输入:一个三维形状以及从各种视点捕获的同一类对象的大量照片。
目标:训练形状感知纹理生成器。
注:对照片没有具体要求,可以是从互联网上随机下载的照片。
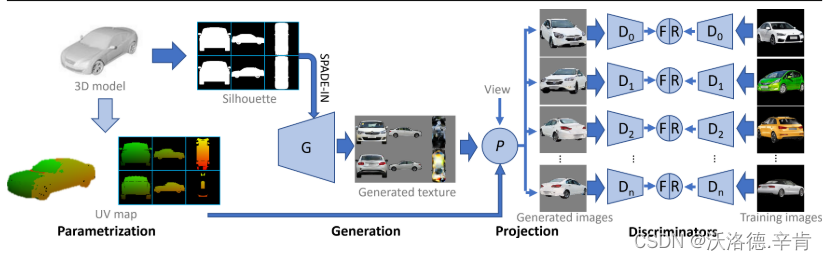
参数化(Texture Parameterization):将三维模型参数化为一个基于视图的纹理图谱,通过轮廓提供形状条件。
语义对齐:一个好的参数化应该遵循形状的语义,便于将语义纹理的生成与其在纹理中的位置联系起来。然而,全自动语义对齐是很难的。因此,选择使用基于视图的纹理投影参数化,作者定义了前、后、左、右、顶、底视点,并将投影坐标指定为顶点的纹理坐标。
鉴别器(Discriminator)的作用:每个鉴别器对照从相似视点观看的样例图像检查生成的纹理。如果所有的视图都通过了鉴别器,则认为纹理生成成功。
注:Xiao Li, Yue Dong, Pieter Peers, and Xin Tong. Synthesizing 3d shapes from silhouette image collections using multi-projection generative adversarial networks. In CVPR,pages 5535–5544, 2019.从轮廓图像获得粗略的视点估计,并基于视点类别将训练图像划分为不同类别。
如何保证chart间语义一致?
令每个视图包括来自多个chart的纹理(例如,在左视图和前视图之间),使得每个鉴别器可以同时向多个生成器提供梯度。
防止鉴别器记忆背景:将每张照片中的背景替换为纯色。
防止鉴别器记忆轮廓:给定照片中的轮廓,生成图像(用现有的GAN很容易训练 ),将其加入一起进行训练,从而将鉴别器训练的重点放在内容上,而不是轮廓上。
消除轮廓的大小和位置影响:在传递到鉴别器之前,应用一个随机比例和一个随机移位。