注意参数位已用中文描述代替。
如果你想训练自己的数据集,大多情况修改他们就可以了。
如果数据格式不大相同 或者 你想要修改网络结构(本文是三层全连接BP神经网络)。
那么你可以试着修改其中的一些函数,试着符合你的要求。
五折交叉、模型保存等均在代码中解释,自行选择
如果你没有安装pytorch,你可以尝试安装这个包的cpu版
如果不想安装,可以去去郭大侠的github,哪里不需要pytorch
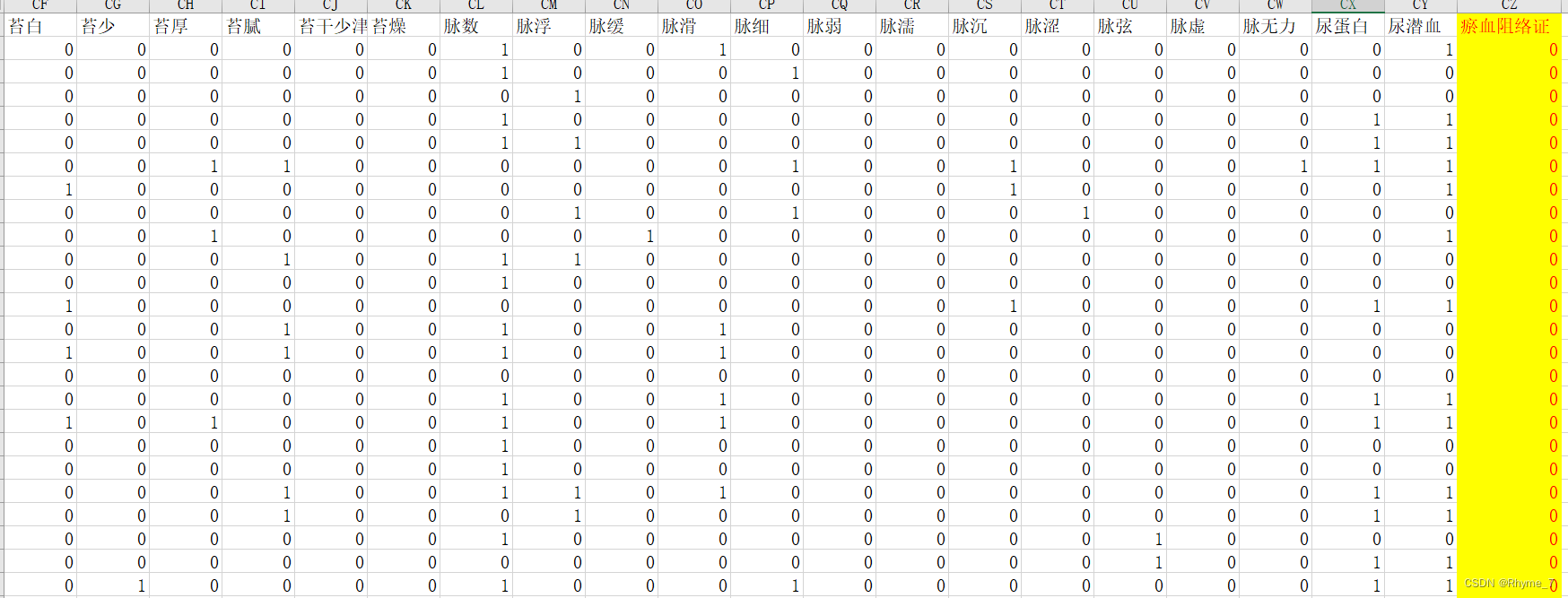
数据格式
664条样本 每条103个属性,最后一列为标签
结果
不使用五折交叉验证

使用五折交叉验证

代码
不使用五折交叉验证
"""
BP神经网络二分类任务 瘀血阻络证 103特征
"""
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import random
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, roc_curve, auc
def open_excel(file_url):
"""
打开数据集,进行数据处理
:param file_url:文件路径
:return:特征集数据、标签集数据
"""
readbook = pd.read_excel(f'{file_url}', engine='openpyxl')
nplist = readbook.T.to_numpy()
data = nplist[0:-1].T
data = np.float64(data)
target = nplist[-1]
return data, target
def open_csv(file_url):
"""
打开数据集,进行数据处理
:param file_url:文件名
:return:特征集数据、标签集数据
"""
readbook = pd.read_csv(f'{file_url}.csv')
nplist = readbook.T.to_numpy()
data = nplist[0:-1].T
data = np.float64(data)
target = nplist[-1]
return data, target
def random_number(data_size, key):
"""
使用shuffle()打乱
"""
number_set = []
for i in range(data_size):
number_set.append(i)
if key == 1:
random.shuffle(number_set)
return number_set
def inputtotensor(inputtensor, labeltensor):
"""
将数据集的输入和标签转为tensor格式
:param inputtensor: 数据集输入
:param labeltensor: 数据集标签
:return: 输入tensor,标签tensor
"""
inputtensor = np.array(inputtensor)
inputtensor = torch.FloatTensor(inputtensor)
labeltensor = np.array(labeltensor)
labeltensor = labeltensor.astype(float)
labeltensor = torch.LongTensor(labeltensor)
return inputtensor, labeltensor
# 定义BP神经网络
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size) # 输入层->隐藏层1
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, hidden_size) # 隐藏层1->隐藏层2
self.fc3 = nn.Linear(hidden_size, num_classes) # 隐藏层2->输出层
self.dropout_i = nn.Dropout(p=0.2) # dropout训练
self.dropout_h = nn.Dropout(p=0.5) # 隐藏层的dropout训练
def forward(self, x):
out = self.fc1(x)
out = self.dropout_i(out)
out = self.relu(out)
out = self.fc2(out)
out = self.dropout_h(out)
out = self.relu(out)
out = self.fc3(out)
return out
def addbatch(data_train, data_test, batchsize):
"""
设置batch
:param data_train: 输入
:param data_test: 标签
:param batchsize: 一个batch大小
:return: 设置好batch的数据集
"""
data = TensorDataset(data_train, data_test)
data_loader = DataLoader(data, batch_size=batchsize, shuffle=True)
return data_loader
def train_test(traininput, trainlabel, Epochs, batchsize): # ,testinput, testlabel
"""
函数输入为:训练输入,训练标签,测试输入,测试标签,一个batch大小
进行BP的训练,每训练一次就算一次准确率,同时记录loss
:return:训练次数list,训练loss,测试loss,准确率
"""
# 设置batch
traindata = addbatch(traininput, trainlabel, batchsize) # shuffle打乱数据集
total_step = len(traindata)
for epoch in range(Epochs):
for step, data in enumerate(traindata):
net.train()
inputs, labels = data
# 前向传播
out = net(inputs)
# 计算损失函数
loss = loss_func(out, labels)
# 清空上一轮的梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 输出loss
if (epoch + 1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.8f}'
.format(epoch + 1, Epochs, step + 1, total_step, loss.item()))
''' # 测试准确率
net.eval()
testout = net(testinput)
testloss = loss_func(testout, testlabel)
prediction = torch.max(testout, 1)[1] # torch.max
pred_y = prediction.numpy() # 事先放在了GPU,所以必须得从GPU取到CPU中!!!!!!
target_y = testlabel.data.numpy()
j = 0
for i in range(pred_y.size):
if pred_y[i] == target_y[i]:
j += 1
acc = j / pred_y.size
if epoch % 10 == 0:
print("训练次数为", epoch, "的准确率为:", acc)'''
# 根据标签和预测概率结果画出ROC图,并计算AUC值
def acu_curve(y, prob):
fpr, tpr, threshold = roc_curve(y, prob) ###计算真正率和假正率
roc_auc = auc(fpr, tpr) ###计算auc的值
print("AUC:", roc_auc)
plt.figure()
lw = 2
plt.figure(figsize=(6, 6))
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.3f)' % roc_auc) ###假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.show()
return roc_auc
if __name__ == "__main__":
# 利用open_excel读取数据
feature, label = open_excel('症状_瘀血阻络证_data.xlsx')
# 数据划分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(feature, label, test_size=你的比例, random_state=你的随机数)
# 将数据转为tensor格式
traininput, trainlabel = inputtotensor(x_train, y_train)
testinput, testlabel = inputtotensor(x_test, y_test)
# 归一化处理
traininput = nn.functional.normalize(traininput)
testinput = nn.functional.normalize(testinput)
# 设置超参数
Epochs = 你的迭代次数
input_size = 103
hidden_size = 你的隐层神经元个数
num_classes = 2
LR = 你的学习率
batchsize =
# 定义网络
net = NeuralNetwork()
# 优化器
optimizer = torch.optim.Adam(net.parameters(), LR)
# 设定损失函数
loss_func = torch.nn.CrossEntropyLoss()
# 训练并且记录每次loss 函数输入为:训练输入,训练标签,测试输入,测试标签,一个batch大小
print(traininput)
print(trainlabel)
train_test(traininput, trainlabel, Epochs, batchsize)
print('----------------------------------不使用五折交叉验证----------------------------------')
# 不使用五折交叉验证的测试结果
net.eval()
test_predict1 = net(testinput).cpu().detach().numpy() # 将tensor转为概率数组
test_predict2 = np.argmax(test_predict1, axis=1) # 将概率数组转为label
# print(test_predict1)
# print(test_predict2)
print(classification_report(testlabel, test_predict2))
auc = acu_curve(testlabel, test_predict1[:, 1:])
#######是否保存模型参数#######
save = True 或者 False
if save:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = NeuralNetwork().to(device)
str = 'hidden_size'+str(hidden_size)+'-batchsize'+str(batchsize)+'-Epochs'+str(Epochs)+'-auc'+str(auc)
url = './'+ str + '.pth'
torch.save(model.state_dict(), url)
print('模型参数已保存到'+url)
'''# 读取教师模型参数 并预测
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
open_model = NeuralNetwork()
open_model.load_state_dict(torch.load('./名字.pth'))
open_model.to(device)
test_predict1 = open_model(testinput.to(device)).cpu().detach().numpy()
test_predict2 = np.argmax(test_predict1, axis=1) # 将概率数组转为label
print(classification_report(testlabel, test_predict2))
acu_curve(testlabel, test_predict1[:, 1:])
'''
使用五折交叉验证(修改之处)
前155行与上述相同(多了几个import)
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import random
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import KFold
from sklearn.metrics import roc_curve, precision_score, recall_score, f1_score, \
roc_auc_score, accuracy_score, auc
from itertools import chain
def statistics(testlabel, test_predict1, test_predict2):
"""
:testlabel 测试集label:
:test_predict1 预测概率数组:
:test_predict2 预测label:
:return:
"""
# 准确率
print(f"Accuracy:", accuracy_score(testlabel, test_predict2))
# 精确率
print("Precision:", precision_score(testlabel, test_predict2, average='macro'))
# 召回率
print("Recall:", recall_score(testlabel, test_predict2, average='macro'))
# F1值
print("F1-Score:", f1_score(testlabel, test_predict2, average='macro'))
# 画ROC曲线
fpr, tpr, thresholds = roc_curve(testlabel, test_predict1[:, 1], pos_label=1) # pos_label=1表示正样本的标签为1
roc_auc = auc(fpr, tpr) ###计算auc的值
print("AUC:", roc_auc)
plt.plot(fpr, tpr, linewidth=2, label="ROC(AUC=%0.3f)" % roc_auc_score(testlabel, test_predict1[:, 1]), color='darkorange')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.ylim(0, 1.05)
plt.xlim(0, 1.05)
plt.legend(loc=4)
plt.show()
return roc_auc
if __name__ == "__main__":
# 加载数据
df = pd.read_excel(r"症状_瘀血阻络证_data.xlsx")
data = df.iloc[:, :-1]
data['target'] = df.iloc[:, -1] # 添加标签
data = data.to_numpy()
# 5-fold cross-validation
kf = KFold(n_splits=5, shuffle=True)
for train_index, test_index in kf.split(data):
x_train, x_test = data[train_index, :data.shape[1] - 1], data[test_index, :data.shape[1] - 1]
y_train, y_test = data[train_index, data.shape[1] - 1:data.shape[1]], data[test_index,data.shape[1] - 1:data.shape[1]]
'''这里把y_train、y_test降维 否则见221行 ps:目前是200行'''
y_train = list(chain.from_iterable(y_train))
y_test = list(chain.from_iterable(y_test))
# 将数据转为tensor格式
traininput, trainlabel = inputtotensor(x_train, y_train)
testinput, testlabel = inputtotensor(x_test, y_test)
# 归一化处理
traininput = nn.functional.normalize(traininput)
testinput = nn.functional.normalize(testinput)
# 设置超参数
Epochs = 你的迭代次数
input_size = 103
hidden_size = 你的隐层神经元个数
num_classes = 2
LR = 你的学习率
batchsize = 你的batchsize
# 定义网络
net = NeuralNetwork()
# 优化器
optimizer = torch.optim.Adam(net.parameters(), LR)
'''设定损失函数 KFold使trainlabel升维 需要更改为多标签损失函数MultiLabelSoftMarginLoss 当然我没这么做 我在200行把y_train、y_test降维了'''
#loss_func = torch.nn.MultiLabelSoftMarginLoss()
loss_func = torch.nn.CrossEntropyLoss()
# 训练并且记录每次loss 函数输入为:训练输入,训练标签,测试输入,测试标签,一个batch大小
train_test(traininput, trainlabel, Epochs, batchsize)
print('----------------------------------使用五折交叉验证----------------------------------')
# 使用五折交叉验证的测试结果
net.eval()
test_predict1 = net(testinput).cpu().detach().numpy() # 将tensor转为概率数组
test_predict2 = np.argmax(test_predict1, axis=1) # 将概率数组转为label
auc = statistics(testlabel, test_predict1, test_predict2)
#######是否保存模型参数#######
save = True 或者 False
if save:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = NeuralNetwork().to(device)
str = 'hidden_size'+str(hidden_size)+'-batchsize'+str(batchsize)+'-Epochs'+str(Epochs)+'-auc'+str(auc)
url = './'+ str + '.pth'
torch.save(model.state_dict(), url)
print('模型参数已保存到'+url)
'''# 读取教师模型参数 并预测
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
open_model = NeuralNetwork()
open_model.load_state_dict(torch.load('./名字.pth'))
open_model.to(device)
test_predict1 = open_model(testinput.to(device)).cpu().detach().numpy()
test_predict2 = np.argmax(test_predict1, axis=1) # 将概率数组转为label
statistics(testlabel, test_predict1, test_predict2)
'''
注意点(参考)
2 、pytorch:批量数据分割(batch)_XYKenny的博客-CSDN博客![]() https://blog.csdn.net/XYKenny/article/details/105935836
https://blog.csdn.net/XYKenny/article/details/105935836