)
spark.sql(
"""
|load data local inpath 'datas/sqlData/user_visit_action.txt' into table atguigu.user_visit_action
""".stripMargin)
spark.sql(
"""
|CREATE TABLE `product_info`(
| `product_id` bigint,
| `product_name` string,
| `extend_info` string)
|row format delimited fields terminated by '\t'
""".stripMargin)
spark.sql(
"""
|load data local inpath 'datas/sqlData/product_info.txt' into table atguigu.product_info
""".stripMargin)
spark.sql(
"""
|CREATE TABLE `city_info`(
| `city_id` bigint,
| `city_name` string,
| `area` string)
|row format delimited fields terminated by '\t'
""".stripMargin)
spark.sql(
"""
|load data local inpath 'datas/sqlData/city_info.txt' into table atguigu.city_info
""".stripMargin)
spark.sql("""select * from city_info""").show
spark.close()
}
}P182【182.尚硅谷_SparkSQL - 案例实操 - 需求部分实现】12:56
3.2 需求:各区域热门商品Top3
3.2.1 需求简介这里的热门商品是从点击量的维度来看的,计算各个区域前三大热门商品,并备注上每个商品在主要城市中的分布比例,超过两个城市用其他显示。
select
*
from (
select
*,
rank() over( partition by area order by clickCnt desc ) as rank
from (
select
area,
product_name,
count(*) as clickCnt
from (
select
a.*,
p.product_name,
c.area,
c.city_name
from user_visit_action a
join product_info p on a.click_product_id = p.product_id
join city_info c on a.city_id = c.city_id
where a.click_product_id > -1
) t1 group by area, product_name
) t2
) t3 where rank <= 3package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object Spark06_SparkSQL_Test1 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("use atguigu")
spark.sql(
"""
|select
| *
|from (
| select
| *,
| rank() over( partition by area order by clickCnt desc ) as rank
| from (
| select
| area,
| product_name,
| count(*) as clickCnt
| from (
| select
| a.*,
| p.product_name,
| c.area,
| c.city_name
| from user_visit_action a
| join product_info p on a.click_product_id = p.product_id
| join city_info c on a.city_id = c.city_id
| where a.click_product_id > -1
| ) t1 group by area, product_name
| ) t2
|) t3 where rank <= 3
""".stripMargin).show
spark.close()
}
}P183【183.尚硅谷_SparkSQL - 案例实操 - 需求完整实现】26:54
3.2.2 需求分析
3.2.3 功能实现
同时操作多行快捷键:ctrl + alt + shift。
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.spark.sql.expressions.Aggregator
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
object Spark06_SparkSQL_Test2 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("use atguigu")
// 查询基本数据
spark.sql(
"""
| select
| a.*,
| p.product_name,
| c.area,
| c.city_name
| from user_visit_action a
| join product_info p on a.click_product_id = p.product_id
| join city_info c on a.city_id = c.city_id
| where a.click_product_id > -1
""".stripMargin).createOrReplaceTempView("t1")
// 根据区域,商品进行数据聚合
spark.udf.register("cityRemark", functions.udaf(new CityRemarkUDAF()))
spark.sql(
"""
| select
| area,
| product_name,
| count(*) as clickCnt,
| cityRemark(city_name) as city_remark
| from t1 group by area, product_name
""".stripMargin).createOrReplaceTempView("t2")
// 区域内对点击数量进行排行
spark.sql(
"""
| select
| *,
| rank() over( partition by area order by clickCnt desc ) as rank
| from t2
""".stripMargin).createOrReplaceTempView("t3")
// 取前3名
spark.sql(
"""
| select
| *
| from t3 where rank <= 3
""".stripMargin).show(false)
spark.close()
}
case class Buffer(var total: Long, var cityMap: mutable.Map[String, Long])
// 自定义聚合函数:实现城市备注功能
// 1. 继承Aggregator, 定义泛型
// IN : 城市名称
// BUF : Buffer =>【总点击数量,Map[(city, cnt), (city, cnt)]】
// OUT : 备注信息
// 2. 重写方法(6)
class CityRemarkUDAF extends Aggregator[String, Buffer, String] {
// 缓冲区初始化
override def zero: Buffer = {
Buffer(0, mutable.Map[String, Long]())
}
// 更新缓冲区数据
override def reduce(buff: Buffer, city: String): Buffer = {
buff.total += 1
val newCount = buff.cityMap.getOrElse(city, 0L) + 1
buff.cityMap.update(city, newCount)
buff
}
// 合并缓冲区数据
override def merge(buff1: Buffer, buff2: Buffer): Buffer = {
buff1.total += buff2.total
val map1 = buff1.cityMap
val map2 = buff2.cityMap
// 两个Map的合并操作
// buff1.cityMap = map1.foldLeft(map2) {
// case ( map, (city, cnt) ) => {
// val newCount = map.getOrElse(city, 0L) + cnt
// map.update(city, newCount)
// map
// }
// }
map2.foreach {
case (city, cnt) => {
val newCount = map1.getOrElse(city, 0L) + cnt
map1.update(city, newCount)
}
}
buff1.cityMap = map1
buff1
}
// 将统计的结果生成字符串信息
override def finish(buff: Buffer): String = {
val remarkList = ListBuffer[String]()
val totalcnt = buff.total
val cityMap = buff.cityMap
// 降序排列
val cityCntList = cityMap.toList.sortWith(
(left, right) => {
left._2 > right._2
}
).take(2)
val hasMore = cityMap.size > 2
var rsum = 0L
cityCntList.foreach {
case (city, cnt) => {
val r = cnt * 100 / totalcnt
remarkList.append(s"${city} ${r}%")
rsum += r
}
}
if (hasMore) {
remarkList.append(s"其他 ${100 - rsum}%")
}
remarkList.mkString(", ")
}
override def bufferEncoder: Encoder[Buffer] = Encoders.product
override def outputEncoder: Encoder[String] = Encoders.STRING
}
}P184【184.尚硅谷_SparkSQL - 总结 - 课件梳理】13:39
02_尚硅谷大数据技术之SparkSql.pdf