摘要
卷积神经网络在表征遥感图像方面取得了巨大的成功。然而,缺乏足够的注释数据 (以及RS图像域的高度复杂性) 常常使 监督和迁移学习方案 从操作的角度来看受到限制。尽管无监督方法可以潜在地缓解这些限制,但它们 经常不能有效地利用关于RS域的相关先验知识,这可能最终限制它们的最终性能。为了应对这些挑战,本文提出了一种新的无监督深度度量学习模型,称为 空间增强动量对比度(SauMoCo),它是 专门设计来表征无标签遥感场景的。基于地理学第一定律,提出的方法 定义了空间增强标准,以揭示土地覆盖 tiles 之间的语义关系。然后,在所考虑的对比学习过程中,构建深度嵌入队列以增强 RS tiles 的语义多样性,其中辅助CNN模型充当更新机制。我们的实验比较,包括不同的最新技术和基准遥感图像档案,揭示了所提出的方法在表征未标记场景时获得了显著的性能增益,因为它能够显著增强复杂土地覆盖类别之间的判别能力。这篇文章的源代码将提供给RS社区用于可重复的研究。
I. INTRODUCTION
随着深度学习 (DL) 技术的不断发展,这些方法在许多重要的遥感 (RS) 应用中取得了巨大的成功 [1]、[2],例如场景分类 [3]-[7]、目标定位 [8]-[12] 和 变化检测 [13]-[15],因为它们具有从 RS 场景 [16] 中发现高度代表性特征的突出能力。一般来说,DL 技术旨在将输入图像的视觉内容投影到特定的标签空间,使用非线性层的层次结构来生成高级语义抽象,这对于表征 RS 数据非常有用。 RS 领域中大多数可用的基于 DL 的图像表征方法依赖于监督学习方案,其中需要大量标记场景来正确训练模型并防止过度拟合 [17]。然而,为大量 RS 数据获取相关注释的任务可能非常困难且耗时。这可能会严重限制 监督 DL 范例在操作 RS 环境中的适用性和潜力,尤其是在最具挑战性的条件下 [18]。
为了减轻对标记 RS 数据的需求,文献 [19]-[22] 中已经有效探索了不同的策略。最流行的方案之一是基于预训练卷积神经网络 (CNN) [23] 的使用,其中不同的预定义 CNN 架构(例如 AlexNet [24]、VGGNet [25]、GoogleNet [26] 和 ResNet [27] ]),在大规模计算机视觉数据集(例如,ImageNet [28])上训练,直接用作 RS 数据的特征提取方法。尽管取得了显着的成功 [29]-[32],但现有的光谱带数量和数据复杂性的限制使得这种迁移学习方案无法充分利用 RS 图像的优势 [33]。解除这些限制的一个有吸引力的选择包括 使用无监督方法来表征未标记的 RS 场景。因此,DL 领域内外都成功提出了不同的方法 [34]-[37]。然而,一般的无监督框架往往无法引入关于 RS 图像域的适当先验知识,最终限制了最终的性能。尽管最近开发的深度度量学习方法——Tile2Vec [38]——肯定能够通过 使用地理空间信息作为先验知识 获得有希望的结果,但 海量 RS 档案的前所未有的可用性,以及 采集技术的不断发展,仍然 使无监督的基于 DL 的图像表征成为 RS 中的主要挑战。请注意,将无监督模式集成到深度度量学习方法中 [39] 高度受限于可以在单个批次中采样的对比土地覆盖类型,这最终可能会 降低模型区分更广泛的复杂 RS 类别的能力,也推动了可用于处理 RS 图像域的大规模方差复杂性的新技术的发展 [40]。
考虑到所有这些考虑因素,本文提出了一种新的无监督深度度量学习方法,称为空间增强动量对比 (SauMoCo),它专门设计用于表征未标记的 RS 场景。受 Tobler 地理第一定律 [41] 的启发,所提出的方法为无监督土地覆盖表征提供了一个新视角,其中不仅 利用 附近场景之间的语义相似性 来学习相应的特征嵌入,还 利用 RS 语义概念中的内在多样性。为了实现这一目标,我们定义了空间增强标准 以 揭示嵌入空间的 RS 分块之间增强的语义关系。然后,我们构建了一个深度嵌入队列,其中队列的大小被迫大于批量大小,以便在训练过程中 进一步增加对比土地覆盖块的语义多样性。此外,我们在模型中 引入了一个辅助 CNN,以持续更新队列中 RS tiles的深度嵌入。为了验证所提出的方法,我们使用两个基准数据集和不同的最先进的表征技术进行了全面的实验比较,证明了所提出的方法在分类 RS 场景任务中的优越性能,无需使用任何土地覆盖类别信息。简而言之,本文的主要贡献可以概括如下。
1)我们 提出了一种新的无监督深度度量学习模型(SauMoCo)来表征未标记的 RS 图像。所提出的方法不仅寻求利用附近地理空间位置之间的语义相似性,而且还利用土地覆盖概念内的固有多样性,通过使用 使用具有 对比损失公式 和 基于动量更新的优化 的新定义的空间增强标准。
2) 我们研究了所提出的 SauMoCo 模型如何处理大规模的训练数据,这让我们对所提出的方法相对于文献中可用的其他无监督 RS 图像表征技术的工作机制和实际优势有了重要的见解。这项工作的代码将在研究社区内发布,用于可重复的研究。
本文的其余部分组织如下。第二节回顾了一些遥感场景表征的相关工作,同时指出了它们的主要局限性。第三节详细介绍了提出的遥感图像无监督深度度量学习模型。第四节介绍了工作的实验部分。最后,第五节对本文进行了总结,并提出了一些可能的未来研究方向。
II. RELATED WORK
在遥感领域已经成功地采用了不同的策略来缓解 在表征空中场景时 对标记数据的需求。本节回顾了一些最相关的趋势,包括 预训练(第II-A节)、无监督(第II-B节) 和 基于深度度量学习(第II-C节)的方法。此外,我们还分析了它们在遥感问题背景下的主要局限性(第II-D节)。
A. 预训练方法
表征 RS 数据的最流行方案之一是 基于使用预训练的 CNN。更详细地说,这些方法利用预定义的 CNN 模型,例如 AlexNet [24]、VGGNet [25]、GoogleNet [26] 或 ResNet [27],这些模型在大规模计算机视觉数据集上进行了预训练,例如ImageNet [28] 集合。这样,通过 将知识从标准图像域转移到 RS 域,可以大大减少标记 RS 场景的数量。例如,Hu 等人 [42] 定义了两种不同的方案来利用在 ImageNet 上预训练的 VGGNet 模型。在第一种方案中,作者 使用最后的全连接层作为图像描述符。在第二个中,使用 额外的编码过程 来融合最后的卷积特征图。在这两种情况下,均采用支持向量机 (SVM) 对 RS 图像进行最终分类。准确地说,Marmanis 等人 [29] 分析了使用从 ImageNet 传输的不同基于 CNN 的表示对遥感场景进行分类的有效性。同样,Li 等人 [31] 提出了一个多层特征融合框架,它集成了几个用于 RS 场景分类的预训练 DL 模型。 Zheng 等人 [43] 使用多尺度池化对预训练特征构建了 RS 图像的整体表示。 Kang 等人 [44] 还结合了几种预训练的 CNN 架构来定义建筑实例级土地利用分类框架。 Othman 等人 [30] 建议在预训练特征上使用稀疏自动编码器 (AE) 来生成 RS 场景的最终表示。
尽管这些和其他预训练模型取得了显着的性能,但 仍然存在一些重要的局限性,这些局限性大大降低了这种迁移学习策略在 RS 领域中的适用性。一方面,标准图像集,如 ImageNet,通常由 RGB 图像组成,这使得现有的预训练网络无法利用机载和星载光学传感器提供的额外光谱带 [45]。请注意,RS 工具通常旨在提供可见光谱之外的有价值信息,这些数据在许多重要应用中都是必不可少的,例如生物物理参数分析 [46] 和土地覆盖材料研究 [47]。另一方面,标准图像通常包含自然的以物体为中心的照片,这些照片很难代表 RS 场景的复杂性,包括地球表面的完全聚焦的多波段照片,在同一采集帧中具有大量复杂的空间光谱细节 [48]。准确地说,这些重要的差异通常使得有必要考虑比预训练 DL 模型更广泛的策略。
B. 无监督方法
减轻对带注释的 RS 数据的需求 的更通用的选择 是 基于使用无监督的图像表征方法。更详细地说,这些技术可以在不使用任何类标签信息的情况下用于表征空中场景,这在 RS 问题中变得特别有吸引力 [18]。因此,已经提出了不同的无监督模型(DL 领域内外)来从未标记的 RS 场景中学习信息表示。例如,Cheriyadat [49] 提出了一种用于航空场景的特征学习方法,该方法采用稀疏编码框架,根据一组从低级测量得出的基函数生成无监督数据表示。按照这个想法,其他作者建议改用不同的无监督分解框架。 [37]、[50] 和 [51] 中的作品就是这种情况,它们使用概率主题模型将 RS 数据表示为特征模式的概率分布。 Zhang 等人 [52] 利用稀疏 AE 有效地学习 RS 场景的显著性引导的无监督特征。类似地,Hu 等人 [35] 利用光谱聚类程序来揭示图像块之间的内在结构。 Romero 等人 [34] 介绍了一种贪婪的分层无监督预训练方法,用于从航拍图像中学习稀疏特征。在 [36] 的情况下,作者定义了一个浅层加权反卷积网络,用于通过最小化原始图像和重建图像之间的欧氏距离来从 RS 场景中提取特征。或者,文献中的一些作品也展示了卷积生成对抗网络在表征标准和遥感图像 [53]、[54] 方面的效用。
C. 无监督深度度量学习
尽管这些和其他重要的无监督方法取得了积极成果,但所有这些工作主要依赖于一般的聚类、分解 或 编码过程,如果不使用监督信息,这些过程通常无法引入有关 RS 域的相关先验知识。在所有进行的研究中,充分表征 RS 图像的最有前途的趋势之一是基于所谓的深度度量学习方法 [39]。特别地,深度度量学习 旨在学习基于 CNN 模型的低维度量空间,其中 相似图像的特征嵌入应该接近,而 不同图像的特征嵌入应该分开。尽管它在 RS 问题 [55]-[58] 中具有巨大潜力,但 如何有效地为未标记的空中场景 定义这种语义关系仍然是一个开放式的问题。然而,随着 无监督深度度量学习的最新研究,这种情况发生了重要变化。具体来说,Jean 等人 [38] 开发了Tile2Vec,这是一种通过 使用地理空间信息作为先验知识 来学习 RS 图像矢量表示的算法。更详细地说,它基于这样的观察,即 那些在地球表面空间上更近的 RS 图像tiles 比相距较远并因此预期包含不同语义的tiles 更有可能包含相似的语义,因此更可能包含相似的表示。通过这种方式,Jean 等人建议学习一个深度度量空间,根据 Tobler 地理第一定律 [41],附近 RS 图像块的特征嵌入应该很近,而远处的块应该分开。
D. RS 中的当前限制
当然,Tile2Vec 算法为从完全无监督的角度学习更多基于 CNN 的 RS 数据特征设置了一条路径。然而,在不使用任何类标签信息的情况下生成高度有意义的空中场景表示的任务仍然是 RS [59]、[60] 中非常重要的挑战。最近 大量数据集的可用性,以及 机载 和空间采集技术的不断发展,正在稳步增加 RS 数据的复杂性,从而 增加它们的语义理解的复杂性。准确地说,这种 不断增长的复杂性通常会产生 巨大的类内多样性 和 类间相似性,从而 在上述学习方案中 引入重要的限制 [39]。当将无监督模式集成到深度度量学习方法 [38] 中时,逻辑上有必要通过在每批次中采样负 RS 图像块来训练 CNN 模型。然而,这种策略 显著降低了模型区分更广泛的对比土地覆盖类型的能力,因为学习过程 受到可以在单个批次中采样的图块的限制。请注意,这一点在复杂的大型数据集中可能变得尤为关键,这刺激了 RS 领域 [18] 中更先进的无监督表征技术的发展,并最终激发了这项工作中进行的研究。
E. 所提出方法的新颖性
为了应对所有这些挑战,本文提出了一种新的无监督深度度量学习模型,该模型 联合利用 两个不同的方面:空间增强对比损失 和 基于动量更新的优化。与 Tile2Vec [38] 相比,所提出的方法集成了一个新的空间增强标准,该标准允许在以无监督方式学习相应的度量空间时,不仅考虑附近 RS 场景之间的语义相似性,而且考虑土地覆盖概念的固有语义多样性。请注意,这种 类内的变化性 尚未在表征未标记 RS 场景的上下文中得到利用,尽管它可能对缓解 RS 数据的大规模方差问题 非常有用 [40]。
使用这种方法改进,所提出的方法能够避免可扩展数据的三元损失限制,同时 还可以在训练期间利用额外的对比 RS 图像对。为了进一步改善这种对比鲜明的土地覆盖多样性,所提出的方法还利用了 基于动量更新的优化[61]。动量更新 背后的总体思想是 基于管理编码器的动态字典 以 增强对比学习过程。按照这个想法,我们 构建了一个 RS 场景的深度嵌入队列,以 强制此类队列的长度大于 小批量大小。与显示大规模数据有限结果的标准动量方案不同[61],所提出的端到端方法旨在通过 使用 基于 CNN 的主干架构来 共同 表征土地覆盖场景 并 更新队列,从而利用大量未标记的 RS 数据集。与表征未标记 RS 场景的不同最新方法相比,所提出的方法能够实现比 [29]、[38]、[54] 和 [62] 中的方法更好的性能,这也揭示了这项工作为 RS 社区提供的新颖性和优势。
III. SauMoCo
我们新提出的用于表征未标记 RS 场景的端到端无监督深度度量学习模型(SauMoCo)可以概括为以下三个部分。
1)骨干架构(称为锚 CNN),用于生成输入 RS 场景的相应特征嵌入。请注意,可以根据特定的现成拓扑定义此 CNN 架构,例如 AlexNet [24]、VGGNet [25]、GoogleNet [26] 和 ResNet [27]。
2) 基于 对比损失公式 和 新定义的空间增强标准 的空间增强损失,它不仅利用了附近 RS 场景之间的语义相似性,还利用了土地覆盖语义概念中的内在多样性。
3)相应的优化算法,它使用动量对比更新来学习所提出的模型参数。为了实现这一目标,构建了一个深度嵌入队列,并引入了一个额外的 CNN 模型(称为动量 CNN)来更新该队列。重要的是要强调,该网络应该使用与其中一个锚定 CNN 相同的架构来定义,以进行可扩展的训练。
图 1 以图形方式显示了所提出的无监督深度度量学习框架。在接下来的部分中,我们将详细介绍新定义的损失函数和考虑的优化算法。
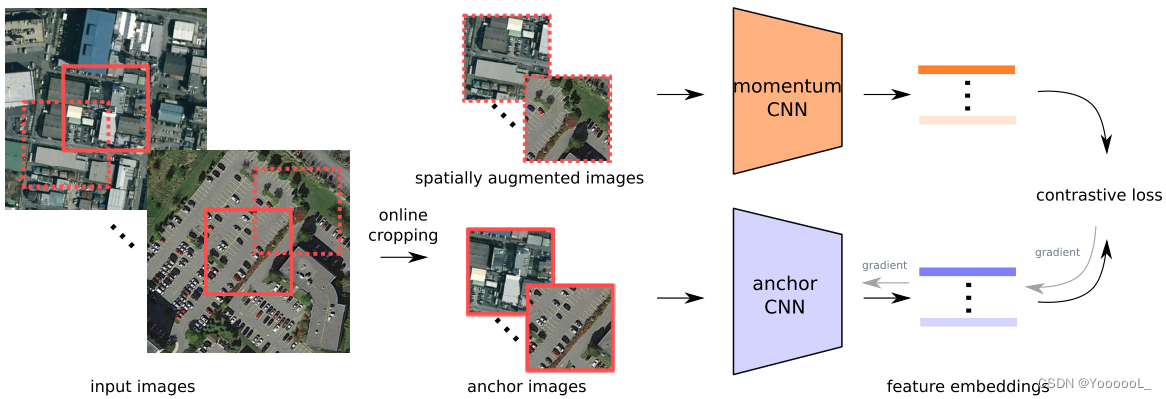
A. 空间增强损失
令 X = {x1, . . . , xM} 是收集的由 M 幅图像组成的 RS 数据集。从每个图像 xi 中,可以裁剪出一定尺寸 W×W 的锚块 ![]() (位于其中心)。对于锚块
(位于其中心)。对于锚块 ![]() 的特定距离 d,从 xi 裁剪的邻域块被定义为其空间增强,即 xni 。如果距离为 100 像素(垂直和水平方向),则 xni 的中心相对于 xai 的中心应在 100 像素以内。令 f ai ∈ RD 表示由 CNN 模型 F(·; θ) 在单位球体上获得的 xai 的深度嵌入(即
的特定距离 d,从 xi 裁剪的邻域块被定义为其空间增强,即 xni 。如果距离为 100 像素(垂直和水平方向),则 xni 的中心相对于 xai 的中心应在 100 像素以内。令 f ai ∈ RD 表示由 CNN 模型 F(·; θ) 在单位球体上获得的 xai 的深度嵌入(即 ![]() ),其中 D是它的维度,θ代表CNN模型的参数。我们将此模型标识为 锚 CNN。
),其中 D是它的维度,θ代表CNN模型的参数。我们将此模型标识为 锚 CNN。
正如地理学第一定律 [41] 所指出的那样,一切事物都与其他事物相关,但附近的事物比远处的事物更相关。遵循这一规则,所提出的方法依赖于这样的假设,即地理上相邻的图像在语义上应该比远处的图像更相似 [38]。因此,在度量空间中,附近图像的嵌入应该比远处图像的嵌入更近。然而,重要的是要强调所提出的空间增强标准不同于其他作品中考虑的标准,例如 [38]。具体来说,我们不会将空间增强 patches的位置固定到特定的邻居位置,而是固定到锚 patches的邻域区域。因此,我们的增强标准 允许裁剪区域的某些空间变化,以增加在线提取的空间增强 patches的多样性。为了以可扩展的方式实现这一点,我们采用了对比学习机制 [63]、[64],其中 ![]() 的对比损失可以定义为,
的对比损失可以定义为,

在这个等式中,内积 < ·
> 衡量 锚块
![]() 的嵌入
的嵌入 与 其空间增强块
的嵌入
之间的余弦相似度。此外,τ 表示控制样本分布浓度水平的温度参数[65]。直观地,(1) 描述了空间增强的 patch的对数似然,它可以在 X 中的所有锚 patch中被归类为它的锚 patch。然后,整个数据集上相应的对比损失 可以正式表示为,

通过优化(2),我们可以获得 X 的深度嵌入 和 训练好的 CNN 模型,这对于表征未标记的 RS 场景 和 进行相应的下游土地覆盖分类任务很有用。
B. 通过动量更新进行优化
为了以无监督的方式充分训练基于 (2) 的 CNN 模型,逻辑上需要将可扩展的数据集输入深度模型。对于可扩展的数据集,应该仔细定义如何对 xai 的 负面patch(即 xaj)进行充分采样,因为空间增强patch的数量 及其一致性 都是所提出的对比无监督学习方案中的关键方面。
文献中采用的一种常见策略是 基于对每个小批量 [39] 中的负样本进行采样。然而,这种优化机制 对于 使用可扩展的空间增强数据 训练我们的深度模型 有重要的局限性。更详细地说,这个小批量采样过程假设每个patch 在一个训练周期内可以看到一次,因此,xai 只存在于当前迭代的一个小批量中。因此,CNN 模型只能看到属于该 minibatch 的相应负样本 xaj,而无法考虑 minibatch 之外的其他重要样本。准确地说,这一事实可以大大减少训练期间对比土地覆盖类型的语义多样性,这是允许从无监督的角度学习更多信息 RS 图像表示的关键因素。
为了解决这个问题,我们采用 动量更新规则 [61]、[66] 来训练我们新提出的无监督 RS 图像表征模型。具体来说,构建图像块 的深度嵌入队列,其中 队列的大小强制大于小批量的大小。通过这种方式,可以通过考虑单批次之外的对比 patches 来 显著增强无监督学习过程。在训练阶段,当前小批量的嵌入 与 队列中的嵌入 进行比较,因为它们被逐步替换。当前小批量的嵌入入队,最旧的嵌入出队。此外,为了持续更新队列中的深度嵌入,引入了一个参数集为 θaux 的辅助 CNN 模型。我们将 θaux 模型识别为 动量 CNN,并更新如下:
![]()
其中 m ∈ [0, 1) 是动量系数。值得注意的是,只有具有 θ 的 CNN 是通过反向传播更新的。具有参数 θaux 的动量 CNN 可以比具有 θ 的 CNN 更平滑地演化。然后,队列中的嵌入(由动量 CNN 编码)更新为
![]()
在这个表达式中,fi 表示动量 CNN 生成的特征。换句话说,在每个训练时期之后,队列中的嵌入被由动量 CNN 编码的嵌入替换。为此,算法 1 详细介绍了所提出的优化机制。

IV . EXPERIMENTS
A. 数据集描述
在这项工作中,我们使用两个基准 RS 图像数据集来验证所提出方法的有效性。下面提供了数据集的详细描述。
1) 国家农业图像计划 (NAIP) [38]:
生成该数据集是为了验证 Tile2V ec 框架 [38]。具体来说,它是从美国农业部 (USDA) 的 NAIP 提供的高分辨率 RS 图像中收集的。所有图像位于纬度 36.45 至 37.05 和经度 -120.25 至 -119.65 之间。该数据集中共有 1000 张图像,大小为 50×50 像素,空间分辨率为 0.6 m,具有四个光谱波段(红、绿、蓝和红外)。每个图像都使用从农田数据层 (CDL) 获得的 28 个类别进行标记,这些类别是玉米、棉花、大麦、灌木丛、冬小麦、燕麦、紫花苜蓿、草地、洋葱、西红柿、休耕、葡萄、其他树木作物、柑橘、杏仁、核桃、黑小麦、开心果、大蒜、橙子、石榴、Dbl Crop WinWht/玉米、Dbl Crop WinWht/高粱、开阔水域、发达/开放空间、发达/低强度、发达/中等强度和发达/高强度。 NAIP 数据集是公开可用的。
2) EuroSAT [67]:
该数据集是为基于多光谱 RS 图像的土地利用和土地覆盖分类而创建的。特别地,它由 27 000 个标记和地理参考的 Sentinel-2 图像组成,大小为 64 × 64 像素,空间分辨率为 10 m,13 个光谱波段覆盖电磁波谱的 443 至 2190 nm 波长区域。每个图像属于总共十个语义土地覆盖类别中的一个类别:一年生作物、森林、草本植被、公路、工业、牧场、永久性作物、住宅、河流和海湖。 EuroSA T 档案也是公开可用的。
选择这两个 RS 档案来从单源土地覆盖采集的角度评估无监督 RS 图像表征过程的性能,因为它们是两个流行的基准集合,也有可用的补充开放访问数据来训练未标记场景的模型,也就是说,一旦分别使用未标记的 NAIP 和 Sentinel-2 图像训练了相应的无监督表征模型,NAIP 和 EuroSA T 数据集仅用于评估目的。具体来说,我们使用以下过程构建了两个大型未标记训练集(一个用于 NAIP,另一个用于 EuroSAT)。
1) 在 NAIP 的情况下,我们通过 USGS EarthExplorer 工具下载位于美国加利福尼亚州弗雷斯诺附近的中央山谷地区的 100 个 NAIP 全场景。下载场景的地理位置在图 2(a) 中的橙色矩形内。然后,我们从下载的图块中随机选择总共 100 000 张图像(大小为 250 × 250 像素)。
2) 以 EuroSAT 为例,我们下载了 100 个从全球范围内采样的 Sentinel-2 Level-1C 图像产品。图 2(b) 显示了下载的 Sentinel-2 产品的地理位置。然后,我们从下载的产品中随机选择 100 000 张图像(大小为 264 × 264 像素)。
图 3 显示了创建训练数据集的示例。从一个 Sentinel-2 tile 中,我们随机裁剪一张图像(大小为 264 × 264 像素),考虑到 锚点和空间增强块的大小为 64 × 64 像素,根据定义的空间增强标准,它们的中心之间的距离为 100 像素。
B. 实验设置
所提出的方法在 PyTorch [68] 中实现。 ResNet18 [27] 网络已被选为基本骨干架构,用于提取 RS 图像的相应深度嵌入,也就是说,我们在所提出方法的锚点和动量 CNN 上都使用了 ResNet18 模型。重要的是要注意,其他架构,如 ResNet50 或 ResNet101,可以在提出的框架内使用。尽管如此,在这项工作中选择了 ResNet18 模型,因为它通常在许多不同的 RS 应用程序中提供复杂性和性能之间的正平衡。在训练阶段,从 NAIP 和 Sentinel-2 图像中裁剪出的锚点和空间增强块的大小分别为 50×50 和 64×64 像素,以与基准数据集保持一致。采用 RandomFlip 和 RandomRotation 进行数据增强。关于考虑的参数,τ 和 D 分别设置为 0.25 和 128。此外,根据 [38] 中使用的设置以及在 NAIP 数据集上对比此配置后,距离参数 d 设置为 100。采用随机梯度下降(SGD)优化器进行训练。初始学习率设置为 0.01,每 30 个 epoch 衰减 0.5。批量大小为 256,我们总共训练 CNN 模型 100 个时期。为了验证所提出的方法相对于不同的最先进方法的有效性,我们在实验比较中包括三种不同的 RS 图像表征技术:1)深度卷积生成对抗网络(DCGAN)[54] ; 2)MARTAaa GAN[62]; 3) 在 ImageNet 上预训练的 ResNet18 模型,同时考虑最具判别力的主要成分(预训练的 CNN+PCA)[29] ;和 4) Tile2Vec [38]。在预训练 CNN+PCA 的情况下,重要的是要强调我们 在提取预训练特征后使用 PCA 方法生成与其他方法具有相同维度的相应深度嵌入。所有实验均在 NVIDIA Tesla P100 图形处理单元 (GPU) 上进行。
为了衡量所提出方法与其他方法相比的有效性,我们在训练后提取了 NAIP 和 EuroSAT 集合的深度嵌入。然后,我们使用可用的注释为每个数据集计算相应的分类结果。更详细地说,我们提供了五个不同的实验,用于从多个角度验证和分析结果:
1) 基于 随机森林 (RF) 分类的深度嵌入评估:我们首先利用 RF 分类器根据所考虑方法获得的两个数据集的提取特征嵌入来衡量分类性能。对于每个数据集,我们随机选择 80% 的图像来训练分类器,并评估其在其余 20% 图像上的性能。为了获得整体准确度的平均分数,总共进行了 100 次试验。然后,我们计算获得的准确度分数的均值和标准差值。
2)图像检索的可视化:在这个实验中,我们进行了检索测试,从定性的角度探索所考虑的表征方法的性能。特别是,我们从完整的 NAIP 场景中提取一个query图像块。然后,我们使用预训练的 CNN+PCA、Tile2Vec 和 SauMoCo 模型来获得所选query以及场景中其余query的深度嵌入。最后,我们根据query计算它们相应的相似度图,并检索整个场景中的十个最近邻块。
3) CNN 模型初始化评估:在这个实验中,我们利用 ResNet18 网络作为分类器,通过使用两种不同的初始化训练该模型,即 预训练的 ImageNet 参数 和 我们的 SauMoCo 方法预训练的参数。目的是评估所提出方法作为 CNN 模型初始化的有效性。具体来说,我们使用 80% 的训练图像和 20% 的测试图像在 EuroSAT 数据集上训练 ResNet18 模型。为了量化相应的性能,我们在每个训练时期后计算测试集的总体准确度,并观察相应的学习曲线。
4) SauMoCo 的超参数分析:我们研究了所提出模型对 τ 参数的敏感性。对于每个数据集,我们测试了 0.05 到 0.5 范围内的八个不同值。然后,我们计算相应的基于 RF 的分类精度,考虑 80% 的训练图像和 20% 的测试图像。
5) SauMoCo 不同 CNN 主干架构的比较:在上述实验中,我们利用 ResNet18 作为 CNN 主干架构来提取特征嵌入。为了通过使用 SauMoCo 的不同 CNN 骨干架构来评估场景表征性能,我们还在 NAIP 数据集上进行的 RF 分类上使用了 ResNet50。实验设置与第 IV-B1 节一致。
C. 实验结果
1)基于RF分类的深度嵌入评估:
为了监测学习效果,图 4 显示了在训练阶段,即在每个训练时期之后,我们使用所提出的 SauMoCo、Tile2Vec、DCGAN 和 MARTA GAN 模型提取的基于深度嵌入的 RF 性能生成的深度嵌入来计算相应的基于 RF 的分类结果。可以观察到,在应用 RF 分类时,基于 SauMoCo 的深度嵌入优于在训练阶段从其他比较方法中提取的深度嵌入。关于 DCGAN 和 MARTA GAN,该模型提供了最不稳定的结果,同时也导致性能明显低于 SauMoCo 和 Tile2Vec,后者始终获得最佳和第二好的性能。在 Tile2Vec 的情况下,三元组损失使得该模型要求很高,因为它需要一组具有大约 ![]() 个样本的三元组,这对于可扩展的数据集来说是无法承受的。准确地说,这种限制可能会导致 模型训练受限,以至于学习到的深度嵌入无法正确表示更广泛的土地覆盖语义概念。在所提出的方法中,由于使用了深度嵌入队列,因此 基于每个小批量内的图像 以及数据集中的所有其他图像计算语义相似度。然后,可以通过捕获 X 中 RS 图像之间所有可能的距离度量来训练 SauMoCo 模型。此外,空间增强图像是在线裁剪的,这也提供了作为数据增强策略的额外优势。通过这样做,可以在训练阶段(相对于锚图像)生成更高语义的相似图像。相比之下,Tile2Vec 中使用的三元组集是预先构建的,并且在训练期间没有表现出任何数据增强能力。因此,所提出的方法还可以利用所提出的空间增强标准。
个样本的三元组,这对于可扩展的数据集来说是无法承受的。准确地说,这种限制可能会导致 模型训练受限,以至于学习到的深度嵌入无法正确表示更广泛的土地覆盖语义概念。在所提出的方法中,由于使用了深度嵌入队列,因此 基于每个小批量内的图像 以及数据集中的所有其他图像计算语义相似度。然后,可以通过捕获 X 中 RS 图像之间所有可能的距离度量来训练 SauMoCo 模型。此外,空间增强图像是在线裁剪的,这也提供了作为数据增强策略的额外优势。通过这样做,可以在训练阶段(相对于锚图像)生成更高语义的相似图像。相比之下,Tile2Vec 中使用的三元组集是预先构建的,并且在训练期间没有表现出任何数据增强能力。因此,所提出的方法还可以利用所提出的空间增强标准。
表 I 列出了使用所考虑的 RS 图像表征方法的 RF 分类性能,其中 平均准确度和标准偏差分数是基于 100 次试验进行的。从报告的结果中,可以做出一些重要的观察。具体来说,可以看出 SauMoCo 相对于所有比较方法都取得了显著改进,NAIP 的准确度提高了 7% 到 10%,EuroSAT 的准确度提高了 2% 到 12%。更详细地说,Tile2Vec 始终获得第二好的性能,其次是预训练的 CNN+PCA、DCGAN 和 MARTA GAN。在 NAIP 数据集上,DCGAN 实现了与预训练 CNN+PCA 所实现的性能相似的性能,而 Tile2Vec,尤其是 SauMoCo 能够提供更好的结果。在 EuroSA T 上,预训练的 CNN+PCA 和 MARTA GAN 的表现明显优于 DCGAN。与DCGAN相比,MARTA GAN中引入的多层特征匹配可以通过判别模型提高图像的编码性能。然而,Tile2Vec 改进了所有这些分类结果,并且所提出的方法显着地实现了最佳性能。在两个集合中获得的结果揭示了类似的趋势,即 Tile2Vec 的良好性能和 SauMoCo 在表征未标记的 RS 场景时的卓越有效性。
为了更详细地分析 Tile2Vec 和 SauMoCo 之间的差异,表 II 提供了 RF 分类器在 EuroSAT 数据集上获得的相应类 F1 分数,其中两个最佳结果以粗体和灰色阴影字体突出显示。可以观察到,所提出的方法分别在两个和五个土地覆盖类别中获得最佳和第二好的性能。尽管 Tile2Vec 在五个类别中也表现出积极的结果,但其余类别的表现相当有限,在某些情况下甚至比预训练的 CNN+PCA 和 MARTA GAN 更差。准确地说,这些重要的差异使得 SauMoCo 从全局的角度来看更加稳定和准确,表明 所提出的方法 能够提取关于更广泛的语义概念的更多相关信息。
2) 图像检索的可视化:
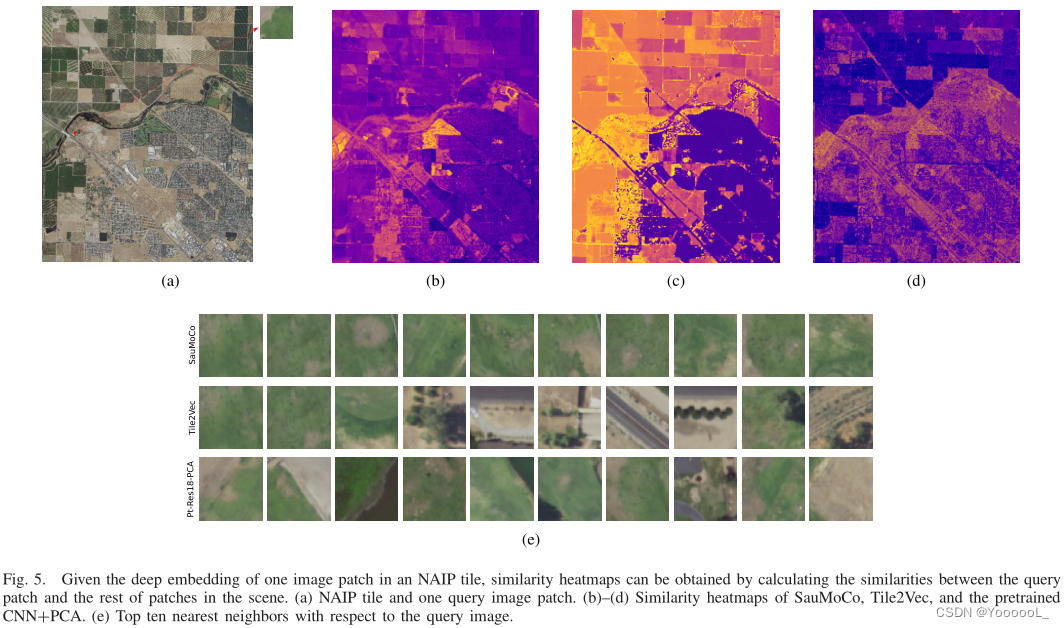
如图 5 所示,我们从 NAIP 块中提取一个query图像块。然后,我们根据所考虑的方法获得其深度嵌入 和 图块中其余patches的深度嵌入。随后,我们计算它们的相似性并获得 SauMoCo 的相应热图 [图5(b)],Tile2Vec [图5(c)] 和 预训练的 CNN+PCA [图 5(d)],其中颜色越亮表示嵌入空间的相似度越高。此外,十个最近邻块如图 5(e)所示。由于可以在热图中观察到,与query相关的最相似patch的位置可以在图 5(b)中更清楚地识别出来。准确地说,这些结果表明 RS 场景的语义信息没有根据 Tile2Vec 和预训练的 CNN+PCA 模型正确编码,因为图像中有较大部分被认为与嵌入空间中的查询相似。关于最近邻结果,可以看出从 SauMoCo 生成的嵌入空间中检索到的图像块与查询在query上最相似,也就是说,所提出的方法能够对查询的语义内容进行建模比其他方法更准确,因为所有检索到的图像都显示相似的土地覆盖模式。
3) CNN 模型初始化评估:
图 6 显示了使用两种不同的初始化策略时 ResNet18 模型在 EuroSAT 集合上的学习曲线:使用所提出的方法获得的参数和使用预训练的 ImageNet 参数。根据显示的结果可以看出,当CNN模型的参数通过所提出的方法进行初始化时,分类精度可以略有提高。尽管预训练的 ImageNet 初始化在训练过程开始时表现出更高的分类精度,但 SauMoCo 能够在 30 个 epoch 后始终如一地取得更好的结果。这一事实表明,所提出的方法能够在相应的嵌入空间中捕获更丰富的语义信息,因为 通过 SauMoCo 预训练的参数 可以 发现损失函数的更好的最小位置。
4) SauMoCo 的超参数分析:
所提出方法的一个重要超参数是 τ,它 控制样本分布的集中水平。为了研究所提出的模型对 τ 的敏感性,我们对由不同超参数值生成的嵌入空间进行了几个额外的分类实验。特别是,图 7 显示了基于 SauMoCo 的 RF 分类在两个基准数据集上关于八个不同 τ 值的有效性:1) NAIP 和 2) EuroSAT。可以观察到,当 τ 为 0.25 时,两个数据集的分类性能均最佳。尽管如此,相应的分类结果在 0.15 到 0.4 的范围内非常一致,这也表明 所提出的方法在 τ 超参数方面具有足够的稳定性。
5)SauMoCo 不同 CNN 主干架构的比较:
图 8 显示了在 SauMoCo 的训练机制下,基于不同 CNN 架构(ResNet18 和 ResNet50)编码的深度嵌入在 NAIP 数据集上的 RF 分类性能。可以观察到,与 ResNet18 相比,从 ResNet50 提取的特征嵌入的质量略有提高。如表 III 所示,与 ResNet18 相比,基于 ResNet50 深度嵌入的分类精度在 NAIP 数据集上提高了 0.5%。
五、结论和未来路线
本文介绍了一种新的无监督深度度量学习框架 (SauMoCo) 来表征未标记的 RS 场景。具体来说,所提出的方法最初 定义了一个空间增强标准,以根据地理第一定律 发现语义相似的 RS 图像。然后,构建一个深度嵌入队列,使得 队列的大小被强制大大大于批量大小,以提高训练期间对比土地覆盖类型的语义多样性。为了实现这一目标,辅助 CNN 模型 也用于持续更新队列中的深度嵌入。该工作的实验部分在两个基准数据集上进行,并基于不同表征方法的使用,揭示了所提出的无监督深度度量学习模型能够在表示无标记遥感图像的任务中提供相对于其他最新技术的竞争优势。
这项工作得出的主要结论之一是 在学习无监督 RS 图像特征时 考虑更广泛的土地覆盖类型的相关性。在这方面,所提出的方法 利用 定义的空间增强标准 和 考虑的深度嵌入队列 来在对比学习过程中 丰富不同 RS 类别的语义信息。准确地说,此功能使我们的 SauMoCo 能够增强无监督土地覆盖类别之间的全局辨别能力,并为不同的数据集和设置提供更稳健的行为。由于所提出的方法取得了显著的性能,我们未来的工作将致力于 使其 适应传感器间数据 和 其他重要的遥感任务,如 高光谱图像的降维 或 细粒度的土地利用分类。