论文链接:https://ui.adsabs.harvard.edu/abs/2020arXiv200707296R/abstract
代码链接:https://github.com/rand2ai/fedboosting
摘要:
创新点:
(1)针对隐私保护和梯度保护,使用联邦学习框架
(2)由于存在非独立同分布数据,导致出现权值发散现象,提出FL增强算法
(3)防御梯度泄漏攻击,提出基于同态加密和差分隐私的梯度共享安全协议
1、引言
第一段:
首先:通过数据隐私问题的限制,传统的机器学习无法实现,需要进行分布式训练,引出联邦学习
其次:对联邦学习进行简述,引用文献进行讲述
最后:通过文献引出文章主要需要解决的问题,即梯度问题,用引用的文献增加说服力
个人数据保护和隐私保护问题尤其引起了研究人员的关注 [1]、[2]、[3]、[4]、[5]、[6]、[7]。由于对数据共享的限制,典型的机器学习方法可能无法实现需要集中数据进行模型训练。因此,分散的数据训练方法更具吸引力,因为它们在隐私保护和数据安全保护方面提供了预期的好处。联邦学习 (FL) [8]、[9] 被提出来解决这样的问题,即允许各个数据提供者协作训练共享的全局模型,而无需集中聚合数据。麦克马汉等人。 [9] 提出了一种实用的基于平均聚合的深度网络分散训练方法。对各种数据集和架构进行了实验研究,证明了 FL 在不平衡和独立同分布 (IID) 数据上的稳健性。频繁的更新方法通常可以导致更高的预测性能,而通信成本急剧增加,特别是对于大型数据集 [9]、[10]、[11]、[12]、[13]。Koneˇcn `y 等人。 [11] 专注于解决效率问题并提出了两种权重更新方法,即基于联合平均(FedAvg)的结构化更新和草图更新方法,以减少将梯度从本地机器传输到中央服务器的上行链路通信成本.
第二段:
点明联邦学习种的两大挑战:预测性能与数据隐私
一方面xx(讨论预测性能):一个文献的引出会接着一个问题的出现,从而引出下一个文献(一环扣一环)
中间加入一段话表明自己所做工作的必要性
另一方面xx(讨论隐私):举例说明
预测性能和数据隐私是 FL 研究中的两大挑战。一方面,FL 的准确性在非独立和非同分布 (Non-IID) 数据上显着降低 [14]。赵等。 [14] 表明可以使用每个本地机器上的类别分布与全球人口分布之间的地球移动距离 (EMD) 来定量测量权重差异。因此,他们建议在所有边缘设备之间共享一小部分数据,以改进非独立同分布数据上的模型泛化。然而,当对数据共享的限制到位时,这种策略是不可行的,这通常会导致隐私泄露。李等。 [15] 研究了 FedAvg 的收敛特性,并得出结论,其通信效率和收敛速度之间存在权衡。他们认为该模型在异构数据集上收敛缓慢。 根据我们在本文中的实证研究,我们确认给定非独立同分布数据集,训练需要更多的迭代才能达到最佳解决方案并且经常无法收敛,特别是当局部模型在具有小规模的大规模数据集上训练时批量大小或全局模型的数量在大量纪元后聚合。另一方面,模型梯度通常被认为在 FL 系统中共享以进行模型聚合是安全的。然而,一些研究表明,从模型梯度中恢复训练数据信息是可行的。例如,弗雷德里克森等人。 [16] 和 Melis 等人。 [17] 报道了两种方法,可以识别训练批次中具有某些属性的样本。希塔吉等人。 [18] 提出了一种生成对抗网络 (GANs) 模型作为对抗客户端,以在不知道其他客户端的训练数据的情况下估计来自其他客户端输出的数据分布。朱等。 [19] 和赵等人。 [20] 证明数据恢复可以表述为梯度回归问题,假设来自目标客户端的梯度可用,这在大多数 FL 系统中是一个基本有效的假设。此外,Ren 等人提出的生成回归神经网络 (GRNN)。 [21] 由两个分支的生成模型组成,一个是基于 GAN 生成假训练数据,另一个是基于全连接层生成相应的标签。通过回归真实梯度和由假数据和相关标签生成的假梯度来揭示训练数据。
第三段:
在本文中,我们提出了联合提升 (FedBoosting) 方法来解决一般 FL 框架中的权重发散和梯度泄漏问题。我 们不是在聚合全局模型时平等对待各个本地模型,而是从收敛状态和泛化能力方面考虑本地客户端的数据多样性。为了解决通过共享梯度泄露数据的潜在风险,提出了一种基于差分隐私(DP)的线性聚合方法,使用同态加密(HE)[22]来加密提供两层保护的梯度。所提出的加密方案只会导致计算成本的微不足道的增加。
第四段:
使用公共基准上的文本识别任务以及两个数据集上的二元分类任务对所提出的方法进行了评估,证明了其在收敛速度、预测准确性和安全性方面的优越性。还评估了由于加密导致的性能下降。我们的贡献有四方面:
• 我们提出了一种新的聚合策略,即用于 FL 的 FedBoosting,以解决权重差异和梯度泄漏问题。我们凭经验证明 FedBoosting 的收敛速度明显快于 FedAvg,而通信成本与传统方法相同。特别是当局部模型以小批量训练并且全局模型在大量 epoch 后聚合时,我们的方法仍然可以收敛到合理的最优值,而 FedAvg 在这种情况下经常失败。
• 我们引入了一种使用HE 和DP 来加密在服务器和客户端之间流动的梯度的双层保护方案,从而保护数据隐私免受梯度泄漏攻击。
• 我们通过直观地评估决策边界来展示我们的方法在两个数据集上的可行性。此外,与集中式方法和 FedAvg 相比,我们还展示了其在多个大型非独立同分布数据集上的视觉文本识别任务中的卓越性能。实验结果证实,我们的方法在收敛速度和预测精度方面优于 FedAvg。这表明 FedBoosting 策略可以在隐私保护场景中与其他深度学习 (DL) 模型集成。
• 我们对拟议的 FedBoosting 的实施是公开的,以确保可重复性。它还可以在分布式多图形处理单元 (GPU) 设置中运行。
3、方法
3.1、FedBoosting 框架
FedAvg [9] 通过平均来自本地客户端的梯度生成一个新模型。然而,在Non-IID数据上,由于数据分布的不一致,局部模型的权重可能会收敛到不同的方向。因此,简单的平均方案表现不佳,尤其是当存在强偏差和极端异常值时 [14]、[15]、[35]。因此,我们建议使用提升方案,即 FedBoosting,根据不同局部验证数据集上的泛化性能自适应地合并局部模型。同时,为了保护数据隐私,去中心化客户端和服务器之间的信息交换是被禁止的。因此,不是在客户端之间交换数据,而是通过中央服务器交换加密的本地模型,并在每个客户端上独立验证。如图 1 所示。
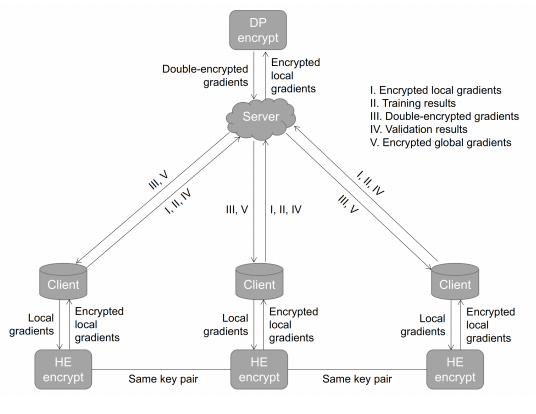
图 1: 所提出的 FedBoosting 和加密协议的示意图。有两个客户端用于演示目的,而所提出的方法可以与任意数量的本地客户端一起使用。
与 FedAvg 相比,所提出的 FedBoosting 考虑了每个客户端模型的适应性和泛化性能,并在所有客户端模型上使用不同的权重自适应地合并全局模型。
具体内容:(2022年8月9号的博客)
tip:发生了一件特别好玩的事,在网上搜这篇文章,想看下有没有大神针对这篇文章进行解读,发现了文章作者写过解读,特别惊喜,但点开阅读原文后,发现了404;但在页面的第一条文章也是这一篇,我点进去一看,这不是我写的吗(这时我还没反应过来怎么一回事,还心想,这链接不行呀,还跳转错误,把我昨天写的博客给跳出来了,但这日期也不对呀,怎么是22年8月份的呢)(之后才反应过来原来自己在22年的时候已经看过这篇文章了,还写了博客分析,自己给忘了。唉,太笨啦)
(之前心动过的东西,再看仍会心动)