目录
1.获取xml文件中所有标签名称及数量
【需求】自己标注的数据集,想要看看有多少个标签,并且想知道每一个标签的数量,又或者是需在标注完成后需要对标注好的XML文件校验,比如看看标签名有没有写错,都有啥标签名。
代码如下,只需将【indir】字段换成自己需要统计的xml的文件夹,随后运行即可~~~
import os
from unicodedata import name
import xml.etree.ElementTree as ET
import glob
def count_num(indir):
# 提取xml文件列表
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(str(annotations) + '*.xml')
dict = {} # 新建字典,用于存放各类标签名及其对应的数目
for i, file in enumerate(annotations): # 遍历xml文件
# actual parsing
in_file = open(file, encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
# 遍历文件的所有标签
for obj in root.iter('object'):
name = obj.find('name').text
if (name in dict.keys()):
dict[name] += 1 # 如果标签不是第一次出现,则+1
else:
dict[name] = 1 # 如果标签是第一次出现,则将该标签名对应的value初始化为1
KeyDict = sorted(dict)
# 打印结果
print("%d kind labels and %d labels in total" % (len(KeyDict), sum(dict.values())))
print('labels:',KeyDict)
print('\n')
print("Label Name and it's number//各类标签的数量分别为:")
for key in dict.keys():
print(key + ': ' + str(dict[key]))
print("\n总标签数目:{}个".format(sum(dict.values())))
print('\t')
print('检索完成!')
indir = '/data_1T/xd1/VOCdevkit/VOC2012/Annotations/' # xml文件所在的目录
count_num(indir) # 调用函数用来统计各类标签数目

2.提取某个特定标签数量
【需求】自己标注的数据集,想要看看某个标签有多少个,又或者是需在标注完成后需要对标注好的XML文件校验。
代码如下,需将下面几个字段进行修改,随后运行即可~~~
【test_dir】【train_dir】【trainval_dir】【xml_dir】【label】
# -- coding: utf-8 --
import pickle
import os
import glob
from os import listdir, getcwd
from os.path import join
import xml.etree.ElementTree as ET # 导入xml模块
test_dir = '/data_1T/xd1/VOCdevkit/VOC2012/ImageSets/Main/test.txt' #修改读取的test_dir文件路径
train_dir = '/data_1T/xd1/VOCdevkit/VOC2012/ImageSets/Main/train.txt' #修改读取的train_dir文件路径
trainval_dir = '/data_1T/xd1/VOCdevkit/VOC2012/ImageSets/Main/trainval.txt' #修改读取的trainval_dir文件路径
xml_dir = '/data_1T/xd1/VOCdevkit/VOC2012/Annotations/' # 修改保存xml文件的路径
read_xmlfile = trainval_dir #修改读取的xml文件索引路径
xml_index = open(read_xmlfile).readlines()
print('【{}】中XML文件的数量为'.format(read_xmlfile),len(xml_index),'个') # 计算测试集的xml文件的数量
label = 'metal' #修改检索指定标签的名字
nums = 0
c = 0
for i in range(len(xml_index)):
index = xml_index[i].strip('\n') # 截取xml文件名
# print(xml_dir+index+'.xml')
xml_file = open(xml_dir + index + '.xml', encoding="utf-8")
xml = ET.parse(xml_file)
for name in xml.iter('object'):
nums = nums + 1
if name.find("name").text == label: # 按标注的标签名进行统计
c = c + 1
xml_file.close()
print('标签为',label,'的个数:', c)
print('\t')
print('检索完成!')

3.生成包含某个标签的图片索引txt并复制图片到指定文件夹
【需求】经过上述步骤,发现自己标注的数据集有个标签是标注错的,想自己看下是那个文件的错误,又或者自己想把它删除,下面代码可以解决!!!
代码如下,需将下面几个字段进行修改,随后运行即可~~~
【test_dir】【train_dir】【trainval_dir】【xml_dir】【label】
# -- coding: utf-8 --
import xml.etree.ElementTree as ET # 导入xml模块
import os
test_dir = '/data_1T/xd1/VOCdevkit/VOC2012/ImageSets/Main/test.txt' # 修改读取的test_dir文件路径
train_dir = '/data_1T/xd1/VOCdevkit/VOC2012/ImageSets/Main/train.txt' # 修改读取的train_dir文件路径
trainval_dir = '/data_1T/xd1/VOCdevkit/VOC2012/ImageSets/Main/trainval.txt' # 修改读取的trainval_dir文件路径
xml_dir = '/data_1T/xd1/VOCdevkit/VOC2012/Annotations/' # 修改保存xml文件的路径
read_xmlfile = trainval_dir # 修改读取的xml文件索引路径
xml_index = open(read_xmlfile).readlines()
save_file = "./" # 保存包含指定标签的图片的索引文件txt
if not os.path.exists(save_file):
os.makedirs(save_file)
label = 'd' #修改检索指定标签的名字
fsave = open(save_file + "/label【{}】_imgpath.txt".format(label), "w", encoding="utf-8")\
for i in range(len(xml_index)):
index = xml_index[i].strip('\n') # 截取xml文件名
# print(xml_dir+index+'.xml')
xml_file = open(xml_dir + index + '.xml', encoding="utf-8")
xml = ET.parse(xml_file)
for path in xml.iter('annotation'):
for name in path.iter('object'):
if name.find("name").text == label:
img_path = path.find('path').text.split("\\")[-1]
fsave.write(img_path + '\n')
print("开始生成包括label为【{}】的图片索引文件!".format(label))
print("生成结束//extract label success!")

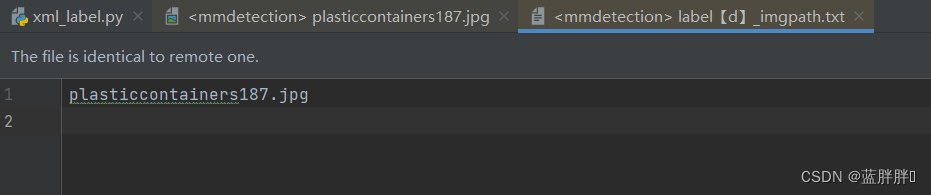
生成的指定标签图片索引txt为:
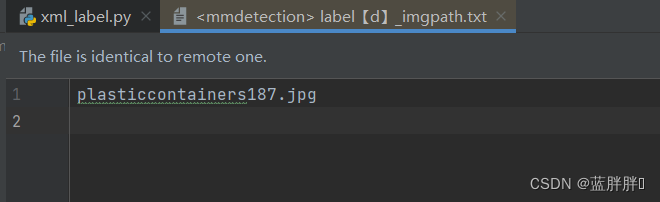
【需求】那么,找到文件是什么,怎么把这些图片提取出来呢?
下面代码帮你解决!
代码如下,需将下面几个字段进行修改,随后运行即可复制图片到指定文件夹~~~
【path】【save_img_path】【read_label_file】
# -- coding: utf-8 --
import os, shutil
path = '/data_1T/xd1/VOCdevkit/VOC2012//JPEGImages/' #原数据集图片文件夹
img_path = os.listdir(path)
save_img_path = './mail_box_img/' #存放提取出来的图片文件夹
if not os.path.exists(save_img_path):
os.makedirs(save_img_path)
read_label_file = './label【d】_imgpath.txt' #上一步生成的包含指定标签的txt索引文档
f = open(read_label_file, "r")
while True:
line = f.readline()
for img in img_path:
if img.split('.')[0] == line.split('.')[0]:
print('包含指定label的图片为:',img)
shutil.copy(path + img, save_img_path + img)
if not line:
break

生成的图片文件夹为:

好了,大功告成,完结撒花!
欢迎关注、点赞、收藏、评论、分享给好友,一起学习有趣的新知识!!!