一、平方损失函数(Quadratic Loss / MSELoss):
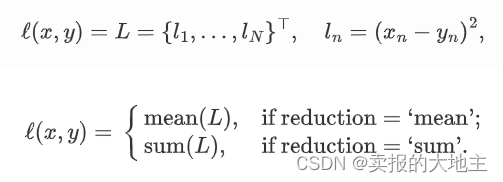
Pytorch实现:
from torch.nn import MSELoss
loss = nn.MSELoss(reduction="none")
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
nn.MSELoss()参数如下:
size_average(bool,optional):已弃用(参见::attr:reduction)。默认情况下,损失在批处理中的每个损失元素上进行平均。请注意,对于某些损失,每个样本可能有多个元素。如果将字段:attr:size_average设置为“False”,则损失将改为对每个小批量进行求和。当:attr:reduce为“False”时,忽略该参数。默认值:Truereduce(bool,optional):已弃用(参见::attr:reduction)。默认情况下,损失在每个小批量的观察结果上进行平均或求和,具体取决于:attr:size_average。当:attr:reduce为“False”时,返回每个批次元素的损失,忽略:attr:size_average。默认值:Truereduction(str,optional):指定要应用于输出的减少方法:“none”|“mean”|“sum”。“none”:不应用任何减少,“mean”:输出的总和将除以输出中的元素数,“sum”:输出将被求和。注意::attr:size_average和:attr:reduce正在被弃用,在此期间,指定这两个参数中的任何一个将覆盖:attr:reduction。默认值:'mean'。
二、交叉熵损失函数(cross-entropy loss)
- 二分类交叉熵损失函数
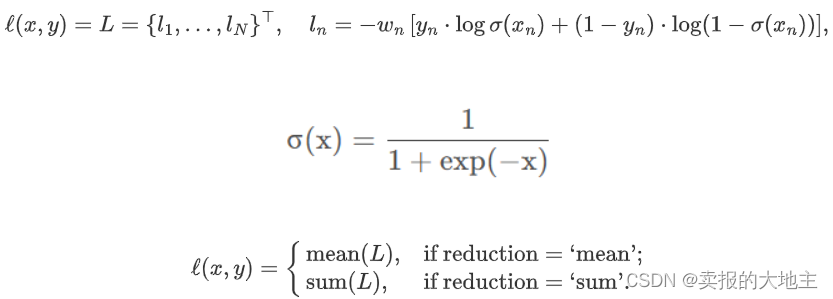
Pytorch实现:
from torch.nn import BCEWithLogitsLoss
target = torch.ones([10, 64], dtype=torch.float32) # 64 classes, batch size = 10
output = torch.full([10, 64], 1.5) # A prediction (logit)
pos_weight = torch.ones([64]) # All weights are equal to 1
criterion = torch.nn.BCEWithLogitsLoss(pos_weight=pos_weight)
criterion(output, target) # -log(sigmoid(1.5))
nn.BCEWithLogitsLoss()参数如下:
weight (Tensor, optional):对每个类别进行手动重新缩放的权重。如果给定,则必须是大小为C的张量。否则,将视为所有权重均为1。size_average (bool, optional):已弃用(参见:attr:reduction)。默认情况下,损失将在批处理中的每个损失元素上进行平均。请注意,对于某些损失,每个样本中可能有多个元素。如果将属性:attr:size_average设置为“False”,则对于每个小批量,损失将被求和而不是平均。当:attr:reduce为“False”时,此属性被忽略。默认值:Noneignore_index (int, optional): 指定要忽略的目标值,并且不会对输入梯度产生贡献。当:attr:size_average为True时,将对未被忽略的目标进行平均损失。reduce (bool, optional):已弃用(参见:attr:reduction)。默认情况下,将对每个小批量的观察结果进行平均或求和,具体取决于:attr:size_average。当:attr:reduce为False时,返回每个批处理元素的损失,并忽略:attr:size_average。默认值:Nonereduction (str, optional):指定要应用于输出的减少方式:'none'|'mean'|'sum'。'none': 不会应用任何减少方式,'mean': 取输出的加权平均值,'sum': 输出将被求和。注意: :attr:size_average和:attr:reduce正在被弃用,与此同时,指定这两个参数中的任何一个都将覆盖:attr:reduction。默认值:'mean'。pos_weight (Tensor, optional):用于指定正样本的权重。它必须是一个长度等于类别数的向量。
Note1:BCEWithLogitsLoss与BCELoss不同在于,前者对target进行了sigmoid()计算,以实现LogSumExp的技巧,达到数值稳定的优势。
Note2:pos_weight参数用于指定正样本的权重,其作用是在处理类别不平衡问题时对于正样本给予更高的权重,以此来平衡类别的数量。默认情况下,所有的类别都被视为同等重要,即每个类别的权重都为1。如果某个类别的数量比其他类别更少,可以通过设置pos_weight参数来给予该类别更高的权重。pos_weight是一个长度为类别数的向量,每个元素表示对应类别的权重,当一个类别的权重被设置为大于1的值时,该类别对损失函数的贡献将会变得更加重要。
- 多分类交叉熵损失函数:
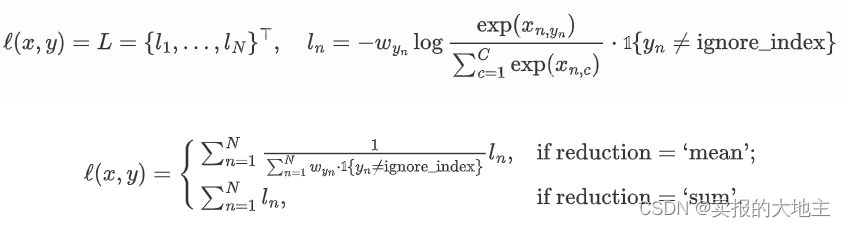
Pytorch实现:
from torch.nn import CrossEntropyLoss
loss = nn.CrossEntropyLoss()
# Example of target with class indices
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(input, target)
nn.CrossEntropyLoss()参数如下:
-
weight (Tensor, optional):对每个类别手动重新缩放的权重。如果给出,必须是大小为C的张量。 -
size_average (bool, optional):已弃用(请参见 :attr:reduction)。默认情况下,每个批次中的损失会被平均。注意,对于某些损失,每个样本可能有多个元素。如果将 :attr:size_average设置为“False”,则每个小批量的损失将被累加。当 :attr:reduce为“False”时被忽略。默认值:True -
ignore_index (int, optional):指定要忽略的目标值,不会对输入梯度产生贡献。当 :attr:size_average为True时,损失将在未忽略的目标上进行平均。注意,仅当目标包含类别索引时,:attr:ignore_index才适用。 -
reduce (bool, optional):已弃用(请参见 :attr:reduction)。默认情况下,损失根据 :attr:size_average对每个小批量的观察结果进行平均或求和。当 :attr:reduce为“False”时,返回每个批次元素的损失,忽略 :attr:size_average。默认值:True -
reduction (str, optional):指定要应用于输出的缩减方式:'none'|'mean'|'sum'。'none':不应用缩减,'mean':取输出的加权平均值,'sum':将输出求和。注意::attr:size_average和 :attr:reduce正在被弃用,同时指定这两个参数之一将覆盖 :attr:reduction。默认值:'mean' -
label_smoothing (float, optional):在计算损失时使用的平滑量,取值范围为 [0.0,1.0],其中 0.0 表示不平滑。目标变成原始标签和均匀分布的混合,如 Rethinking the Inception Architecture for Computer Vision中所述。默认值::math:0.0。
Note1:Pytorch中CrossEntropyLoss()函数的主要是将softmax-log-NLLLoss合并到一块得到的结果。
Softmax后的数值都在0~1之间,所以ln之后值域是负无穷到0。- 然后将
Softmax之后的结果取log,使得乘法改成加法减少计算量,同时保障函数的单调性 。 - 进行
NLLLoss计算。
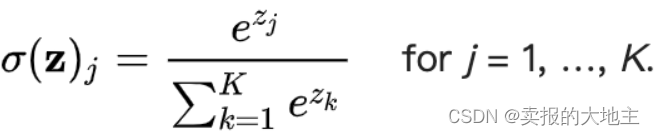
Note2:label_smoothing 是一种在计算交叉熵损失时用于减少过度自信的技术。在训练分类器时,通常将标签视为单热向量,即只有正确的类别概率为1,其余为0。然而,这种做法会导致模型对于预测的类别非常自信,即使预测概率分布与实际分布相差很远。为了缓解这个问题,可以使用标签平滑技术。在标签平滑技术中,将正确标签的概率从 1 降低到 1-ε,同时将错误标签的概率从 0 提高到 ε/(C-1),其中 C 是类别数量。这样可以使得正确标签对于预测分布的影响减小,让模型更加谨慎,同时也可以避免过度拟合于训练集上的噪声。
在 nn.CrossEntropyLoss 中,可以使用 label_smoothing 参数来指定标签平滑的强度,范围是 0 到 1。默认情况下,不进行标签平滑,即 label_smoothing=0。
在BCEWithLogitsLoss中并未实现label_smoothing、ignore_index,我们可以自己实现,参考pytorch-toolbelt:
from typing import Optional
import torch
import torch.nn.functional as F
from torch import nn, Tensor
class SoftBCEWithLogitsLoss(nn.Module):
__constants__ = [
"weight",
"pos_weight",
"reduction",
"ignore_index",
"smooth_factor",
]
def __init__(
self,
weight: Optional[torch.Tensor] = None,
ignore_index: Optional[int] = -100,
reduction: str = "mean",
smooth_factor: Optional[float] = None,
pos_weight: Optional[torch.Tensor] = None,
):
"""Drop-in replacement for torch.nn.BCEWithLogitsLoss with few additions: ignore_index and label_smoothing
Args:
ignore_index: Specifies a target value that is ignored and does not contribute to the input gradient.
smooth_factor: Factor to smooth target (e.g. if smooth_factor=0.1 then [1, 0, 1] -> [0.9, 0.1, 0.9])
Shape
- **y_pred** - torch.Tensor of shape NxCxHxW
- **y_true** - torch.Tensor of shape NxHxW or Nx1xHxW
"""
super().__init__()
self.ignore_index = ignore_index
self.reduction = reduction
self.smooth_factor = smooth_factor
self.register_buffer("weight", weight)
self.register_buffer("pos_weight", pos_weight)
def forward(self, y_pred: torch.Tensor, y_true: torch.Tensor) -> torch.Tensor:
"""
Args:
y_pred: torch.Tensor of shape (N, C, H, W)
y_true: torch.Tensor of shape (N, H, W) or (N, 1, H, W)
Returns:
loss: torch.Tensor
"""
if self.smooth_factor is not None:
soft_targets = (1 - y_true) * self.smooth_factor + y_true * (1 - self.smooth_factor)
else:
soft_targets = y_true
loss = F.binary_cross_entropy_with_logits(
y_pred,
soft_targets,
self.weight,
pos_weight=self.pos_weight,
reduction="none",
)
if self.ignore_index is not None:
not_ignored_mask = y_true != self.ignore_index
loss *= not_ignored_mask.type_as(loss)
if self.reduction == "mean":
loss = loss.mean()
if self.reduction == "sum":
loss = loss.sum()
return loss