一、论文简述
1. 第一作者:Wenyue Guo、Bing Liu
2. 发表年份:2021
3. 发表期刊:JPRS
4. 关键词:MVS、3D重建、注意力、相关体
5. 探索动机:先前的方法内存占用太高。一种常用的释放内存负担的方法是用下采样图像推断深度图。然而,这是以重建的准确性和完整性为代价的。
Though the aforementioned literatures could achieve better results in terms of accuracy and completeness compared to traditional MVS methods, they require huge GPU memory caused by high dimension cost volume for depth inference. A normal way to release memory burden is to inference depth map with downsampled images. It comes at the cost of reconstruction accuracy and completeness, however.
6. 工作目标:减小内存开销。
7. 核心思想:we endeavor to propose an Attention Aware Cost Volume Pyramid Multi-view Stereo Network (AACVP-MVSNet) for 3D reconstruction.
- We introduce the self-attention layers for hierarchical features extraction, which may capture important information for the subsequent depth inference task.
- We introduce the similarity measurement for cost volume generation instead of the variance based methods used by most MVS networks.
8. 实验结果:
We use a coarse-to-fine strategy for depth inference which is applicable for large scaled images, and extensive experiments validate that the proposed approach achieves an overall performance improvement than most SOTA algorithms on DTU dataset.
9.论文&代码下载:
https://arxiv.org/pdf/2011.12722.pdf
https://github.com/ArthasMil/AACVP-MVSNet
二、实现过程
1. AACVP-MVSNet概述
结构如图所示。首先对多视图图像进行下采样,形成图像金字塔,然后构建权重共享的特征提取块,用于各层次的特征提取。深度推断从粗层(L层)开始,使用相似度测量构建代价体CL,即代价体相关,使用相似度测量而不是基于方差的测量,并使用共享的权重的3D卷积块和softmax操作通过代价体正则化生成初始深度图。估计的深度图DL被放大到下一层(级别L−1)的图像大小,并通过深度假设平面估计和代价体相关构建代价体C(L−1)。深度残差图R(L−1)也由三维卷积块和softmax运算,深度图D(L−1)被放大到L−2级的图像大小,用于(L−2)级的深度推理。这样,一个迭代的深度图估计过程就形成了一个代价体金字塔Ci。
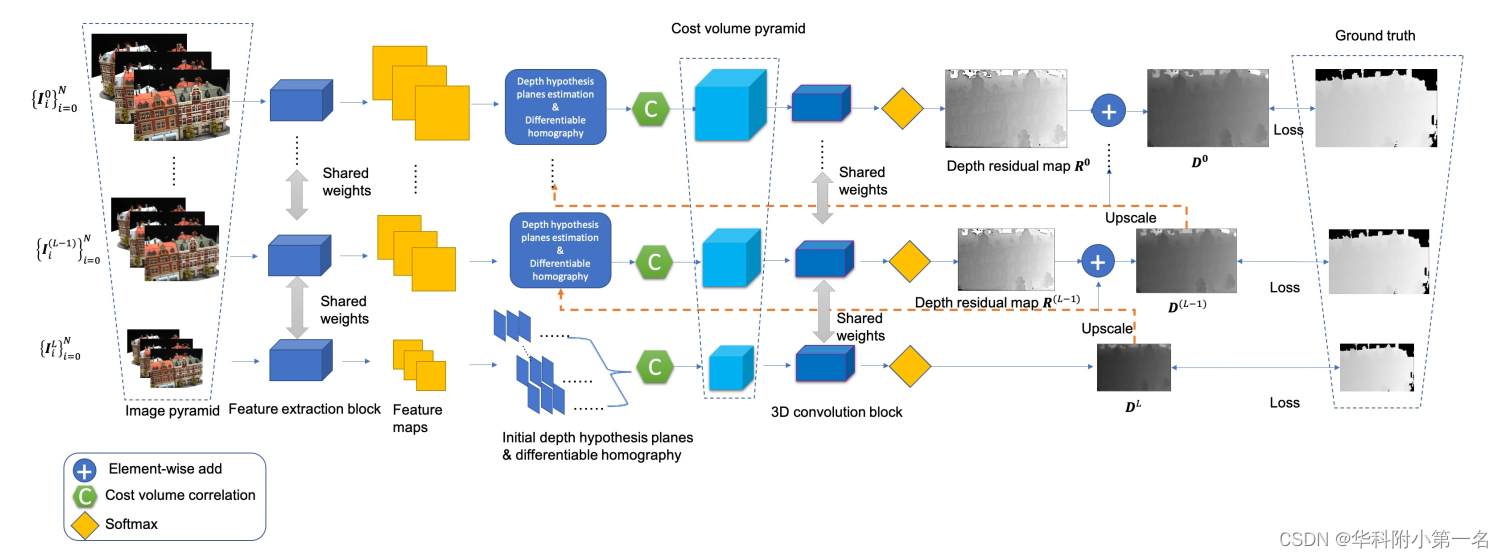
2. 基于自注意力的层次特征提取
2.1. 基于自注意力的特征提取块
特征提取块由8个卷积层和一个具有16个输出通道的自注意力层组成,每个层后面都有一个leaky ReLU,核大小设置为3,所有层的步幅设置为1,输出通道每3层减少,最终输出通道为16。引入自注意力机制学习关注重要信息进行深度推理。

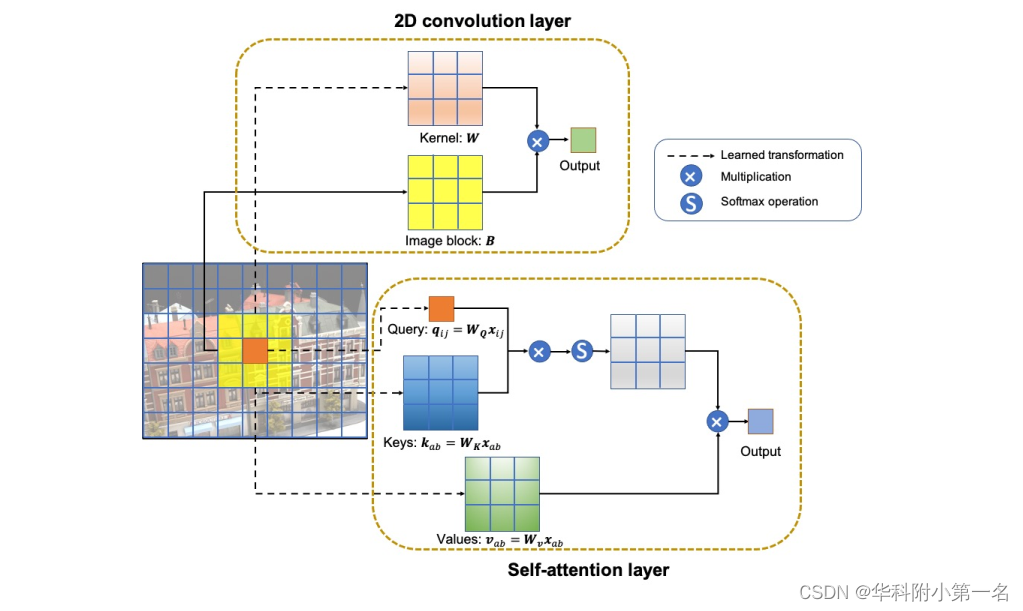
卷积定义:给定一个学习权重矩阵W∈k×k×din×dout,像素(i,j)的卷积输出yij∈dout定义为输入图像I与权值矩阵的线性乘积之和:
其中k为核大小,din为输入通道数量,dout为输出通道数量,B为相同核大小的用于卷积计算的图像块。

自注意力:与传统的注意力机制相比,自注意力机制被定义为应用于单个上下文而不是跨多个上下文的注意力,它直接模拟长距离交互,定义如下:
其中,q,k,v分别表示查询、键和值,矩阵W)由学习参数组成。与传统的卷积计算相比,自注意力可以分解为3步:
步骤1:计算查询(q)、键(k)和值(v)。
步骤2:通过计算查询和键的内积qTk来测量它们的相似性,然后使用softmax操作相似性映射到0,0和1,0之间。
步骤3:用步骤2中的相似性对值进行加权,并对B中的每个像素重复所有步骤。

不难看出,输出y是通过位置ij的像素与邻域像素的线性变换来实现的,该操作通过内容的带有交互参数化的混合权重的值向量的凸组合来聚合空间信息。当k = 3时,二维卷积层与二维自注意力层的差异如图所示。卷积层可以认为是像素和学习权重W的组合,而自注意力层有三个学习权重矩阵,分别是WQ, WK和WV。
然而,自注意力不包含查询qij的位置信息,这使得它排列等变,限制了视觉任务的表达能力。因此,为了达到更好的效果,引入位置信息嵌入方法。引入相对位置嵌入方法,而不是绝对位置嵌入方法,将行和列偏移量(记为ra−i;b−j)引入公式,自注意力计算可表示为

每个y测量查询与B中的元素之间的相似性,并享有平移不变性。
2.2. 层次特征提取
特征提取管道由两个步骤组成。第一步是为所有输入源图像和参考图像建立一个总共(L + 1)层的图像金字塔。下一个步骤是使用特征提取块进行Lt级层级表示。由于提取块可以在不同视图、不同尺度的图像上实现,因此该块的学习权重共享。
3. 从粗到细的深度估计
由于所提出的网络在图像空间中引入了金字塔结构,形成的代价体金字塔(CVP)用于最粗分辨率的深度图推断和更细尺度的深度残差估计。
3.2. 最粗分辨率的深度推断
在最粗糙的尺度上构造代价体作为初始深度图推断。通过单应性变化得到投影后的特征图。引入平均组相关,通过相似度测量来构建图像匹配任务的代价体,其基本思想是将特征分组,并逐组计算相关图。因此,第一步是将特征图的特征通道划分为G组,计算参考图像与第j组在假设深度平面dm处的warp图像为:

最终代价体为G ×H/2L×W/2L×M大小的张量,G为组数,M为深度假设数。因此,最终的聚合的代价体可以计算为所有视图的平均相似性,即:

当估计L级的代价体时,可以通过一个与前面学习的相似的三维卷积生成概率体P。

在最粗糙的层次上,每个像素p的深度图可以估计为

3.3. 精细尺度下的深度残差估计
在更精细的层次上改进DL(p),实现残差图估计。以估计(L−1)阶段的残差图(R(L−1))为例,其数学模型可以概括为:

其中,M为假设深度平面数,rp =m∆dp为深度残差,∆dp=lp/M为深度区间,D(upscaleL)为从L层放大的深度图,Lp表示为p(u,v)的深度搜索范围。如下图所示,∆dp和lp决定了像素p处的深度估计结果,是深度残差估计的关键参数。深度搜索范围和深度区间确定有几种方法,如迭代范围缩小和基于不确定性的搜索边界。本文将参考图像中的p(u,v)与源图像中的对应点投影到物体空间中确定深度间隔∆dp为相邻两个像素点沿极线的投影距离,由于采样的三维点在图像中的投影距离太近,无法为深度推断提供额外的信息,因此不需要对深度平面进行密集采样。因此,在水平(L−1)下,lp可计算为∆dp与给定参数M的乘积。

3.4. 迭代深度图估计
将Dl作为(l−1)层的输入,并形成一个迭代的深度图估计过程。当到达图的顶层时,将得到最终的深度图D0。对于网络反向传播,将损失函数构建为真实的深度和估计深度之间的l1范数,即:

4. 实验
4.1. 实现细节
在所有的实验中,在最粗的层次设置假设深度平面的数量M = 48,在其他层次设置假设深度平面的数量M = 8,用于训练和评估。网络在4个Nvidia GeForce RTX 2080Ti显卡进行训练40个epoch,批大小设置为36。
4.2. 与先进技术的比较

4.3. 消融实验
AACVP-MVSNet在不同G参数下每批使用的内存。训练图像大小为160 × 128像素。

不同参数H的AACVP-MVSNet在DTU数据集上的结果。

不同视图数的重建质量。
