本文由 52CV 粉丝投稿,作者:信息门下奶狗,知乎地址:https://zhuanlan.zhihu.com/p/535695807
我们提出Illumination-Adaptive-Transformer (IAT)网络,用来探索实时的暗光增强和曝光矫正,以及一系列不良光照场景下的视觉任务(如暗光场景目标检测/ 语义分割)。
IAT网络是全监督训练范式,网络总体的参数量仅需90k+,属于超轻量级的实时增强网络(相比近期CVPR 2022的Transformer工作Restormer[1]和MAXIM[2]等),在这篇论文中,我们借鉴了目标检测中的DETR[3] 结构,来帮助我们实现轻量设计。值得一提的是,IAT网络的训练/测试代码都已经公布,非常容易follow,并且暗光场景下语义分割和目标检测的代码也全部公布,可以说是良心满满。

图1. 有了IAT,愿少年你的科研道路不再黑暗
-
论文链接:https://arxiv.org/abs/2205.14871
扫描二维码关注公众号,回复: 14533738 查看本文章
-
项目链接:https://github.com/cuiziteng/Illumination-Adaptive-Transformer
demo视频:
,时长00:41
01
前言
自然场景下存在着各种不良光照场景,如低光照环境和摄影造成的过(欠)曝光环境,相机在不良光照下完成摄影任务时,因为接收到过多/过少的光子数量,和相机内部的处理过程 (如低光照场景需要调高ISO,这会导致噪声也同时放大)。往往得到的图像也会收到影响,无论从视觉感观还是完成一些视觉任务(如检测,分割等)都会受到影响。
区别于传统的HE或者RetiNex做法以及此前的CNN做法,我们提出了Illimination-Adaptive-Transformer (IAT), IAT模型借鉴了目标检测网络DETR思路,通过动态query学习的机制来调整计算摄影中的一些相关参数,建立了一个end-to-end的Transformer,来克服这些不良光照所造成的视觉感观/视觉任务影响。
02
网络结构
在不良光照场景 的环境中 , 场景 中的光子数量投到相机camera lens上,再通过相机内部的处理和相机内Image Signal Processor (ISP) 流程 G ,最终得到我们所获得的sRGB图像 。图像增强以及曝光纠正的目的是把非正常光照下摄影得到的图像 ,去学习一个正常光照条件 下摄影得到的图像 ,此前的方法往往通过一个end-to-end的网络,或者通过学习一些高层次的表征(如:图像曲线,光照,3D-LUT等),来完成

到 的学习。
这里我们借鉴了此前CVPR 2020上 Afif 和 Brown的工作 [4],通过一个逆映射函数 F , 将sRGB图像

映射到其对应的raw-RGB空间 上,这样做的好处是还原到raw-RGB空间上面后,我们可以通过调整ISP过程 G 中的一些关键参数(如gamma数值, 白平衡和一些相关色彩矩阵)来动态调整图像亮度,让最终的预测图像 尽量接近正常光照环境下的摄影图像 ,公式如下:

为了实现轻量化设计,在这里ISP环节中 G 过程,我们简化为一个3X3的色彩矩阵

和一个gamma参数,详细的推导论证请见我们论文的supp环节,在逆映射过程 F 中,我们学习了一张乘法图 M 和加法图 A ,以一个最小二乘法来完成拟合,总体公式如下:

综上所述,IAT网络总体包含两个独立分支,逆映射调整的local分支F和学习ISP参数的global分支G,local分支由两个独立支路负责预测像素级别乘法图M和加法图A,global分支则是利用attention预测控制图像全局信息的色彩矩阵和gamma数值。输入图像将分别通过local分支和global分支来一起完成暗光增强和曝光纠正任务。网络具体结构如下图,其中每个local分支都由三个PEM (Pixel-wise Enhancement Module) 模块组成,为了保证轻量设计和输入任意分辨率,这里采用了depth-wise convolution组成的Transformer结构。
同时在global分支我们采用attention模块来获得全局信息来产生色彩矩阵以及gamma数值,受到了目标检测DETR网络的启发,我们将随机初始化的query输入到模块中,与图像自身生成的key和value共同作用,最终输出十个参数,分别代表3x3的色彩矩阵和1维的gamma数值,通过这样的动态query学习策略,随着epoch的更新,网络可以自适应的调整操控图像全局信息的色彩矩阵以及gamma值,同时可以更好的利用transformer擅长捕捉全局信息的特性。
我们设计的色彩矩阵与gamma数值都是针对每张图像进行调整,相当于给每张图像都假定一个专属的特定gamma数值与色彩矩阵来完成增强任务,曝光矫正任务以及后续的高层次视觉任务。
图2. IAT网络结构
图3. (a). Local分支中的PEM模块与, (b). local分支的的attention模块
03
实验结果
(低光照增强/曝光纠正)
在实验部分,我们做了大量的实验,包括低光照增强/ 曝光纠正,以及低光照场景下的目标检测,低光照场景下的语义分割,以及复杂光照场景下的目标检测。
(a). 低光照增强实验结果(LOL-V1数据集低光照增强, 485 image training, 15 image testing和LOL-V2-real数据集低光照增强, 589 image training, 100 image testing)。

图4. LOL数据集测试结果
网络训练时采用L1损失函数,可以看出IAT在暗光增强上面的性能达到SOTA,并且参数量,FLOPS和速度相比之前算法都非常少,时效性很好,一些视觉效果如下:

图5. LOL-V1数据集结果
(b). 曝光纠正实验结果 [同时欠曝光/ 过曝光](Exposure数据集曝光纠正):

图6. 曝光增强数据集结果
04
实验结果
(低光照检测/分割)
在低光照检测/分割任务上,我们首先探究了将图像增强直接作用到暗光图像上,然后将增强后的图像输入到检测/分割网络结构中,我们分别采用了低光照检测数据集EXDark和低光照分割数据集ACDC以及多光源场景检测数据集TYOL。
我们以YOLO-V3检测器为范例,在目标检测时采用COCO预训练模型上面训练不同增强算法增强后的EXDark和TYOL,在语义分割时采用City-scape预训练模型训练不同增强算法增强后的ACDC,结果如下:

图7. 在暗光场景(d),(e)和多光源场景(f)数据集下的定量结果
可以看出低光照增强方法对于目标检测任务有些许提升,但是在后续的语义分割任务(e)上,增强算法反而无法提升目标的分割性能,这是由于图像增强算法与高层视觉算法的目的与评价指标不一致所导致的,图像增强是为了更好提升人眼视觉(评价指标PSNR,SSIM),而目标检测和语义分割属于机器视觉(评价指标mIOU, mAP)。
针对于这种情况,我们采用了joint-training范式来训练网络,即将图像增强网络和后续检测分割网络联合,一起更新参数,其中图像增强网络还可以加载不同的预训练模型(如LOL数据集预训练和MIT-5K数据集预训练),图示如下:
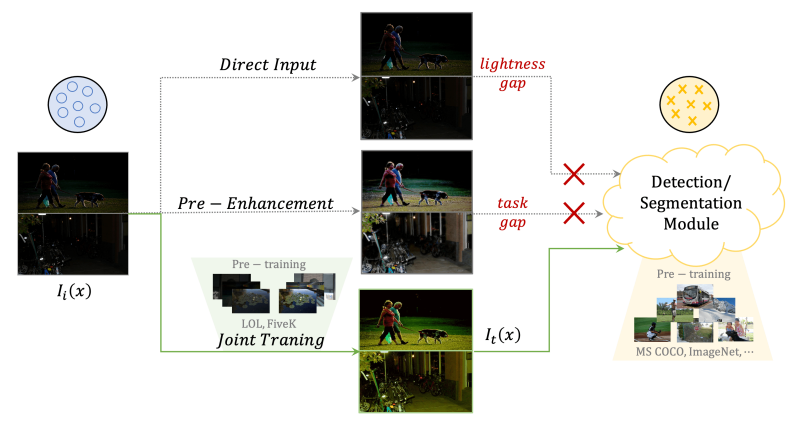
图8. 将图像增强网络和后续的检测分割网络Joint-Training.
通过实验结果发现,Joint-training范式可以有效提升低光照场景下的检测/分割结果,引入了Joint-training和直接增强的方法对比如下,可以看到Joint-training更能有效提升性能:

图9. Joint-Traing与直接增强的对比
关于更多实验细节和对比实验欢迎大家阅读我们的论文和代码,感谢~
参考文献
[1]. Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. arXiv preprint arXiv:2111.09881, 2021.
[2]. Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, and Yinxiao Li. Maxim: Multi-axis mlp for image processing. CVPR, 2022.
[3]. Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European conference on computer vision, 2020.
[4]. Mahmoud Afifi and Michael S. Brown. Deep white-balance editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.