前言
作为当前先进的深度学习目标检测算法YOLOv8,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv8的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv8,YOLOv7、YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他目标检测算法同样可以适用进行改进。希望能够对大家有帮助。
一、解决问题
这篇文章提出的方法主要用并行子网络代替一层层叠加。这有助于有效减少深度同时保持高性能。尝试用提出的方法改进目标检测算法中,提升目标检测效果。
二、基本原理
原文链接:2110.07641.pdf (arxiv.org)
代码链接:GitHub - imankgoyal/NonDeepNetworks: Official Code for "
原文摘要:深度是深度神经网络的标志。但是,更多的深度意味着更多的顺序计算和更高的延迟。这引出了一个问题:是否可能构建高性能的“非深度”神经网络?我们展示了这是可能的。为了做到这一点,我们使用并行子网络代替一层层叠加。这有助于有效减少深度同时保持高性能。通过利用并行子结构,我们首次展示了仅深度为12的网络可以在ImageNet上实现80%以上的top-1准确率,在CIFAR10上实现96%的准确率,在CIFAR100上实现81%的准确率。我们还展示了一个低深度(12)骨干网可以在MS-COCO上实现48%的AP。我们分析了我们设计的扩展规则,并展示了如何在不改变网络深度的情况下提高性能。最后,我们提供了一个概念验证,展示了如何使用非深度网络构建低延迟的识别系统。
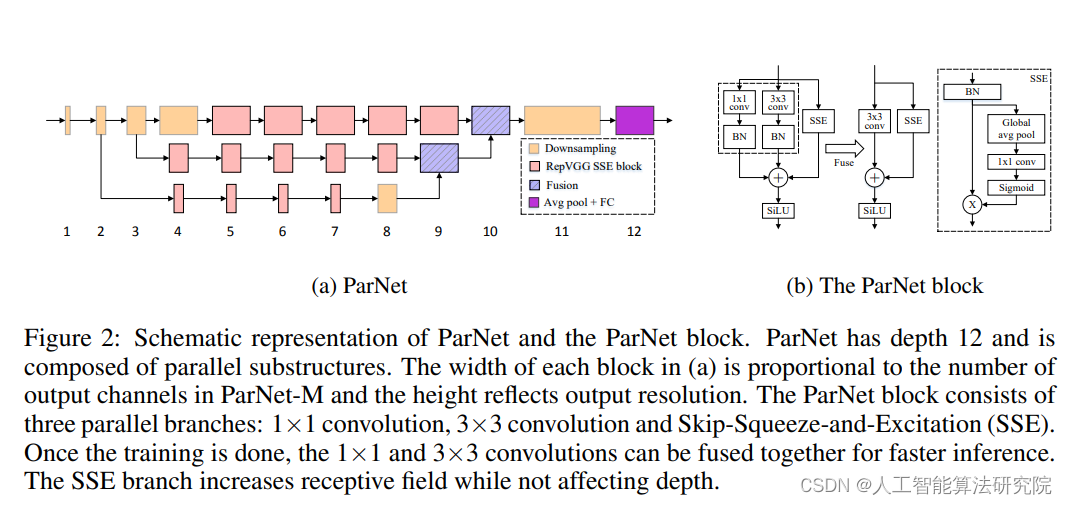
三、添加方法
原论文提出的部分参考源码如下所示:
class FeatureHookNet(nn.ModuleDict):
""" FeatureHookNet
Wrap a model and extract features specified by the out indices using forward/forward-pre hooks.
If `no_rewrite` is True, features are extracted via hooks without modifying the underlying
network in any way.
If `no_rewrite` is False, the model will be re-written as in the
FeatureList/FeatureDict case by folding first to second (Sequential only) level modules into this one.
FIXME this does not currently work with Torchscript, see FeatureHooks class
"""
def __init__(
self, model,
out_indices=(0, 1, 2, 3, 4), out_map=None, out_as_dict=False, no_rewrite=False,
feature_concat=False, flatten_sequential=False, default_hook_type='forward'):
super(FeatureHookNet, self).__init__()
assert not torch.jit.is_scripting()
self.feature_info = _get_feature_info(model, out_indices)
self.out_as_dict = out_as_dict
layers = OrderedDict()
hooks = []
if no_rewrite:
assert not flatten_sequential
if hasattr(model, 'reset_classifier'): # make sure classifier is removed?
model.reset_classifier(0)
layers['body'] = model
hooks.extend(self.feature_info.get_dicts())
else:
modules = _module_list(model, flatten_sequential=flatten_sequential)
remaining = {f['module']: f['hook_type'] if 'hook_type' in f else default_hook_type
for f in self.feature_info.get_dicts()}
for new_name, old_name, module in modules:
layers[new_name] = module
for fn, fm in module.named_modules(prefix=old_name):
if fn in remaining:
hooks.append(dict(module=fn, hook_type=remaining[fn]))
del remaining[fn]
if not remaining:
break
assert not remaining, f'Return layers ({remaining}) are not present in model'
self.update(layers)
self.hooks = FeatureHooks(hooks, model.named_modules(), out_map=out_map)
def forward(self, x):
for name, module in self.items():
x = module(x)
out = self.hooks.get_output(x.device)
return out if self.out_as_dict else list(out.values())改进后运行的网络层数以及参数如下所示,博主是在NWPU VHR-10遥感数据集进行训练测试,实验是有提升效果的。具体获取办法可私信获取改进后的YOLO项目百度链接。


四、总结
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!