1,直接在html代码中添加“charset="text/html;utf-8”。
这个方法,会直接让浏览器使用gbk编码模式。这虽然可以解决网页乱码的问题,但不能根本解决编码问题。如果你后面确定不使用含有中文的一些函数操作,那么你可以使用这个方法,否则不推荐使用。

这里举例说明一下,如下所示:

标号1位置的代码,表面浏览器会采用gbk的编码模式,事实也确实如此。运行后如图所示:
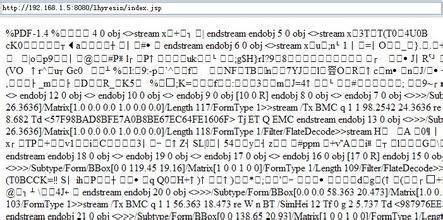
标记2、3位置的代码,就是用获取之前网页设置的cookie。这时候浏览器运行这段脚本的时候就出错了。打开apache24中的log文件,在erro中我们可以看到错误日志,如下图所示:

通过这四个红色框,我们就发现了脚本运行出错的根本原因,最后一个红色框里已经说明了:
AH01215: UnicodeEncodeError: 'gbk' codec can't encode character '\\x8f'
这个错误,说直白一点,就是编码出问题了,网页代码用的是gbk编码,而python脚本用的是utf-8编码,所以在使用print打印时,apache报错了或者直接乱码显示。
那么为了避免这些问题,我推荐大家使用第二个解决网页编码、乱码的方法。
2,python文件中,指明控制台的编码的方式,即添加:
import sys
sys.stdout=codecs.getwriter('utf-8')(sys.stdout.buffer);
这两句代码,类似于java中的输出流套接方法,getwriter(“utf-8”)返回一个streamwritter(‘parameter’)函数,而sys.stdout.buffer就作为参数,供streamwritter(‘parameter’)使用。这样就指明了sys.stdout标准输出流的编码方式为utf。
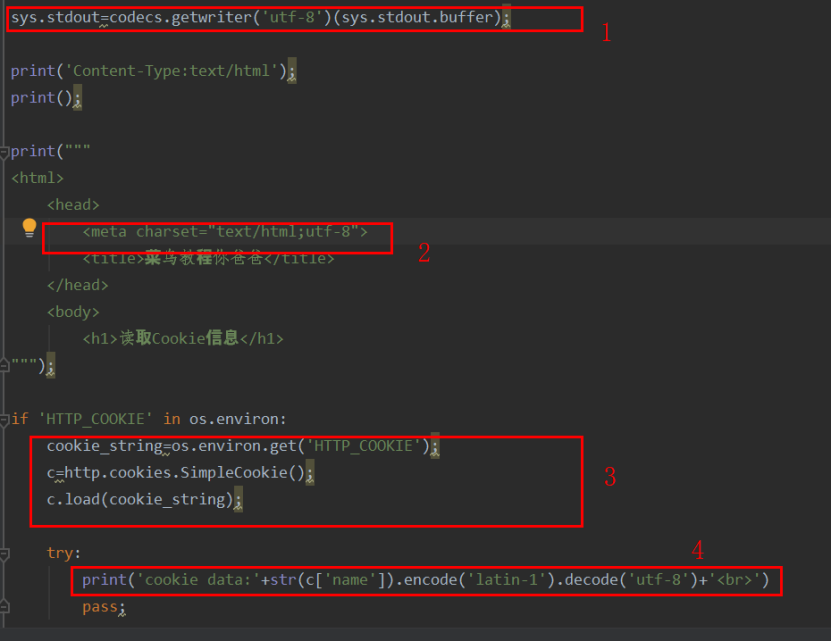
如此一来,整个网页的编码方式就是’utf’了。如上图所示,添加标记1的代码后,整个网页的编码都是utf-8了,如下图运行所示:
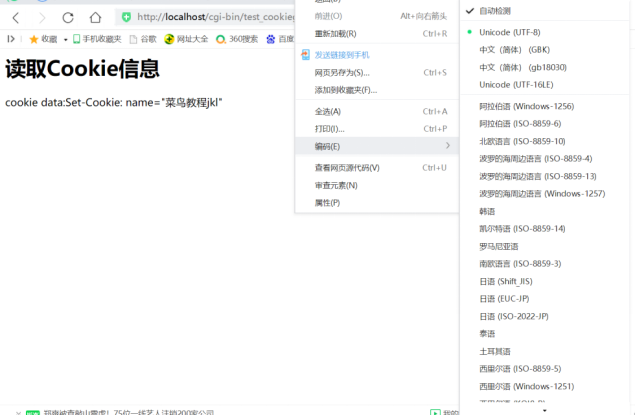
解决了整个网页编码的问题,最后我们还要解决python函数调用cookie时出现的乱码问题。如图标记4所示,我们需要对从cookie中获取的字段值进行编码,最终输出utf-8编码的内容,即采用这段代码:
‘your getting str’.encode(‘latin-1’).decode(‘utf-8’)
这里需要注意一个点:cookie采用latin-1的编码模式,所以我们要用encode将cookie的字段内容按latin-1来解码,最后再utf-8编码成字符串。最终,这个脚本运行结果就正确了!如上面最后一张图所示,这个python文件正确读出了cookie的字段值。

我是科学财子,一个正在学习python的新人程序员,立志从事测试、游戏开发、大数据、AI方向!关注我,不定时为你分享python编程干货!每天进步一小点,每天成长一大步!