系列文章目录
- python开发低代码数据可视化大屏:pandas.read_excel读取表格
- python实现直接读取excle数据实现的百度地图标注
- python数据可视化开发(1):Matplotlib库基础知识
文章目录

前言
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。在python数据可视化的开发过程中,pandas读取Excel表格数据,然后通过matplotlib、echarts等图表工具进行展示,是最为常见的数据操作。如下:表格为不同月份钢材的价格、销量和库存的演示数据,就实际工作中遇见的问题作为实践学习的目标。
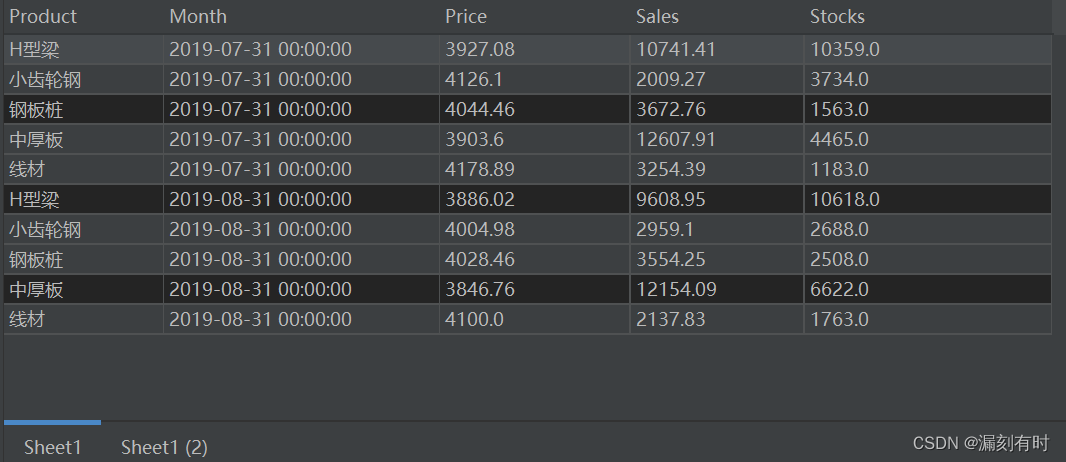
实践目标
- 通过pandas读取excel的参数
- 将读取后的数据转化为flask数据可视化API对接的json格式
- 将读取后的数据结果导出对应的Excel表格
- 将读取后的数据结果进行透视运算
一、读取Excel数据
read_excel参数说明
def read_excel(io,sheet_name=0,header=0,names=None,index_col=None,parse_cols=None,usecols=None,squeeze=False,dtype=None,engine=None,converters=None, true_values=None, false_values=None,skiprows=None,nrows=None,na_values=None,keep_default_na=True,na_filter=True,verbose=False,parse_dates=False,date_parser=None,thousands=None,comment=None,skip_footer=0,skipfooter=0,convert_float=True,mangle_dupe_cols=True,**kwds)
io,为文件类对象,一般作为读取文件的路径;sheet_name,该参数为指定读取excel的表格名;usecols,该参数为返回指定的列,usecols=[A,C]表示只选取A列和C列。usecols=[A,C:E]表示选择A列,C列、D列和E列
读取全部数据
代码如下:
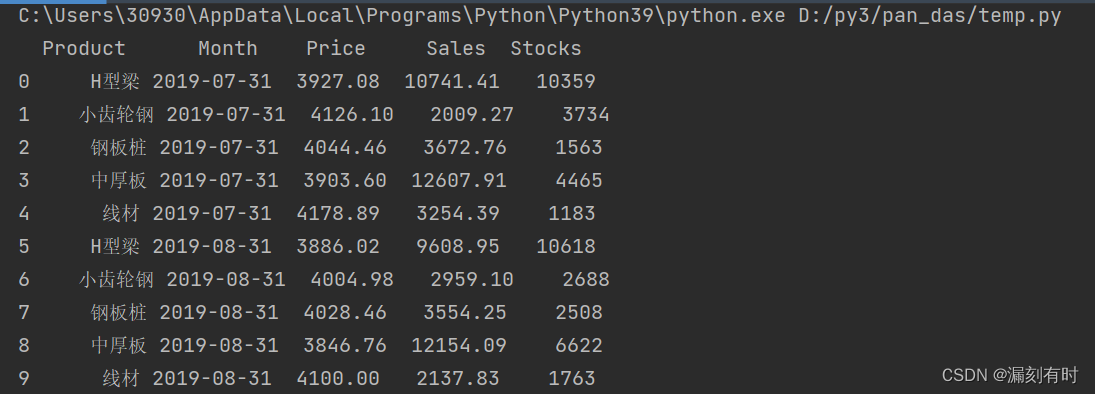
import pandas as pd
df = pd.read_excel(r'temp.xlsx', sheet_name=0)
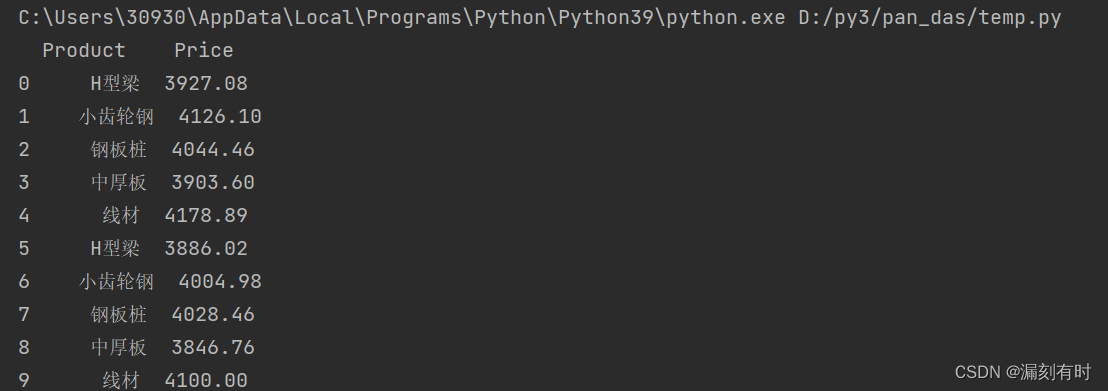
读取指定列数据
代码如下:
import pandas as pd
df = pd.read_excel(r'temp.xlsx', sheet_name=0, usecols=[0, 2])
print(df)
二、DataFrame转化为json
DataFrame.to_json参数说明
DataFrame.to_json(path_or_buf=None, orient=None, date_format=None, double_precision=10, force_ascii=True, date_unit=‘ms’, default_handler=None, lines=False, compression=‘infer’, index=True, indent=None)
- path_or_buf :str 或 file handle, 默认为 None,文件路径或对象。如果未指定,则结果以字符串形式返回;
- force_ascii :bool, 默认为True,强制将字符串编码为ASCII。
- date_format :{None, ‘epoch’, ‘iso’},日期转换的类型,默认为date_format=‘epoch’,意为将日期转为毫秒形式,输出内容为
1564531200000;date_format=‘iso’,输出内容为:“2018-09-17T00:00:00Z”。实际开发中,建议使用epoch,在数据可视化展示页面进行时间戳的转化即可。 - JSON字符串格式:
| 参数 | 说明 |
|---|---|
| ‘split’ | 类似{‘index’-> [index], |
| ‘columns’ | [columns],‘data’-> [values]}的字典 |
| ‘records’ | 类似于[{column-> value},…,{column-> value}]的列表 |
| ‘index’ | 类似{index-> {column-> value}}的字典 |
| ‘columns’ | 类似{column-> {index-> value}}的字典 |
| 'values’ | 只是值数组 |
| ‘table’ | 类似{‘schema’:{schema},‘data’:{data}}的字典 |
不同参数的调用,JSON内容输出逻辑如下:
split参数json输出
import pandas as pd
df = pd.read_excel(r'temp.xlsx', sheet_name=0)
# print(df)
# 01.输出为json
res = df.to_json(orient='split', force_ascii=False)
print(res)
数据格式:
{
"columns":["Product","Month","Price","Sales","Stocks"],"index":[0,1,2,3,4,5,6,7,8,9],"data":[["H型梁",1564531200000,3927.08,10741.41,10359],["小齿轮钢",1564531200000,4126.1,2009.27,3734],["钢板桩",1564531200000,4044.46,3672.76,1563],["中厚板",1564531200000,3903.6,12607.91,4465],["线材",1564531200000,4178.89,3254.39,1183],["H型梁",1567209600000,3886.02,9608.95,10618],["小齿轮钢",1567209600000,4004.98,2959.1,2688],["钢板桩",1567209600000,4028.46,3554.25,2508],["中厚板",1567209600000,3846.76,12154.09,6622],["线材",1567209600000,4100.0,2137.83,1763]]}
columns参数json输出
import pandas as pd
df = pd.read_excel(r'temp.xlsx', sheet_name=0)
# print(df)
# 01.输出为json
res = df.to_json(orient='columns', force_ascii=False)
print(res)
数据格式:
{
"Product":{
"0":"H型梁","1":"小齿轮钢","2":"钢板桩","3":"中厚板","4":"线材","5":"H型梁","6":"小齿轮钢","7":"钢板桩","8":"中厚板","9":"线材"},"Month":{
"0":1564531200000,"1":1564531200000,"2":1564531200000,"3":1564531200000,"4":1564531200000,"5":1567209600000,"6":1567209600000,"7":1567209600000,"8":1567209600000,"9":1567209600000},"Price":{
"0":3927.08,"1":4126.1,"2":4044.46,"3":3903.6,"4":4178.89,"5":3886.02,"6":4004.98,"7":4028.46,"8":3846.76,"9":4100.0},"Sales":{
"0":10741.41,"1":2009.27,"2":3672.76,"3":12607.91,"4":3254.39,"5":9608.95,"6":2959.1,"7":3554.25,"8":12154.09,"9":2137.83},"Stocks":{
"0":10359,"1":3734,"2":1563,"3":4465,"4":1183,"5":10618,"6":2688,"7":2508,"8":6622,"9":1763}}
index参数json输出
import pandas as pd
df = pd.read_excel(r'temp.xlsx', sheet_name=0)
# print(df)
# 01.输出为json
res = df.to_json(orient='index', force_ascii=False)
print(res)
数据格式:
{
"0":{
"Product":"H型梁","Month":1564531200000,"Price":3927.08,"Sales":10741.41,"Stocks":10359},"1":{
"Product":"小齿轮钢","Month":1564531200000,"Price":4126.1,"Sales":2009.27,"Stocks":3734},"2":{
"Product":"钢板桩","Month":1564531200000,"Price":4044.46,"Sales":3672.76,"Stocks":1563},"3":{
"Product":"中厚板","Month":1564531200000,"Price":3903.6,"Sales":12607.91,"Stocks":4465},"4":{
"Product":"线材","Month":1564531200000,"Price":4178.89,"Sales":3254.39,"Stocks":1183}}
values参数json输出***
适合于地图数据可视化二维数组调用的输出。
import pandas as pd
df = pd.read_excel(r'temp.xlsx', sheet_name=0)
# print(df)
# 01.输出为json
res = df.to_json(orient='values', force_ascii=False)
print(res)
数据格式:
[["H型梁",1564531200000,3927.08,10741.41,10359],["小齿轮钢",1564531200000,4126.1,2009.27,3734],["钢板桩",1564531200000,4044.46,3672.76,1563],["中厚板",1564531200000,3903.6,12607.91,4465],["线材",1564531200000,4178.89,3254.39,1183],["H型梁",1567209600000,3886.02,9608.95,10618],["小齿轮钢",1567209600000,4004.98,2959.1,2688],["钢板桩",1567209600000,4028.46,3554.25,2508],["中厚板",1567209600000,3846.76,12154.09,6622],["线材",1567209600000,4100.0,2137.83,1763]]
records参数json输出***
records,是在API对接过程中,最为常用的数据格式,也是DataFrame转json过程中,需要重点使用的。
import pandas as pd
df = pd.read_excel(r'temp.xlsx', sheet_name=0)
# print(df)
# 01.输出为json
res = df.to_json(orient='records', force_ascii=False)
print(res)
数据格式:
[{
"Product":"H型梁","Month":1564531200000,"Price":3927.08,"Sales":10741.41,"Stocks":10359},{
"Product":"小齿轮钢","Month":1564531200000,"Price":4126.1,"Sales":2009.27,"Stocks":3734},{
"Product":"钢板桩","Month":1564531200000,"Price":4044.46,"Sales":3672.76,"Stocks":1563},{
"Product":"中厚板","Month":1564531200000,"Price":3903.6,"Sales":12607.91,"Stocks":4465},{
"Product":"线材","Month":1564531200000,"Price":4178.89,"Sales":3254.39,"Stocks":1183}]
三、数学运算
print(df['Price'].sum()) # 求和
print(df['Price'].max()) # 求最大值
print(df['Price'].mean()) # 求平均数
print(df['Price'].median()) # 求中位数
四、透视表运算输出
pivot_table透视表
import pandas as pd
df = pd.read_excel(r'temp.xlsx', sheet_name=0) # , usecols=[0, 2]
# 透视功能计算
new_data = pd.pivot_table(df, index=["Product"], aggfunc=sum)
# print(new_data)
输出JSON
使用reset_index(),重新格式化索引号。
# 透视索引号,新增行,
res = new_data.reset_index().to_json(orient='records', force_ascii=False)
print(res)
数据格式:
[{
"Product":"H型梁","Price":7813.1,"Sales":20350.36,"Stocks":20977},{
"Product":"中厚板","Price":7750.36,"Sales":24762.0,"Stocks":11087},{
"Product":"小齿轮钢","Price":8131.08,"Sales":4968.37,"Stocks":6422},{
"Product":"线材","Price":8278.89,"Sales":5392.22,"Stocks":2946},{
"Product":"钢板桩","Price":8072.92,"Sales":7227.01,"Stocks":4071}]
@漏刻有时