【Jetson目标检测SSD-MobileNet应用实例】(一)win11中配置SSD-MobileNet网络训练境搭建
【Jetson目标检测SSD-MobileNet应用实例】(二)制作自己的数据集–数据集的采集、标注、预处理
【Jetson目标检测SSD-MobileNet应用实例】(三)训练自己的检测模型和推理测试
关于Jetson nano或者NX上的CSI摄像头接口,这里值得特殊说一句:希望获得最佳性能(较快的FPS,较高的分辨率和较少的CPU使用情况),或者需要对摄像机进行底层控制那么最好考虑使用CSI接口的摄像头。USB摄像头之所以能够免驱使用因为系统中通用的USBCamer驱动很大程度上屏蔽了硬件的差异性,对于较低层的摄像机属性操作起来不是很方便。
USB摄像头与CSI摄像头的对比
在Jetson开发者论坛中有这样一个关于USB和CSI的比较回答:
USB相机:
· 优:很容易整合。
· 优:可以做很多的离线的图像工作(曝光控制,帧率等)。
· 优:提供输入/中断功能,可为您节省计算应用程序时间(例如,在新帧上中断)。
· 优:可以长距离工作(最高可达USB标准)。
· 优:可以支持更大的图像传感器(1英寸或更高,以获得更好的图像质量和更少的噪音)。
· 缺:由于USB总线使用CPU时间,如果使用高的CPU占用,这会影响您的应用程序。
· 缺:对于使用硬件视觉管线(硬件编码器等)不是最佳的。
CSI相机:
· 优:根据CPU和内存使用情况进行优化,以便将图像处理并存入内存。
· 优:可以充分利用硬件的视觉管线。
· 优:可执行底层访问与控制传感器/摄像头。
· 缺:支持较短距离(通常不超过10cm)。除非您使用序列化系统(GMSL,FPD Link,COAXPress,Ambarella),但这些系统目前尚不成熟并且需要定制。
· 缺:通常与手机相机模块的小型传感器一样,要不就得多花点钱去定制。通过硬件去噪降低小传感器的额外噪音。
Jetson nano支持的CSI相机
参考官方wiki说明
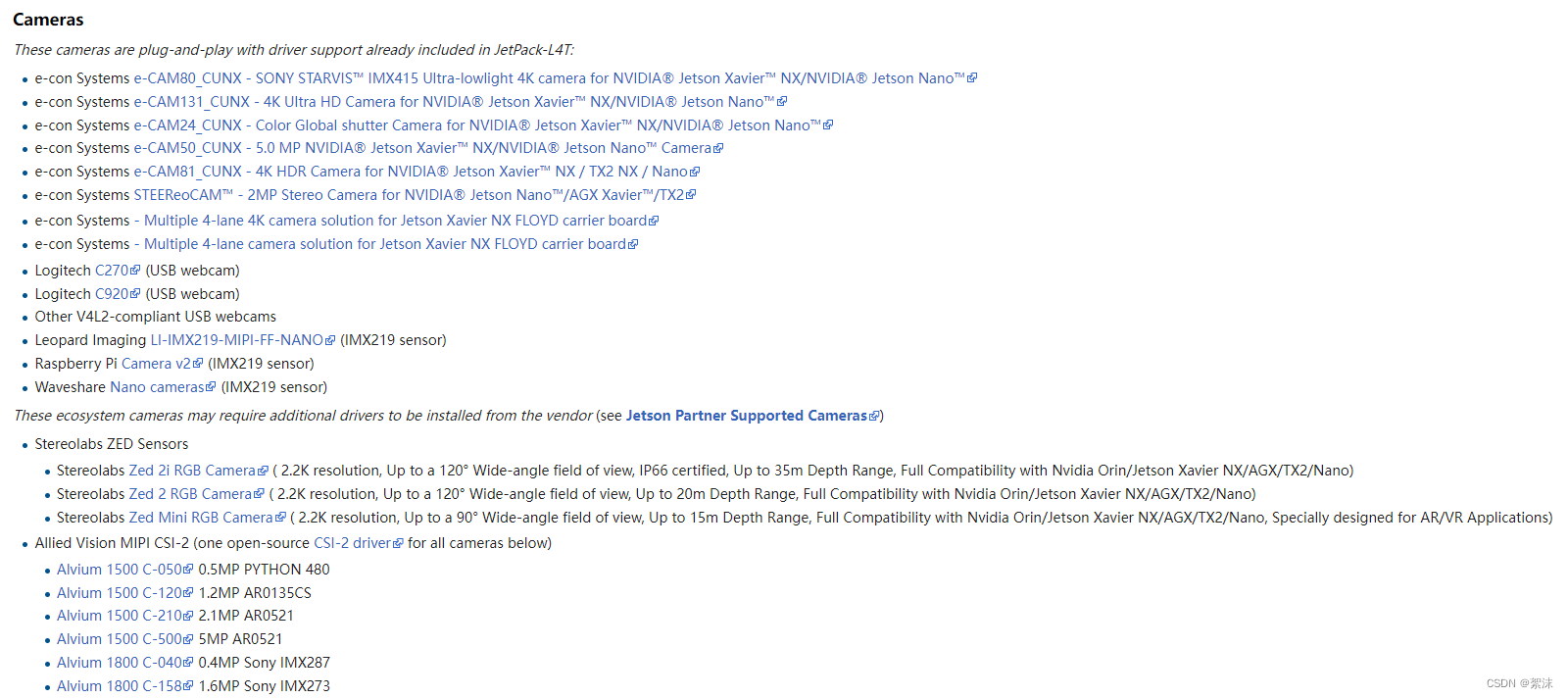
可以看到原版的IMX219树莓派摄像头也可以在这里使用。
使用CSI摄像头读取视频流
我们首先要使用CSI摄像头读取进视频流来供下一步操作。
在Jetson中CSI摄像头接到主板上之后不会被定义成camerx的摄像头,所以我们无法直接使用cap = cv2.VideoCapture(0)来读取摄像头数据。对应的我们要使用jetcam.csi_camera包来读取摄像头数据。
为了让CSI摄像头的数据读取之后能够被OPENCV读取使用,我们在编译OpenCV的时候需要打开GSTREAMER的编译选项,通过这个选项可以打开对CSI摄像头管道数据的接收。
对于完整的编译选项可以参考博客【CUDA加速DNN】【CSI摄像头】Jetson nano使用记录之源代码编译安装opencv4.5.1
那么我们测试一下摄像头:
import cv2
from jetcam.csi_camera import CSICamera
import numpy as np
camera1 = CSICamera(width=680, height=680,capture_width=320,capture_height=320,capture_fps=15)
while True:
image1 = camera1.read()
img = cv2.flip(image1, 0)
cv2.imshow("Output",img)
kk = cv2.waitKey(1)
if kk == ord('q'): # 按下 q 键,退出
break
CSICamera函数的入口参数分别是显示图像的长宽,读取图像的长宽,视频读取帧率。
这样对应的摄像头操作,在树莓派或者其设备上也可以:
cap = cv2.VideoCapture(0)
cap.set(3,1280)
cap.set(4,720)
cap.set(10,15)
通过定义cap对象的属性来操作。具体cap.set传入的第一个数字是对应图像的参数名对应序号(可以自己查阅opencv文档),第二个参数是该参数名要设置的的值。这里的cap.set(3,1280)是图像长1280像素,cap.set(4,720)图像宽720像素,cap.set(10,15)图像帧率为15。这个操作会占用一定的CPU资源,使用效果不是太好。
使用DNN模块读取模型和类名
我们最关注的就是如何使用DNN模块读取相关的模型文件并进行推理。
读取文件
classNames= []
classFile = 'coco.names'
with open(classFile,'rt') as f:
classNames = f.read().rstrip('\n').split('\n')
configPath = 'ssd_mobilenet_v3_large_coco_2020_01_14.pbtxt'
weightsPath = 'frozen_inference_graph.pb'
这里我们读取了和当前py脚本文件同路径下的三个文件,第一个是要识别的类名称,第二个是模型的描述文件,第三个是网络权重文件。
加载网络
net = cv2.dnn_DetectionModel(weightsPath,configPath)
net.setInputSize(320,320)
net.setInputScale(1.0/ 127.5)
net.setInputMean((127.5, 127.5, 127.5))
net.setInputSwapRB(True)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
这里我们使用dnn_DetectionModel函数读取了模型文件,下面接着的就是对模型的参数设置。
setInputSize:定义模型的输入图像尺寸,如果输入图像不符合这个尺寸会被自动缩放后输入图像,我们前面使用的预训练模型的输入大小就是320*320所以我们这里只能设置这个参数,这是由你训练的模型决定的。setInputScale:设置帧的缩放系数setInputMean:设置图像是三个通道的平均值setInputSwapRB:打开为帧设置SwapRB标志。(该标志表示交换第一个和最后一个通道,因为opencv读取的图像矩阵是BGR通道,我们采集训练用的图像是标准图像的RGB通道,所以要对调。)setPreferableBackend`setPreferableTarget`:用来使能CUDA进行前向推理,不打开这两句的话即使OpenCV编译时打开的CUDA支持,推理也只能使用CPU推理。
使用模型进行前向推理
推理的核心函数是:
classIds, confs, bbox = net.detect(img,confThreshold=thres)
- 这里传入的第一个参数是待识别图像,第二个参数是置信度阈值,低于这个置信度的预选框都会被过滤
- 返回三个列表,列表中一一对应上每个框的id,置信度,坐标
再加上NMS极大值抑制算法,剔除同一物体的重复识别框:
indices = cv2.dnn.NMSBoxes(bbox,confs,thres,nms_threshold)
- 这个函数的输入参数分别是预选框坐标、置信度、置信度阈值、nms抑制阈值
处理返回数据
由于数据类型的不同,我们要对数据做一些简单的处理,让他看起来更加接近于我们期望的可用效果。
for i in indices:
i = i[0]
box = bbox[i]
x,y,w,h = box[0],box[1],box[2],box[3]
cv2.rectangle(img, (x,y),(x+w,h+y), color=(0, 255, 0), thickness=2)
cv2.putText(img,classNames[classIds[i][0]-1].upper(),(box[0]+10,box[1]+30),
cv2.FONT_HERSHEY_COMPLEX,1,(0,255,0),2)
通过这样的操作后我们把所用识别到的物体的框和物体对应的名字就绘制的在了原始图像上。
完整推理代码
import cv2
from jetcam.csi_camera import CSICamera
import numpy as np
camera1 = CSICamera(width=680, height=680,capture_width=320,capture_height=320,capture_fps=15)
thres = 0.45 # Threshold to detect object
nms_threshold = 0.2
image1 = camera1.read()
classNames= []
classFile = 'coco.names'
with open(classFile,'rt') as f:
classNames = f.read().rstrip('\n').split('\n')
#print(classNames)
configPath = 'ssd_mobilenet_v3_large_coco_2020_01_14.pbtxt'
weightsPath = 'frozen_inference_graph.pb'
net = cv2.dnn_DetectionModel(weightsPath,configPath)
net.setInputSize(320,320)
net.setInputScale(1.0/ 127.5)
net.setInputMean((127.5, 127.5, 127.5))
net.setInputSwapRB(True)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
while True:
#success,img = cap.read()
image1 = camera1.read()
img = cv2.flip(image1, 0)
classIds, confs, bbox = net.detect(img,confThreshold=thres)
bbox = list(bbox)
confs = list(np.array(confs).reshape(1,-1)[0])
confs = list(map(float,confs))
#print(type(confs[0]))
#print(confs)
indices = cv2.dnn.NMSBoxes(bbox,confs,thres,nms_threshold)
#print(indices)
for i in indices:
i = i[0]
box = bbox[i]
x,y,w,h = box[0],box[1],box[2],box[3]
cv2.rectangle(img, (x,y),(x+w,h+y), color=(0, 255, 0), thickness=2)
cv2.putText(img,classNames[classIds[i][0]-1].upper(),(box[0]+10,box[1]+30),
cv2.FONT_HERSHEY_COMPLEX,1,(0,255,0),2)
cv2.imshow("Output",img)
kk = cv2.waitKey(1)
if kk == ord('q'): # 按下 q 键,退出
break
推理效果:

这里我随手检测了一些球,效果还是比较好的,都正确识别出来了。