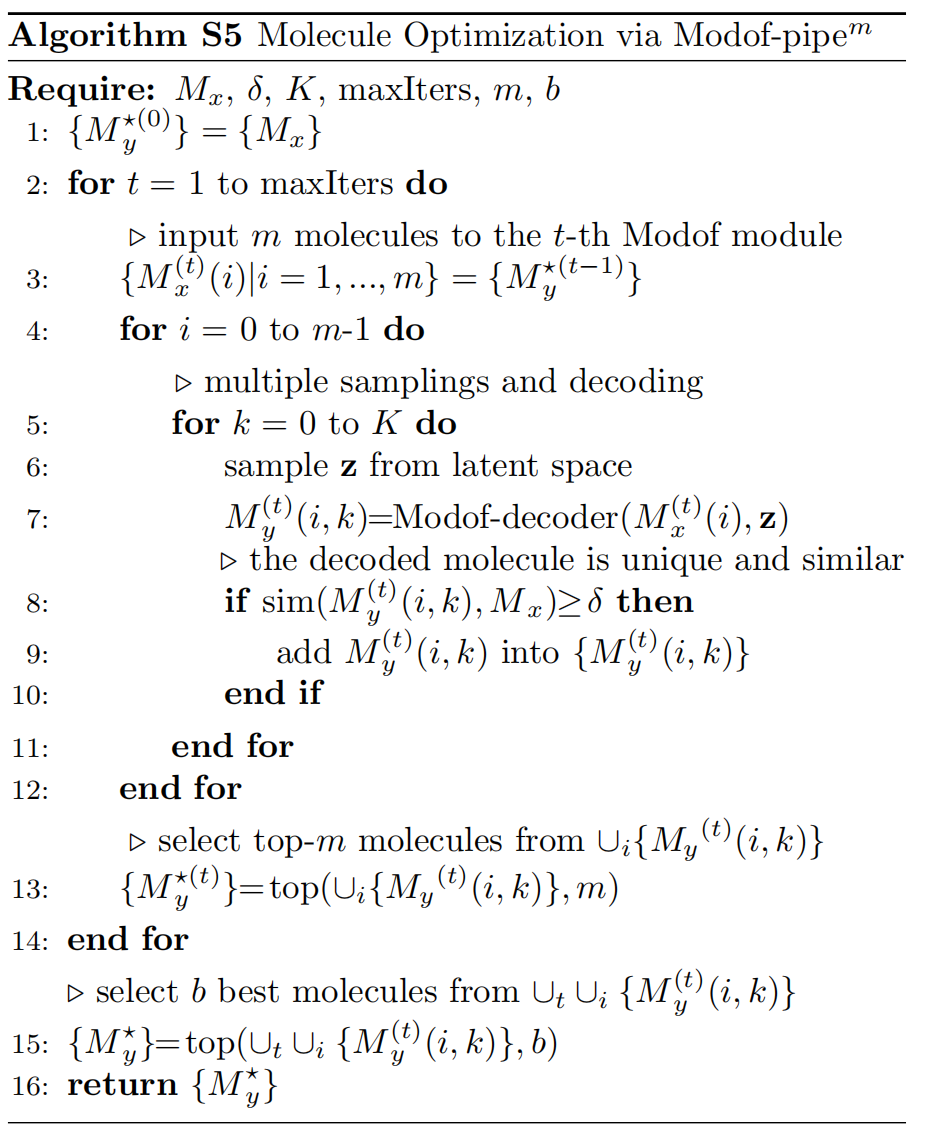Decoder整体流程:
- DSP预测在哪个节点应该断开,并预测在该断开位点 n d n_d nd 是否应该有一个child node 或者多个 child node
- n c n_c nc 再预测这些child node的类型 x c x_c xc
- 连接断开位点 n ∗ ( t ) n^{*}(t) n∗(t) 和这些 child node n c n_c nc【连接的键的选择、连接的时候中间的atom的选择】(关于怎么连接它们,则通过NFA-app-p以及NFA-app-c两种方法确定如何进行连接)
一、Molecule Representations and Notations
我们使用molecular graph G x \mathscr{G}_{x} Gx 以及 junction tree T x \mathscr{T}_{x} Tx 来表示一个分子 M x M_x Mx .
Molecular graph G x \mathscr{G}_{x} Gx 表示为 G x = ( A x , B x ) \mathscr{G}_{x} = (\mathscr{A}_{x}, \mathscr{B}_{x}) Gx=(Ax,Bx)
A x \mathscr{A}_{x} Ax是 M x M_x Mx 中的原子集合, B x \mathscr{B}_{x} Bx 是 M x M_x Mx 中的键的集合
在junction tree 表示 T x = ( V x , E x ) \mathscr{T}_{x}=\left(\mathscr{V}_{x}, \mathscr{E}_{x}\right) Tx=(Vx,Ex) 中, M x M_x Mx 中的所有的 环 和 键 被提取为 V x \mathscr{V}_{x} Vx中的结点
在 E x \mathscr{E}_{x} Ex 中,具有公共原子的节点用边连接,
因此,每一个结点 n ∈ V x n \in \mathscr{V}_{x} n∈Vx 是 G x \mathscr{G}_{x} Gx 中的一个子结构(例如环、连接着原子的键),
我们将节点 n n n 中包含的原子表示为 A x ( n ) \mathscr{A}_{x}(n) Ax(n) ,并将 T x \mathscr{T}_{x} Tx 中与 n n n 相连的节点表示为其邻居,表示为 N x ( n ) \mathcal{N}_{x}(n) Nx(n),因此每个边 ( n u , n v ) ∈ E x \left(n_{u}, n_{v}\right) \in \mathscr{E}_{x} (nu,nv)∈Ex 实际上符合 n u n_u nu 和 n v n_v nv 之间通用的原子 A x ( n u ) ∩ A x ( n v ) \mathscr{A}_{x}\left(n_{u}\right) \cap \mathscr{A}_{x}\left(n_{v}\right) Ax(nu)∩Ax(nv)
请注意:
原子(atom)和键(bonds)是用于molecular graph 表示的术语,
节点(nodes)和边(edges)用于junction tree 表示。
在本文中,所有的 embedding 向量默认为列向量,用小写粗体字母表示;
所有矩阵都用大写字母表示。关键符号如表3所示:

二、Molecular Difference Encoder (Modof-encoder)
Modof-encoder将成对的分子作为输入,然后把它们不同的地方encoder成向量 z x y z_{xy} zxy
Algorithm S1

给定两个分子 ( M x , M y ) \left(M_{x}, M_{y}\right) (Mx,My),
GMPN:Modof (Algorithm S1 in Section S14) 使用“message passing networks”学习到 M x M_{x} Mx , M y M_{y} My 的差异的Embedding 表示为graphs G x \mathscr{G}_{x} Gx and G y \mathscr{G}_{y} Gy,
TMPN:然后表示为 junction trees T x \mathscr{T}_{x} Tx and T y \mathscr{T}_{y} Ty
Step 1. Atom Embedding over Graphs (GMPN 图消息传递网络)
Modof 首先使用 Embedding 来表示原子,通过在分子 graphs 上沿键传播信息来捕获原子类型及其局部邻域结构;
Modof 使用 an one-hot encoding x i x_i xi 表示原子 a i a_i ai 的类型,
An one-hot encoding x i j x_{ij} xij 表示 a i a_i ai and a j a_j aj 的连接键的类型( b i j b_{ij} bij) .
其中,每一个键 b i j b_{ij} bij 与 m i j m_{ij} mij , m j i m_{ji} mji 的信息相关联( m i j m_{ij} mij 表示 a i a_i ai 到 a j a_j aj 的信息传播,反之亦然)。
m i j ( t ) m_{i j}^{(t)} mij(t) 表示 GMPN 的第t 次 iteration :
m i j ( t ) = ReLU ( W 1 a x i + W 2 a x i j + W 3 a ∑ a k ∈ N ( a i ) \ { a j } m k i ( t − 1 ) ) \mathbf{m}_{i j}^{(t)}=\operatorname{ReLU}\left(W_{1}^{a} \mathbf{x}_{i}+W_{2}^{a} \mathbf{x}_{i j}+W_{3}^{a} \sum_{a_{k} \in \mathcal{N}\left(a_{i}\right) \backslash\left\{a_{j}\right\}} \mathbf{m}_{k i}^{(t-1)}\right) mij(t)=ReLU W1axi+W2axij+W3aak∈N(ai)\{ aj}∑mki(t−1)
when t = = 1 t ==1 t==1:
m i j ( 1 ) = ReLU ( W 1 a x i + W 2 a x i j ) \mathbf{m}_{i j}^{(1)}=\operatorname{ReLU}\left(W_{1}^{a} \mathbf{x}_{i}+W_{2}^{a} \mathbf{x}_{i j}\right.) mij(1)=ReLU(W1axi+W2axij)
m k i ( 0 ) m_{k i}^{(0)} mki(0) 被初始化为0,
W i a ′ s ( i = 1 , 2 , 3 ) W_{i}^{a \prime} \mathrm{s}(i=1,2,3) Wia′s(i=1,2,3) 是可学习的参数矩阵
因此,message m i j ( t ) m_{ij}^{(t)} mij(t) encoder 了在graph中所有从 b i j b_{ij} bij 到 a j a_j aj 长度为 t 的路径
经过 t a t_a ta 次信息传递的迭代,原子embedding a j a_j aj 被如下规则更新:
a j = ReLU ( U 1 a x j + U 2 a ∑ a i ∈ N ( a j ) m i j ( 1 ⋯ t a ) ) \mathbf{a}_{j}=\operatorname{ReLU}\left(U_{1}^{a} \mathrm{x}_{j}+U_{2}^{a} \sum_{a_{i} \in \mathscr{N}\left(a_{j}\right)} \mathrm{m}_{i j}^{\left(1 \cdots t_{a}\right)}\right) aj=ReLU
U1axj+U2aai∈N(aj)∑mij(1⋯ta)
m i j ( 1 ⋯ t a ) \mathbf{m}_{i j}^{\left(1 \cdots t_{a}\right)} mij(1⋯ta) 是在所有iteration过程中的信息的连接和,
U 1 a U_{1}^{a} U1a , U 2 a U_{2}^{a} U2a 是可学习的参数矩阵
因此,原子embedding a j a_j aj 聚合了 a j a_j aj 的 t a t_a ta-hop的所有邻居的信息,是为了提升原子的embedding represtation 能力
Step 2. Node Embedding over Junction Trees (TMPN 树消息传递网络)
Modof将连接树中的节点encodes 为embedding,通过沿着树边缘传递消息来捕获它们的局部邻域结构。
为了更丰富的产生结点的表示,Modof首先将节点 n u n_u nu 中的原子信息聚合到嵌入的 s u s_u su 中,树边 e u v e_{uv} euv 共享的原子信息通过以下池化方式存入嵌入 s u v s_{uv} suv 中:
s u = ∑ a i ∈ A ( n u ) a i \mathbf{s}_{u}=\sum_{a_{i} \in \mathscr{A}\left(n_{u}\right)} \mathbf{a}_{i} su=ai∈A(nu)∑ai
s u v = ∑ a i ∈ A ( n u ) ∩ A ( n v ) a i \mathbf{s}_{u v}=\sum_{a_{i} \in \mathscr{A}\left(n_{u}\right) \cap \mathscr{A}\left(n_{v}\right)} \mathbf{a}_{i} suv=ai∈A(nu)∩A(nv)∑ai
Modof还使用了一个可学习的嵌入 x u x_u xu 来表示节点 n u n_u nu 的类型。因此,在TMPN的第t次迭代中,从节点 n u n_u nu 到 n v n_v nv 的 m u v t m_{uv}^t muvt 更新如下:
m u v ( t ) = ReLU ( W 1 n ReLU ( W 2 n [ x u ; s u ] ) + W 3 n s u v + W 4 n ∑ n w ∈ N ( n u ) \ { n v } m w u ( t − 1 ) ) \mathbf{m}_{u v}^{(t)}=\operatorname{ReLU}\left(W_{1}^{n} \operatorname{ReLU}\left(W_{2}^{n}\left[\mathbf{x}_{u} ; \mathbf{s}_{u}\right]\right)+W_{3}^{n} \mathbf{s}_{u v}+W_{4}^{n} \sum_{n_{w} \in \mathcal{N}\left(n_{u}\right) \backslash\left\{n_{v}\right\}} \mathbf{m}_{w u}^{(t-1)}\right) muv(t)=ReLU W1nReLU(W2n[xu;su])+W3nsuv+W4nnw∈N(nu)\{ nv}∑mwu(t−1)
其中 [ x u , s u ] [x_u,s_u] [xu,su] 是 x u x_u xu 和 s u s_u su 的信息融合,从而可以更好的表示节点信息;
W i n 1 s ( i = 1 , 2 , 3 , 4 ) W_{i}^{n_{1}} \mathrm{~s}(i=1,2,3,4) Win1 s(i=1,2,3,4) 是可学习的参数矩阵;
与 GMPN 相似, m u v ( t ) \mathbf{m}_{u v}^{(t)} muv(t) encoder了在树中所有从 e u v e_uv euv 到 n v n_v nv 长度为 t 的边。迭代完成后,节点的embedding n v n_v nv 被更新为:
n v = ReLU ( U 1 n ReLU ( U 2 n [ x v ; s v ] ) + U 3 n ∑ n u ∈ N ( n v ) m u v ( 1 ⋯ t n ) ) \mathbf{n}_{v}=\operatorname{ReLU}\left(U_{1}^{n} \operatorname{ReLU}\left(U_{2}^{n}\left[\mathbf{x}_{v} ; \mathbf{s}_{v}\right]\right)+U_{3}^{n} \sum_{n_{u} \in \mathscr{N}\left(n_{v}\right)} \mathbf{m}_{u v}^{\left(1 \cdots t_{n}\right)}\right) nv=ReLU
U1nReLU(U2n[xv;sv])+U3nnu∈N(nv)∑muv(1⋯tn)
U i n ’s ( i = 1 , 2 , 3 ) U_{i}^{n \text { 's }(i=1,2,3)} Uin ’s (i=1,2,3) 是可学习的参数矩阵
Step 3. Difference Embedding (DE)
M x M_x Mx 和 M y M_y My 的embedding的差异通过池化从 T x \mathscr{T}_{x} Tx 到 T y \mathscr{T}_{y} Ty 的节点:
h x y − = ∑ n x ∈ { V x ∣ V y } ∪ { n d ∈ V x } n x , \mathbf{h}_{x y}^{-}=\sum_{n_{x} \in\left\{\mathscr{V}_{x} \mid \mathscr{V}_{y}\right\} \cup\left\{n_{d} \in \mathscr{V}_{x}\right\}} \mathbf{n}_{x}, hxy−=nx∈{
Vx∣Vy}∪{
nd∈Vx}∑nx,
h x y + = ∑ n y ∈ { V y ∣ V x } ∪ { n d ∈ V y } n y , \mathbf{h}_{x y}^{+}=\sum_{n_{y} \in\left\{\mathscr{V}_{y} \mid \mathscr{V}_{x}\right\} \cup\left\{n_{d} \in \mathscr{V}_{y}\right\}} \mathbf{n}_{y}, hxy+=ny∈{
Vy∣Vx}∪{
nd∈Vy}∑ny,
n x / n y n_x / n_y nx/ny 只出现在 T x \mathscr{T}_{x} Tx / T y \mathscr{T}_{y} Ty 中并通过TMPN从中学习到的节点嵌入。
请注意,在上述方程中, n d n_d nd 是断开的位置,并且 T x \mathscr{T}_{x} Tx and T y \mathscr{T}_{y} Ty 都有共同的断开位点 n d n_d nd 。
因此, h x y − {h}_{x y}^{-} hxy− 本质上表示应该在 M x M_x Mx 中在断开位点 n d n_d nd 处移除的fragment,
h x y + {h}_{x y}^{+} hxy+ 本质上表示应该在断开位点 n d n_d nd 处添加到 M x M_x Mx 的fragment,是为了将 M x M_x Mx 修改为 M y M_y My
与VAE一样,通过计算全连接层 µ(·) 和 Σ(·) 的均值和对数方差,将两个差分嵌入的 h x y − {h}_{x y}^{-} hxy− 和 h x y + {h}_{x y}^{+} hxy+ 映射为两个正态分布。然后,从这两个分布中采样潜在向量 z x y − {z}_{x y}^{-} zxy− 和 z x y + {z}_{x y}^{+} zxy+ ,并将它们连接到一个潜在向量 z x y z_{xy} zxy 中,即:
z x y − ∼ N ( μ − ( h x y − ) , Σ − ( h x y − ) ) \mathbf{z}_{x y}^{-} \sim N\left(\mu^{-}\left(\mathbf{h}_{x y}^{-}\right), \Sigma^{-}\left(\mathbf{h}_{x y}^{-}\right)\right) zxy−∼N(μ−(hxy−),Σ−(hxy−))
z x y + ∼ N ( μ + ( h x y + ) , Σ + ( h x y + ) ) \mathbf{z}_{x y}^{+} \sim N\left(\mu^{+}\left(\mathbf{h}_{x y}^{+}\right), \Sigma^{+}\left(\mathbf{h}_{x y}^{+}\right)\right) zxy+∼N(μ+(hxy+),Σ+(hxy+))
z x y = [ z x y − ; z x y + ] \mathbf{z}_{x y}=\left[\mathbf{z}_{x y}^{-} ; \mathbf{z}_{x y}^{+}\right] zxy=[zxy−;zxy+]
Thus, z x y z_{xy} zxy encodes the difference between M x M_x Mx and M y M_y My
三、Algorithm S2 :Molecular Difference Decoder (Modof-decoder)
Modof-decoder 首先识别出在优化过程中应该被保留的scaffold,然后移除不在scaffold 中部分来得到中间表示
改变中间表示 M ∗ M∗ M∗为 M y M_y My:通过广度优先 Algorithm S3 有序的添加新的节点到 T ∗ T* T∗
Algorithm S4描述了Modof-pipe的优化

Modof 首先decoder差异的embedding z x y z_{xy} zxy (Eqn 4) 为可编辑的操作,从而可以改变 M x M_x Mx into M y M_y My.
Modof 首先预测在 T x \mathscr{T}_{x} Tx 中的断开位点 n d n_d nd ,
这个断开位点 n d n_d nd
将 T x \mathscr{T}_{x} Tx 拆为很多片段(fragments),fragments的数量取决于断开位点 n d n_d nd 周围的邻居结点的数量 N ( n d ) \mathcal{N}\left(n_{d}\right) N(nd)
Modof 然后预测哪一个fragments 将会被移除,然后将剩余的fragments与断开位点 n d n_d nd 合并为中间表示 M ∗ = ( G ∗ , T ∗ ) M *=\left(\mathscr{G} *, \mathscr{T}^{*}\right) M∗=(G∗,T∗)
之后,Modof从 n d n_d nd 开始依次将新的片段附加到 ( G ∗ , T ∗ ) (\mathscr{G} *, \mathscr{T}^{*}) (G∗,T∗),decoder总共有4步:
Step1. DSP 断开位点预测
输入 Mx的Tree表示、Mx和My的差异Embedding
输出 断开位点 n d n_d nd
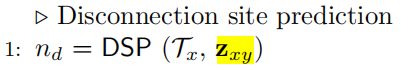
DSP是为了预测在 T x T_x Tx 中的每一个结点 n u n_u nu 断开的概率:
f d ( n u ) = ( w d ) ⊤ tanh ( W 1 d n u + W 2 d z ) , ∀ n u ∈ V x f_{d}\left(n_{u}\right)=\left(\mathbf{w}^{d}\right)^{\top} \tanh \left(W_{1}^{d} \mathbf{n}_{u}+W_{2}^{d} \mathbf{z}\right), \forall n_{u} \in \mathscr{V}_{x} fd(nu)=(wd)⊤tanh(W1dnu+W2dz),∀nu∈Vx,
其中 n u n_u nu 是在 T x \mathscr{T}_{x} Tx 中 n u n_u nu 的embedding, W d W_d Wd 和 W i d W_{i}^{d} Wid 分别是可学习的向量和矩阵,将断开评分最大的节点预测为断开点 n d n_d nd。直觉上讲,Modof 考虑了 n u n_u nu 的邻居或局部结构和“有多大可能”编辑操作(用z表示)可以应用于 n u n_u nu。为了学习到 f d f_d fd ,Modof 使用树 T x \mathscr{T}_{x} Tx 中ground-truth断开点的负对数似然作为损失函数。
Step 2. RFP 移除片段预测
输入 断开位点 n d n_d nd 周围的节点 n u n_u nu、Mx的差异Embedding
输出 待移除的节点 n r n_r nr
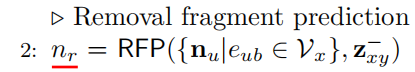
下一步,Modof 预测在 T x \mathscr{T}_{x} Tx 中的哪个 fragment应该被移除。对于连接在 n d n_d nd 的每个节点 n u n_u nu,Modof 进行预测的规则如下:
f r ( n u ) = σ ( ( w r ) ⊤ ReLU ( W 1 r n u + W 2 r z − ) ) , ∀ e u d ∈ E x f_{r}\left(n_{u}\right)=\sigma\left(\left(\mathbf{w}^{r}\right)^{\top} \operatorname{ReLU}\left(W_{1}^{r} \mathbf{n}_{u}+W_{2}^{r} \mathbf{z}^{-}\right)\right), \forall e_{u d} \in \mathscr{E}_{x} fr(nu)=σ((wr)⊤ReLU(W1rnu+W2rz−)),∀eud∈Ex
σ \sigma σ 是sigmode函数, W r W^r Wr 和 W i r 1 ′ s ( i = 1 , 2 ) W_{i}^{r_{1}^{\prime} \mathrm{s}}(i=1,2) Wir1′s(i=1,2) 分别是可学习的参数向量和参数矩阵;
预测得分 >0.5 则被判定为移除,因此,可以删除多个片段,也可以不删除。
直觉上讲,Modof 考虑了fragment的局部结构以及有多大可能性被移除(表示为 z − z^- z−),为了学习到 f r f_{r} fr ,Modof 最小化二进制交叉熵损失来最大化预测的得分。
Step 3. IMR 中间表示
输入 待移除的节点 n r n_r nr、 M x M_x Mx 是完整的图和树的表示
输出 M x M_x Mx 的scaffold M ∗ M^* M∗

在 fragment被移除后,Modof 合并剩余的 fragments 与断开位点 n d n_d nd 作为中间表示( M ∗ = ( G ∗ , T ∗ ) M^{*}=\left(\mathscr{G} *, \mathscr{T}^{*}\right) M∗=(G∗,T∗))
在fragment被移除后, M ∗ M^{*} M∗ 可能不是一个 valid 的分子(因为一些键被破坏了)。
M ∗ M^{*} M∗ 代表 M x M_x Mx 的 scaffold,在优化过程中应该保持不变。Modof首先移除一个fragment 以识别这样的支架,然后在支架上添加一个fragment 来修饰分子。
Step 4. NFA 新片段附着
输入 M x M_x Mx 的scaffold M ∗ M^* M∗、断开位点 n d n_d nd 、 M y M_y My 的差异性Embedding
输出 优化好的分子 M y M_y My
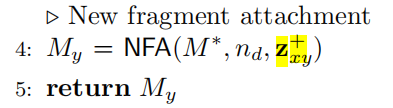
按照自动编码器的想法,Modof将差异嵌入 z x y z_{xy} zxy 解码为编辑操作,将 M x M_x Mx 更改为 M y M_y My (Algorithm S3 in Section S14). 具体来说,Modof首先预测 T x T_x Tx 中的一个节点 n d n_d nd 为断开位点。这个节点将把 T x T_x Tx 分割成几个片段,结果片段的数量取决于 n d n_d nd 的相邻节点 N ( n d ) N(n_d) N(nd) 的数量。然后,Modof预测要从 M x M_x Mx 中移除哪些片段,并将剩余的片段与 n d n_d nd 合并为一个中间表示的 M ∗ = ( G ∗ , T ∗ ) M^{*}=\left(G^{*}, T^{*}\right) M∗=(G∗,T∗) 。之后,Modof从 n d n_d nd 到 ( G ∗ , T ∗ ) (G^{*}, T^{*}) (G∗,T∗) 依次连接新的片段。
Modof 使用如下的四种预测来序列化的附着新的节点到 T ∗ T^{*} T∗ ,这种预测将会被迭代,在每个附着点 T ∗ T^{*} T∗ 中,开始于 n d n_d nd。
在第 t 次附着新的节点被表示为: n ∗ ( t ) ( n ∗ ( 0 ) = n d ) n^{*}(t)\left(n^{*(0)}=n_{d}\right) n∗(t)(n∗(0)=nd),其对应的分子图和树分别表示为: G ∗ ( t ) ( G ∗ ( 0 ) = G ∗ ) and T ∗ ( t ) ( T ∗ ( 0 ) = T ∗ ) \mathscr{G}^{*(t)}\left(\mathscr{G}^{*(0)}=\mathscr{G}^{*}\right) \text { and } \mathscr{T}^{*(t)}\left(\mathscr{T}^{*(0)}=\mathscr{T}^{*}\right) G∗(t)(G∗(0)=G∗) and T∗(t)(T∗(0)=T∗)
Algorithm S3: Modof New Fragment Attacher NFA
通过广度优先(一层一层的遍历,直至找到目标结点而深度优先是沿着一条路径不断往下,直至找到目标结点) Algorithm S3 有序的添加新的节点到 T ∗ T* T∗

Step 4.1. Child Connection Prediction (NFA-cp)
NFA-cp是为了预测是否应该在 n ∗ ( t ) n^{*(t)} n∗(t) 处附着新的节点,而不是预测scaffold上所有的节点是否应该附着新的节点
返回 n ∗ ( t ) n^{*(t)} n∗(t) 是否应该有一个新的子节点附加到它上面,并计算附着在该节点上的概率:
f c ( n ∗ ( t ) ) = σ ( ( w c ) ⊤ ReLU ( W 1 c n ∗ ( t ) + W 2 c z + ) ) f_{c}\left(n^{*(t)}\right)=\sigma\left(\left(\mathbf{w}^{c}\right)^{\top} \operatorname{ReLU}\left(W_{1}^{c} \mathbf{n}^{*(t)}+W_{2}^{c} \mathbf{z}^{+}\right)\right) fc(n∗(t))=σ((wc)⊤ReLU(W1cn∗(t)+W2cz+))
n ∗ ( t ) \mathbf{n}^{*(t)} n∗(t) 是 n ∗ ( t ) n^{*(t)} n∗(t) 的embedding( n ∗ ( t ) n^{*(t)} n∗(t) 是在 T ∗ ( t ) \mathscr{T}^{*(t)} T∗(t), G ∗ ( t ) \mathscr{G}^{*(t)} G∗(t)中学到的), z + z^+ z+ 表明了有多少 T ∗ ( t ) \mathscr{T}^{*(t)} T∗(t)应该被expanded,

Step 4.2. Child Node Type Prediction (NFA-ntp)
输入 n ∗ ( t ) n^{*(t)} n∗(t) :被附着新节点的位置、 M ∗ M^* M∗ 分子的scaffold、 z x y + z^+_{xy} zxy+ My的不同的片段的部分
返回 待添加的新子节点 n c n_c nc、 添加的子节点的类型 x c x_c xc

n ∗ ( t ) n^{*(t)} n∗(t) 的新子节点表示为 n c n_c nc 。Modof通过计算可以连接到 n ∗ ( t ) n^{*(t)} n∗(t) 上的所有类型的节点的概率来预测 n c n_c nc 的类型,如下所示:
f l ( n c ) = softmax ( U l × ReLU ( W 1 l n ∗ ( t ) + W 2 l z + ) ) f_{l}\left(n_{c}\right)=\operatorname{softmax}\left(U^{l} \times \operatorname{ReLU}\left(W_{1}^{l} \mathbf{n}^{*(t)}+W_{2}^{l} \mathbf{z}^{+}\right)\right) fl(nc)=softmax(Ul×ReLU(W1ln∗(t)+W2lz+))
Softmax() 将向量转为概率值, U 1 U^1 U1 and W i l W^l_i Wil 是可学习的矩阵,Modof为新的子节点 n c n_c nc 分配了对应于最高概率的子节点类型 x c x_c xc。
Modof 通过最小化交叉熵来最大化子节点的学习可能性 f l f_l fl 。
Step 4.3. Attachment Point Prediction (NFA-app)
输入 n ∗ ( t ) n^{*(t)} n∗(t) :被附着新节点的位置、 n c n_c nc:被附着的节点、 G ∗ G^* G∗:分子graph的scaffold、 z x y + z^+_{xy} zxy+ My的不同的片段的部分
返回: 对父节点 n ∗ ( t ) n^{*(t)} n∗(t)上的每个候选附着点进行评分,记为 a p ∗ a_p^* ap∗ 、对子节点 n c n_c nc 上的每个候选附着点进行评分,记为 a c ∗ a_c^* ac∗

如果节点 n ∗ ( t ) n^{*(t)} n∗(t) 被预测有一个子节点 n c n_c nc ,则下一步是连接 n ∗ ( t ) n^{*(t)} n∗(t) 和 n c n_c nc 。如果 n ∗ ( t ) n^{*(t)} n∗(t) 和 n c n_c nc 共享一个或多个原子(例如, n ∗ ( t ) n^{*(t)} n∗(t) 和 n c n_c nc 形成一个融合环,从而共享两个相邻的原子)可以根据化学规则明确地确定为附着点(s)),Modof将通过原子(s)连接 n ∗ ( t ) n^{*(t)} n∗(t) 和 n c n_c nc 。否则,如果 n ∗ ( t ) n^{*(t)} n∗(t) 和 n c n_c nc 有多个连接构型,则Modof分别预测 n ∗ ( t ) n^{*(t)} n∗(t) 和 n c n_c nc 处的附着原子。
Step 4.3.1. Attachment Point Prediction at Parent Node (NFA-app-p)
Modof对父节点 n ∗ ( t ) n^{*(t)} n∗(t)上的每个候选附着点进行评分,记为 a p ∗ a_p^* ap∗ ,如下:
g p ( a p ∗ ) = ( w p ) ⊤ tanh ( W 1 p a p ∗ + W 2 p x c + W 3 p × ReLU ( U 2 n [ x ∗ ( t ) ; s ~ ∗ ( t ) ] ) + W 4 p z + ) g_{p}\left(a_{p}^{*}\right)=\left(\mathbf{w}^{p}\right)^{\top} \tanh \left(W_{1}^{p} \mathbf{a}_{p}^{*}+W_{2}^{p} \mathbf{x}_{c}+W_{3}^{p} \times \operatorname{ReLU}\left(U_{2}^{n}\left[\mathbf{x}^{*(t)} ; \tilde{\mathbf{s}}^{*(t)}\right]\right)+W_{4}^{p} \mathbf{z}^{+}\right) gp(ap∗)=(wp)⊤tanh(W1pap∗+W2pxc+W3p×ReLU(U2n[x∗(t);s~∗(t)])+W4pz+)
Step 4.3.2. Attachment Point Prediction at Child Node (NFA-app-c)
Modof对子节点 n c n_c nc 上的每个候选附着点进行评分,记为 a c ∗ a_c^* ac∗ ,如下:
g c ( a c ∗ ) = ( w o ) ⊤ tanh ( W 1 o a c ∗ + W 2 o x c + W 3 o a p ∗ + W 4 o z + ) g_{c}\left(a_{c}^{*}\right)=\left(\mathbf{w}^{o}\right)^{\top} \tanh \left(W_{1}^{o} \mathbf{a}_{c}^{*}+W_{2}^{o} \mathbf{x}_{c}+W_{3}^{o} \mathbf{a}_{p}^{*}+W_{4}^{o} \mathbf{z}^{+}\right) gc(ac∗)=(wo)⊤tanh(W1oac∗+W2oxc+W3oap∗+W4oz+)
Algorithm S4: Molecule Optimization via Modof-pipe
给定一个分子 M x M_x Mx、相似性约束 δ \delta δ、最大的采样数目 K K K、允许的最大迭代次数,
在相似性约束 ( sim ( M x , M y ) ≥ δ ) \left(\operatorname{sim}\left(M_{x}, M_{y}\right) \geq \delta\right) (sim(Mx,My)≥δ)的前提下,Modof-pipe 迭代优化 M x M_x Mx 到 M y M_y My,其中 M y M_y My 有更好的性质: ( plog P ( M y ) > plog P ( M x ) ) \left(\operatorname{plog} \mathrm{P}\left(M_{y}\right)>\operatorname{plog} \mathrm{P}\left(M_{x}\right)\right) (plogP(My)>plogP(Mx))

Algorithm S5: Molecule Optimization via M o d o f − p i p e m Modof-pipe^m Modof−pipem
给定一个分子 M x M_x Mx、相似性约束 δ \delta δ、最大的采样数目 K K K、允许的最大迭代次数、每次迭代 m m m 的最大输入分子数、在 M o d o f − p i p e m Modof-pipe^m Modof−pipem的最大输出数。
在第 t 次的迭代中,在相似性约束下, M o d o f − p i p e m Modof-pipe^m Modof−pipem 优化每个输入的分子,表示为 M x ( t ) ( i ) M_{x}^{(t)}(i) Mx(t)(i),变成 K K K 个解码的分子,表示为 { M y ( t ) ( i , k ) ∣ k = 1 , ⋯ , K } \left\{M_{y}{ }^{(t)}(i, k) \mid k=1, \cdots, K\right\} {
My(t)(i,k)∣k=1,⋯,K},然后 M o d o f − p i p e m Modof-pipe^m Modof−pipem 在 { M y ( t ) ( i , k ) ∣ k = 1 , ⋯ , K } \left\{M_{y}{ }^{(t)}(i, k) \mid k=1, \cdots, K\right\} {
My(t)(i,k)∣k=1,⋯,K}选择不超过m个独一无二的最好的分子为了在下一个 t + 1 t+1 t+1 迭代中进一步优化。在所有的decoded分子中 ∪ i { M y ( t ) ( i , k ) ∣ k = 1 , ⋯ , K } \cup_{i}\left\{M_{y}{ }^{(t)}(i, k) \mid k=1, \cdots, K\right\} ∪i{
My(t)(i,k)∣k=1,⋯,K} 最好的 b b b 个分子将会是 M o d o f − p i p e m Modof-pipe^m Modof−pipem 的最终的输出。