一、前言
本文总结常用树模型: rf,xgboost,catboost和lightgbm等模型的保存和加载(序列化和反序列化)的多种方式,并对多种方式从运行内存的使用和存储大小做对比
二、模型
2.1 安装环境
pip install xgboost
pip install lightgbm
pip install catboost
pip install scikit-learn可以指定版本也可以不指定,直接下载可获取最新的pkg
2.2 模型运行例子
针对iris数据集的多分类任务
import xgboost as xgb
from catboost import CatBoostClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)
# xgb
xgb_train = xgb.DMatrix(X_train, y_train)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_params = {'objective': 'multi:softmax', 'eval_metric': 'mlogloss', 'num_class': 3, 'verbosity': 0}
xgb_model = xgb.train(xgb_params, xgb_train)
y_pred = xgb_model.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
# lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {
'boosting_type': 'gbdt',
'objective': 'multiclass',
'num_class': 3,
'metric': 'multi_logloss',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9
}
gbm = lgb.train(params, lgb_train, num_boost_round=100, valid_sets=[lgb_eval], early_stopping_rounds=5)
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
y_pred = [list(x).index(max(x)) for x in y_pred]
lgb_acc = accuracy_score(y_test, y_pred)
# rf
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
rf_acc = accuracy_score(y_test, y_pred)
# catboost
cat_boost_model = CatBoostClassifier(depth=9, learning_rate=0.01,
loss_function='MultiClass', custom_metric=['AUC'],
eval_metric='MultiClass', random_seed=1996)
cat_boost_model.fit(X_train, y_train, eval_set=(X_test, y_test), use_best_model=True, early_stopping_rounds=1000)
y_pred = cat_boost_model.predict(X_test)
cat_acc = accuracy_score(y_test, y_pred)
print(xgb_acc, lgb_acc, rf_acc, cat_acc)2.3 运行内存计算
def cal_current_memory():
# 获取当前进程内存占用。
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory_used = info.uss / 1024. / 1024. / 1024.
return {
'memoryUsed': memory_used
}获取当前进程的pid,通过pid来定向查询memory的使用
三、保存和加载
主要有三种方法:
jsonpickle
pickle
模型api
3.1 jsonpickle
jsonpickle 是一个 Python 序列化和反序列化库,它可以将 Python 对象转换为 JSON 格式的字符串,或将 JSON 格式的字符串转换为 Python 对象。
调用jsonpickle.encode即可序列化,decode进行反序列化
以xgb为例
保存:
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)
# xgb
xgb_train = xgb.DMatrix(X_train, y_train)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_params = {'objective': 'multi:softmax', 'eval_metric': 'mlogloss', 'num_class': 3, 'verbosity': 0}
xgb_model = xgb.train(xgb_params, xgb_train)
y_pred = xgb_model.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
xgb_str = jsonpickle.encode(xgb_model)
with open(f'{save_dir}/xgb_model_jsonpickle.json', 'w') as f:
f.write(xgb_str)加载:
save_dir = './models'
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)
xgb_test = xgb.DMatrix(X_test, y_test)
with open(f'{save_dir}/xgb_model_jsonpickle.json', 'r') as f:
xgb_model_jsonpickle = f.read()
xgb_model_jsonpickle = jsonpickle.decode(xgb_model_jsonpickle)
y_pred = xgb_model_jsonpickle.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
print(xgb_acc)这样就完成了模型的保存和加载
优势
模型加载过程不需要重新实例化,直接jsonpickle.decode模型文件即可直接获得模型
获得的模型文件是json格式,便于各种编程语言和平台之间的数据交换,方便实现不同系统之间的数据传输和共享
劣势
在处理大型或者复杂的模型时,序列化过程可能会出现性能问题(占用更多的memory)
模型文件存储空间比较大
3.2 pickle
pickle 是 Python 的一种序列化和反序列化模块,可以将 Python 对象转换为字节流,也可以将字节流转换为 Python 对象,进而实现 Python 对象的持久化存储和恢复。(模型也是个对象)
调用pickle.dump/dumps即可序列化,pickle.load/loads进行反序列化(其中dump直接将序列化文件保存,二dumps则是返回序列化后的bytes文件,load和loads亦然)
这里可以查看和其他python方法的对比:https://docs.python.org/zh-cn/3/library/pickle.html
以xgb为例
保存:
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)
# xgb
xgb_train = xgb.DMatrix(X_train, y_train)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_params = {'objective': 'multi:softmax', 'eval_metric': 'mlogloss', 'num_class': 3, 'verbosity': 0}
xgb_model = xgb.train(xgb_params, xgb_train)
y_pred = xgb_model.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
with open(f'{save_dir}/xgb_model_pickle.pkl', 'wb') as f:
pickle.dump(xgb_model, f)加载:
save_dir = './models'
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)
xgb_test = xgb.DMatrix(X_test, y_test)
with open(f'{save_dir}/xgb_model_pickle.pkl', 'rb') as f:
xgb_model_pickle = pickle.load(f)
y_pred = xgb_model_pickle.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
print(xgb_acc)优势
模型加载过程同样不需要重新实例化,这点和jsonpickle一样
序列化文件相比于jsonpickle小非常的多,且读取和保存都会更快
劣势
在处理大型或者复杂的对象时,可能会出现性能问题(占用更多的memory)
不是json格式,很难跨平台和语言使用
3.3 模型自带
以xgb为例
保存
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)
# xgb
xgb_train = xgb.DMatrix(X_train, y_train)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_params = {'objective': 'multi:softmax', 'eval_metric': 'mlogloss', 'num_class': 3, 'verbosity': 0}
xgb_model = xgb.train(xgb_params, xgb_train)
y_pred = xgb_model.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
model_path = f'{save_dir}/xgb_model_self.bin' #也可以是json格式,但最终文件大小有区别
xgb_model.save_model(model_path)加载
save_dir = './models'
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_model_self = xgb.Booster()
xgb_model_self.load_model(f'{save_dir}/xgb_model_self.bin')
y_pred = xgb_model_self.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
print(xgb_acc)更多文档参考:https://xgboost.readthedocs.io/en/stable/tutorials/saving_model.html
优势
只保存了模型的参数文件(包含树结构和需要模型参数比如 the objective function等), 模型文件较小
序列化过程中的运行内存所占不多
也可以保存json的形式(在XGBoost 1.0.0之后推荐以json的方式保存)
劣势
需要在加载模型之前创建模型的实例。
四、实验
以下主要还是针对较小的模型来做的实验
4.1 模型存储大小对比实验
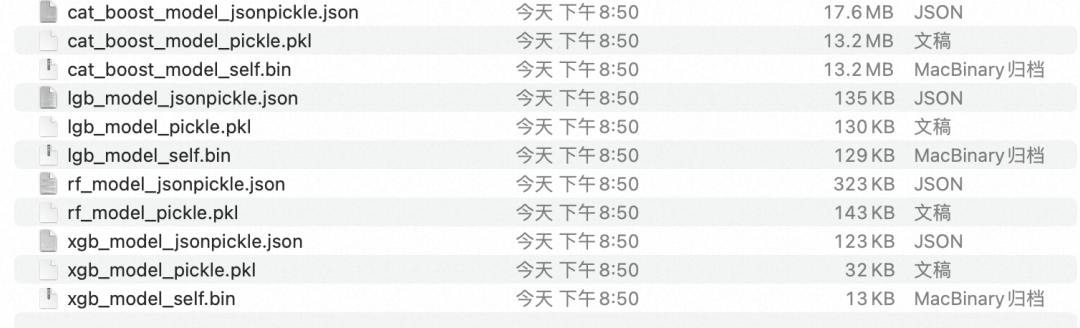
_jsonpickle就是用jsonpickle方法序列化的模型文件
_pickle是用pickle方法序列化的模型文件
_self就是利用自身的save model的方法保存的模型文件
可以看出来是 jsonpickle> pickle > self 的关系
4.2 运行的memory对比实验
通过对序列化前后的memory做监控,例如xgb(只考虑序列化,去掉文件写入所需要的memory):
print("before:", cal_current_memory())
model_path = f'{save_dir}/xgb_model_self.bin'
xgb_model.save_model(model_path)
print("after:", cal_current_memory())运行得到:
before: {'memoryUsed': 0.1490936279296875}
after: {'memoryUsed': 0.14911270141601562}print("before:", cal_current_memory())
pickle.dumps(xgb_model)
print("after:", cal_current_memory())运行得到:
before: {'memoryUsed': 0.1498260498046875}
after: {'memoryUsed': 0.14990234375}print("before:", cal_current_memory())
xgb_str = jsonpickle.encode(xgb_model)
print("after:", cal_current_memory())运行得到:
before: {'memoryUsed': 0.14917755126953125}
after: {'memoryUsed': 0.15140914916992188}可以看出来对于xgb模型,picklejson所需要的memory是其他两种方法的几十倍,而其余两种方法很相似
lgb的结果:
对应上述顺序:
self:
before: {'memoryUsed': 0.14953994750976562}
after {'memoryUsed': 0.14959716796875}
pickle:
before: {'memoryUsed': 0.14938735961914062}
after {'memoryUsed': 0.14946746826171875}
jsonpickle:
before: {'memoryUsed': 0.14945602416992188}
after {'memoryUsed': 0.14974594116210938}这里依然是jsonpickle大一些,但倍数小一些
catboost的结果:
self:
before: {'memoryUsed': 0.24615478515625}
after {'memoryUsed': 0.25492095947265625}
pickle:
before: {'memoryUsed': 0.2300567626953125}
after {'memoryUsed': 0.25820159912109375}
jsonpickle:
before: {'memoryUsed': 0.2452239990234375}
after {'memoryUsed': 0.272674560546875}4.3 序列化时间对比
因为catboost总体模型大小大一些,所以通过catboost才能更好的反应序列化的速度
self:
0.02413797378540039 s
pickle:
0.04681825637817383 s
jsonpickle:
0.3211638927459717 sjsonpickle的花费的时间会多一些
五、 总体代码
训练:
import base64
import json
import os
import pickle
import time
import jsonpickle
import psutil
import xgboost as xgb
from catboost import CatBoostClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
save_dir = "./models"
def cal_current_memory():
# 获取当前进程内存占用。
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory_used = info.uss / 1024. / 1024. / 1024.
return {
'memoryUsed': memory_used
}
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)
# xgb
xgb_train = xgb.DMatrix(X_train, y_train)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_params = {'objective': 'multi:softmax', 'eval_metric': 'mlogloss', 'num_class': 3, 'verbosity': 0}
xgb_model = xgb.train(xgb_params, xgb_train)
y_pred = xgb_model.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
#
# print("before:", cal_current_memory())
# model_path = f'{save_dir}/xgb_model_self.bin'
# xgb_model.save_model(model_path)
# print("after", cal_current_memory())
with open(f'{save_dir}/xgb_model_pickle.pkl', 'wb') as f:
pickle.dump(xgb_model, f)
print(cal_current_memory())
xgb_str = jsonpickle.encode(xgb_model)
with open(f'{save_dir}/xgb_model_jsonpickle.json', 'w') as f:
f.write(xgb_str)
print(cal_current_memory())
# lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {
'boosting_type': 'gbdt',
'objective': 'multiclass',
'num_class': 3,
'metric': 'multi_logloss',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9
}
gbm = lgb.train(params, lgb_train, num_boost_round=100, valid_sets=[lgb_eval], early_stopping_rounds=5)
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
y_pred = [list(x).index(max(x)) for x in y_pred]
lgb_acc = accuracy_score(y_test, y_pred)
#
# print("before:", cal_current_memory())
# model_path = f'{save_dir}/lgb_model_self.bin'
# gbm.save_model(model_path)
# print("after", cal_current_memory())
with open(f'{save_dir}/lgb_model_pickle.pkl', 'wb') as f:
pickle.dump(gbm, f)
lgb_str = jsonpickle.encode(gbm)
with open(f'{save_dir}/lgb_model_jsonpickle.json', 'w') as f:
f.write(lgb_str)
# rf
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
rf_acc = accuracy_score(y_test, y_pred)
with open(f'{save_dir}/rf_model_pickle.pkl', 'wb') as f:
pickle.dump(rf, f)
rf_str = jsonpickle.encode(rf)
with open(f'{save_dir}/rf_model_jsonpickle.json', 'w') as f:
f.write(rf_str)
# catboost
cat_boost_model = CatBoostClassifier(depth=9, learning_rate=0.01,
loss_function='MultiClass', custom_metric=['AUC'],
eval_metric='MultiClass', random_seed=1996)
cat_boost_model.fit(X_train, y_train, eval_set=(X_test, y_test), use_best_model=True, early_stopping_rounds=1000)
y_pred = cat_boost_model.predict(X_test)
cat_acc = accuracy_score(y_test, y_pred)
# t = time.time()
# model_path = f'{save_dir}/cat_boost_model_self.bin'
# cat_boost_model.save_model(model_path)
# print("after", time.time() - t)
# print("before:", cal_current_memory())
# model_path = f'{save_dir}/cat_boost_model_self.bin'
# cat_boost_model.save_model(model_path)
# print("after", cal_current_memory())
with open(f'{save_dir}/cat_boost_model_pickle.pkl', 'wb') as f:
pickle.dump(cat_boost_model, f)
cat_boost_model_str = jsonpickle.encode(cat_boost_model)
with open(f'{save_dir}/cat_boost_model_jsonpickle.json', 'w') as f:
f.write(cat_boost_model_str)
print(xgb_acc, lgb_acc, rf_acc, cat_acc)测试
import pickle
import jsonpickle
import psutil
import xgboost as xgb
from catboost import CatBoostClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
save_dir = './models'
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1996)
xgb_test = xgb.DMatrix(X_test, y_test)
xgb_model_self = xgb.Booster()
xgb_model_self.load_model(f'{save_dir}/xgb_model_self.bin')
y_pred = xgb_model_self.predict(xgb_test)
xgb_acc = accuracy_score(y_test, y_pred)
print(xgb_acc)
# with open(f'{save_dir}/xgb_model_pickle.pkl', 'rb') as f:
# xgb_model_pickle = pickle.load(f)
# y_pred = xgb_model_pickle.predict(xgb_test)
# xgb_acc = accuracy_score(y_test, y_pred)
# print(xgb_acc)
#
# with open(f'{save_dir}/xgb_model_jsonpickle.json', 'r') as f:
# xgb_model_jsonpickle = f.read()
# xgb_model_jsonpickle = jsonpickle.decode(xgb_model_jsonpickle)
# y_pred = xgb_model_jsonpickle.predict(xgb_test)
# xgb_acc = accuracy_score(y_test, y_pred)
# print(xgb_acc)ps:这里给出所有的代码,代码不多,但都写在一起了,比较粗糙,每个实验要记得把其他的对应代码注释掉。
六、总结
以上实验都是几次实验运行的结果的平均,如果想更有说服力,可以更多次实验取平均值来参考,整体的结果基本上没有差异。(还可以从更大的模型入手来讨论)
1. 对于图省事,并且想跨平台语言的话可以选择picklejson,但一定要有一定的memory预估,如果模型比较复杂比较大(可能一个模型class包含多种其他模型的对象),会占用非常大的memory,且模型文件也会非常大,但不需要对于每个单独的子模型做序列化,直接decode即可。
2. 对于要求省空间且运行内存的话,可以选择模型自身的保存方式(主要只保存模型参数文件),但对于这种方式,可能需要在模型的总class去实现序列化和反序列化方法(子模型都要实现,且每个都调用该模型的savemodel和loadmodel方法)
3. python下不考虑跨平台语言序列化和反序列可以直接考虑pickle的序列化方式,也比较省事。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书