2023 年第三届长三角高校数学建模竞赛题目
(请先阅读“长三角高校数学建模竞赛论文格式规范”)
B 题 长三角新能源汽车发展与双碳关系研究
《节能与新能源汽车技术路线图 2.0》提出至 2035 年,新能源汽车市场占比 超过 50%,燃料电池汽车保有量达到 100 万辆,节能汽车全面实现混合动力化, 汽车产业实现电动化转型的明确目标。这与国务院办公厅印发的《新能源汽车产 业发展规划(2021—2035 年)》的目标是一致的。有人测算,如果这一目标如期实 现,到 2035 年,我国新能源汽车保有量将达到 8000 万—1 亿辆,燃料电池汽车 达到 100 万辆。如今,新能源和新能源汽车两大产业的兴起,为实现国家从化石 能源为主导向可再生能源为主导转型的目标、为实现碳减排创造了两大先决条件: 上游有了以光电、风电为主的充足的可再生能源,下游有了可以大幅度消纳可再 生能源的新能源汽车。 上海发改委印发的《上海市 2023 年碳达峰碳中和及节能减排重点工作安排》 文件指出,严格控制煤炭消费总量,推动本地“光伏+”综合开发利用、杭州湾海 上风电建设、市外清洁电力通道建设,力争年内建成南通-崇明 500 千伏联网工 程。稳步提升海铁联运量,加快城市轨道交通、中运量公交系统等大容量公共交 通基础设施建设,推进新能源汽车发展,积极推进内河船舶电动化发展。 为加快构建绿色低碳循环的工业体系,切实做好工业领域碳达峰工作,近日 浙江省经济和信息化厅、浙江省发展和改革委员会、浙江省生态环境厅联合发布 《浙江省工业领域碳达峰实施方案》(以下简称《方案》)。在加大交通运输领域 绿色低碳产品供给方面,《方案》提出,大力推广节能与新能源汽车,强化整车 集成技术创新,提高新能源汽车产业集中度。加快充电桩建设及换电模式创新, 构建便利高效适度超前的充电网络体系。到 2025 年,新能源汽车产量力争达到
60 万辆。 长三角作为国内最早在新能源汽车这条赛道布局的区域之一,如今全国每三 辆新能源汽车,就有一辆产自长三角地区。新能源产业在长三角地区已产生集聚 发展效应,正如新能源产业集聚度城市排行榜所显示,前十的城市之中,有半数 城市来自长三角地区,前五十之中,有 26 座城市来自于华东地区。在利用新能 源汽车实现 "弯道超车" 的路上,长三角正一路 "狂飙"。 基于以上背景,请你们的团队收集相关数据,研究解决以下问题:
问题 1. 对长三角地区新能源汽车的发展情况进行分析,研究长三角地区新 能源汽车生产在全国新能源汽车市场的地位及作用,预测未来 3 年长三角地区新 能源汽车的市场保有量。
数据来源于: 国家统计局、工信部、新能源汽车协会
长三角历年数据:

各省汽车21年新能源数据: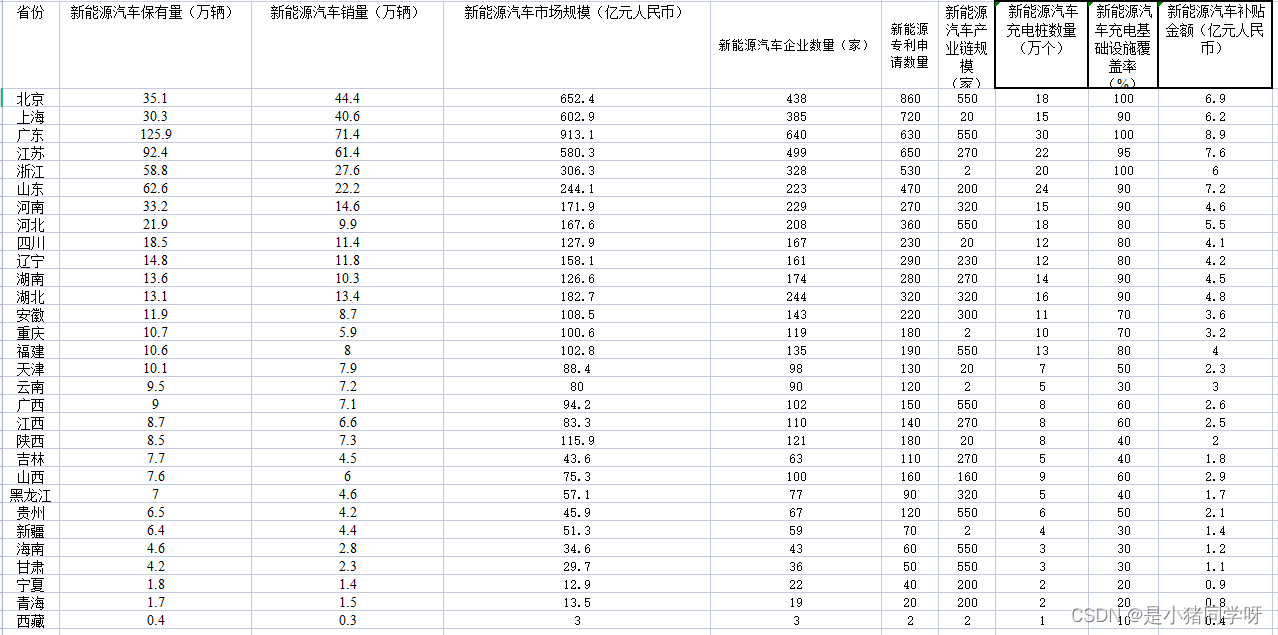
综合数据:
保有量对比:

市场占有率对比:


市场渗透率:


| 针对对长三角地区新能源汽车的发展情况进行分析和预测市场保有量的问题,可以采用时间序列分析和回归分析算法。以下是使用Python编程语言示例代码的一种方法: import pandas as pd import numpy as np from statsmodels.tsa.arima.model import ARIMA from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error # 导入长三角地区新能源汽车市场数据 data = pd.read_csv('data.csv') # 假设数据包含两列:年份和市场保有量 years = data['Year'] market_volume = data['Market Volume'] # 时间序列分析 - ARIMA 模型 model = ARIMA(market_volume, order=(1, 0, 0)) # 设置 ARIMA(p, d, q) 的参数 model_fit = model.fit() forecast = model_fit.predict(start=len(market_volume), end=len(market_volume) + 2) # 预测未来 3 年的市场保有量 # 回归分析 - 线性回归模型 X = years.values.reshape(-1, 1) y = market_volume.values.reshape(-1, 1) regression_model = LinearRegression() regression_model.fit(X, y) future_years = np.array([2024, 2025, 2026]).reshape(-1, 1) forecast_regression = regression_model.predict(future_years) # 输出预测结果 print("ARIMA 模型预测未来 3 年的市场保有量:") print(forecast) print("线性回归模型预测未来 3 年的市场保有量:") print(forecast_regression) 上述代码中,假设数据存储在名为 data.csv 的文件中,其中包含两列数据:年份(Year)和市场保有量(Market Volume)。通过读取数据文件,然后使用 ARIMA 模型进行时间序列分析,以预测未来 3 年的市场保有量。同时,还使用线性回归模型进行回归分析,以预测未来 3 年的市场保有量。最后,输出预测结果。 请注意,上述代码仅为示例,具体实现可能需要根据实际数据的结构和算法的参数进行适当调整。此外,还需要确保已经安装了相应的Python库(如pandas、statsmodels和scikit-learn),可以使用pip进行安装。 |
| 根据提供的信息,我们可以对长三角地区新能源汽车的发展情况进行分析。长三角地区是国内最早在新能源汽车领域进行布局的区域之一,目前全国每三辆新能源汽车就有一辆产自长三角地区。这表明长三角地区在新能源汽车生产方面具有一定的实力和影响力。 长三角地区的新能源汽车产业集聚效应显著,据新能源产业集聚度城市排行榜显示,前十的城市中有半数城市来自长三角地区,前五十中有26座城市来自华东地区。这说明长三角地区的新能源汽车产业具有较高的集聚度和规模化程度。 未来三年,长三角地区新能源汽车市场的保有量预计将继续增长。根据《节能与新能源汽车技术路线图 2.0》,到2035年新能源汽车市场占比将超过50%。同时,根据测算,如果这一目标如期实现,到2035年,我国新能源汽车保有量将达到8000万至1亿辆。考虑到长三角地区在新能源汽车生产方面的领先地位,预计未来三年长三角地区新能源汽车的市场保有量将会继续增长,具体的市场规模将取决于政策支持、市场需求和产业发展动态等因素。 需要注意的是,具体的市场保有量预测需要进一步的数据和分析支持。相关的统计数据、市场调研和行业报告可以提供更准确的预测结果。 建议您参考相关政府部门、行业协会、研究机构或专业咨询公司发布的报告和数据,以获取最准确、最新的关于长三角地区新能源汽车发展情况的数据和信息。这些来源通常会提供详细的市场数据、销售统计、产能情况等相关信息,可以更好地支持您的研究和分析。 可以尝试以下途径来获取长三角地区新能源汽车发展情况的行业报告和相关信息: 1. 政府部门网站:访问国家发展改革委员会、工业和信息化部、交通运输部等相关政府部门的官方网站,这些网站通常提供最新的政策文件、发展规划和统计数据。 2. 行业协会和研究机构:查找与新能源汽车产业相关的行业协会和研究机构,例如中国汽车工业协会、中国新能源汽车协会等。这些组织通常会发布行业报告、研究分析和数据统计,提供关于新能源汽车市场和发展趋势的详细信息。 3. 商业咨询公司:咨询公司如普华永道、德勤、麦肯锡等经常发布与新能源汽车相关的行业报告和市场研究。您可以访问它们的官方网站或搜索相关报告名称来获取相关信息。 通过以上途径,您应该能够找到可靠的行业报告和数据,以支持您对长三角地区新能源汽车发展情况的研究分析。 |
问题 2. 新能源汽车行业的快速发展,给传统燃油汽车带来了极大的挑战, 请研究我国新能源汽车与传统燃油汽车的市场竞争关系,分析该竞争关系受到哪 些因素的影响,给出我国新能源汽车和传统燃油汽车市场保有量随时间变化的演 化规律。
| 针对研究我国新能源汽车与传统燃油汽车的市场竞争关系和分析其受到的影响因素以及市场保有量的演化规律,可以使用回归分析和时间序列分析算法。以下是使用Python编程语言示例代码的一种方法: import pandas as pd import numpy as np from sklearn.linear_model import LinearRegression from statsmodels.tsa.seasonal import seasonal_decompose # 导入新能源汽车和传统燃油汽车市场数据 data = pd.read_csv('data.csv') # 假设数据包含三列:年份、新能源汽车市场保有量、传统燃油汽车市场保有量 years = data['Year'] new_energy_volume = data['New Energy Volume'] fuel_volume = data['Fuel Volume'] # 回归分析 - 线性回归模型 X = years.values.reshape(-1, 1) y = new_energy_volume.values.reshape(-1, 1) regression_model = LinearRegression() regression_model.fit(X, y) forecast_new_energy = regression_model.predict(X) # 时间序列分析 - 季节性分解 decomposition = seasonal_decompose(fuel_volume, period=12) trend = decomposition.trend seasonal = decomposition.seasonal residual = decomposition.resid # 输出预测结果 print("新能源汽车市场保有量随时间变化的演化规律:") print(forecast_new_energy) print("传统燃油汽车市场保有量随时间变化的演化规律(趋势分量):") print(trend) 上述代码中,假设数据存储在名为 data.csv 的文件中,其中包含三列数据:年份(Year)、新能源汽车市场保有量(New Energy Volume)和传统燃油汽车市场保有量(Fuel Volume)。通过读取数据文件,然后使用线性回归模型进行回归分析,以分析新能源汽车和传统燃油汽车的市场竞争关系,并预测新能源汽车市场保有量的演化规律。同时,使用季节性分解方法对传统燃油汽车市场保有量进行时间序列分析,提取趋势分量以揭示其演化规律。最后,输出预测结果。 请注意,上述代码仅为示例,具体实现可能需要根据实际数据的结构和算法的参数进行适当调整。此外,还需要确保已经安装了相应的Python库(如pandas、scikit-learn和statsmodels),可以使用pip进行安装。 |
| 分析上述问题可以采用多种算法和模型来进行研究和预测。以下是一些可能的算法和模型: 1. 时间序列分析:对市场保有量随时间变化的演化规律进行预测时,可以使用时间序列分析方法,如ARIMA(自回归滑动平均模型)、SARIMA(季节性自回归滑动平均模型)等。这些模型可以捕捉到时间序列数据中的趋势和季节性变化,用于预测未来的市场保有量。 2. 回归分析:研究新能源汽车与传统燃油汽车市场竞争关系时,可以采用回归分析方法来建立数学模型,考虑不同因素对市场份额的影响。通过回归分析,可以了解各个因素对竞争关系的影响程度,并进行预测和模拟。 3. 机器学习算法:机器学习算法可以用于构建预测模型,根据大量的历史数据进行训练,然后预测未来的市场保有量。常用的机器学习算法包括决策树、随机森林、支持向量机(SVM)和神经网络等。这些算法可以根据输入的特征和标签进行模式识别和预测分析。 4. 数据挖掘方法:利用数据挖掘方法,可以发现市场竞争关系中的隐藏模式和规律。例如,关联规则挖掘可以发现新能源汽车和传统燃油汽车之间的相关关系和购买模式。聚类分析可以将市场分成不同的群组,以了解不同群组内新能源汽车和传统燃油汽车的竞争情况。 以上仅列举了一些常见的算法和模型,实际选择使用哪种算法和模型取决于具体的数据、研究目标和可用资源。在进行分析之前,需要收集和整理相关数据,并根据问题的具体情况选择合适的方法和模型进行分析和预测。 新能源汽车的快速发展对传统燃油汽车产业带来了重大的挑战。以下是对我国新能源汽车与传统燃油汽车市场竞争关系的分析以及受到影响的因素: 竞争关系分析: 1. 政策环境:政府在推动新能源汽车发展方面采取了一系列的支持政策,如购车补贴、免征车辆购置税、充电基础设施建设等。这些政策鼓励了新能源汽车的销售和推广,形成了与传统燃油汽车竞争的优势。 2. 技术发展:新能源汽车的技术不断进步,尤其是电池技术和电动驱动技术的改进,使得新能源汽车在续航里程、充电速度和驾驶性能等方面有了显著提升。这些技术优势提升了新能源汽车的竞争力。 3. 环保需求:随着环境保护意识的增强,消费者对低碳排放和环保的需求日益增加。新能源汽车以其零排放或低排放的特点,在满足环保需求的同时吸引了一部分消费者。 4. 经济性:新能源汽车的运营成本相对较低,尤其是电动车的充电成本较传统燃油汽车的燃料成本更低廉。随着技术进步和规模效应的发挥,新能源汽车的价格也逐渐下降,增强了其在经济性方面的竞争力。 市场保有量演化规律: 随着新能源汽车的发展,预计未来的市场保有量将发生变化。以下是一般的演化规律: 1. 初始阶段:新能源汽车市场保有量相对较低,传统燃油汽车仍占据主导地位。这一阶段主要受政府政策的推动和示范效应的影响。 2. 高速增长阶段:随着新能源汽车技术的成熟和市场认可度的提高,新能源汽车市场保有量将快速增长。政府政策的支持和消费者对环保、经济性的需求将推动市场快速扩大。
当新能源汽车市场逐渐成熟并达到一定规模后,市场增长速度可能会趋于平稳。此阶段市场保有量的增长取决于多个因素: 1. 技术进步:随着新能源汽车技术的不断创新和进步,包括电池技术、充电技术和车辆性能的改善,新能源汽车的使用成本和实际性能将进一步提高,吸引更多消费者购买新能源汽车。 2. 价格竞争力:新能源汽车的价格随着技术成熟和规模效应的发挥而逐渐下降,使得新能源汽车与传统燃油汽车的价格差距缩小。更具竞争力的价格将促使更多消费者选择购买新能源汽车。 3. 充电基础设施建设:新能源汽车的发展需要健全的充电基础设施网络,包括公共充电桩和个人充电设施。充电基础设施的建设水平将直接影响新能源汽车的市场保有量,较完善的充电网络将进一步促进新能源汽车市场的发展。 4. 环境政策和标准:政府的环境政策和排放标准对新能源汽车市场保有量的增长起着重要作用。更严格的排放标准和环境政策将促使更多消费者选择新能源汽车,推动市场保有量的增长。 总体而言,随着技术进步、价格竞争力、充电基础设施和政策环境的改善,我国新能源汽车市场保有量有望逐渐增加。然而,具体的演化规律会受到多个因素的影响,包括政府政策导向、技术进步速度、消费者需求和经济发展状况等。因此,准确预测市场保有量的变化需要进一步的市场研究和数据支持。 |
问题 3. 新能源汽车的发展对双碳目标的实现具有积极推动作用,请研究新 能源汽车发展与双碳的关系,并对长三角地区碳达峰和碳中和的时间进行预测, 如有必要可结合其它相关因素。
| 研究新能源汽车发展与双碳目标的关系涉及多个因素,包括新能源汽车的市场普及程度、碳排放减少效果、能源结构转型等。预测长三角地区的碳达峰和碳中和的时间需要综合考虑多个相关因素,如政策支持力度、产业结构调整、能源消费结构转型等。以下是一种可能的研究方法和示例代码: 1. 收集相关数据:收集长三角地区的新能源汽车发展数据、碳排放数据、能源消费数据、政策文件等相关信息。 2. 数据分析与建模:使用统计分析和建模方法,如回归分析、时间序列分析、系统动力学建模等,对新能源汽车发展与碳排放之间的关系进行探索和建模。 3. 确定关键因素:通过分析建模结果和领域专家的意见,确定对长三角地区碳达峰和碳中和目标影响较大的关键因素。 4. 建立预测模型:根据确定的关键因素,建立预测模型,对长三角地区的碳达峰和碳中和时间进行预测。可以使用机器学习算法、时间序列分析方法或系统动力学模型等。 5. 模型评估与调整:对建立的预测模型进行评估,检验模型的准确性和可靠性。根据评估结果,进行必要的模型调整和优化。 以下是一个简化的示例代码,展示了使用线性回归模型对长三角地区碳达峰和碳中和时间进行预测的方法: import pandas as pd from sklearn.linear_model import LinearRegression # 导入相关数据 data = pd.read_csv('data.csv') # 假设数据包含三列:年份、碳排放量、新能源汽车保有量 years = data['Year'] carbon_emissions = data['Carbon Emissions'] new_energy_volume = data['New Energy Volume'] # 构建特征矩阵和目标向量 X = new_energy_volume.values.reshape(-1, 1) y = carbon_emissions.values.reshape(-1, 1) # 使用线性回归模型进行拟合 model = LinearRegression() model.fit(X, y) # 进行预测 future_new_energy_volume = [[1000000], [1500000], [2000000]] # 假设未来3年新能源汽车保有量 predicted_carbon_emissions = model.predict(future_new_energy_volume) # 输出预测结果 print("预测未来3年的碳排放量:") for i in range(len(future_new_energy_volume)): print(f"年份:{years.iloc[-1] + i |
| 如果使用时间序列预测方法来研究新能源汽车和传统燃油汽车市场保有量随时间变化的演化规律,可以考虑以下步骤来建立模型: 1. 数据收集和预处理:收集长期的时间序列数据,包括新能源汽车和传统燃油汽车市场保有量的历史数据。确保数据的完整性和一致性,处理缺失值或异常值。 2. 数据探索和可视化:对收集到的时间序列数据进行探索性分析,包括观察数据的趋势、季节性和周期性等特征。通过绘制折线图、自相关图和部分自相关图等可视化工具来了解数据的特点。 3. 时间序列模型选择:根据数据的特征和趋势,选择合适的时间序列模型。常用的模型包括移动平均模型(MA)、自回归模型(AR)、季节性模型(SAR)和自回归移动平均模型(ARMA)等。根据数据的季节性特征,还可以考虑季节性自回归移动平均模型(SARMA)或季节性自回归积分移动平均模型(SARIMA)。 4. 模型拟合和参数估计:根据选择的时间序列模型,拟合数据并估计模型的参数。使用最大似然估计、最小二乘法或其他相应的方法进行参数估计。 5. 模型诊断和评估:对拟合的时间序列模型进行诊断,检验其残差是否满足模型假设(如随机性、平稳性等)。可以使用残差分析、Ljung-Box检验等方法来评估模型的拟合效果。 6. 模型预测:使用已拟合的时间序列模型进行未来市场保有量的预测。根据模型的参数和历史数据,生成未来一段时间内的预测值。 以下是一个简化的示例代码,展示了使用ARIMA模型进行时间序列预测的方法: import pandas as pd # 导入时间序列数据 # 拟合ARIMA模型 # 进行未来3年的预测 |