上一篇博客配置好了树莓派端的串口通信,这次在加入涡轮流量计之前也先用PC端模拟树莓派测试一下该仪表是否能正常工作。
一、测试流量计通信
流量计说明书如下:

并且在设备上电时以(9600,8n1格式)自动发送四个字节:
返码格式:站地址(1字节)+波特率(2字节)+格式(1字节)
8n1格式指8个数据位,无校验,1个停止位,8e1与8o1分别对应偶校验和奇校验。
将流量计与USB转485转换器及24V电源正确接线,打开PC端串口,开启电源,观察接收窗口信息(注意接收区和发送区均调成十六进制显示):

接收到返码为“01 25 80 00”,其意义为:设备地址1,波特率9600,格式8n1
依据说明书的样例,在PC端发送以下命令:

这一命令用于查询瞬时流量值,依据上篇学过的modbus-RTU协议,可以对该命令作如下解析:
发送:
01 03 00 00 00 02 C4 0B
01-设备地址为1
03-代表查询功能
00 00-查询的寄存器起始地址,由此得知储存瞬时流量值这一数据的寄存器起始地址为0
00 02-查询的寄存器数量,由此得知瞬时流量这一数据由2个寄存器储存
C4 0B-CRC校验码
接收:
01 03 04 00 00 00 00 FA 33
01-设备地址为1
03-查询功能
04-表示后面有4个字节的数据,因为查询了2个寄存器,所以返回2*2个字节数据
00 00 00 00-查询所得的数据
FA 33-CRC校验码确认了流量计通讯正常后,将树莓派与流量计正确接线,在通讯实验前我事先利用CRC校验算法算好了所有将要用到的命令的校验位值,依据说明书记录的各项数据类型可以推算该数据占用的寄存器个数,例如32位无符号占用4字节,即2个寄存器,因此查询时需要从起始地址往后查两个寄存器的数据,各个数据的起始地址在说明书中均已给出。
二、流量计实验前准备工作
所有拟用到的完整命令如下:
01 03 00 00 00 02 C4 0B //查询瞬时流量值(L/H)
01 03 00 02 00 02 65 CB //查询累计流量(L)
01 03 00 08 00 02 45 C9 //查询累计脉冲数
01 03 17 71 00 02 91 A4 //查询仪器系数
01 06 00 06 00 01 A8 0B //累计流量清零
01 06 00 07 00 01 F9 CB //累计脉冲数清零解释一下脉冲数和仪器系数,流量计工作时,内部的水流会推动里面的涡轮叶片转动,每当叶片经过磁铁时会产生感应信号,再经过放大器之类的将脉冲送到计数器里,而仪器系数就是表明多少个脉冲来表示一升水的流量,比如仪器系数1000就表示1000个脉冲1升水。
首先查询一下仪器系数(左边发送,右边接收):
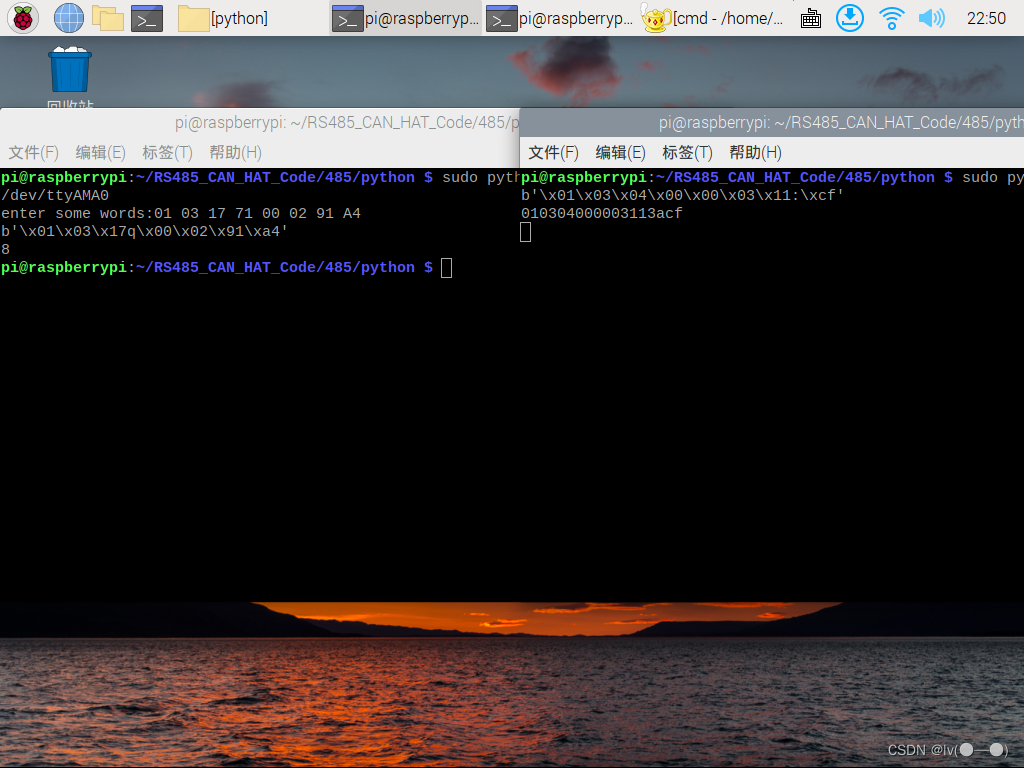
可以看到返回的数据位是“00 00 03 11”,将十六进制311转成十进制为785,说明此流量计仪器系数为785,785个脉冲一升水。
清零累计流量与累计脉冲数:

清零之后我先往流量计里倒了一瓶自来水做实验,对比其脉冲数和流量值的关系,最后确认了瞬时流量值和累计流量值的数据位返回的均是保留两位小数的十六进制形式,比如累计流量返码的数据位是“00 00 01 00”即十六进制的100,转化为十进制256,表示的水量是2.56升。
到这准备工作都已经完成,想要采集流量数据只要把流量计装到工作环境里开始工作就完事了,随时可以通过receive和send两个python文件发送计算好的命令来查询和修改流量计采集的各项数据。接下来我就夹带点私货了~
三、数据处理预备工作
以上两步基本确认了树莓派与流量计的通讯没有问题,不出意外的话实验可以顺利进行的。那我在这里先准备一下实验数据的处理(这一节其实和上篇写的实验目标没啥关系hhh)。我最终是想将查询流量计所得的瞬时流量、累计流量两项数据上传到搭建好的Hyperledger Fabric环境中,此前对照官方示例fabcar写了个test链码:
/*
SPDX-License-Identifier: Apache-2.0
*/
package main
import (
"encoding/json"
"fmt"
"github.com/hyperledger/fabric-contract-api-go/contractapi"
)
type SmartContract struct {
contractapi.Contract
}
type Data struct {
Now string `json:"now(L/H)"`
Total string `json:"total(L)"`
}
type QueryResult struct {
Key string `json:"Key"`
Record *Data
}
func (s *SmartContract) InitLedger(ctx contractapi.TransactionContextInterface) error {
datas := []Data{
Data{Now:"0", Total: "0"},
}
for data := range datas {
dataAsBytes, _ := json.Marshal(data)
err := ctx.GetStub().PutState("2022-07-20 00:00", dataAsBytes)
if err != nil {
return fmt.Errorf("Failed to put to world state. %s", err.Error())
}
}
return nil
}
func (s *SmartContract) AddData(ctx contractapi.TransactionContextInterface, dataNumber string, now string, total string) error {
data := Data{
Now: now,
Total: total,
}
dataAsBytes, _ := json.Marshal(data)
return ctx.GetStub().PutState(dataNumber, dataAsBytes)
}
func (s *SmartContract) QueryData(ctx contractapi.TransactionContextInterface, dataNumber string) (*Data, error) {
dataAsBytes, err := ctx.GetStub().GetState(dataNumber)
if err != nil {
return nil, fmt.Errorf("Failed to read from world state. %s", err.Error())
}
if dataAsBytes == nil {
return nil, fmt.Errorf("%s does not exist", dataNumber)
}
data := new(Data)
_ = json.Unmarshal(dataAsBytes, data)
return data, nil
}
func (s *SmartContract) QueryAllDatas(ctx contractapi.TransactionContextInterface) ([]QueryResult, error) {
startKey := ""
endKey := ""
resultsIterator, err := ctx.GetStub().GetStateByRange(startKey, endKey)
if err != nil {
return nil, err
}
defer resultsIterator.Close()
results := []QueryResult{}
for resultsIterator.HasNext() {
queryResponse, err := resultsIterator.Next()
if err != nil {
return nil, err
}
data := new(Data)
_ = json.Unmarshal(queryResponse.Value, data)
queryResult := QueryResult{Key: queryResponse.Key, Record: data}
results = append(results, queryResult)
}
return results, nil
}
func main() {
chaincode, err := contractapi.NewChaincode(new(SmartContract))
if err != nil {
fmt.Printf("Error create test chaincode: %s", err.Error())
return
}
if err := chaincode.Start(); err != nil {
fmt.Printf("Error starting test chaincode: %s", err.Error())
}
}上传的数据叫做Data,Record包含“total”(累计流量,单位L)和“now”(瞬时流量,单位L/H);Key是查询的时间,形如“2022-07-20 19:00”,将格式化的定长时间字符串作为Key可以避免由字典序排列引起的查询结果乱序问题。
稍微修改一下上篇博客里的收发python文件,主要是调试时出现过参数类型的问题,修改完之后receive.py在接收数据后截取出数据位,转化成十进制,再转化为浮点数除以100,然后以字符串形式存入data.txt。
receive.py:
# -*- coding:utf-8 -*-
import RPi.GPIO as GPIO
import serial
EN_485 = 4
GPIO.setwarnings(False)
GPIO.setmode(GPIO.BCM)
GPIO.setup(EN_485,GPIO.OUT)
GPIO.output(EN_485,GPIO.LOW)
ser = serial.Serial("/dev/ttyAMA0",9600,timeout=1) # open first serial port
while 1:
Str = ser.readall()
if Str:
print (Str)
string=Str.hex()
data=string[6:14]
print(data)
res=int(data,16)
#print(res)
result=float(res)/100
#print(result)
note=open('/home/pi/Desktop/hyperledger/multinodes-pi/data.txt',mode='w')
note.write(str(result))
note.close()
#break
为了方便shell脚本的调用,我把原先的send.py分成了两个,一个query_now用来查询瞬时流量,一个query_total用来查询累计流量。
query_now.py:
# -*- coding:utf-8 -*-
import RPi.GPIO as GPIO
import serial
EN_485 = 4
GPIO.setwarnings(False)
GPIO.setmode(GPIO.BCM)
GPIO.setup(EN_485,GPIO.OUT)
GPIO.output(EN_485,GPIO.HIGH)
t = serial.Serial("/dev/ttyAMA0",9600)
print (t.portstr)
strInput = '01 03 00 00 00 02 C4 0B'
str=bytes.fromhex(strInput)
print(str)
n = t.write(str)
print (n)
query_total.py:
# -*- coding:utf-8 -*-
import RPi.GPIO as GPIO
import serial
EN_485 = 4
GPIO.setwarnings(False)
GPIO.setmode(GPIO.BCM)
GPIO.setup(EN_485,GPIO.OUT)
GPIO.output(EN_485,GPIO.HIGH)
t = serial.Serial("/dev/ttyAMA0",9600)
print (t.portstr)
strInput = '01 03 00 02 00 02 65 CB'
str=bytes.fromhex(strInput)
print(str)
n = t.write(str)
print (n)
然后就是shell脚本的编写,我预想的逻辑是首先开启receive.py保持接收数据,然后3min一次循环调用脚本。每次循环先是调用一次query_now.py,此时data.txt会通过receive.py存入瞬时流量值的数据,用shell命令读取出数据存入变量n;再调用一次query_total.py,相同的方法读出累计流量值数据存入变量t。n和t再和当前时间time组成一条命令“AddData”写入add.sh这一脚本,最后在cli容器里调用add脚本完成数据上传的操作。为了预留足够的时间给流量计通讯以及python的数据写入等工作,我在运行pyhton文件之后会等待3s的时间,确保数据写入的操作已经完成。
但是很不幸,一个莫名其妙的bug卡了我整整一个下午。。按照上述的逻辑进行到shell命令从data.txt中读命令这一步时,它读出来的永远是空串?在确认了逻辑无误后我在网上查了很久也查不到和我遇到的相同的bug,相对来说比较可能的说法是脚本读取文件时光标位置出错,由于文件没有关闭,读取操作结束后光标会一直停留在文件末尾,所以下次再读时是从文件末尾开始读,读出来的就是空串。这样看来是我shell命令读完之后文件没有正确关闭吗?那起码第一次得能读出数据吧,我连一次都没读出来过。。另一次文件操作也就只有receive.py里写入数据的过程了,但是我也的确写了关闭文件这个操作,我唯一能猜测的可能性就是树莓派系统的shell命令行对文件是否关闭的判断与python有点冲突,因为我用shell脚本读其他未被python操作过的文件都是能读出数据的,唯独这个被python改写过的data.txt不行。后来我就想怎么让shell读取时光标再重新回到文件起始位置?我用shell也写点东西进去,写入完毕之后应该会关上文件吧?于是我就用shell语句写了一个空格添加在data.txt的末尾,然后再用“while read rows”读取,就这样还真解决了这个bug。。。当然以上的原因都是我的猜想,如果有大佬明白真正原因的也请评论区告诉我一下~感谢!
最后能成功运行的test.sh是这样的:
#!/bin/bash
for i in {1..20}
do
sudo python /home/pi/RS485_CAN_HAT_Code/485/python/query_now.py
time=$(date "+%Y-%m-%d %H:%M")
sleep 3
echo " " >> data.txt
while read rows
do
n=$rows
break
done < data.txt
sudo python /home/pi/RS485_CAN_HAT_Code/485/python/query_total.py
sleep 3
echo " " >> data.txt
while read rows
do
t=$rows
break
done < data.txt
echo "这是第"$i"次查询到并添加的数据:"
echo "Now(L/H):"$n" Total(L):"$t" time:"$time
cmd="'{\"Args\":[\"AddData\",\"$time\",\"$n\",\"$t\"]}'"
echo "Add命令:"$cmd
echo "#!/bin/bash
peer chaincode invoke -o orderer.example.com:7050 --tls true --cafile /opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem -C mychannel -n test --peerAddresses peer0.org1.example.com:7051 --tlsRootCertFiles /opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/tls/ca.crt --peerAddresses peer0.org2.example.com:7051 --tlsRootCertFiles /opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/peerOrganizations/org2.example.com/peers/peer0.org2.example.com/tls/ca.crt -c "$cmd "
exit"> add.sh
docker cp add.sh cli:/opt/gopath/src/github.com/hyperledger/fabric/peer/
docker exec -it cli bash add.sh
sleep 174
#break
done
差不多准备就绪了,在家里的洗手间搭了一下实验环境:


四、运行结果
test.sh启动,挂了大概一个小时:

Org1查询的结果,按照时间顺序排序:

搞定!