目录
model.train()与model.eval()
当模型中有BN层(Batch Normalization)或者Dropout,两者才有区别
需要在
训练时model.train(),保证BN层用每一批数据的均值和方差,Dropout随机取一部分网络连接来训练更新参数
测试时model.eval(),保证BN用全部训练数据的均值和方差,Dropout用到了所有网络连接,
pytorch自动把BN和DropOut固定住,不会取平均,而是用训练好的值
无论标准化还是归一化都是针对某个特征(某一列)进行操作的
例如:每一条样本(row)的三列特征:身高、体重、血压。
归一化(Normalization)
将训练集中某一列数值特征(假设是第 i ii 列)的值缩放到0和1之间

当X最大值或者最小值为孤立的极值点,会影响性能。
标准化(Standardization)
将训练集中某一列数值特征(假设是第i列)的值缩放成均值为0,方差为1的状态
 x_nor = (x-mean(x))/std(x)=输入数据-数据均值)/数据标准差
x_nor = (x-mean(x))/std(x)=输入数据-数据均值)/数据标准差
Batch Normalization
batch_size:表示单次传递给程序用以训练的数据(样本)个数
对网络中间的每层进行归一化处理,并且使用变换重构(Batch Normalization Transform)保证每层所提取的特征分布不会被破坏。
训练时是针对每个mini-batch的,但是在测试中往往是针对单张图片,即不存在mini-batch的概念。由于网络训练完毕后参数都是固定的,因此每个batch的均值和方差都是不变的,因此直接结算所有batch的均值和方差。所有Batch Normalization的训练和测试时的操作不同。
Dropout
在每个训练Batch中,通过忽略一半的特征检测器,可以明显的减少过拟合现象
在训练中,每个隐层的神经元先乘概率P的被丢弃可能性,然后再进行激活。
在测试中,所有的神经元先进行激活,然后每个隐层神经元的输出乘P的被丢弃可能性。
TensorFlow和pytorch中dropout参数p
TensorFlow中p(keep_prob):保留节点数的比例
pytorch中的p:该层(layer)的神经元在每次迭代训练时会随机有 p的可能性被丢弃(失活),不参与训练
#随机生成tensor
a = torch.randn(10,1)
>>> tensor([[ 0.0684],
[-0.2395],
[ 0.0785],
[-0.3815],
[-0.6080],
[-0.1690],
[ 1.0285],
[ 1.1213],
[ 0.5261],
[ 1.1664]])torch.nn.Dropout(0.5)(a)
>>> tensor([[ 0.0000],
[-0.0000],
[ 0.0000],
[-0.7631],
[-0.0000],
[-0.0000],
[ 0.0000],
[ 0.0000],
[ 1.0521],
[ 2.3328]])数值上的变化: 2.3328=1.1664*2
relu,sigmiod,tanh激活函数
在神经网络中原本输入输出都是线性关系,
但现实中,许多的问题是非线性的(比如房价不可能随着房子面积的增加一直线性增加),
这个时候就神经网络的线性输出,再经过激励函数,便使得原本线性的关系变成非线性了,增强了神经网络的性能。

nn.Linear
对输入数据进行线性变换
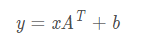
>>> m = nn.Linear(20, 30)
>>> input = torch.randn(128, 20)
>>> output = m(input)
>>> print(output.size())
torch.Size([128, 30])张量的大小由 128 x 20 变成了 128 x 30
执行的操作是:
[128,20]×[20,30]=[128,30]