18.5 Spark On Hive⭐️
18.5.1 UDF
-
UDF特点:
- one to one ,进来一个出去一个,row mapping,是row级别的操作
-
举例
- upper、substr函数
-
实现代码
package com.yjxxt import org.apache.spark.sql.SparkSession import org.apache.spark.sql.types.DataTypes object HelloHiveUDF { def main(args: Array[String]): Unit = { //搭建环境 val sparkSession =SparkSession.builder().master("local").appName("HelloHiveUDF").enableHiveSupport().getOrCreate() //定义UDF sparkSession.udf.register("strLen", (x: String) => { x.size }, DataTypes.IntegerType) //SQL sparkSession.sql("use yjx") val dataFrame = sparkSession.sql("select id,strLen(uname) from t_user") //打印数据 dataFrame.show() //关闭 sparkSession.stop() } }
18.5.2 UDAF
-
特点:
- many to noe,进来多个出去一个 ,row mapping 是row级别的操作
-
举例
- sum、min
-
代码实现
18.5.3 UDTF
-
特点
- one to many,进来一个出去多行,
- 通过实现抽象类org.apache.hadoop.hive.ql.udf.generic.GenericUDTF来自定义UDTF算子
-
举例
- lateral view、explode,
-
代码实现
18.5.4 开窗函数
- 概念理解
- row_number()开窗函数是按照某个字段分组,然后取另一个字段的前几个的值,相当于分组取topN
- 开窗函数格式
- row_number() over (partitin by XXX order by XXX)
十九、Spark Streaming
19.1 Spark Streaming简介及与Storm的区别
19.1.1 Spark Streaming简介
-
简介
- SparkStreaming是 流式处理框架 ,是Spark API(RDD)的扩展,支持可扩展、高吞吐量、容错的准实时数据流处理
-
实时数据流的来源
- Kafka、Flume、Twitter、ZeroMQ、Kinesis 以及 TCP Sockets。
- 从数据源获取数据之后,可以使用诸如 map、reduce、join 和 window 等高级函数进行复杂算法的处理,最后还可以将处理结果存储到文件系统、数据库和现场仪表盘中

-
DStream
- Spark Streaming将产生高度分离的数据流叫DStream(discretized Stream);DStream既可以从输入数据源创建得来,(如Kafka、Flume或者Kinesis)也可以从其他DStream经过一些算子操作得来;
- 在内部,一个DStream就包含一系列的RDDs
-
Spark Streaming 的一些常用术语
名称 说明 离散流(Discretized Stream)或 DStream Spark Streaming 对内部持续的实时数据流的抽象描述,即处理的一个实时数据流,
在 Spark Streaming 中对应于一个 DStream 实例。时间片或批处理时间间隔(BatchInterval) 拆分流数据的时间单元,一般为 500 毫秒或 1 秒。 批数据(BatchData) 一个时间片内所包含的流数据,表示成一个 RDD。 窗口(Window) 一个时间段。系统支持对一个窗口内的数据进行计算 窗口长度(Window Length) 一个窗口所覆盖的流数据的时间长度,必须是批处理时间间隔的倍数。 滑动步长(Sliding Interval) 前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数。 Input DStream 一个 Input DStream 是一个特殊的 DStream。
19.1.2 Spark Streaming与Storm的区别
- 处理模型以及延迟
- 虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。
- Storm可以实现亚秒级时延的处理,而每次只处理一条event,
- 而Spark Streaming可以在一个短暂的时间窗口里面处理多条(batches)Event。
- 所以说Storm可以实现亚秒级时延的处理,而Spark Streaming则有一定的时延。
- 容错和数据保证
- Storm可能被处理多次、
- 在Storm中,每条记录在系统的移动过程中都需要被标记跟踪,所以Storm只能保
证每条记录最少被处理一次,但是允许从错误状态恢复时被处理多次。这就意味着可变更的状态可能被更新两次从而导致结果不正确
- 在Storm中,每条记录在系统的移动过程中都需要被标记跟踪,所以Storm只能保
- Spark Streaming只能被处理一次
- Spark Streaming仅仅需要在批处理级别对记录进行追踪,所以他能保证每个批处理记录仅仅被处理一次,即使是node节点挂掉
- 虽然说Storm的 Trident library可以保证一条记录被处理一次,但是它依赖于事务更新状态,而这个过程是很慢的,并且需要由用户去实现
- Storm可能被处理多次、
- 实现和编程API
- Storm主要是由Clojure语言实现,Spark Streaming是由Scala实现
- Storm提供了Java API,同时也支持其他语言的API。 Spark Streaming支持Scala和Java语言(其实也支持Python)
- 批处理框架集成
- Spark Streaming的一个很棒的特性就是它是在Spark框架上运行的
- 这样你就可以想使用其他批处理代码一样来写Spark Streaming程序,或者是在Spark中交互查询。这就减少了单独编写流批量处理程序和历史数据处理程序
- Spark Streaming的一个很棒的特性就是它是在Spark框架上运行的
- 生产支持
- Storm已经出现好多年了,而且自从2011年开始就在Twitter内部生产环境中使用,还有其他一些公司。而Spark Streaming是一个新的项目,并且在2013年仅仅被Sharethrough使用(据作者了解)。
- Storm是 Hortonworks Hadoop数据平台中流处理的解决方案,而Spark Streaming出现在MapR的分布式平台和Cloudera的企业数据平台中。除此之外,Databricks是为Spark提供技术支持的公司,包括了Spark Streaming。
19.2 Spark Streaming流式计算⭐️
19.2.1 流式计算过程
-
计算流程
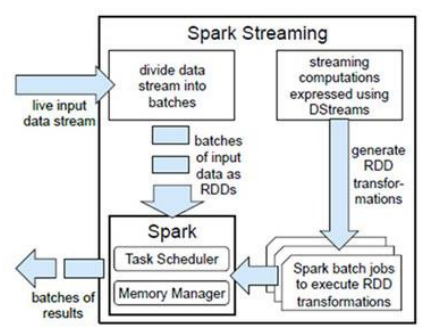
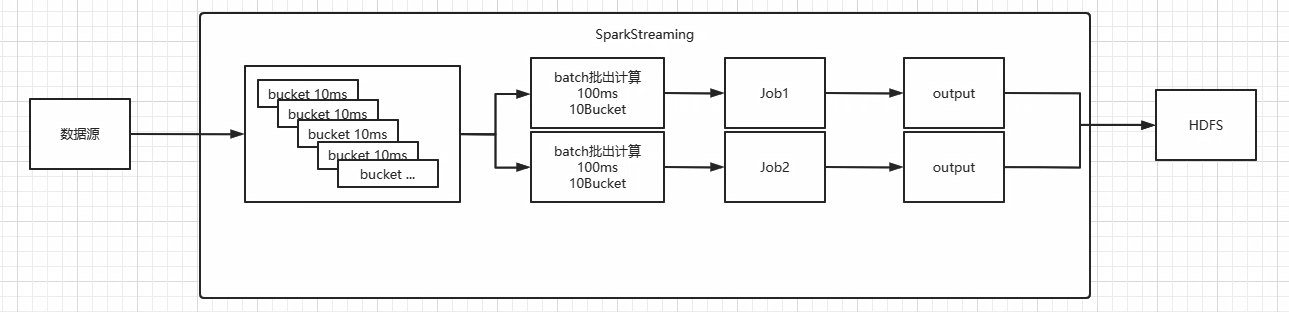
- 分解计算作业
- SparkStreaming 是将流式计算分解成一系列短小的批处理作业
- Job1和Job2 的计算逻辑相同,但是计算时间不同(先后顺序)
- 批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream)
- SparkStreaming 是将流式计算分解成一系列短小的批处理作业
- 转换分解数据
- 每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset)
- 转换算子操作数据
- 然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作
- 存储中间结果或导出
- 将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备
- 分解计算作业
-
Spark Streaming在内部的处理机制
- 实时流数据的接收、拆分、处理、得到结果
- 接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据
- 批数据对应RDD实例
- 对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列
- 处理机制总结
- 在内部,DStream 是由一系列 RDD 组成的。一批数据在 Spark 内核中对应一个 RDD 实例。因此,对应流数据的 DStream 可以看成是一组 RDD,即 RDD 的一个序列。也就是说,在流数据分成一批一批后,会通过一个先进先出的队列,Spark Engine 从该队列中依次取出一个个批数据,并把批数据封装成一个 RDD,然后再进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。
- 实时流数据的接收、拆分、处理、得到结果
-
receiver task

- 工作原理
- receiver task是 7*24 小时一直在执行,一直接受数据,将一段时间内接收来的数据保存到batch中。
- 假设batchInterval 为 5s,那么会将接收来的数据每隔 5 秒封装到一个 batch 中
- 假设batchInterval为5秒,每隔5秒通过SparkStreamin将得到一个DStream,在第6秒的时候计算这5秒的数据,假设执行任务的时间是3秒,那么第6到9秒一边在接收数据,一边在计算任务,9~10秒只是在接收数据。然后在第11秒的时候重复上面的操作
- batch 没有分布式计算特性,这一个batch的数据又被封装到一个RDD中最终封装到一个DStream中,然后sparkStreaming回启动一个job去计算
- 问题:如果job执行的时间大于batchInterval(批处理间隔)?
- 如果接受过来的数据设置的级别是仅内存,接收来的数据会越堆积越多,最后可能会导致OOM
- 如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟
- 工作原理
19.2.2 流式计算特性
-
容错性
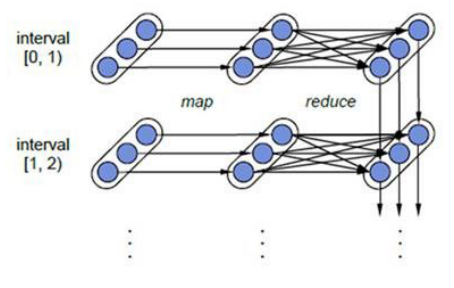
- 理解Spark中的RDD容错机制
- 每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系(lineage)
- 只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
- 结合上图理解
- 图中的每一个椭圆形表示一个RDD,椭圆形中的每个圆形代表一个RDD中的一个Partition
- 图中的每一列的多个RDD表示一个DStream(图中有三个DStream),而每一行最后一个RDD则表示每一个Batch Size所产生的中间结果RDD。
- 图中的每一个RDD都是通过lineage相连接的
- 理解Spark中的RDD容错机制
-
实时性
- 分解任务
- Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程
- 延迟及适用场景
- 对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右)
- 所以Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景
- 分解任务
-
扩展性与吞吐量
- Spark目前在EC2上已能够线性扩展到100个节点(每个节点4Core),可以以数秒的延迟处理6GB/s的数据量(60M records/s),其吞吐量也比流行的Storm高2~5倍
19.2.3 编程模型DStream
-
概念理解
- DStream 它表示的事连续数据流,可以是源数据接收的输入流,也可以事通过转换输入流生成的已处理的数据流;
- 在内部,DStream由一系列的RDD组成;
- DStream中的每个RDD都包含了自己特定时间间隔内的数据流。

-
DStream与RDD
Spark Streaming 计算还是基于Spark Core的,Spark Core 的核心又是RDD. 所以Spark Streaming 肯定也要和RDD扯上关系
- 一组RDD的抽象概念
- Spark Streaming 并没有直接让用户使用RDD而是自己抽象了一套DStream的概念。
- DStream包含了RDD
- DStream 和 RDD 是包含的关系,你可以理解为Java里的装饰模式,也就是DStream 是对RDD的增强,但是行为表现和RDD是基本上差不多的。
- 一组RDD的抽象概念
-
生命周期
- 接收数据
- 在InputDStream会将接受到的数据转化成RDD,比如DirectKafkaInputStream 产生的就是KafkaRDD
- 转换数据
- 接着通过MappedDStream等进行数据转换,这个时候是直接调用RDD对应的map方法进行转换的
- 输出数据
- 在进行输出类操作时,才暴露出RDD,可以让用户执行相应的存储,其他计算等操作
- 接收数据
-
对于DStream算子的理解
-
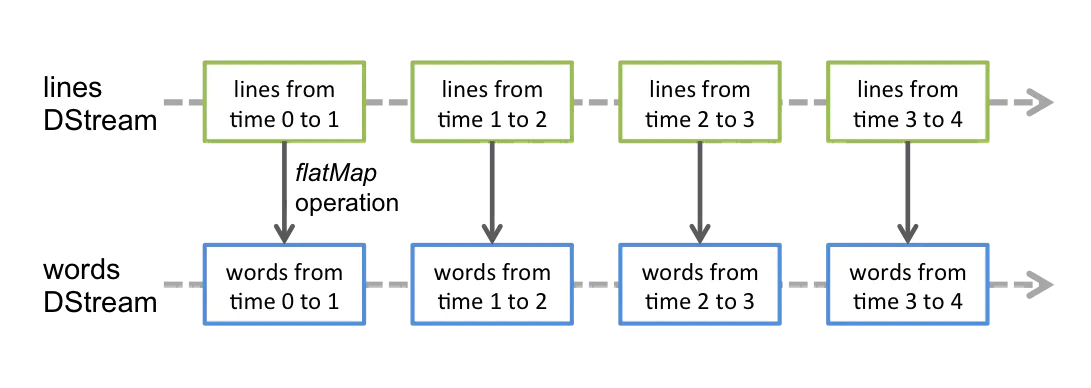
任何作用于DStream的算子,其实都会被转化为对其内部RDD的操作。
-
例如,我们将 lines 这个DStream转成words DStream对象,其实作用于lines上的flatMap算子,会施加于lines中的每个RDD上,并生成新的对应的RDD,而这些新生成的RDD对象就组成了words这个DStream对象。其过程如下图所示
-
19.3 Spark Streaming代码实现
19.3.1 代码实现
-
pom.xml
-
启动socket server服务器(指定9999端口号)
- 【Linux】nc –lk 9999
- 【Window】nc –lp 9999
-
优雅的停止sparkstreaming
- 将spark.streaming.stopGracefullyOnShutdown #设置成true
sparkConf.set("spark.streaming.stopGracefullyOnShutdown","true")- 系统会发送一个SIGTERM的信号给对应的程序。这个信号是termination不同于-9的直接kill,它同样会结束进程但是会给进程时间善后
kill -15 driverpid -
注意点
- receiver模式下接受数据,local的模拟线程必须大于等于2,一个线程用来receiver用来接受数据,另一个线程用来执行job。
- setMaster(“local[2]”)
- Durations时间设置就是我们能接收的延迟度。这个需要根据集群的资源情况以及任务的执行情况来调节。
- StreamingContext.start() Streaming框架启动后不能再次添加业务逻辑。
- StreamingContext.stop() 无参的stop方法将SparkContext一同关闭,stop(false),不会关闭SparkContext。
- StreamingContext.stop()停止之后不能再调用start。
- receiver模式下接受数据,local的模拟线程必须大于等于2,一个线程用来receiver用来接受数据,另一个线程用来执行job。
-
代码实现
19.3.2 DStream转换操作⭐️
1. 无状态转换操作
-
概念理解
- 每个批次的处理不依赖于之前批次的操作
- 无状态转换操作就是把简单的RDD转换操作应用到每个批次上,也就是转换DStream上的每一个RDD,下表是部分无状态转换操作算子
-
常见的无状态转换
- map、flatMap、filter、repartition、reduceByKey、groupByKey
- 直接作用在DStream上
- 重要的转换操作:transform
- Transform 是一个比较特殊的无状态转换算子。它允许DStream 上执行任意的 RDD-to-RDD 函数,即使函数并没有在DStream的API中暴露出来,通过该函数可以方便的扩展Spark API,该函数每一批次调度一次,Transform其本质是对DStream中的RDD进行转换
-
对无状态转换的理解
- 尽管这些算子看起来像作用在整个流上一样,但事实是每个DStream在内部都是由许多的RDD(批次)组成,且无状态转换操作时分别应用到每个RDD上的。
- 例如:reduceBykey() 会规约每个时间区间的数据,但不会规约不同区间之间的数据。在Streaming wordCount 输出结果可以看出,我们只会统计采集周期内的单词个数,而不是跨采集周期进行累加
-
常见的无状态转换
Transformation Meaning map(func) 将源DStream中的每个元素通过一个函数func从而得到新的DStreams flatMap(func) 和map类似,但是每个输入的项可以被映射为0或更多项 filter(func) 选择源DStream中函数func判为true的记录作为新DStreams repartition(numPartitions) 通过创建更多或者更少的partition来改变此DStream的并行级别 union(otherStream) 联合源DStreams和其他DStreams来得到新DStream count() 统计源DStreams中每个RDD所含元素的个数得到单元素RDD的新DStreams reduce(func) 通过函数func(两个参数一个输出)来整合源DStreams中每个RDD元素得到单元素RDD的DStreams。这个函数需要关联从而可以被并行计算 countByValue() 对于DStreams中元素类型为K调用此函数,得到包含(K,Long)对的新DStream,其中Long值表明相应的K在源DStream中每个RDD出现的频率 reduceByKey(func, [numTasks]) 对(K,V)对的DStream调用此函数,返回同样(K,V)的新DStream,新DStream中的对应V为使用reduce函数整合而来。默认情况下,这个操作使用Spark默认数量的并行任务(本地模式为2, 集群模式中的数量取决于配置参数spark.default.parallelism)。 也可以传入可选的参数numTasks来设置不同数量的任务 join(otherStream, [numTasks]) 两DStream分别为(K,V)和(K,W)对,返回(K,(V,W))对的新DStream cogroup(otherStream, [numTasks]) 两DStream分别为(K,V)和(K,W)对,返回(K,(Seq[V],Seq[W])对新DStreams transform(func) 将RDD到RDD映射的函数func作用于源DStream中每个RDD上得到新DStream。这个可用于在DStream的RDD上做任意操作
2. 有状态转换操作
- updateStateByKey操作
- 得到”状态”DStream,其中每个key状态的更新是通过将给定函数用于此key的上一个状态和新值而得到。这个可用于保存每个key值的任意状态数据
- 一个简单的案例理解是可以对之前输入的数据进行一个记录更新的操作
- 如输入两次 aa,就会产生两个aa,生成(aa,2)会累加之前的状态值
- 对于updateStateByKey 保存任意状态的实现
- 该 updateStateByKey 操作可以让你保持任意状态,同时不断有新的信息进行更新。要使用此功能,必须进行两个步骤 :
- 定义状态 - 状态可以是任意的数据类型。
- 定义状态更新函数 - 用一个函数指定如何使用先前的状态和从输入流中获取的新值 更新状态
- 使用到updateStateByKey要开启checkpoint机制和功能
- 该 updateStateByKey 操作可以让你保持任意状态,同时不断有新的信息进行更新。要使用此功能,必须进行两个步骤 :
19.3.3 DStream窗口操作
-
概念理解
-
版本一
- 在Spark Streaming中,数据处理是按批进行的,而数据采集是逐条进行的,因此在Spark Streaming中会先设置好批处理间隔(batch duration),当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给系统去处理。
- 对于窗口操作而言,在其窗口内部会有N个批处理数据,批处理数据的大小由窗口间隔
(window duration)决定,而窗口间隔指的就是窗口的持续时间,在窗口操作中,只有窗口的长度满足了才会触发批数据的处理。除了窗口的长度,窗口操作还有另一个重要的参数就是滑动间隔(slide duration),它指的是经过多长时间窗口滑动一次形成新的窗口, - 滑动窗口默认情况下和批次间隔的相同,而窗口间隔一般设置的要比它们两个大。在这里必须注意的一点是滑动间隔和窗口间隔的大小一定得设置为批处理间隔的整数倍
-
版本二
-
管中窥豹,基本上就能够很形象的解释什么是窗口函数了。DStream数据流就是那只豹子,窗口就是那个管,以一个固定的速率平移,就能够每次看到豹的一部分。
-
窗口函数,就是在DStream流上,以一个可配置的长度为窗口,以一个可配置的速率向前移动窗口,根据窗口函数的具体内容,分别对当前窗口中的这一波数据采取某个对应的操作算子。
-
需要注意的是窗口长度,和窗口移动速率需要是batch time的整数倍
-
-
-
window(windowLength, slideInterval)窗口函数
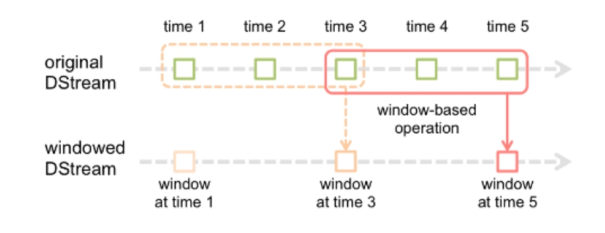
- 批处理间隔是1个时间单位,窗口间隔是3个事件单位,滑动间隔是2个事件单位
- 窗口长度和滑动间隔必须是batchInterval的整数倍,否则会检测报错
- window(windowLength, slideInterval)
– 窗口总长度(window length):你想计算多长时间的数据
– 滑动时间间隔(slide interval):你每多长时间去更新一次
-
转换算子
-
print()
- 在Driver中打印出DStream中数据的前10个元素。
-
saveAsTextFiles(prefix,[suffix])
- 将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。
-
foreachRDD(func)
- 最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或者网络数据库等。需要注意的是func函数是在运行该streaming应用的Driver进程里执行的。
- 使用注意

-
19.4 Spark Streaming检查点
19.4.1 介绍
- 对于引入检查点的介绍
- 流应用程序必须保证7*24全天候运行,因此必须能够适应与程序逻辑无关的故障【例如:系统故障、JVM崩溃等】。为了实现这一点,SparkStreaming需要将足够的信息保存到容错存储系统中,以便它可以从故障中恢复。
- 检查点类型
- 元数据检查点
- 将定义流式计算的信息保存到容错存储系统【如HDFS等】。这用于从运行流应用程序所在的节点的故障中恢复。
- 元数据包括:
- 配置 :用于创建流应用程序的配置。
- DStream操作:定义流应用程序的DStream操作集。
- 不完整的批次:在任务队列中而尚未完成的批次。
- 数据检查点
- 将生成的RDD保存到可靠的存储系统。在一些跨多个批次组合数据的有状态转换中,这是必须的。在这种转换中,生成的RDD依赖于先前批次的RDD,这导致依赖关系链的长度随着时间而增加。
- 为了避免恢复时间的这种无限增加【与依赖链成正比】,有状态变换的中间RDD周期性地检查以存储到可靠的存储系统中,以切断依赖链。
- 元数据检查点
19.4.2 需要检查点的情况
- 有状态转换的使用
- 如果在应用程序中使用了updateStateByKey或reduceByKeyAndWindow,则必须提供检查点以缓存之前批次的中间结果
- 从运行应用程序的节点故障中恢复,元数据检查点用于使用进度信息进行恢复
19.4.3 配置检查点
- 文件系统中保存
- 可以通过在容错、可靠的文件系统中设置目录来启用检查点,检查点信息将保存到该文件系统中
- 使用:streamingContext.checkpoint(checkpointDirectory)来设置的。
- 这将允许使用上述状态转换。此外,如果要使应用程序从节点故障中恢复,则应重写流应用程序以使其具有以下行为。
- 当程序首次启动时,它将创建一个新的StreamingContext,设置所有流后调用start()。
- 当程序在失败后重新启动时,它将从检查点目录中的检查点数据重新创建StreamingContext。
19.5 Spark Streaming数据源
19.5.1 基础数据源
- 文本本地数据源
- Spark Streaming提供了streamingContext.socketTextStream()方法,可以通过 TCP 套接字连接,从文本数据中创建了一个 DStream
- 文件系统数据源
- Spark Streaming提供了streamingContext.fileStream(dataDirectory)方法可以从任何文件系统(如:HDFS、S3、NFS 等)的文件中读取数据
- 然后创建一个DStream。Spark Streaming 监控 dataDirectory 目录和在该目录下任何文件被创建处理(不支持在嵌套目录下写文件)。
- 需要注意的是:读取的必须是具有相同的数据格式的文件;创建的文件必须在 dataDirectory目录下,并通过自动移动或重命名成数据目录;文件一旦移动就不能被改变,如果文件被不断追加,新的数据将不会被阅读。
- Spark Streaming提供了streamingContext.fileStream(dataDirectory)方法可以从任何文件系统(如:HDFS、S3、NFS 等)的文件中读取数据
- 简单的文本文件数据源
- Spark Streaming提供了streamingContext.textFileStream(dataDirectory)来读取简单的文本文件
- 自定义Actors流的DStream
- Spark Streaming提供了streamingContext.actorStream(actorProps, actor-name)可以基于自定义 Actors 的流创建DStream
- 通过 Akka actors 接受数据流
- Spark Streaming提供了streamingContext.actorStream(actorProps, actor-name)可以基于自定义 Actors 的流创建DStream
- 基于RDD队列的DStream数据源
- Spark Streaming提供了 streamingContext.queueStream(queueOfRDDs)方法可以创建基于RDD 队列的DStream
- 每个RDD 队列将被视为 DStream 中一块数据流进行加工处理
- Spark Streaming提供了 streamingContext.queueStream(queueOfRDDs)方法可以创建基于RDD 队列的DStream
19.5.2 高级数据源
- Twitter Spark Streaming的TwitterUtils工具类使用Twitter4j,Twitter4J 库支持通过任何方法提供身份验证信息,你可以得到公众的流,或得到基于关键词过滤流。
- Flume Spark Streaming可以从Flume中接受数据。
- Kafka Spark Streaming可以从Kafka中接受数据。
- Kinesis Spark Streaming可以从Kinesis中接受数据
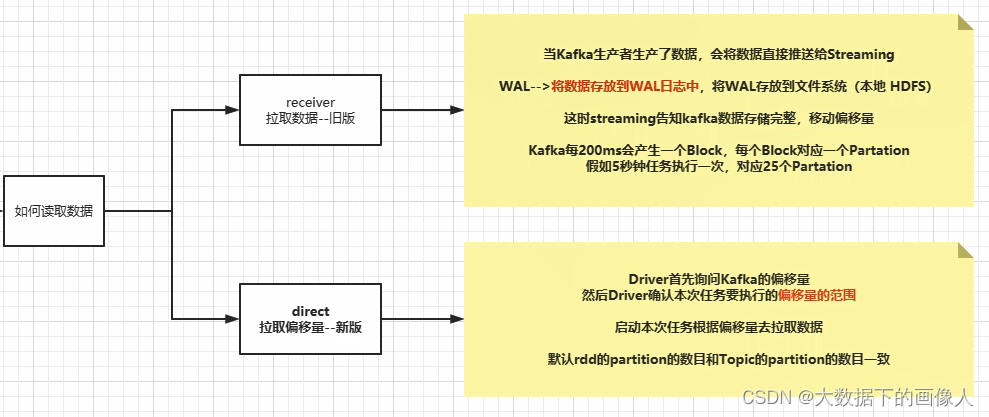
19.5.3 kafka接收数据方式⭐️
Kafka与Spark Streaming集成时有两种方法:旧的基于receiver的方法,新的基于direct stream的方法
-
基于receiver的方法
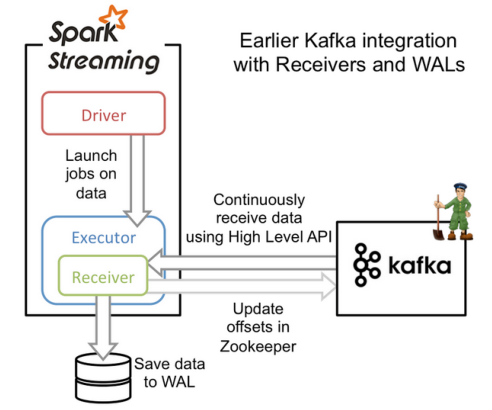
- 基于receiver的方法采用kafka的高级消费者API,每个executor进程都不断拉取消息,并同时保存在executor内存与HDFS上的预写日志(write-ahead log/WAL),当消息写入WAL中后,自动更新Zookeeper中的offset
- 它可以保证at last once 语义,但无法保证ecactly once 语义,虽然引入了WAL来确保消息不会丢失,但是还有可能会出现消息以及写入WAL,但offset更新失败的情况,Kafka就会按照上次的offset重新发送消息
- receiver的并行度是由spark.streaming.blockInterval来决定的,默认为200ms,假设
batchInterval为5s,那么每隔blockInterval就会产生一个block,这里就对应每批次产生RDD的partition,这样5秒产生的这个Dstream中的这个RDD的partition为25个,并行度就是25。如果想提高并行度可以减少blockInterval的数值,但是最好不要低于50ms- 通过改变产生block的时间和批任务执行的时间来确定RDD的任务并行度
-
基于direct stream的方法
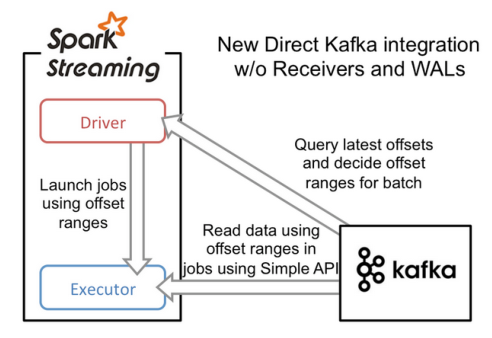
- 基于direct stream的方法采用Kafka的简单消费者API,它的流程大大简化了。executor不再从Kafka中连续读取消息,也消除了receiver和WAL。还有一个改进就是Kafka分区与RDD分区是一一对应的,更可控
- driver进程只需要每次从Kafka获得批次消息的offset range,然后executor进程根据offset
range去读取该批次对应的消息即可。由于offset在Kafka中能唯一确定一条消息,且在外部只能被Streaming程序本身感知到,因此消除了不一致性,达到了exactly once - 由于它采用了简单消费者API,我们就需要自己来管理offset。
- Direct模式的并行度是由读取的kafka中topic的partition数决定的
19.5.4 Kafka0.10Higher
- 代码实现
19.5.5 offset操作⭐️
- SparkStreaming Kafka 维护offset 官网有三种实现方式
- Checkpoint
- Kafka itself
- Your own data store
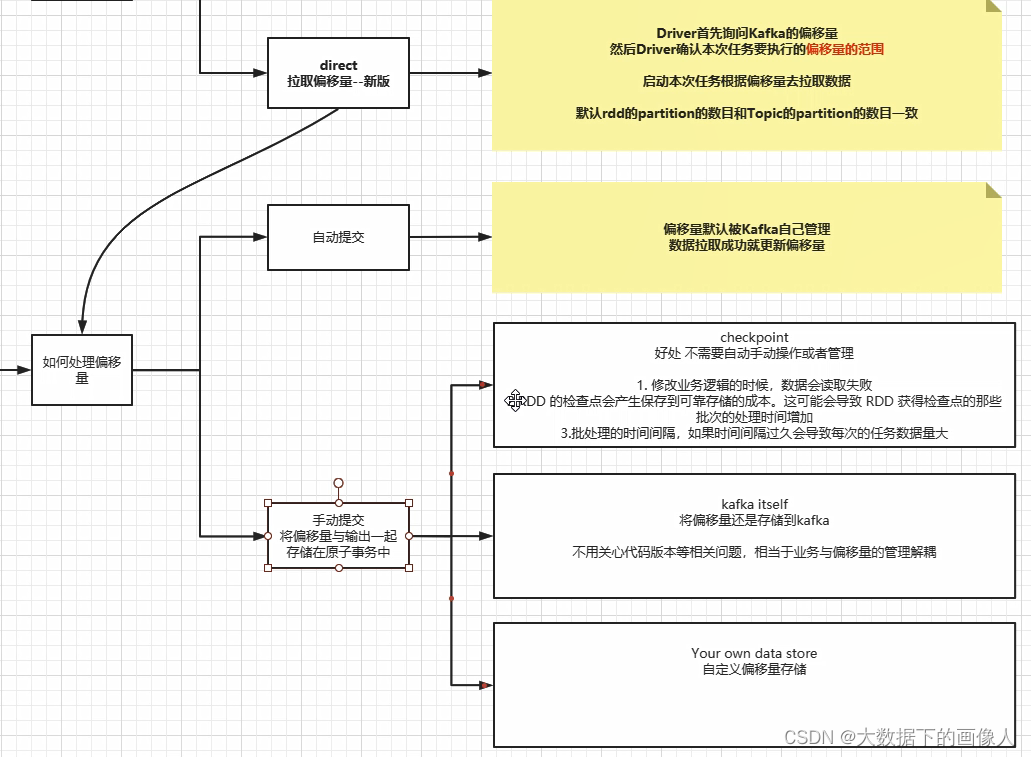
1. Checkpoint
- 概念理解
- spark streaming里面管理偏移量的策略,默认的spark streaming它自带管理的offset的方式是通过checkpoint来记录每个批次的状态持久化到HDFS中,
- 如果机器发生故障,或者程序故障停止,下次启动时候,仍然可以从checkpoint的目录中读取故障时候rdd的状态,便能接着上次处理的数据继续处理
- 存在的问题
- 版本升级丢失数据
- checkpoint方式最大的弊端是如果代码升级,新版本的jar不能复用旧版本的序列化状态,导致两个版本不能平滑过渡,结果就是要么丢数据,要么数据重复,所以官网搞的这个东西,几乎没有人敢在生产环境运行非常重要的流式项目
- 新旧序列化二进制文件不匹配导致的数据重复或丢失
- checkpoint第一次持久化的时候会把整个相关的jar给序列化成一个二进制文件,每次重启都会从里面恢复,但是当你新的程序打包之后序列化加载的仍然是旧的序列化文件,这就会导致报错或者依旧执行旧代码。有的同学可能会说,既然如此,直接把上次的checkpoint删除了,不就能启动了吗? 确实是能启动,但是一旦你删除了旧的checkpoint,新启动的程序,只能从kafka的smallest或者largest的偏移量消费,默认是从最新的,如果是最新的,而不是上一次程序停止的那个偏移量就会导致有数据丢失,如果是老的,那么就会导致数据重复
- 版本升级丢失数据
2. Kafka itself
- 概念理解
- Kafka本身就有机制可以定时存储消费者分组的偏移量,但是这样会有重复消费的情况,如果采用这种方式,那么就是将kafka的offset全部交给kafka管理
- 存在的问题
- kafka的数据也是存储在内存和磁盘中的,如果数据量过大,会造成kafka集群的压力
- 因为我们项目在实际开发中的时候,遇到数据峰值很高的时候kafka集群的磁盘io是特别高的这样是非常不安全的
3. Your own data store
- 概念理解
- 自己写代码管理offset,其实就是把每批次offset存储到一个外部的存储系统中,如HBASE、HDFS、Zookeeper、Kafka、DB等(外部的存储系统比较安全)
- 对偏移量处理的过程
- 第一次启动流式项目–>创建流–>更新批数据和偏移量到外部存储系统
- 当一个新的spark streaming+kafka的流式项目第一次启动的时候,这个时候发现外部的存储系统并没有记录任何有关这个topic所有分区的偏移量,所以就从
KafkaUtils.createDirectStream直接创建InputStream流,默认是从最新的偏移量消费,如果是第一次其实最新和最旧的偏移量时相等的都是0,然后在以后的每个批次中都会把最新的offset给存储到外部存储系统中,不断的做更新
- 当一个新的spark streaming+kafka的流式项目第一次启动的时候,这个时候发现外部的存储系统并没有记录任何有关这个topic所有分区的偏移量,所以就从
- 第二次启动流式数据–>读取外部存储系统的数据偏移量–>接着上次的偏移量进行处理
- 当流式项目停止后再次启动,会首先从外部存储系统读取是否记录的有偏移量,如果有的话,就读取这个偏移量,然后把偏移量集合传入KafkaUtils.createDirectStream中进行构建InputSteam,这样的话就可以接着上次停止后的偏移量继续处理,然后每个批次中仍然的不断更新外部存储系统的偏移量,这样以来就能够无缝衔接了,无论是故障停止还是升级应用,都是透明的处理
- 第一次启动流式项目–>创建流–>更新批数据和偏移量到外部存储系统
- 对于一个正在运行的spark streaming+kafka的流式项目,增加kafka的分区个数的处理
- 增加kafka分区–>流式项目感知不到–>重启项目识别新增分区–>插入新增分区到已存储的分区偏移量(保证数据不丢失,针对于自己写代码管理的offset方式)
- 对正在运行的一个spark streaming+kafka的流式项目,我们在程序运行期间增加了kafka的分区个数,请注意:这个时候新增的分区是不能被正在运行的流式项目感应到的,如果想要程序能够识别新增的分区,那么spark streaming应用程序必须得重启,同时如果你还使用的是自己写代码管理的offset就千万要注意,对已经存储的分区偏移量,也要把新增的分区插入进去,否则你运行的程序仍然读取的是原来的分区偏移量,这样就会丢失一部分数据
- 增加kafka分区–>流式项目感知不到–>重启项目识别新增分区–>插入新增分区到已存储的分区偏移量(保证数据不丢失,针对于自己写代码管理的offset方式)