【阿里天池算法学习赛】测测你的一见钟情指数
地址:https://tianchi.aliyun.com/competition/entrance/531825/introduction?spm=5176.12281973.0.0.4c883b74SwHDoH
性格判断,职业预测,恋爱指数……你一定在各种网页或微信公众号里接触过此类的测试小游戏。只需要回答几个简单的问题,长篇大论的分析文章就被甩到你脸前,说得头头是道,看起来也有那么几分道理。在信息时代的大背景下,利用数据分析来实现人格测试早已屡见不鲜。
赛题背景
“在2002年-2004年期间,Ray Fisman教授和Sheena Iyengar教授在筹备论文时,邀请志愿者参加闪电速配实验(相亲车轮战,每4分钟与一名相亲对象快速沟通,然后再换下一个相亲对象),提供一些相关的个人信息给相亲对象,并询问相亲对象给出是否愿意在不久的未来再次见面。本次学习赛的分析数据,记录了当时一见钟情相亲实验时,志愿者的相关信息及相亲结果。”
选手可以针对数据集不同字段间的相互影响进行分析,训练一个机器学习模型,去预测实验人身上一个或多个特性对其相亲成功与否的影响。也就是利用其它特征信息,预测数据集中的“match”字段的结果,1=成功,0=不成功。
解题思路:
丢弃缺失率大的数据、填充缺失率小的数据、线性降维+非线性降维、设计模型、训练、预测
1、数据预处理
def missing(data,threshold,dropna = False):# 第三个参数为是否把有缺失数据的样本也删除
percent_missing = data.isnull().sum() / len(data)
# 统计缺失情况
missing = pd.DataFrame({
'column_name': data.columns,
'percent_missing': percent_missing})
# 要删除处理的数据
out = missing[missing['percent_missing']>threshold]
# 把缺失率大于阈值的列删了
data_new = data.drop(out['column_name'], axis=1).dropna() if dropna else
data.drop(out['column_name'], axis=1)
return data_new
这里我做了三轮处理,第一轮把缺失率大于百分之50的数据删除,第二轮均值填充缺失率小于百分之50的样本,第三轮做个缺失检查,把不能填充的样本整行删除。
data = pd.read_csv('./data/speed_dating_train.csv')
data = missing(data, 0.5)
data.fillna(data.mean(), inplace=True)
data = missing(data, 0, True)
2、数据降维
原始数据是有180多个特征,经过预处理后剩下130个特征,但往往很多特征与是否能匹配成功并没有关系,例如参加者的 id。有一些特征则和是否能匹配成功有着较高的相关性,例如收入等。
因为考虑到样本比较多,且恋爱本来就是比较玄幻的东西,所以非线性降维我用了皮尔逊相关系数把与label相关性的绝对值大于0.15的特征提取出来。
corr = data.corr('pearson')
# 这一行是用来创建一个布尔矩阵的,其中每个元素表示两个变量之间的相关系数是否大于0.15(绝对值)。如果是,那么对应的元素为True,否则为False。这样可以筛选出相关性较强的变量对
bool_matrix = (corr.abs() > 0.15)
# 这里使用的是条件选择,也就是只保留那些与’match’列相关系数大于0.15的列。这样可以减少数据框中的维度,只保留与目标变量(‘match’)相关性较强的变量。
data = data_new.loc[:, bool_matrix.loc['match']]
本来还打算PCA进行线性降维,但打印出来发现,剩下16个特征,所以我觉得不做也行
print(data.shape)
3、设计模型&训练
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
import pandas as pd
训练集/验证集
相亲匹配成功与匹配失败的样本分布不均,正负样本比约为1:5,所以要对训练集扩容,扩容方法我选择了简单的复制粘贴。
device = torch.device("cuda:0" if torch.cuda.is_available() else 'cpu')
# 训练集取前面6500个样本,剩下1700多个样本做验证集
train_data = data[0:6500]
test_data = data[6500:]
# 将训练集正样本复制4份
positive_samples = train_data[train_data['match'] == 1].copy()
positive_samples = pd.concat([positive_samples] * 4)
train_data = pd.concat([train_data, positive_samples])
# 对数据集进行打乱,保证样本顺序随机
train_data = train_data.sample(frac=1).reset_index(drop=True)
转换为tensor
train_X = train_data.drop('match', axis=1)
train_y = train_data['match']
test_X = test_data.drop('match', axis=1)
test_y = test_data['match']
test_X = torch.from_numpy(test_X.to_numpy()).float().to(device)
test_y = torch.from_numpy(test_y.to_numpy()).float().to(device)
train_X = torch.from_numpy(train_X.to_numpy()).float().to(device)
train_y = torch.from_numpy(train_y.to_numpy()).float().to(device)
# 打包成小批量随机梯度下降
dataset = TensorDataset(train_X, train_y)
dataloader = DataLoader(dataset, batch_size=30, shuffle=True)
模型设计/训练
# 三层神经网络,逻辑回归模型
model = nn.Sequential(
nn.Linear(16, 64),
nn.ReLU(),
nn.Linear(64, 1),
nn.Sigmoid()
).to(device)
# 优化器随机梯度下降
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 损失函数二元交叉熵
criterion = nn.BCELoss()
# 模型权重初始化
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
model.apply(init_weights)
# 训练模型
epochs = 60
for epoch in range(epochs):
for X, y in dataloader:
# 前向传播,得到预测值
y_pred = model(X)
# 计算损失值
loss = criterion(y_pred.squeeze(), y)
# 反向传播,计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 清零梯度
optimizer.zero_grad()
# 每10轮打印一次损失值
if (epoch + 1) % 10 == 0:
print(f'Epoch {
epoch + 1}, Loss: {
loss.item():.4f}')
4、测试模型
# 计算准确率函数
def accuracy(y_pred, y_true):
y_pred = y_pred.squeeze()
y_true = y_true.squeeze()
correct = torch.eq(y_pred, y_true).float()
acc = correct.sum() / len(correct)
return acc
with torch.no_grad(): # 不需要计算梯度
y_pred = model(test_X)
y_pred = y_pred.round() # 将预测值四舍五入为0或1
acc = accuracy(y_pred, test_y)
print(f'Accuracy: {
acc:.4f}')
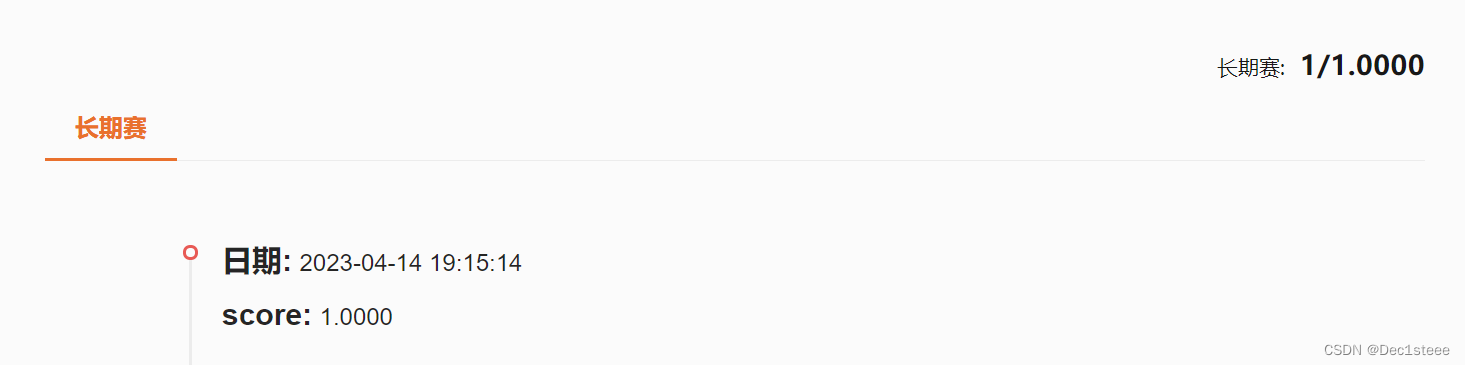
结果:
Epoch 20, Loss: 0.0105
Epoch 40, Loss: 0.0041
Epoch 60, Loss: 0.0017
Accuracy: 1.0000
5、保存数据&提交
# 同样的方法预处理data2
data2 = pd.read_csv('./data/speed_dating_test.csv')
data2 = missing(data, 0.5)
data2.fillna(data2.mean(), inplace=True)
data2 = missing(data2, 0, True)
data2 = torch.from_numpy(data2.to_numpy()).float().to(device)
# data2是没有'match'字段的,所以可以不用分离出来
predict_test = model(data2)
predict_test = predict_test.round().cpu()
predict_list = predict_test.squeeze().tolist() # 将张量转换为列表
predict_int = [int(x) for x in predict_list] # 将列表中的每个元素转换为int
# 提交要按照官方给出的格式,所以把sample导入进来,替换sample的'match'字段即可
save = pd.read_csv('data/sample_submission.csv')
save['match'] = predict_int
# 保存
save.to_csv('data/predict_submission.csv', index=False) # index=False表示不写入行索引
提交文件,获得成绩与排名