自回归线性混合模型:网络过程的瞬时混合的时间序列模型
0 作者
Addison W. Bohannon, Member , IEEE,
V ernon J. Lawhern, Member , IEEE,
Nicholas R. Waytowich, Member , IEEE,
Radu V . Balan, Senior Member , IEEE
AWB, VJL和NRW是陆军研究实验室的成员,位于Aberdeen Proving Ground, MD 21005,电子邮件:addison.w.bohannon.civ@mail. mil, [email protected], [email protected]
RVB是马里兰大学数学系和科学计算与数学建模中心的成员,位于College Park, MD 20742,电子邮件:[email protected]。
RVB的工作得到了美国国家科学基金会DMS-1816608号拨款的部分支持。
本文有作者提供的补充下载材料,可在http:// ieeexplore.ieee.org。该材料包括所用算法的额外细节和手稿中未包括的结果。该材料的大小为6MB。
1 摘要
向量自回归模型,为多元时间序列数据提供了一个简单的生成模型。向量自回归模型的自回归系数描述了一个网络过程。然而,在实际应用中,如宏观经济学或神经影像学,时间序列数据不是来自孤立的网络过程,而是来自多个网络过程的同时发生。标准的矢量自回归模型不能提供关于这种时间序列数据的基本结构的洞察力。在这项工作中,我们提出了自回归线性混合(ALM)模型。ALM提出将时间序列数据分解为共同发生的网络过程,我们称之为自回归成分。我们还提出了一个用于拟合ALM模型的非凸似然估计器,并表明它可以用近似交替线性化最小化(PALM)算法来解决。我们在合成和真实世界的脑电图数据上验证了ALM,表明我们可以区分与任务有关的自回归成分,这些成分与不同的网络过程相对应。
向量自回归模型为多元时间序列数据提供了一种简单的生成模型。向量自回归模型的自回归系数描述了一个网络过程。然而,在实际应用中,如宏观经济学或神经成像,时间序列数据不是来自孤立的网络过程,而是来自多个网络过程的同时发生。标准向量自回归模型无法提供关于此类时间序列数据基础结构的见解。
在这项工作中,我们提出了自回归线性混合(ALM)模型。ALM提出将时间序列数据分解为共现网络过程,我们称之为自回归分量。我们还提出了一种用于拟合ALM模型的基于非凸似然的估计量,并表明它可以使用最近交替线性化最小化(PALM)算法求解。我们在合成和实际脑电图数据上验证了ALM,表明我们可以消除与不同网络过程对应的任务相关的自回归成分的歧义。
索引关键词(index keywards)
时间序列分析、自回归过程、混合模型、无监督学习、脑电图
2 引言
矢量自回归模型描述了多变量时间序列,在多个时间尺度上变量之间具有线性交互作用。
设(x[t])t∈Z是一个由p阶自回归过程产生的d维矢量值时间序列[1]。
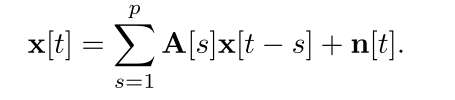
这里,(A[s])s=1,…,p与A[s]∈Rd×d的所有s=1,…,p是自回归系数,(n[t])t∈Z是dd维的噪声过程。p是自回归系数,(n[t])t∈Z是dd维噪声过程,其中n[t]∼iid N (0, Σ)为一些Σ ? 0∈Rd×d。自回归系数指定了各变量之间的相互作用。例如,A[s]的i,j项捕获了x[t-s]的j项对x[t]的i项的影响。这些值可能是相关的、反相关的或不相关的,取决于Ai,j[s]是正的、负的还是零。这样,(1)为自然数据提供了一个简单而强大的生成模型。因此,来自网络神经科学和计量经济学的从业人员通常使用向量自回归模型及其变体来分析数据和预测未来结果。
矢量自回归模型的自回归系数描述了一个单一的网络过程,即变量之间在时间上的结构关系。然而,在许多现实世界的应用中,时间序列数据来自于对复杂自然现象的观察,如宏观经济数据[2]和神经成像[3]-[5],我们可能会问:我们相信我们观察的是一个孤立的网络过程吗?如果不是,我们如何解释其他网络过程的同时发生?利用上面的例子,也许xi[t-s]与xj[t]对某一网络过程是正相关的,而与另一网络过程是负相关的。如果这些网络过程同时发生,那么我们将观察到变量之间没有相关性。如果我们只对预测感兴趣,这种微妙的情况可能并不重要,但如果我们想深入了解这个过程,这应该是令人关注的。在这项工作中,我们提出了一个网络过程同时发生的模型:自回归线性混合物(ALM)模型。ALM模型将自回归系数分解为r个典型的自回归成分,即A[s] = Pr j=1 cjDj[s] for s = 1, . . . ,p,cj∈R,Dj[s]∈Rd×d,所有j=1,. . . , r和s = 1, . . . ,p,因此,ALM模型由递归关系来定义
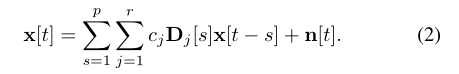
我们将把阶数为p、分量数为r的ALM模型表示为ALM(p,r)。自回归成分n (Dj[s])s=1,…,p : j = 1, … . r代表不同的网络过程,混合系数c = (cj)j=1,…,r表明这些网络过程如何共同发生以带来观察到的活动。
在手稿的其余部分,我们回顾了相关的时间序列和混合模型。我们提出了ALM模型的非凸似然估计器,并建议使用近似交替线性化最小化(PALM)算法[6]来推导估计。我们在模拟数据上描述了PALM算法的性能。
使用PALM算法,我们将ALM模型与来自ISRUC-睡眠数据集(可从sleeptight.isr.uc.pt/ISRUC Sleep/)[7]的脑电图(EEG)记录相适应。我们表明,恢复的自回归成分对应于用于睡眠阶段分类的已知网络过程。我们提供了一个用于拟合ALM模型的软件包,可在github.com/addisonbohannon/alm上找到,并在第四和第五节中实现了所有实验。
3 背景
3.1 相关工作
在时间序列分析中,特别是在计量经济学中,研究人员先前已经开发了自回归过程的混合模型。这些研究人员对时间序列数据的生成模型感兴趣,这些数据的特点是瞬时行为,如突发和周期。第一个混合自回归模型归功于Le、Martin和Rafferty开发的高斯混合过渡分布(GMTD)[8]。
Wong和Li在开发混合自回归(MAR)模型时对GMTD进行了概括[9]。MAR将实现中的每个观测值建模为自回归过程的高斯混合物。Fong等人[10];Bec, Rahbek和Shephard[11];Duekker等人[12];以及Kalliovirta, Meitz和Saikkonen[13]提出了MAR的各种多变量扩展。Fong, 等人提出了混合向量自回归(MV AR)模型,它最直接地概括了MAR。我们正是用这个模型来进行比较。让(x[t])t∈Z是一个随机的d维向量值的时间序列,Ft是到时间t为止的观察所产生的σ代数,{x[s]:s≤t}。同时,让(z[t])t∈Z为iid r维分类随机变量的随机时间序列,参数(cj)j=1,…,r。那么,有r个分量的MV AR由以下公式给出
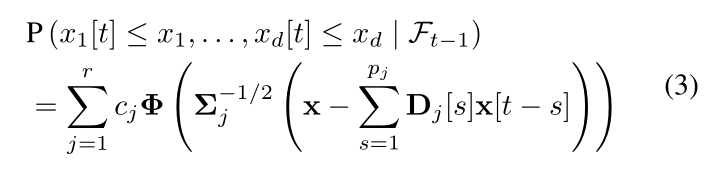
对于任何x = (xi)i=1,…,d∈Rd,其中Φ(x)=Qd i=1 Φ(xi),Φ是单变量正态分布的累积分布函数,Σj ? 0是j分量的协方差,pj是j分量的模型顺序,(Dj[s])s=1,…,pj是j分量的自回归系数。
为了估计MAR模型的参数,Wong和Li提出了一种期望最大化(EM)算法[14]。Fong等人对MV AR模型进行了效仿[10]。在该算法的期望步骤中,计算了(z[t])t∈Z的条件期望。然后,在最大化步骤中,j=1, …, r的(cj)j和(Dj[s])s=1, …, pj的估计值在j=1, . . . r的估计值是使用(z[t])t∈Z的条件期望值更新的。如果(Σj)j=1,…,r被当作一个未知参数,那么这个估计值在最大化步骤中也会被更新。
在信号和图像处理方面,研究人员已经为一类被称为字典学习和非负矩阵分解的双线性模型找到了许多成功的应用。字典学习,或称稀疏编码,源于对自然图像进行编码的实验工作[15], [16]。在字典学习中,我们给定实现(xi)i=1,…,n,我们想找到一个字典,其中的信号是适当的稀疏的,即
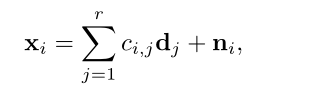
其中 ci = (ci,j)j=1,…,r 是 i 实现的字典系数, (dj)j=1,…,r 是字典原子, (ni)i=1,…,n 是随机噪声[17]. 在这个模型中,稀疏性意味着所有i=1, … …, n的kcik0 ? r。非负矩阵分解采用字典学习的生成模型(4),但系数ci不再需要是稀疏的,相反,系数和基向量(dj)j=1,…,r被限制在正态中[18]。
在高斯噪声模型下,(4)的最大似然估计(MLE)由以下公式给出
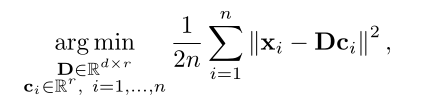
其中D=[d1|··|dr]。方程(5)是非凸的,很难全局求解。此外,参数是不可识别的,因为对于任何n D,(ci)i=1,…,n o,其最小化(5),n DU也一样?U−1ci?i=1,…,n o,对于任何U∈ Rr×r可逆。对(5)的许多扩展和相关算法已被提出用于其解决方案。一些著名的算法包括最优方向法[19]、FOCUSS[20]、k-SVD[17]、特征符号搜索算法[21]、ER SpUD[22]和平方和[23]。非负矩阵分解在词典学习中有着广泛而独立的文献,因为它主要是并行发展的。Berry等人对非负矩阵分解算法进行了很好的回顾[24]。
其他以分解为特征的生成性信号模型包括主成分分析(PCA)和独立成分分析(ICA)。这些模型将信号线性分解为(4)中的成分。与字典学习相比,PCA寻找正交成分,最大限度地说明数据的方差[25],而字典学习特别允许非正交成分(原子)。ICA则是寻找来源(系数)在统计上独立的成分[26],而字典学习则是寻找系数中的稀疏性。ALM的自回归结构将其与字典学习、PCA和ICA模型区分开来,在这些模型中,实现是由未观察到的源的线性组合瞬间(或因果)产生的。在ALM中,一个实现来自其自身历史的瞬时线性组合,通过不同的自回归系数进行过滤
3.1 注释
我们用黑体小写字母表示向量,用黑体大写字母表示矩阵。实矩阵A的转置表示为AT,复矩阵A的复共轭表示为A∗。