浏览器跨域问题
1、什么是浏览器的跨域
跨域是浏览器的同源策略,浏览器为了保证页面中发起的异步请求安全,所以做了跨域访问的限制。postman是没有的,说到底跨域是为了保证后端接口资源安全
只要当前页面执行js代码时需要访问另外一个服务器,浏览器会提前对该服务器的接口发起一个预检请求 判断服务器返回的结果响应报文头中是否包含允许当前页面所在的服务器跨域访问。 如果允许浏览器才会执行异步请求
只有post访问时才可以看到跨域的预检请求
同源:协议 域名+端口号 任意一个不同 都是跨域,所有的都相同才是同源
如果域名和端口都相同,但是请求路径不同,不属于跨域,如:
www.jd.com/item
www.jd.com/goods以下情况都属于跨域:
跨域原因说明 示例 域名不同 www.jd.com与www.taobao.com域名相同,端口不同 www.jd.com:8080与www.jd.com:8081二级域名不同 item.jd.com与miaosha.jd.com
2、怎么解决跨域问题?
CORS

CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
CORS需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE浏览器不能低于IE10。
CORS通信与AJAX没有任何差别,因此你不需要改变以前的业务逻辑。只不过,浏览器会在请求中携带一些头信息,我们需要以此判断是否允许其跨域,然后在响应头中加入一些信息即可。这一般通过过滤器完成即可
Spring已经帮我们写好了CORS的跨域过滤器,内部已经实现了判定逻辑。
springcloud-gateway集成的是webflux,所以这里使用的是CorsWebFilter,在gmall-gateway中编写一个配置类,并且注册CorsWebFilter:
@Configuration
public class CorsConfig {
@Bean
public CorsWebFilter corsWebFilter() {
// 初始化CORS配置对象
CorsConfiguration config = new CorsConfiguration();
// 允许的域,不要写*,否则cookie就无法使用了
config.addAllowedOrigin("http://manager.gmall.com");
config.addAllowedOrigin("http://www.gmall.com");
// 允许的请求头信息
config.addAllowedHeader("*");
// 允许的请求方式
config.addAllowedMethod("*");
// 是否允许携带Cookie信息
config.setAllowCredentials(true);
// 添加映射路径,我们拦截一切请求 /**代表所有请求
UrlBasedCorsConfigurationSource corsConfigurationSource = new UrlBasedCorsConfigurationSource();
corsConfigurationSource.registerCorsConfiguration("/**", config);
return new CorsWebFilter(corsConfigurationSource);
}
}3、CORS原理
预检请求
跨域请求会在正式通信之前,增加一次HTTP查询请求,称为"预检"请求(preflight)。
浏览器先询问服务器,当前网页所在的域名是否在服务器的许可名单之中,以及可以使用哪些HTTP动词和头信息字段。只有得到肯定答复,浏览器才会发出正式的XMLHttpRequest请求,否则就报错。
一个“预检”请求的样板:
OPTIONS /cors HTTP/1.1 Origin: http://localhost:1000 Access-Control-Request-Method: GET Access-Control-Request-Headers: X-Custom-Header User-Agent: Mozilla/5.0...
Origin:会指出当前请求属于哪个域(协议+域名+端口)。服务会根据这个值决定是否允许其跨域。
Access-Control-Request-Method:接下来会用到的请求方式,比如PUT
Access-Control-Request-Headers:会额外用到的头信息
预检请求的响应
服务的收到预检请求,如果许可跨域,会发出响应:
HTTP/1.1 200 OK Date: Mon, 01 Dec 2008 01:15:39 GMT Server: Apache/2.0.61 (Unix) Access-Control-Allow-Origin: http://miaosha.jd.com Access-Control-Allow-Credentials: true Access-Control-Allow-Methods: GET, POST, PUT Access-Control-Allow-Headers: X-Custom-Header Access-Control-Max-Age: 1728000 Content-Type: text/html; charset=utf-8 Content-Encoding: gzip Content-Length: 0 Keep-Alive: timeout=2, max=100 Connection: Keep-Alive Content-Type: text/plain如果服务器允许跨域,需要在返回的响应头中携带下面信息:
Access-Control-Allow-Origin:可接受的域,是一个具体域名或者*(代表任意域名)
Access-Control-Allow-Credentials:是否允许携带cookie,默认情况下,cors不会携带cookie,除非这个值是true
Access-Control-Allow-Methods:允许访问的方式
Access-Control-Allow-Headers:允许携带的头
Access-Control-Max-Age:本次许可的有效时长,单位是秒,过期之前的ajax请求就无需再次进行预检
有关cookie:
要想操作cookie,需要满足3个条件:
服务的响应头中需要携带Access-Control-Allow-Credentials并且为true。
浏览器发起ajax需要指定withCredentials 为true
响应头中的Access-Control-Allow-Origin一定不能为*,必须是指定的域名
阿里云oss图片上传
1、最佳方式实现图片上传
之前的项目上传文件方式,请求方式必须是post
- 前端将上传的文件提交给后端服务器
- 后端服务器将文件上传到阿里云oss
这种方式安全,阿里云oss参数配置在服务器中、保存文件参数后端服务器来生成,但是性能非常差,文件先提交给服务器在推送到阿里云oss
使用前端直传文件,性能非常高,但是不安全
性能非常高:用户直传,后端服务器不用处理文件的上传
不安全:oss的参数会配置到前端,容易丢失
最佳实践
oss参数保存在后端服务器
前端js上传文件之前先访问后端接口获取临时授权,临时授权会过期,不能伪造
js在临时授权过期前上传文件 可以成功
2、配置阿里云对象存储(OSS)
这真的是一条很漫长的路。。大概就是做下面这三件事
1、登录到个人阿里云控制台,创建bucket,
2、在权限管理下的跨域设置中配置允许跨域访问
3、创建子账户并分配oss操作的权限
服务端签名后直传

提供了浏览器直接上传到阿里云的参考文档:

3、后端oss参数获取接口
引入oss依赖:
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>3.5.0</version>
</dependency>核心代码
@Api(tags = "阿里云获取policy")
@RequestMapping("pms/oss")
@RestController
public class PmsOssController {
//注意:出错检查 子账户权限、地域节点地址、桶名、桶的跨域配置
String accessId = ""; // 请填写您的AccessKeyId。
String accessKey = ""; // 请填写您的AccessKeySecret。
String endpoint = ""; // 请填写您的 endpoint。如:oss-cn-beijing.aliyuncs.com
String bucket = ""; // 请填写您的 bucketname 。
String host = "https://" + bucket + "." + endpoint; // host的格式为 bucketname.endpoint
// callbackUrl为 上传回调服务器的URL,请将下面的IP和Port配置为您自己的真实信息。
//String callbackUrl = "http://88.88.88.88:8888";
// 图片目录,每天一个目录
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String dir = sdf.format(new Date()); // 用户上传文件时指定的前缀。
@GetMapping("policy")
public ResponseVo<Object> policy() throws UnsupportedEncodingException {
OSSClient client = new OSSClient(endpoint, accessId, accessKey);
long expireTime = 30;
//代表获取的授权的token的过期时间:默认30s
long expireEndTime = System.currentTimeMillis() + expireTime * 1000;
Date expiration = new Date(expireEndTime);
PolicyConditions policyConds = new PolicyConditions();
policyConds.addConditionItem(PolicyConditions.COND_CONTENT_LENGTH_RANGE, 0, 1048576000);
policyConds.addConditionItem(MatchMode.StartWith, PolicyConditions.COND_KEY, dir);
String postPolicy = client.generatePostPolicy(expiration, policyConds);
byte[] binaryData = postPolicy.getBytes("utf-8");
String encodedPolicy = BinaryUtil.toBase64String(binaryData);
//生成临时的授权签名
String postSignature = client.calculatePostSignature(postPolicy);
//响应的map
Map<String, String> respMap = new LinkedHashMap<String, String>();
respMap.put("accessid", accessId);
respMap.put("policy", encodedPolicy);
respMap.put("signature", postSignature);
respMap.put("dir", dir);
respMap.put("host", host);
respMap.put("expire", String.valueOf(expireEndTime / 1000));
// respMap.put("expire", formatISO8601Date(expiration));
return ResponseVo.ok(respMap);
}
}4、抽取阿里云账号参数(优化)
1.配置绑定类绑定配置文件中的参数
@Data
// ConfigurationProperties如果爆红 表示当前类没有被扫描到注入到容器中
//@Configuration
@ConfigurationProperties(prefix = "aliyun.oss")
public class OssProperties {
String accessId;//
String accessKey;//
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint;//
// 填写Bucket名称,例如examplebucket。
String bucket;// = "xa220328-gmall";
// 填写Host地址,格式为https://bucketname.endpoint。 我们在阿里云oss创建的桶 它会为我们分配一个子域名
String schema;// = "https://"+bucket+"."+endpoint;
}2.policy方法里面的内容不变,就是那5个参数不再是写死的了。。而是从配置文件中读取的
@RestController
@RequestMapping("/pms/oss")
@EnableConfigurationProperties(OssProperties.class)
public class OssController {
@Autowired
OssProperties ossProperties;
// 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户。
String accessId;
String accessKey;
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint;
// 填写Bucket名称,例如examplebucket。
String bucket;
// 填写Host地址,格式为https://bucketname.endpoint。 我们在阿里云oss创建的桶 它会为我们分配一个子域名
String host;
@PostConstruct //jdk提供的 在bean的构造器调用后立即执行的初始化方法
public void init(){
accessId = ossProperties.getAccessId();
accessKey = ossProperties.getAccessKey();
endpoint = ossProperties.getEndpoint();
bucket = ossProperties.getBucket();
host = ossProperties.getSchema()+bucket+"."+endpoint;
}
@GetMapping("policy")
public ResponseVo policy() throws UnsupportedEncodingException {
}
}搜索引擎(SEO)优化
1、客户端渲染
前后端分离的项目,一般浏览器访问前端项目得到页面(html+css+js,页面中不包含数据),浏览器解析页面时执行页面中的异步请求的js代码发起请求获取数据。通过js解析渲染到页面中展示,叫做客户端渲染
优点:页面渲染由客户端浏览器来完成,服务器效率高
缺点:搜索引擎(百度)爬虫爬取页面内容时没有数据,用户通过搜索引擎输入关键字不能匹配到我们的页面
搜索引擎的工作流程

2、服务端渲染
服务端渲染:客户端提交请求给后端,后端先查询数据在页面中解析数据渲染到页面中之后,再将有数据的页面响应给客户端。
如果一个网站希望爬虫爬取后,用户输入关键字能够匹配到我们的页面,我们应该使用服务端渲染的方式渲染页面
电商项目 首页 搜索页面 购物车页面 等等 每个页面都有复杂的业务 并发访问量也较大,但是我们希望SEO优化排名能够提升,可以使用每个页面一个服务 服务端渲染的方式来开发(thymeleaf
更容易理解的话
互联网早期,用户使用的浏览器浏览的都是一些没有复杂逻辑的、简单的页面,
这些页面都是在后端将 html 拼接好的,然后返回给前端完整的 html 文件,
浏览器拿到这个 html 文件之后就可以直接解析展示了,这也就是所谓的服务器端渲染。
而随着前端页面的复杂性提高,前端就不仅仅是普通的页面展示了,可能是添加更多功能的组件,复杂性更大,
另外,此时 ajax 的兴起,使得页面就开始崇拜前后端分离的开发模式,即后端不提供完整的 html 页面,
而是提供一些 api 使得前端可以获取 json 数据,然后前端拿到 json 数据之后再在前端进行 html 页面
的拼接,然后展示在浏览器上,这就是所谓的客户端渲染Mybatis分步查询
1、理清需求/实际使用场景
一级分类是在跳转到首页的时候就带过去了,渲染一级分类使用的是服务端渲染,一级分类数据存放在请求域
@GetMapping({"/","index","index.html"})
public String index(Model model){
List<CategoryEntity> categoryEntities = this.indexService.queryLvl1Categories();
model.addAttribute("categories", categoryEntities);
return "index";
}需求是这样的,在鼠标移动到一级分类上,一级分类所属的二级分类和三级分类就一起加载出来了,使用客户端渲染,ajax异步请求数据
/** *根据以及id查找2级和3级分类列表 * @param pid * @return */ @ResponseBody @GetMapping("index/cates/{pid}") public ResponseVo<List<CategoryEntity>> queryLvl2CategoriesWithSub(@PathVariable("pid")Long pid){ List<CategoryEntity> categoryEntities = this.indexService.queryLvl2CategoriesWithSub(pid); return ResponseVo.ok(categoryEntities); }

我们会使用远程服务调用,调用pms服务。。当然这不是重点,重点是如何在pms服务中做到根据
一级分类id查询到2/3级分类集合。
给CategoryEntity类加一个额外属性,要记得加exist=false
@Data @TableName("pms_category") public class CategoryEntity implements Serializable { //省略CategoryEntity 很多属性.... @TableField(exist = false) List<CategoryEntity> subs; }这些查询出来的3级分类就可以存储在二级分类的这个属性中了
2、使用MybatisPlus做分步查询
1.mapper接口
@Mapper
public interface CategoryMapper extends BaseMapper<CategoryEntity> {
/**
* 根据一级分类id查询二级三级
* @param pid
* @return
*/
List<CategoryEntity> queryCategoriesWithSub(@Param("pid") Long pid);
}2.mapper映射文件
使用了二级分类的id再次执行select="queryCategoriesWithSub" 查询三级分类的集合并设置给subs
<mapper namespace="com.atguigu.gmall.pms.mapper.CategoryMapper">
<resultMap id="CategoryMap" type="com.atguigu.gmall.pms.entity.CategoryEntity">
<collection property="subs" ofType="com.atguigu.gmall.pms.entity.CategoryEntity" column="id" select="queryCategoriesWithSub">
</collection>
</resultMap>
<select id="queryCategoriesWithSub" resultMap="CategoryMap">
select * From pms_category where parent_id =#{pid}
</select>
</mapper>分步查询更多请移步我的另外一篇文章: 2202-04-04 西安 mybatis(3)resultMap 和 动态sql_£小羽毛的博客-CSDN博客
记录项目中的一些问题
1.分页合理化害我啊
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
PaginationInnerInterceptor paginationInnerInterceptor = new PaginationInnerInterceptor();
//开启分页合理化: 如果查询页码<1 则查询第一页 或者页码大于总页码 查询最后一页
// paginationInnerInterceptor.setOverflow(true);
interceptor.addInnerInterceptor(paginationInnerInterceptor);
return interceptor;
}会出现的问题,让我在批量从mysql中导入数据到ES索引库中的时候报错
因为是使用while循环判断的,
Integer pageNum = 1; Integer pageSize =5; do{ PageParamVo pageParamVo = new PageParamVo(); pageParamVo.setPageNum(pageNum); pageParamVo.setPageSize(pageSize); ResponseVo<List<SpuEntity>> listResponseVo = pmsClient.querySpusListByPage(pageParamVo); //业务方法,批量导入数据到索引库.. pageSize = spuEntities.size(); pageNum++; } while (pageSize==5);正如我数据库中正好有5条记录,那么因为分页合理化的原因,不管我查询哪一页,结果都是5条。。所以while循环停不下来了
2、FieldType.Object数据扁平化
FieldType.Object : 会导致es数据出现数据扁平化问题
如果是Object: 采用级联属性和值的集合方式来存储,同一个级联属性的多个值会存到一个集合列表中
现象:交叉当做条件使用了
-----------------
怎么解决
嵌套对象:字段类型设置为nested,会变为一个个的隐藏文档来存储
Nested避免数据扁平化 (就是将集合中的对象每一个单独创建一个子文档来存储)
//spu和sku检索属性集合
@Field(type = FieldType.Nested) //以后查询嵌套属性时需要指定nested查询
List<SearchAttrValue> searchAttrValues;注意:使用Nested之后,以后查询嵌套属性时需要指定给的nestId查询
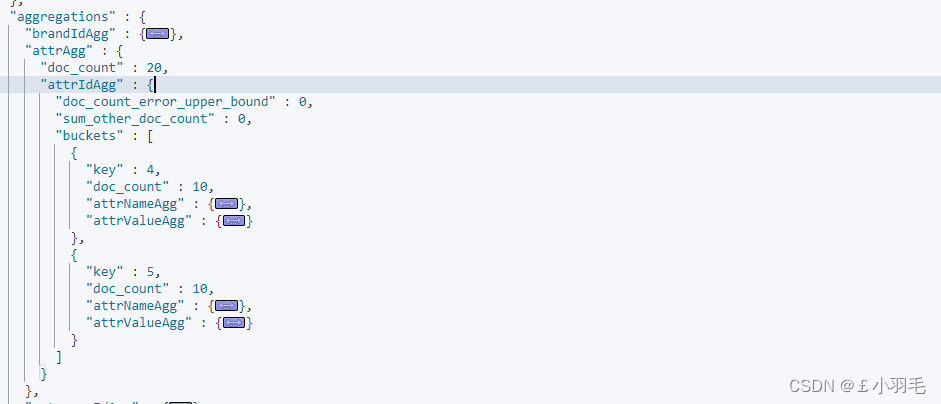
//6.3检索属性和值的聚合 builder.aggregation(AggregationBuilders.nested("attrAgg", "searchAttrs") .subAggregation(AggregationBuilders.terms("attrIdAgg").field("searchAttrs.attrId") .subAggregation(AggregationBuilders.terms("attrNameAgg").field("searchAttrs.attrName")) .subAggregation(AggregationBuilders.terms("attrValueAgg").field("searchAttrs.attrValue"))));对应在kibina中
点击展开其中一个
解析结果集
//解析聚合结果集,获取规格参数 ParsedNested attrAgg = (ParsedNested)response.getAggregations().asMap().get("attrAgg"); ParsedLongTerms attrIdAgg = (ParsedLongTerms)attrAgg.getAggregations().get("attrIdAgg"); List<? extends Terms.Bucket> attrIdAggBuckets = attrIdAgg.getBuckets(); if (!CollectionUtils.isEmpty(attrIdAggBuckets)) { List<SearchResponseAttrVo> filters = attrIdAggBuckets.stream().map(bucket -> { SearchResponseAttrVo responseAttrVo = new SearchResponseAttrVo(); // 规格参数id responseAttrVo.setAttrId(((Terms.Bucket) bucket).getKeyAsNumber().longValue()); // 规格参数的名称 ParsedStringTerms attrNameAgg = (ParsedStringTerms)((Terms.Bucket) bucket).getAggregations().get("attrNameAgg"); responseAttrVo.setAttrName(attrNameAgg.getBuckets().get(0).getKeyAsString()); // 规格参数值 ParsedStringTerms attrValueAgg = (ParsedStringTerms)((Terms.Bucket) bucket).getAggregations().get("attrValueAgg"); List<? extends Terms.Bucket> attrValueAggBuckets = attrValueAgg.getBuckets(); if (!CollectionUtils.isEmpty(attrValueAggBuckets)){ List<String> attrValues = attrValueAggBuckets.stream().map(Terms.Bucket::getKeyAsString).collect(Collectors.toList()); responseAttrVo.setAttrValues(attrValues); } return responseAttrVo; }).collect(Collectors.toList()); searchResponseVo.setFilters(filters); }