关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
斯坦福大学和谷歌大脑的研究者提出使用两步蒸馏方法来提升无分类器指导的采样效率。该方法能够在 ImageNet 64x64 和 CIFAR-10 上使用少至 4 个采样步骤生成视觉上与原始模型相当的图像,实现与原始模型的采样速度提高了 256 倍。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
转自《极市平台》
去噪扩散概率模型(DDPM)在图像生成、音频合成、分子生成和似然估计领域都已经实现了 SOTA 性能。同时无分类器(classifier-free)指导进一步提升了扩散模型的样本质量,并已被广泛应用在包括 GLIDE、DALL·E 2 和 Imagen 在内的大规模扩散模型框架中。
然而,无分类器指导的一大关键局限是它的采样效率低下,需要对两个扩散模型评估数百次才能生成一个样本。这一局限阻碍了无分类指导模型在真实世界设置中的应用。尽管已经针对扩散模型提出了蒸馏方法,但目前这些方法不适用无分类器指导扩散模型。
为了解决这一问题,斯坦福大学和谷歌大脑的研究者在论文《On Distillation of Guided Diffusion Models》中提出使用两步蒸馏(two-step distillation)方法来提升无分类器指导的采样效率。
在第一步中,他们引入单一学生模型来匹配两个教师扩散模型的组合输出;在第二步中,他们利用提出的方法逐渐地将从第一步学得的模型蒸馏为更少步骤的模型。
利用提出的方法,单个蒸馏模型能够处理各种不同的指导强度,从而高效地对样本质量和多样性进行权衡。此外为了从他们的模型中采样,研究者考虑了文献中已有的确定性采样器,并进一步提出了随机采样过程。

论文地址:https://arxiv.org/pdf/2210.03142.pdf
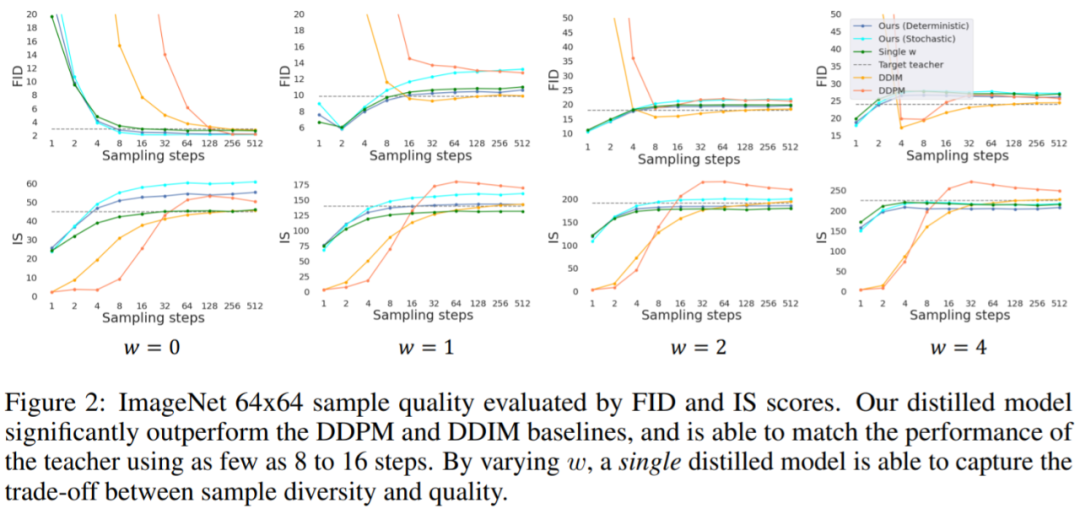
研究者在 ImageNet 64x64 和 CIFAR-10 上进行了实验,结果表明提出的蒸馏模型只需 4 步就能生成在视觉上与教师模型媲美的样本,并且在更广泛的指导强度上只需 8 到 16 步就能实现与教师模型媲美的 FID/IS 分数,具体如下图 1 所示。
此外,在 ImageNet 64x64 上的其他实验结果也表明了,研究者提出的框架在风格迁移应用中也表现良好。
方法介绍
接下来本文讨论了蒸馏无分类器指导扩散模型的方法 ( distilling a classifier-free guided diffusion model)。给定一个训练好的指导模型,即教师模型 之后本文分两步完成。
第一步引入一个连续时间学生模型 , 该模型具有可学习参数 , 以匹配教师模型在任意时间步 处的输出。给定一个优化范围 [w_min, w_max], 对学生模型进行优化:
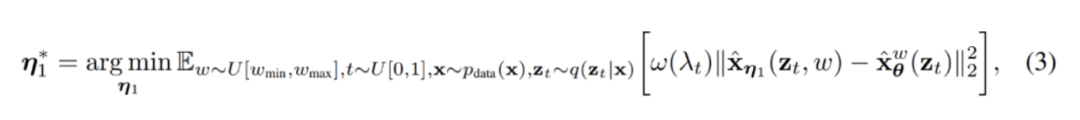
其中, 。为了合并指导权重 , 本文引入了一个 条件模 型, 其中 作为学生模型的输入。为了更好地捕捉特征, 本文还对 应用傅里叶嵌入。此外, 由于初始化在模型性能中起着关键作用, 因此本文初始化学生模型的参数与教师模型相同。
在第二步中, 本文将离散时间步 (discrete time-step) 考虑在内, 并逐步将第一步中的蒸馏模型 转化为步数较短的学生模型 , 其可学习参数为 , 每次采样步数减半。设 为采样步数, 给定 和 , 然后根据 Salimans & Ho 等人提出的方法训练学生模型。在将教师模型中的 步蒸馏为学生模型中的 步之后, 之后使用 步学生模型作为新的教师模型, 这个过程不断重复, 直到将教师模型蒸馏为 N/2 步学生模型。
步可确定性和随机采样:一旦模型 训练完成, 给定一个指定的 ,, 然后使用 DDIM 更新规则执行采样。
实际上, 本文也可以执行 步随机采样, 使用两倍于原始步长的确定性采样步骤, 然后使用原始步长向后执行一个随机步骤。对于 , 当 时, 本文使用以下更新规则
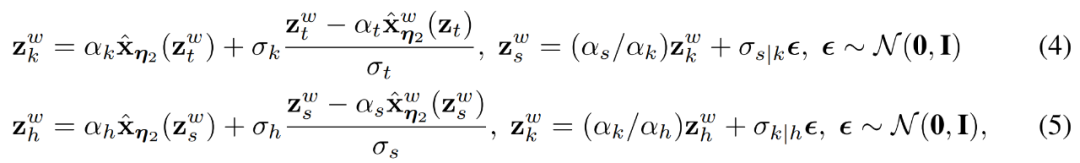
实验
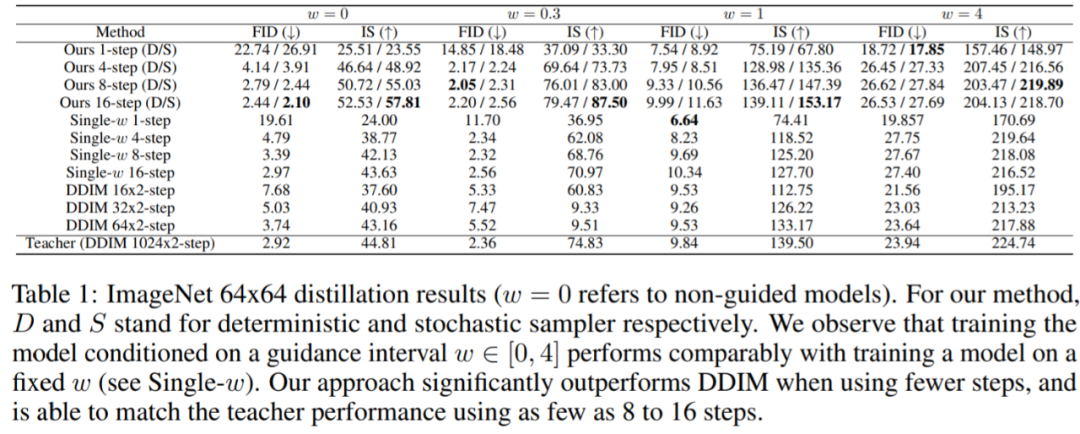
实验评估了蒸馏方法的性能,本文主要关注模型在 ImageNet 64x64 和 CIFAR-10 上的结果。他们探索了指导权重的不同范围,并观察到所有范围都具有可比性,因此实验采用 [w_min, w_max] = [0, 4]。图 2 和表 1 报告了在 ImageNet 64x64 上所有方法的性能。
本文还进行了如下实验。具体来说,为了在两个域 A 和 B 之间执行风格迁移,本文使用在域 A 上训练的扩散模型对来自域 A 的图像进行编码,然后使用在域 B 上训练的扩散模型进行解码。由于编码过程可以理解为反向 DDIM 采样过程,本文在无分类器指导下对编码器和解码器进行蒸馏,并与下图 3 中的 DDIM 编码器和解码器进行比较。

本文还探讨了如何修改指导强度 w 以影响性能,如下图 4 所示。

© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606
