- BERT的“[CLS]”标记生成的原生句子表示在句子评估基准(如语义文本相似性(STS)任务)上表现非常糟糕。
- 缺乏有效的自监督句子训练集
- 通常自监督方法:通过加mask生成,或者对比(NSP)
- ConSERT标记变换、特征截断
- SimCSE使用不同 的dropout掩码
- 自监督学习:支持生成内容选择,效果不错,但在句子方向应用少
- 现有:句子视为整体,句间不同
- 本文:句内视角
- 短语感知的句子表示(PaSeR):在句子表示中将最重要短语编码
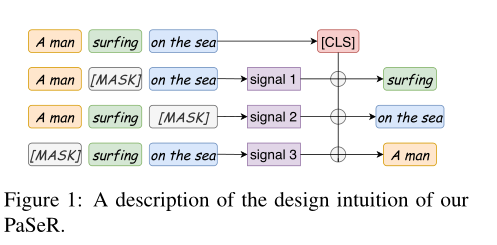
- 核心方法
- 短语提取:一个句子句法解析树中的随机子树。通过使用NLTK (Loper and Bird, 2002),我们可以很容易地提取一个句子的组成部分,包括从句(SBAR),动词短语(VP)和名词短语(NP)。
- 统计关键短语提取算法,RAKE (Rose等人,2010)。RAKE首先使用停顿词或标点符号将原句子或文档标记成短语。为了获得每个短语的重要性,RAKE首先构建单词的共现矩阵,并通过其在共现矩阵中的度deg(w)和其在文档或句子中的频率freq (w)计算单词w的重要性。最后,通过对该短语中所有单词的wordScore求和来计算该短语的重要性。(best perform)

-

- Duplicate and Masking
- 差分模型:具体来说,对于一个给定的句子s,它由多个短语P = {p0, p1,…, pn},按RAKE计算的重要性排序(Rose et al., 2010)。为了恢复像p0这样最重要的短语,我们很自然地提出了以下等式:
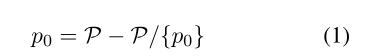
- 把句子s复制成s~,把我们想生成的最重要短语p0mask,把句子编码表示为Enc,然后得句子表示如下。

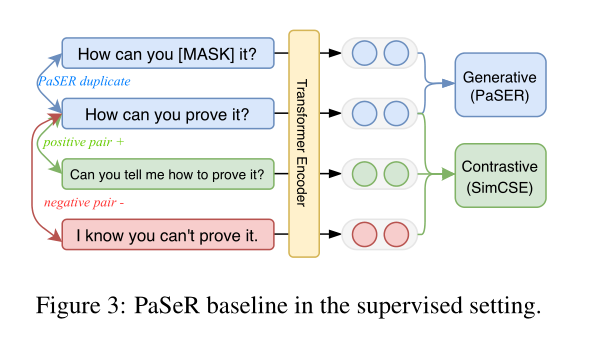
- PaSeR

- 左边的部分展示了共享参数的句子编码器。
- 右边是生成解码器,在evaluation过程中舍弃
因此,额外的参数只在训练阶段使用,不影响评估阶段的推理速度。
- 通过结合Es和Es~的表示,我们可以使用合适的解码器恢复屏蔽短语p0。
- 差分模型:具体来说,对于一个给定的句子s,它由多个短语P = {p0, p1,…, pn},按RAKE计算的重要性排序(Rose et al., 2010)。为了恢复像p0这样最重要的短语,我们很自然地提出了以下等式:
- 数据扩增
- 同义词替换、随机删除和token重排序
- 在S和S~上使用同义词替换:tokens不同的语义相似短语,帮助模型捕获语义相似而不是tokens相似
- 随机删除:减轻频繁的单词或短语带来的影响
- Token Reordering:句子编码器对标记顺序和位置嵌入的变化不那么敏感
- 无监督PaSeR:
- 句子编码:基于Bert预训练模型,pooling method 包括
- 直接用[CLS]
- 对Bert的最后一层token表示求平均
- 使用Bert中间层的加权平均token
- 解码信号

- 这里m和n为scaling factors,对这四个解码信号进行归一化,通过网格搜索选择这两个变量。我们将在附录A中讨论m和n的选择。
- generative decoder
- 生成式译码器用作训练句子编码器的正则表示器,evaluation阶段抛弃。因此不给下游任务添加任何额外参数
- transformers的decoder 变体作为我们的短语重构decoder Dec
- 假设masked短语p0由若干tokens组成,给定解码信号SignalDec,则短语重构过程为
- 公式

- masked language model结合
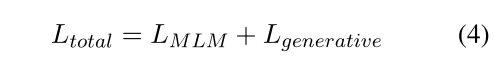
- 句子编码:基于Bert预训练模型,pooling method 包括
- 有监督PaSeR:无监督PaSeR可以为训练有监督句子编码器提供良好的初始化检查点
- 在句子表示学习中引入监督信号
- 依据SBERT的序列分类训练
- 根据SimCSE的训练学习
- 本文选SimCSE引入的contrastive loss和我们PaSeR的loss

- 从无监督PaSeR的最好表现点初始化encoder。loss函数终极形态
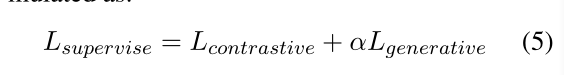
α是实验中的可调超参数
- 在句子表示学习中引入监督信号
- 实验
- 数据
- 评估数据集:STS。数据集人工标记的分数0~5。
- 我们使用这7个STS数据集的spearman相关性x 100来评估和比较所有基线和前沿研究之间的性能
- Quora问题对:问题重复对表示为(q1, q2),把p2作为问题库,所有所有的q1都至少有一个正配对的q2作为查询集。然后使用查询集从问题语料库中检索类似的问题。评价指标包括平均平均精度(MAP)和平均倒数秩(MRR)。
- AskUbuntu Question:语义重排序数据集。每个查询给出的问题语料库大小为20个,模型需要根据相似度度量对这20个给定问题进行重新排序。我们还使用MAP和MRR作为评价指标。
- 训练细节
- 编码器:bert-base
- 序列最大长度:32
- 初始学习率:3e-5
序列最大长度和初始学习率遵从SimCSE
- batch size:[32,64,96]中选择
- 无监督学习下:混合STS的七个数据集
- 监督环境下:SNLI+MNLI组合,SimCSE+PaSeR结合训练编码器。
- 句子表示:[CLS]
- generative decoder:6层transformer decoder
generative可以接受任何类型的transformer decoder
- 单词embedding layer由sentence encoder 和generative decoder共享
- 语义文本相似度结果
- 无监督
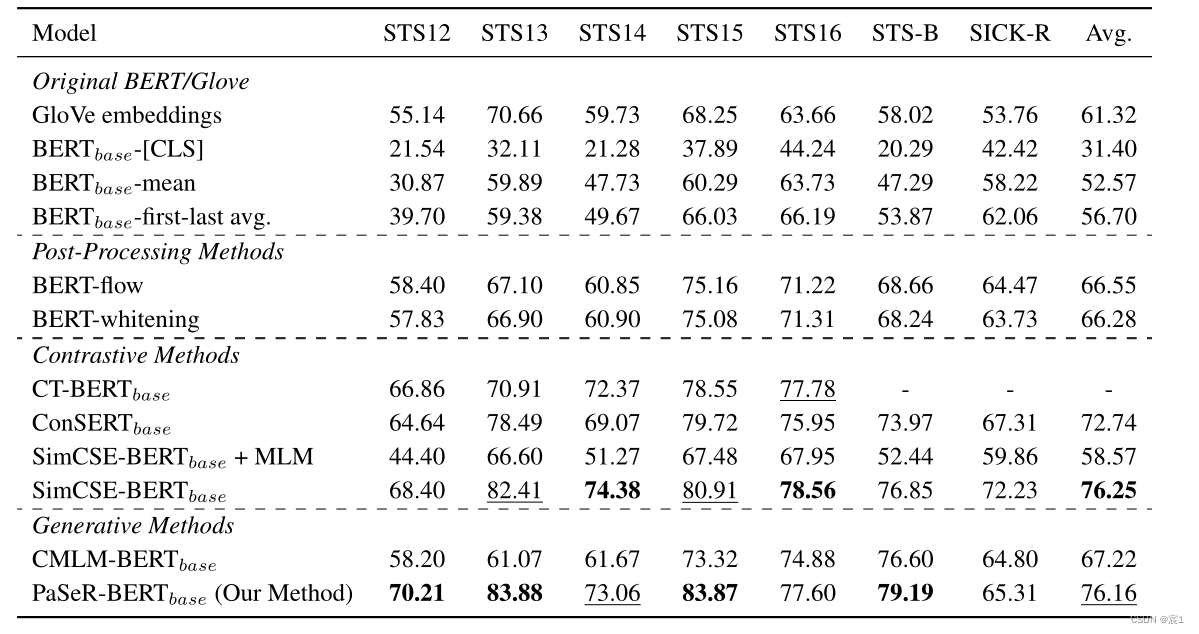
粗体的统计数据表示最佳性能,而下划线的统计数据表示次优性能。
- 有监督
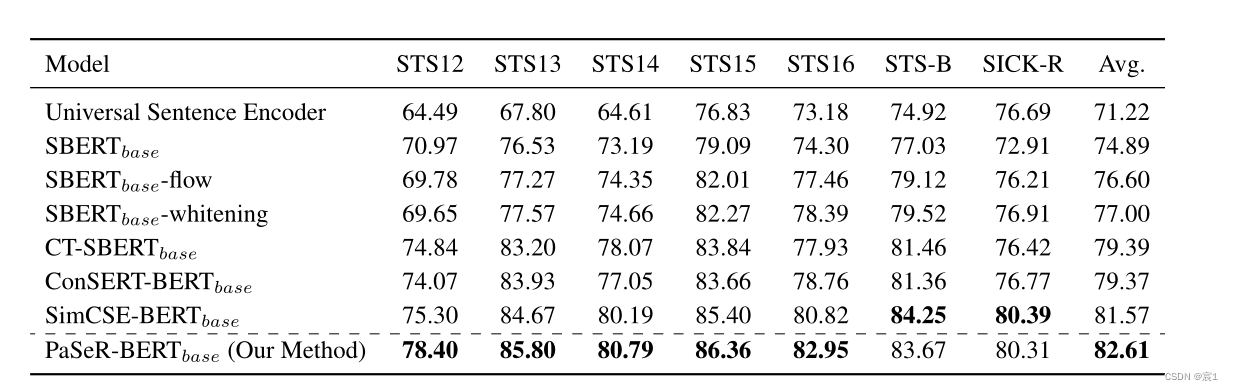
- 语义检索/重排序
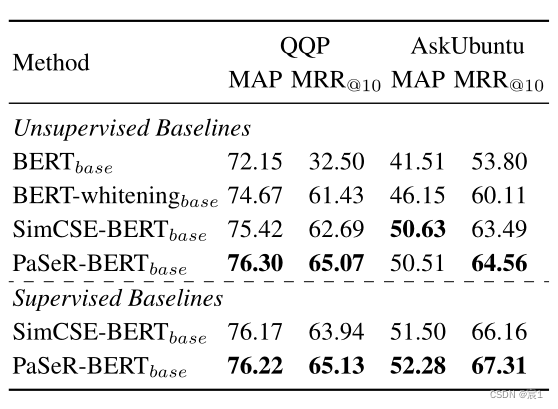
- 无监督
- 消融实验
- generative decoder的复杂度
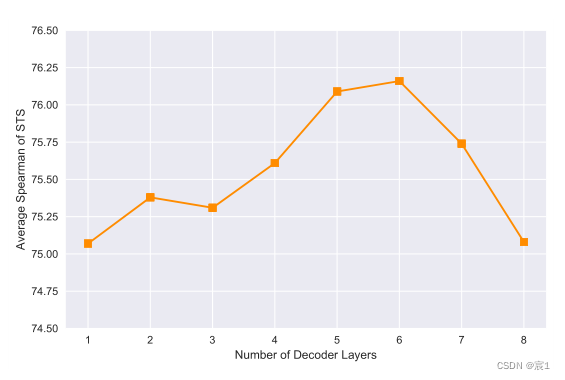
推测这是因为太小的生成器缺乏足够的模型容量,而太大的生成器往往会导致训练数据的过拟合
- 数据增强
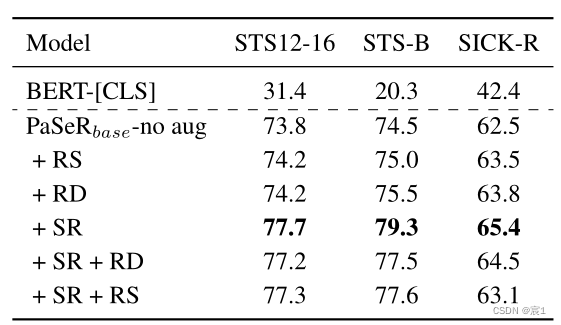
同义词替换(SR) 随机交换(RS)随机删除(RD)
- mask短语选择:
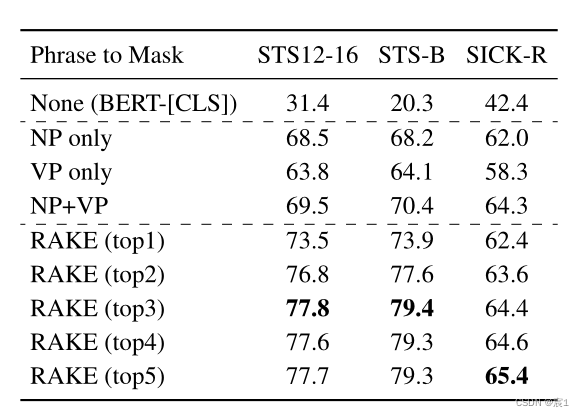
- NLTK:
- 只屏蔽名词短语NP
- 只屏蔽verb短语VP
- 同时屏蔽NP\VP
- RAKE屏蔽:选择屏蔽的最重要短语的数量
- NLTK:
- generative decoder的复杂度
- 数据
- 定性分析
- 句子检索
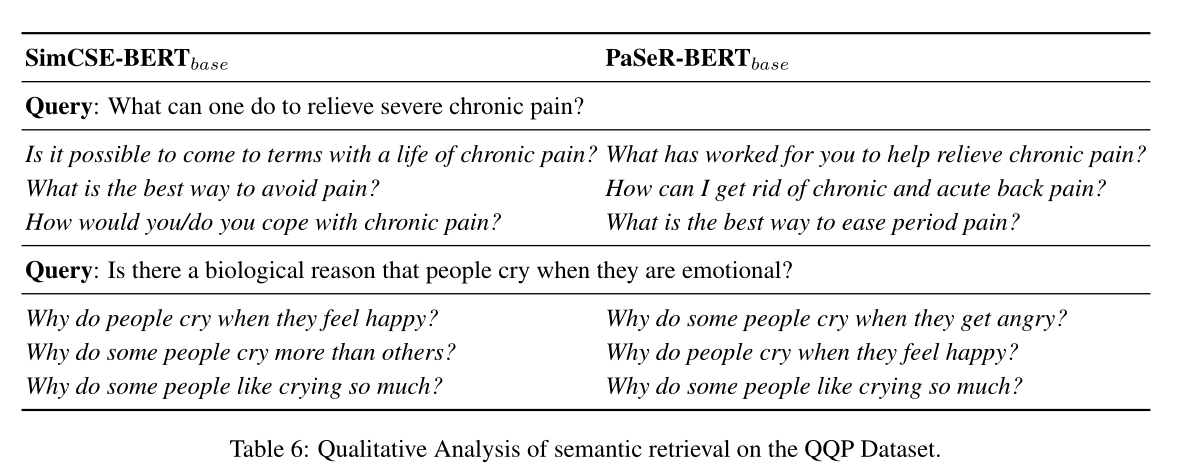
- 解码器生成的短语
- 生成文本与原始文本不同

- 生成文本与原始文本不同
- 句子检索
基于短语的句子学习模型Sentence Representation Learning withGenerative Objective rather than Contrastive Object
猜你喜欢
转载自blog.csdn.net/qq_56061892/article/details/127628426
今日推荐
周排行