I. 介绍
Stable Diffusion模型(稳定扩散模型)
是一种用于生成式建模的深度学习模型,它使用随机微分方程(SDE)来建模连续时间的动态过程。在图像、声音、文本等各种领域都有广泛的应用。与传统的生成式模型相比,Stable Diffusion模型能够生成更加高质量的样本。其原理是通过对随机微分方程进行离散化,将连续时间的过程转换为离散时间的过程,然后通过反向传播算法进行求解。
Google Colab
是一种基于云端的Jupyter笔记本环境,它提供了免费的GPU和TPU资源,使得深度学习训练变得更加便捷和高效。Colab可以直接在浏览器中运行,不需要单独安装任何软件,用户只需上传自己的代码和数据即可开始训练深度学习模型。Colab所提供的免费GPU和TPU资源,可以大幅缩短训练时间,并且不会消耗本地计算机的性能资源,大大降低了深度学习开发者的成本和门槛。
II. 准备工作
1:一个谷歌账号。注册地址
2:一个github账号。注册地址
3:一个Hugging Face账号。注册地址
4:准备好魔法梯子
III. 拉取Stable_Diffusion_WebUi_Altryne(云版带UI)
到这里,AI绘画门槛又又又降低了,从最开始需要花半天时间折腾的 Disco-Diffusion ,紧接着 Stable Diffusion 在 github 上开源,各家平台都推出了云平台,让用户通过轻松的点击、选择、输入就能生成一张张AI图。
再到现在!!!使用 webui 在 github 上开源了,不仅有手动教程、docker 教程,还有 Colab 傻瓜式的集成方案。
webui github 地址: https://github.com/sd-webui/sta
IV. 平台搭建
今天就来交大家如果来搭建和使用这个云平台。
第一步: 打开链接
初始化打开Google Colab官网地址

使用你的谷歌账号进行登录,登录后访问下面这个链接导入Jupyter Notebook
导入后效果为
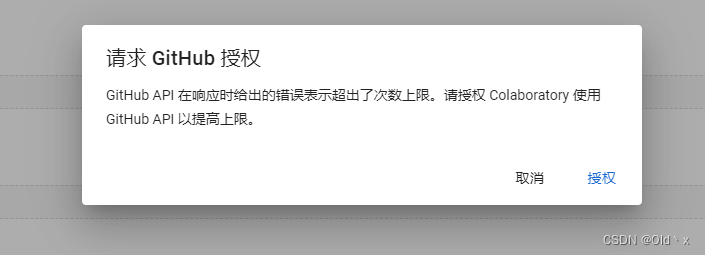
如遇无法导入,请配置github账号并给予对应权限
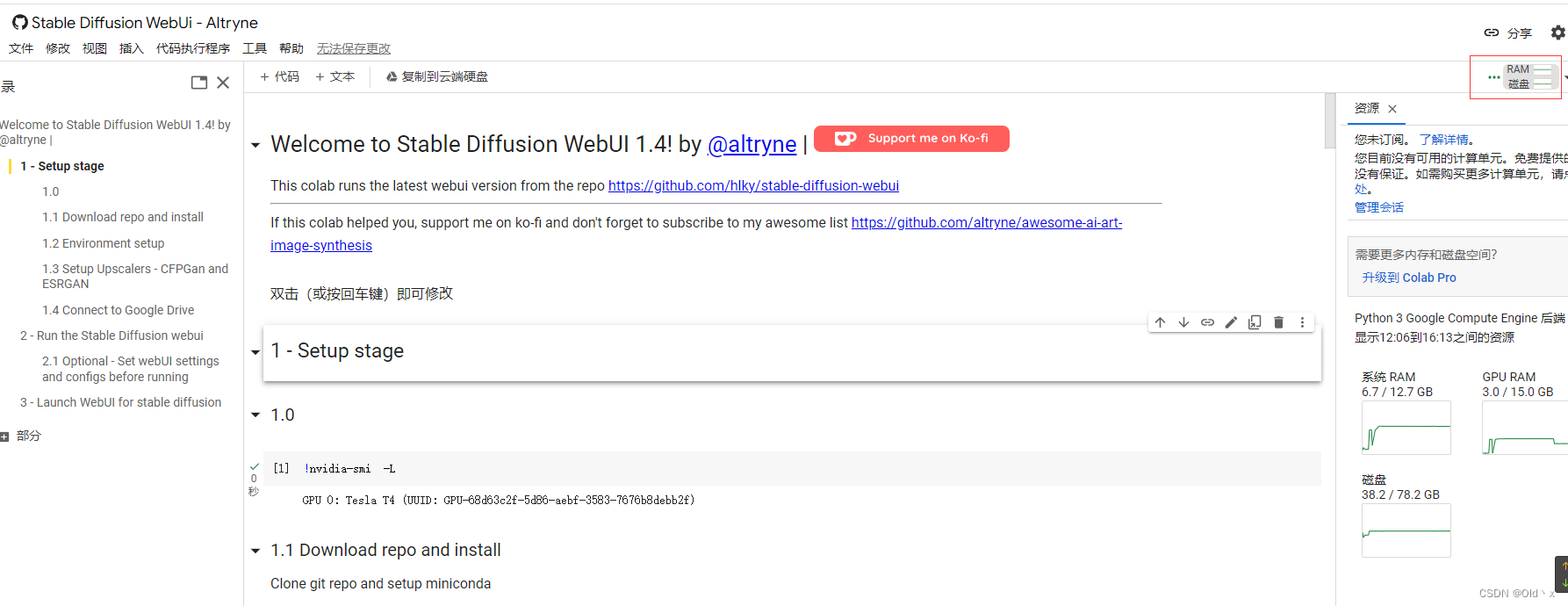
第二步: 配置服务器
点击右上角的连接

点击确定,等待连接上
如下图所示出现对于的配置信息就算成功了
第三步: 设置 Token
总共分了三个步骤执行
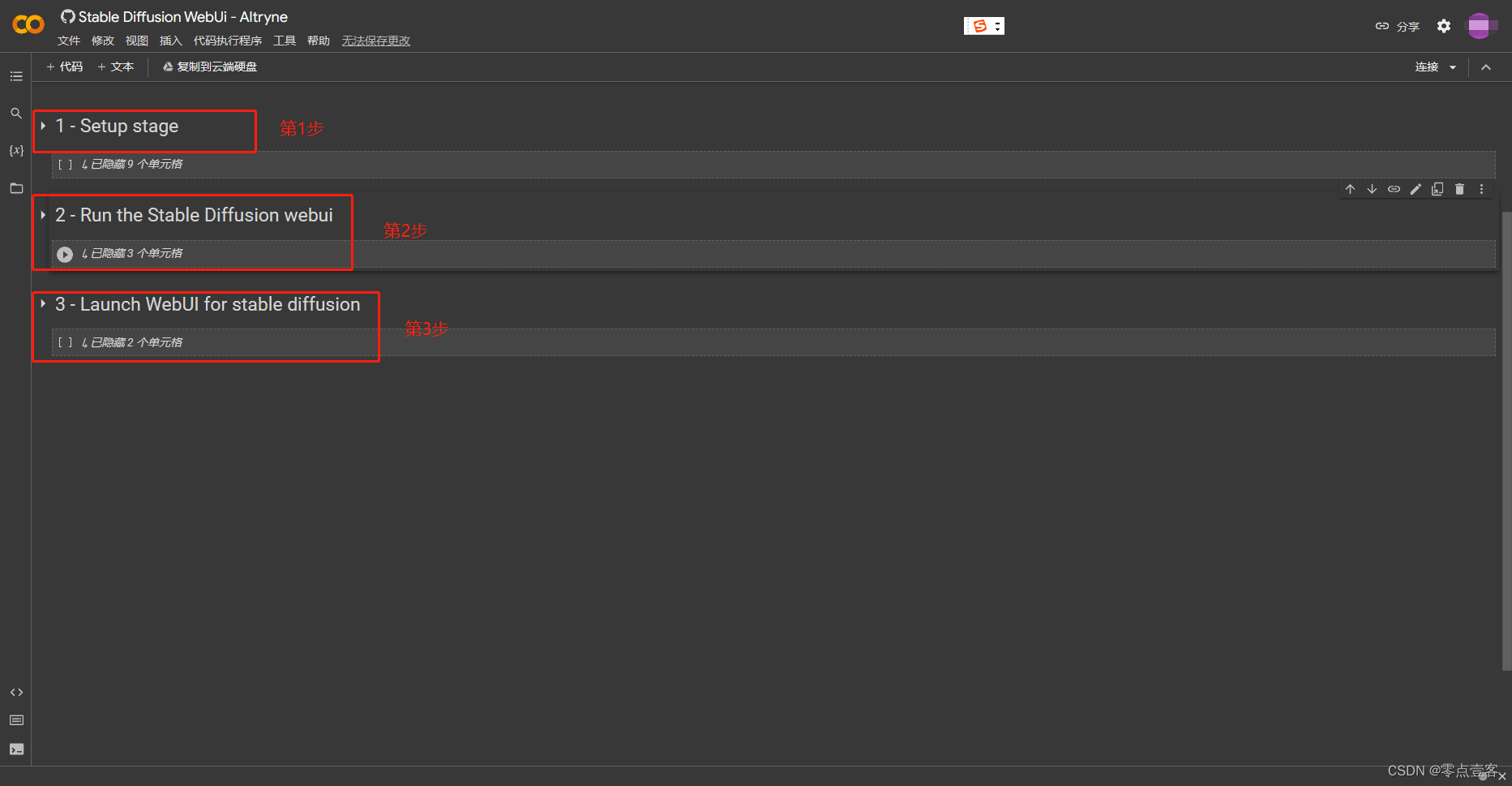
点击这个 1 - Setup stage 左边的小箭头进行展开
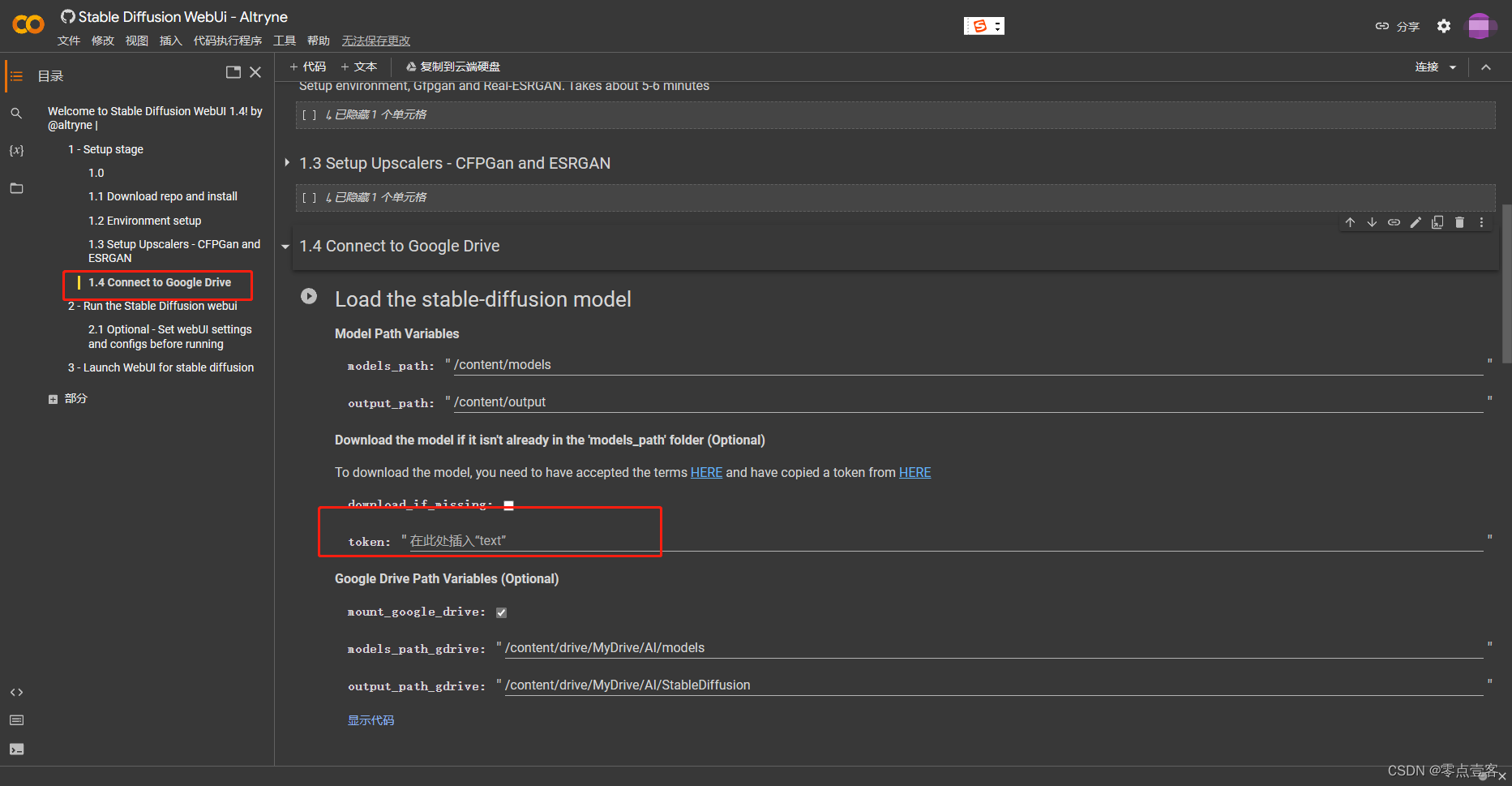
勾选 download_if_missing ,然后到 https://huggingface.co/settings/tokens 复制你的 toekn 并填入
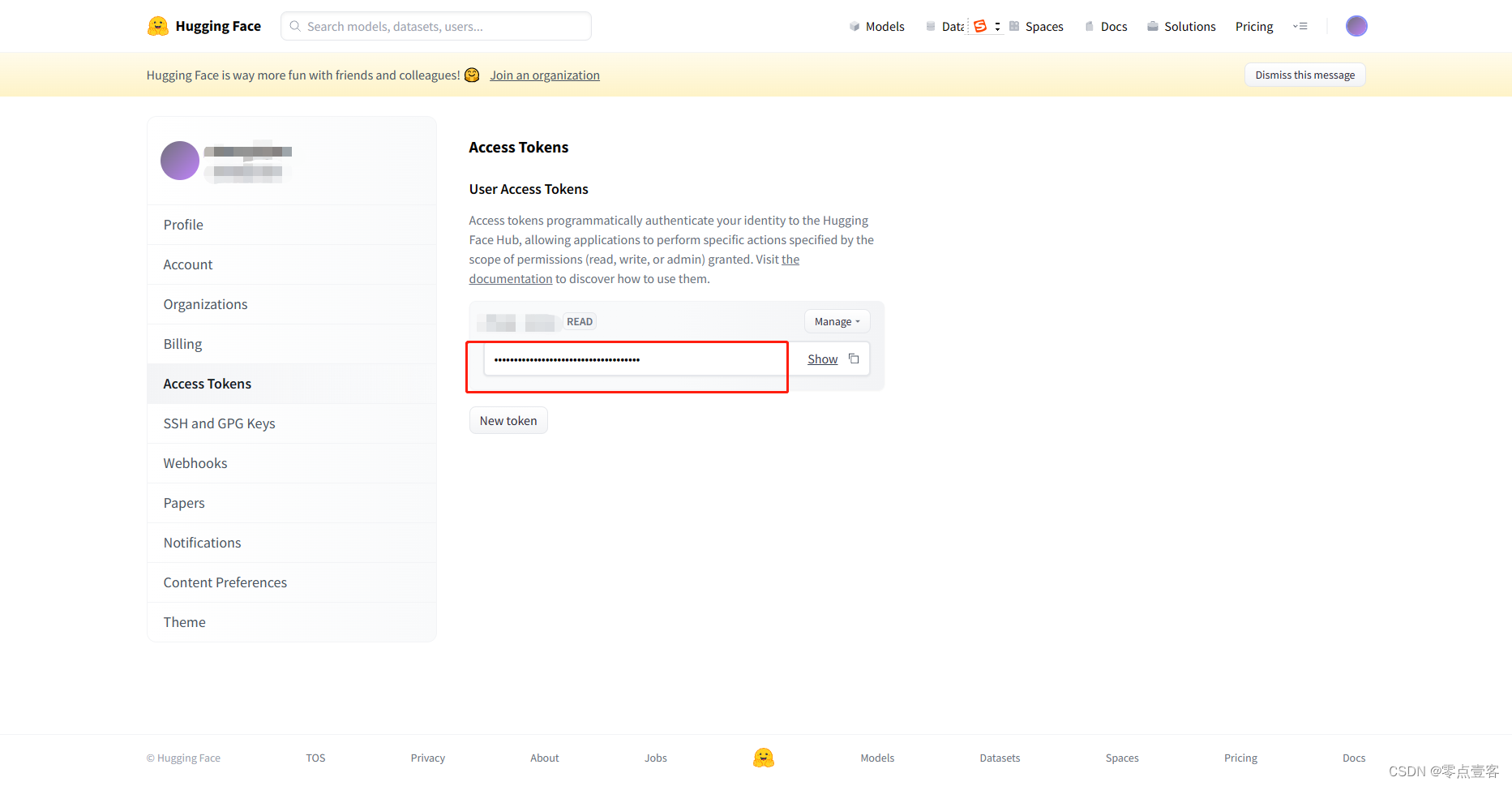
关于 huggingface 如何注册,可以看程序员秋风文章程序员秋风:AI数字绘画 stable-diffusion 保姆级教程![]() https://zhuanlan.zhihu.com/p/560226367
https://zhuanlan.zhihu.com/p/560226367
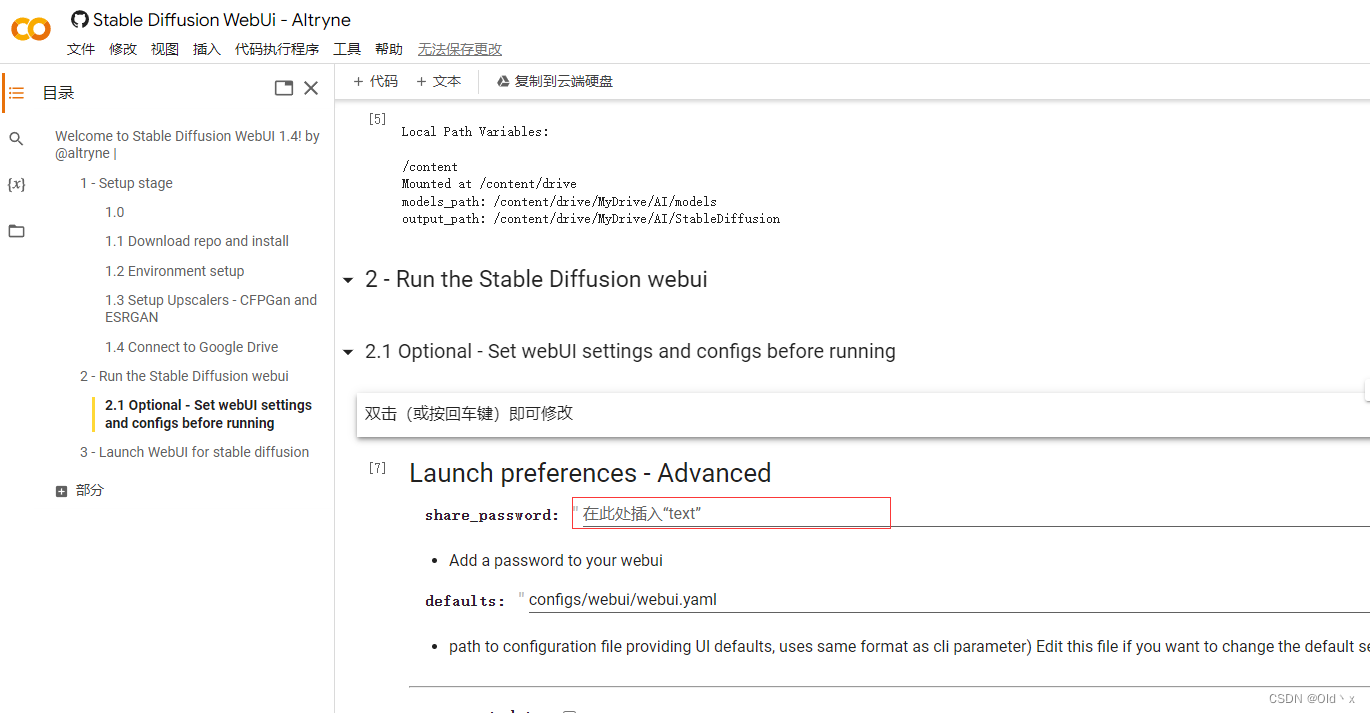
第四步: 设置密码
从目录中切换到2-2.1设置一个密码。
第五步: 配置依赖库
将鼠标光标移动到2-2.1后面,点击+代码
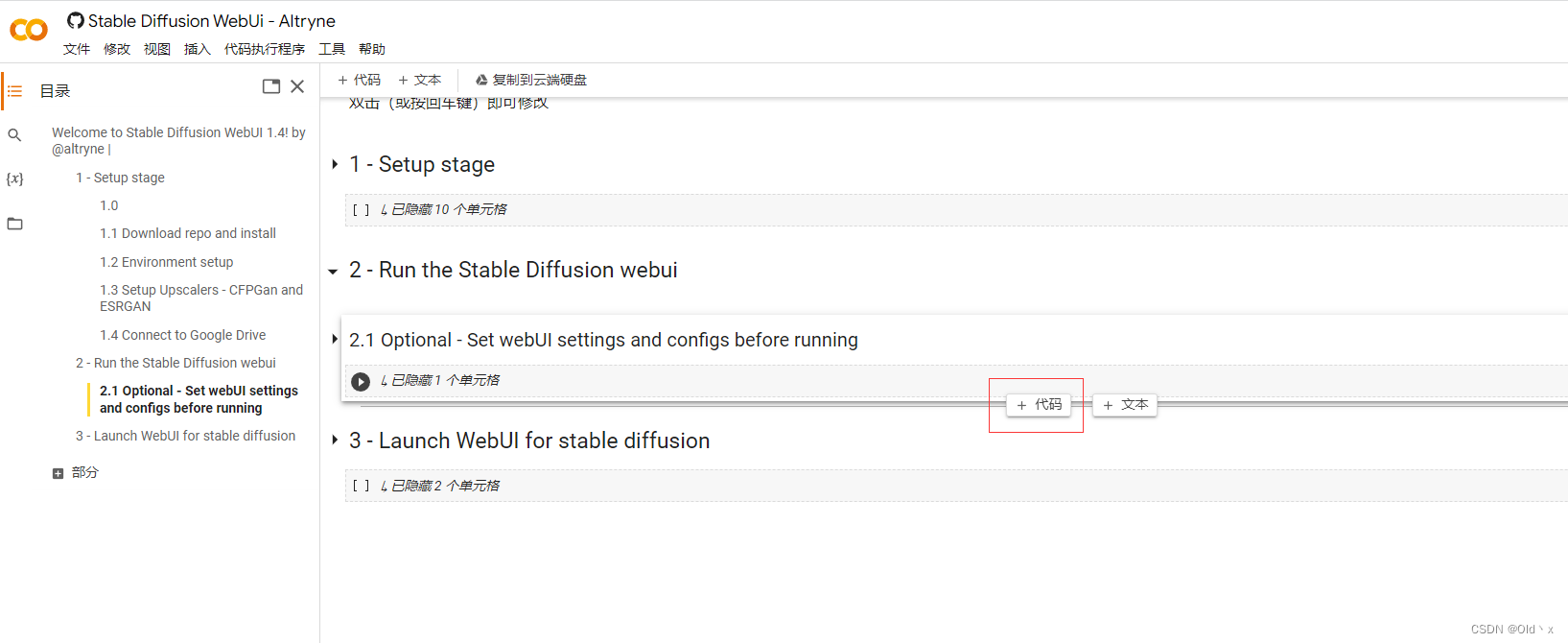
复制以下安装的代码并插入
!pip install gradio==3.20.1
!pip install k_diffusion
!pip install pynvml
!pip install omegaconf
!pip install pytorch_lightning
!pip install taming-transformers
!pip install taming-transformers-rom1504
!pip install transformers
!pip install pytorch-lightning==1.6.5
如下图所示
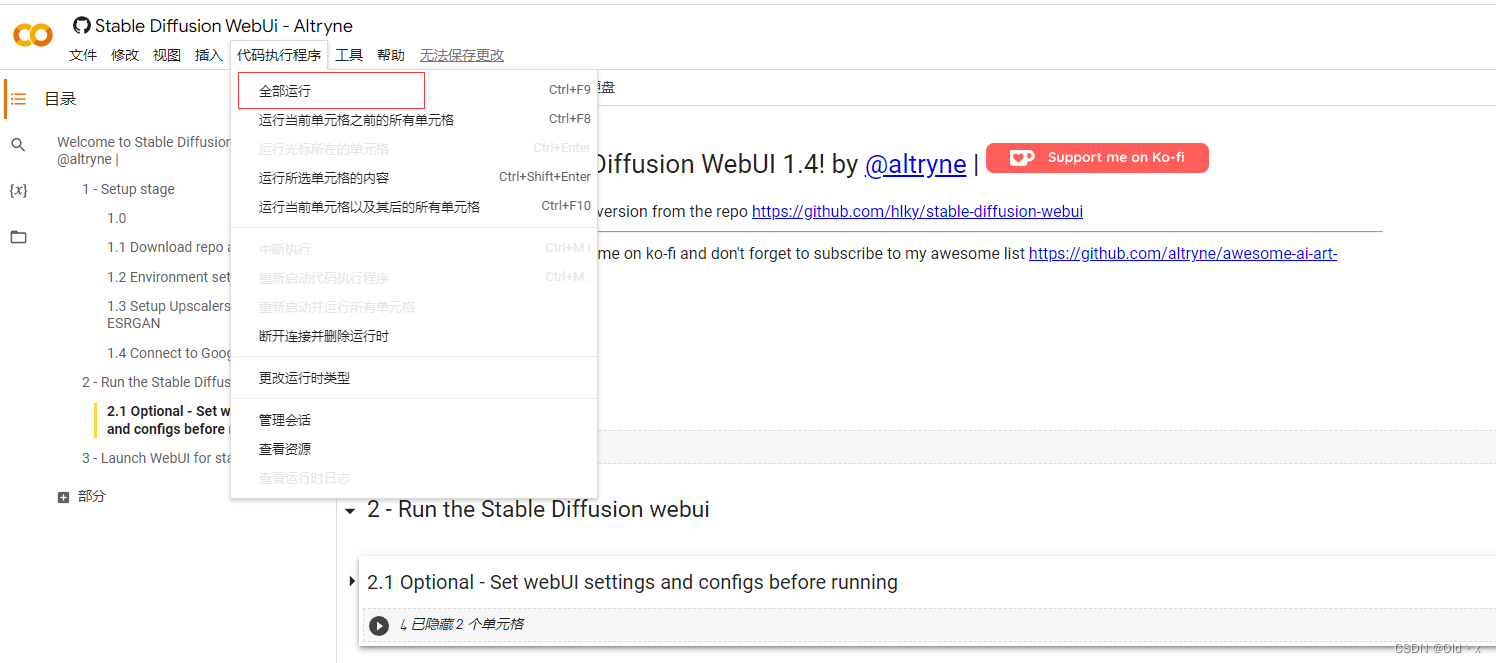
然后点击“代码执行程序”-----“全部运行”
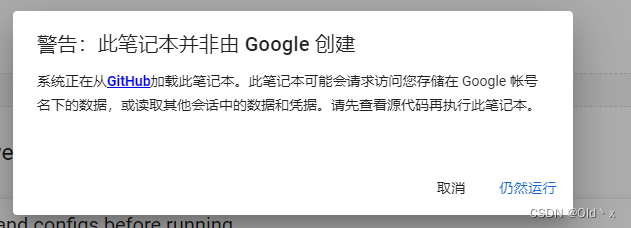
点击仍然运行
第六步: 打开 Web 服务
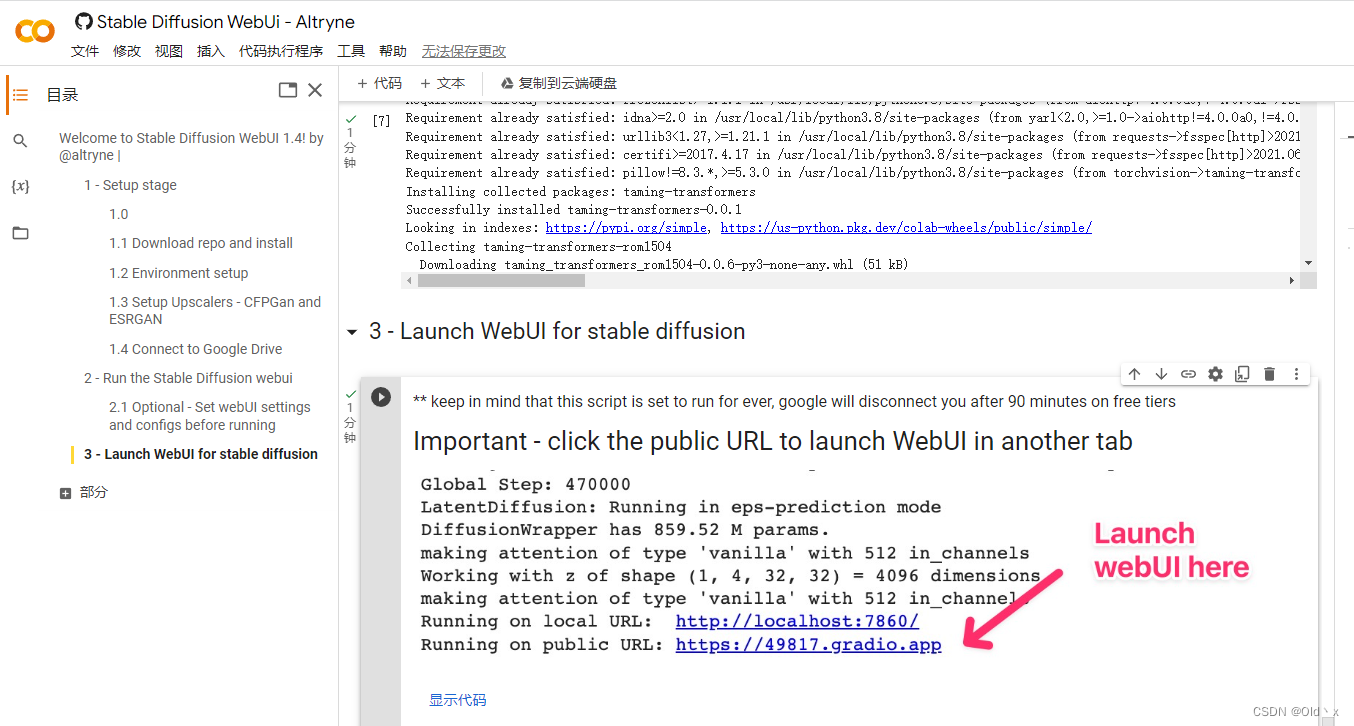
账号为 webui,密码如果设置了就是你设置的密码。
登录后就是如下的界面
V. 使用教程
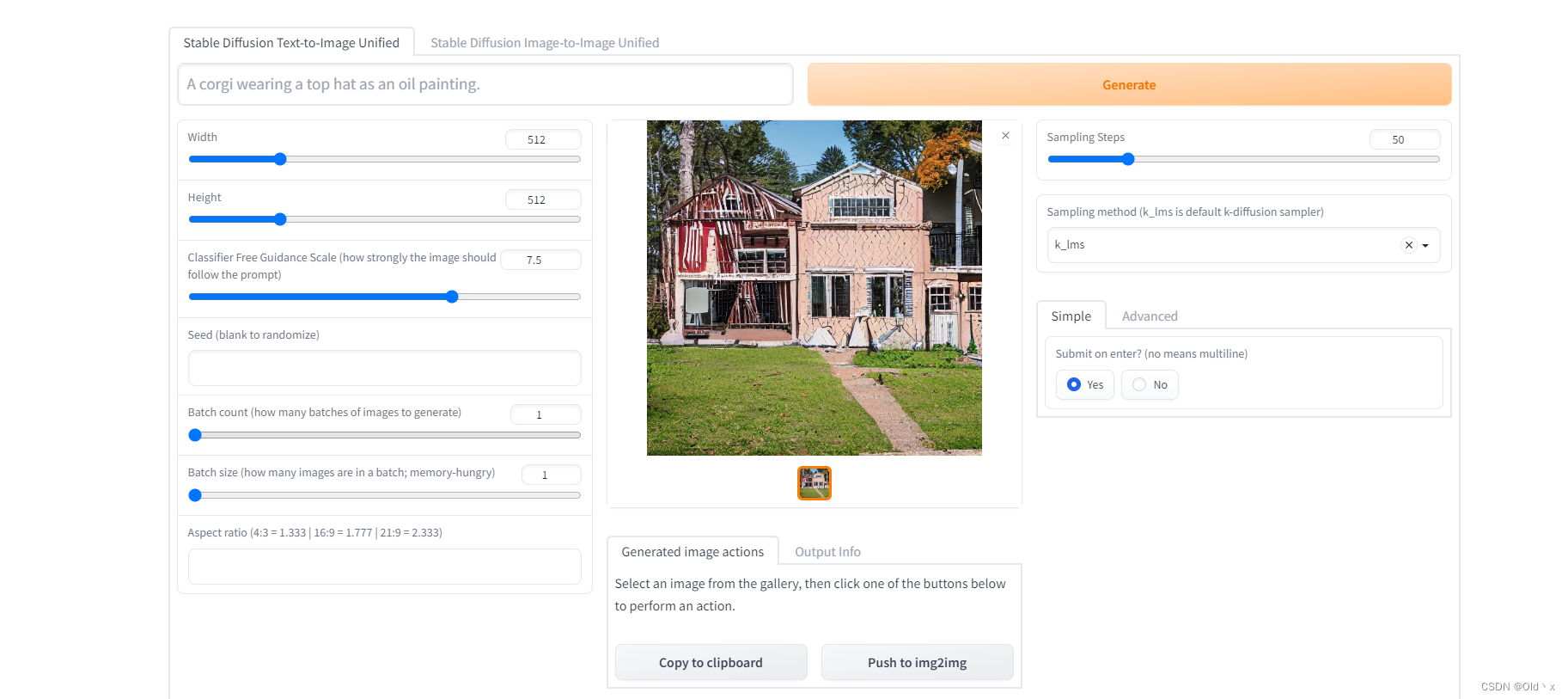
打开后就是这样一个界面,主要包含了4块功能,text2img,img2img,人脸修复算法,照片清晰化。

text2img
我们首先来看 text2img,也就是输入一段文字就可以生成一张照片。

然后来看生成的一些案例吧
prompt: a girl with lavender hair and black skirt, fairy tale style background, a beautiful half body illustration, top lighting, perfect shadow, soft painting, reduce saturation, leaning towards watercolor, art by hidari and krenz cushart and wenjun lin and akihiko yoshida

rimuru looking into the camera, beautiful face, ultra realistic, fully clothed, intricate details, highly detailed, 8 k, photorealistic, octane render, unreal engine, photorealistic, portrait
((a point coloration cat by the lakeside)), big face, small ears, play in the snow, sharp
focus, illustration, highly detailed, concept art, matte, anime, trending on artstation

prompt: Cyberpunk, 8k resolution, castle, the rose sea, dream

水墨画风格
prompt: a watercolor ink painting of a fallen angel with a broken halo wielding a jagged broken blade standing on top of a skyscraper in the style of anti - art trending on artstation deviantart pinterest detailed realistic hd 8 k high resolution

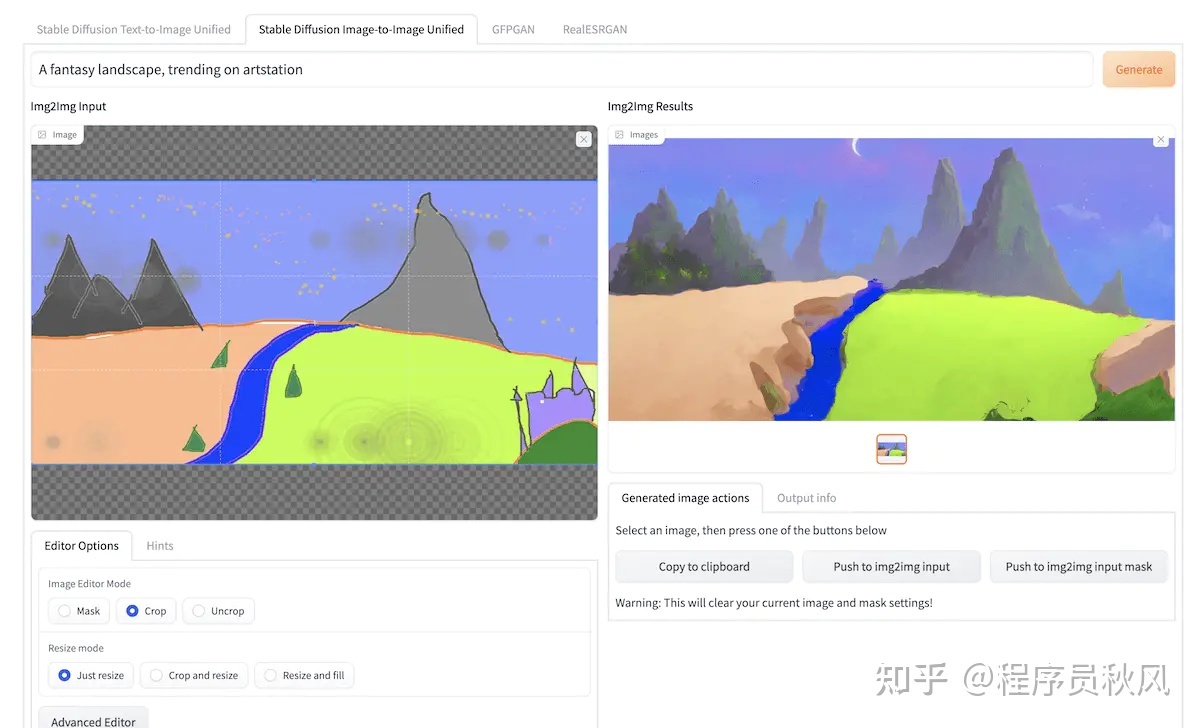
img2img
这个功能则是利用图片生成图片的功能。

人像优化
直接将老照片拖入框框。
案例:

清晰度优化
如果你觉得你生成的图片质量不够,可以使用这个功能进行4倍图进行放大。这个功能生成时间比较久,需要耐心等待, 大约5-10分钟,最终生成的清晰度提升还是蛮大的。
案例:

最后附上一个常见参数说明

更多内容请查看我整理的 Github https://github.com/hua1995116/awesome-ai-painting, 包含了 30+个 AI 绘画平台,SD 和 DD 使用教程,调参教程以及其他的文档。
