目录
题目
共80多个PDF,要统计这些PDF中含有财务术语词的数量和非财务术语词的数量,以及每个文件中含有上述两种词的数量。
起初觉得统计词频非常简单,但在用python将pdf转txt上花了很长时间。。。最后用格式工厂1min完成(格式工厂yyds);再一个花费时间比较久的是dataframe放入同一工作表的不同sheet且不覆盖,还好最后解决了
 80多份薪酬管理办法PDF
80多份薪酬管理办法PDF
 非财务指标和财务指标词,就是统计这些词语在上面80多份文件中的出现次数。
非财务指标和财务指标词,就是统计这些词语在上面80多份文件中的出现次数。
正文
合并多个txt
在用格式工厂将所有PDF都转成txt之后,先将80多个PDF合并
PDF转txt,格式工厂YYDS!!
# -*- coding:utf-8 -*-
import os
"""
合并多个txt
参考:https://blog.csdn.net/allan2222/article/details/90789197
"""
# 获取目标文件夹的路径
path = "E:/txt_files/1/"
# 获取当前文件夹中的文件名称列表
filenames = os.listdir(path)
result = "merge.txt"
# 打开当前目录下的result.txt文件,如果没有则创建
file = open(result, 'w+', encoding="utf-8")
# 向文件中写入字符
# 先遍历文件名
for filename in filenames:
filepath = path + '/'
filepath = filepath + filename
# 遍历单个文件,读取行数
for line in open(filepath, encoding="utf-8"):
file.writelines(line)
file.write('\n')
# 关闭文件
file.close()
对txt进行分词
import jieba
import numpy as np
jieba.load_userdict("E:/jupyter notebook/文本分析/1031/财务数据分析/dict.txt")
with open('merge.txt','r', encoding="utf-8") as f:
text = f.read()
words = jieba.lcut(text)
save_words = np.array(words)
np.save("words.npy", save_words)
# 可以不保存成.npy,直接用words也可以
剔除停用词
import numpy as np
words = np.load('words.npy')
words_list = words.tolist()
# 读取停用词表
with open('stopwords.txt','r') as f:
stop_words = f.read()
# 对每一句话剔除停用词
fliter_list = [w for w in words_list if not w in stop_words]
统计词频
import pandas as pd
word_list = [word for word in fliter_list]
df = pd.DataFrame(word_list,columns=["word"])
# 排序
result = df.groupby(["word"]).size().sort_values(ascending=False)
df_result = pd.DataFrame(result, columns = ['cnt'])
df_result.to_excel("过滤停用词之后.xlsx")
df_result.head(10)
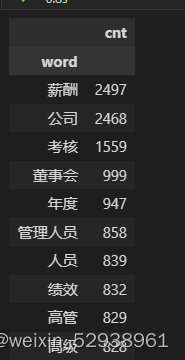 输出结果
输出结果
上面是词语设置成index了,看那个列名一高一低的,再转换下
import pandas as pd
df_word = pd.DataFrame({
'words':list(df_result.index), 'cnt':list(df_result.cnt)})
df_word
筛选出包含财务及非财务指标的所有词
with open('dict.txt','r',encoding='utf8') as f:
word_list = f.read().splitlines()
ind = '|'.join(word_list)
total = df_word[df_word['words'].str.contains(ind)]
筛选出非财务指标词
with open('non_financial.txt','r',encoding='utf8') as f:
word_list = f.read().splitlines()
ind = '|'.join(word_list)
non_financial = df_word[df_word['words'].str.contains(ind)]
non_financial.to_excel('non_financial.xlsx')
筛选出财务指标词
with open('financial.txt','r',encoding='utf8') as f:
word_list = f.read().splitlines()
ind = '|'.join(word_list)
financial = df_word[df_word['words'].str.contains(ind)]
financial.to_excel('financial.xlsx')
将dataframe放入同意工作表不同sheet且不覆盖的方法
参考:https://blog.csdn.net/xihen7/article/details/119540825
import pandas as pd
writer = pd.ExcelWriter('test.xlsx',mode='a', engine='openpyxl',if_sheet_exists='new')
financial.to_excel(writer, sheet_name='kyb')
writer.save()
writer.close()
将上面封装成一个函数,循环调用
import jieba
import numpy as np
import pandas as pd
# 事先创建好test.xlsx用来之后循环调用写入sheet
# 自己根据需求修改这个函数
def financial_word_frequency(txt_file, SheetName):
jieba.load_userdict("E:/jupyter notebook/文本分析/1031/财务数据分析/dict.txt")
with open('merge.txt','r', encoding="utf-8") as f:
text = f.read()
words = jieba.lcut(text)
# **********************去除停用词**************************
words_list = words
# 读取停用词表
with open('stopwords.txt','r') as f:
stop_words = f.read()
# 对每一句话剔除停用词
fliter_list = [w for w in words_list if not w in stop_words]
# *****************************统计词频*****************************
word_list = [word for word in fliter_list]
df = pd.DataFrame(word_list,columns=["word"])
# 排序
result = df.groupby(["word"]).size().sort_values(ascending=False)
# 得到所有切词结果
df_result = pd.DataFrame(result, columns = ['cnt'])
# *************************筛选出非财务指标***************
with open('non_financial.txt','r',encoding='utf8') as f:
word_list = f.read().splitlines()
ind1 = '|'.join(word_list)
non_financial = df_word[df_word['words'].str.contains(ind1)]
writer = pd.ExcelWriter('test.xlsx',mode='a', engine='openpyxl',if_sheet_exists='new')# 事先创建好的test.xlsx
non_financial_tag = '非财务_'
non_financial.to_excel(writer,sheet_name= str(SheetName)+non_financial_tag)
writer.save()
writer.close()
# *************************筛选出财务指标***************
with open('financial.txt','r',encoding='utf8') as f:
word_list = f.read().splitlines()
ind = '|'.join(word_list)
financial = df_word[df_word['words'].str.contains(ind)]
writer = pd.ExcelWriter('test.xlsx',mode='a', engine='openpyxl',if_sheet_exists='new')
financial_tag = '财务'
financial.to_excel(writer,sheet_name= str(SheetName)+financial_tag)
writer.save()
writer.close()
print("finish!!!!!")
调用上面的函数,写入80多个文件的结果
file_path_list = read_file('E:/txt_files/')[0]
file_name_list = read_file('E:/txt_files/')[1]
for i in range(len(file_name_list)):
financial_word_frequency(file_path_list[i], file_name_list[i][:10])

最终是这样的形式
另外还找了其他两个转换的代码
拓展
将word转换为txt
参考:https://zhuanlan.zhihu.com/p/353420233
import docx
def word_to_txt(filenamedocx, filenametxt):
#打开docx的文档并读入名为file的变量中
file = docx.Document(filenamedocx)
#输入docx中的段落数,以检查是否空文档
print('段落数:'+str(len(file.paragraphs)))
#将每个段落的内容都写进去txt里面
with open(filenametxt,'w') as f:
for para in file.paragraphs:
f.write(para.text)
print('操作已经完成!')
将pdf转换为docx
from pdf2docx import Converter
def pdf_to_docx(pdf_file,docx_file):
# convert pdf to docx
cv = Converter(pdf_file)
cv.convert(docx_file) # 默认参数start=0, end=None
cv.close()
将pdf转换为txt
import PyPDF2
# 打开 PDF 文件
with open('document.pdf', 'rb') as file:
# 创建 PDF 读取器对象
reader = PyPDF2.PdfReader(file)
# 获取 PDF 文件的页数
num_pages = len(reader.pages)
# 循环每一页
for i in range(num_pages):
# 读取每一页
page = reader.pages[i]
# 获取该页的文本
text = page.extract_text ()
# 将文本写入 txt 文件
with open('document.txt', 'a') as txt_file:
txt_file.write(text)
自己记录一下,有些比较小的东西以后也会用到。要是能养成记博客的习惯也蛮不错的!