1.IDEFO需求建模方法
IDEFO是活动模型的缩写,来源于结构化分析与设计技术的一套标准,这些标准包含多种层次的图形语言,其中IDEFO用来描述对于企业具有重要性的各个过程(活动)。它以图形表示完成一项活动所需要的具体步骤、操作、数据要素以及各项具体活动之间的联系方式。
输入(Input):实行或完成特定活动所需的资源,置于框图的左侧。
输出(Output):经由活动处理或修正后的产出,置于框图的右侧。
控制(Control):活动所需的条件限制,置于框图的上方。
机制(Mechanisms):完成活动所需的工具,包括人员、设施及装备,置于框图的下方。
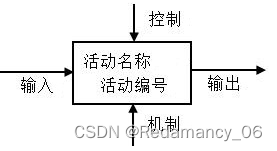
描述功能活动示意图中矩形框代表功能活动,写在矩形框内的动词短语描述功能活动的名称,活动的编号按照要求写在矩形框右下角指定的位置。
左边的输入箭头表示完成活动需要的数据;矩形框上方的控制箭头描述了影响这个活动执行的事件或约束条件;右边的输出箭头说明由活动产生的结果及信息,下方进入的机制箭头表示实施该活动的物理手段或完成活动需要的资源(计算机系统、人或组织)。
2.解释实体、实体型、实体集的区别
2.1实体
实体就是具体的个体,不同的实体是不同的,只能代表他自己一种。(官方解释即:客观存在并可相互区别的事物)
举个例子:阿拉斯加、萨摩耶、哈士奇、柯基、中华田园犬、边牧、德牧、罗威纳、拉布拉多、史宾格、田园猫、暹罗、英短、加菲猫、波斯猫。这些都可以称之为实体。大家注意我所列举的上述都是一个非常具体的东西
2.2实体型
用实体名及其属性名集合来抽象和刻画同类实体,称为实体型。(不理解没关系,往下看例子)
举个例子:
阿拉斯加、萨摩耶、哈士奇前面三种狗我们把它统称为狗。狗有什么属性(特征)呢,狗有品种、长度、重量等属性(随便举的哈,当然描述狗的特征的都可以称之为属性)那么狗这个统称和这些属性名的组合,我们将这个组合称为实体型即:狗(品种,长度,重量)就是个实体型,我们可以把实体型当成是一个模型或是一个框架;再比方说学生(学号,姓名,性别,班级)也是实体型,汽车(品牌、价格、产地)也是实体型。他是对一类事物及其属性的概括注意哦,一个实体型,它用的是类别的统称,你看我用的是狗、汽车、学生而不是用的萨摩耶,奥迪,小胖(小胖是个学生)这些具体的名称,属性也是抽象的,我没有说狗具体的什么品种,多长,多重。
总结:所谓实体型即:类别统称+属性。形式上就是:类别统称(属性1,属性二,属性三…)。
2.3实体集
所谓实体集就是同一类型实体的集合(一般是有限的)。注意!是同—类型实体的集合哦。实体集中包含的是实体,可以把它理解成数学中的集合,还是以上面的例子为例:{英短、加菲猫、波斯猫}这就是一个实体集。再比如(阿拉斯加、萨摩耶、哈士奇}这也是一个实体集,这两个实体集里分别只包含了三个实体。
注意:我们不能把{阿拉斯加、萨摩耶、哈士奇、加菲猫、波斯猫}归为一个集合,因为他们不是一个类别
2.4实体型与实体集的区别总结:
实体型是一个类别的统称加其属性,就是描述—类事物的一个模型,是对一个事物及其属性抽象的表征,一般用于描述E-R图;实体集是有限的,是对具体事物的描述,对于一个实体集,只包含一定数量的实体,比如(阿拉斯加、萨摩耶、哈士奇}这个实体集只包含这三个实体
3.完全函数依赖、部分函数依赖、传递函数、平凡函数依赖、非平凡函数依赖举例
3.1非平凡函数依赖
3.1.1定义:
若X->Y,但Y不是X的子集,就是非平凡函数依赖。
3.1.2例如:
在学生表(学号,姓名,年级)中通过(学号,姓名)可以推出这个学生所在的年级,但年级不是(学号,姓名)的子集,这是非平凡函数依赖((学号,姓名)就是一个X,年级就是一个Y)。
3.2平凡函数依赖
3.2.1定义:
若X->Y,且Y是X的子集(对任一关系模式,平凡函数依赖必然成立),就是平凡函数依赖。
3.2.2例如:
在学生表(学号,姓名,年级)中.(学号,姓名)可以推出学号和姓名其中的任何一个;这就是平凡函数依赖.直白点说,就是只要Y是X的子集,Y就依赖于X。
3.3完全函数依赖:
3.3.1定义:
若X->Y,并且对于X的任何一个真子集X’,都有Y不函数依赖于X’,则称Y对X完全函数依赖。
3.3.2例如:
通过(学生学号,选修课程名}可以得到该生本门选修课程的成绩},而通过单独的{学生学号}或者单独的{选修课程名}都无法得到该成绩,则说明{该生本门选修课程的成绩}完全依赖于{学生学号,选修课程名}
3.4部分函数依赖
3.4.1定义:
若X->Y,但Y不完全函数依赖于X,则称Y对X部分函数依赖。
3.4.2例如:
通过{(学生学号,课程号}可以得到{该生姓名},而通过单独的{(学生学号}已经能够得到该生姓名},则说明(该生姓名}部分依赖于{(学生学号,课程号};又比如,通过(学生学号,课程号}可以得到[课程名称},而通过单独的{课程号}已经能够得到{课程名称},则说明(课程名称}部分依赖于{学生学号,课程号}。(部分依赖会造成数据冗余及各种异常。)
3.5传递函数
3.5.1定义:
如果X->Y(Y不是X的子集),Y不函数依赖于X,Y->Z,Z不是Y的子集,则称Z对X传递函数依赖。
3.5.2例如:
在关系R(学号,宿舍,费用)中,通过(学号}可以得到[{宿舍},通过{宿舍}可以得到[费用},而反之都不成立,则存在传递依赖{学号}->{费用}。(传递依赖也会造成数据冗余及各种异常。)
4.超码、主码、候选码的概念与区分
4.1什么是码?
4.1.1定义:

码是数据系统中的基本概念。所谓码就是能唯一标识实体(数据库中的实体:对应现实生活中某样事物或者人物)的属性,他是整个实体集的性质,而不是单个实体的性质。它包括超码,候选码,主码。
4.1.2例如:
下面我以学生表为例,给大家分享我对码的理解,比如有一个学生表: student(Id,Sno , Name , Sex),即:Id、学号、姓名、性别,这里的实体是student,实体的属性有Id,Sno , Name , Sex。
4.2超码
4.2.1定义:
超码也叫做超级码”,是一个或多个属性的集合,这些属性可以让我们在一个实体集(所谓的实体集就是student表中多条记录的集合)中唯一地标识一个实体。如果K是一个超码,那么K的任意超集也是超码,也就是说如果K是超码,那么所有包含K的集合也是超码。
所谓超集是集合论的术语,A ⊇ B,则 A 集是 B 的超集,也就是说 B 的所有元素 A 里都有,但 A 里的元素 B 就未必有
4.2.2例如:
因为通过Id或者Sno可以找到唯一一个学生,所以{Id}和{Sno}是超码,同理{Id ,Sno}、 {Id,Sno, Name}、{Id,Sno ,Name , Sex}、{Sno, Name}、 {Sno, Name,Sex}也是超码
4.3候选码
4.3.1定义:
超码包括候选码,虽然超码可以唯一标识一个实体,但是可能大多数超码中含有多余的属性,所以我们需要候选码。若关系中的一个属性或属性组的值能够唯一地标识一个元组,且它的真子集不能唯一的标识一个元组,则称这个属性或属性组做候选码。
子集比真子集范围大,子集是包括本身的元素的集合,真子集是除本身的元素的集合
4.3.2例如:
在上例中,只有{Id}或者{Sno}是候选码。如果Sex和Name可以唯一标识一个学生,则{Name, Sex}也为候选码,但是,Sex和Name并不能唯一标识一个学生,这与现实生活是违反的,因为现实有同名同姓的人,则{Name,Sex}不能作为候选码。
4.4主码
4.4.1定义:
一个表的候选码可能有多个,从这些个候选码中选择一个做为主码,至于选择哪一个候选码,这个是无所谓的,只要是从候选码中选的就行。
4.4.2例如:
在上例中,只有{Id}或者{Sno}是候选码。可以选Id或者Sno为主码。
4.5总结
所有码都是一个集合。所有可以用来在实体集中标识唯一一个实体的集合,都是超码。如果任意超码的真子集不能包括超码(换句话说就是:它的真子集不能唯一的标识一个元组),则称其为候选码。被数据库设计者选中的,用来在同一实体集中区分不同实体的候选码就是主码,可以是一个属性或者多个属性的集合。
简单的说,超码包括候选码,候选码包括主码。
4.5.1例子1:使用id属性作为主码,MySQL表定义代码如下:
-- 创建学生表
CREATE TABLE student1(
Id INT PRIMARY KEY,
Sno VARCHAR(20),
Name VARCHAR(20),
Sex VARCHAR(4)
);
4.5.2例子2:使用id和Sno属性集合作为主码,MySQL表定义代码如下:
-- 创建学生表
CREATE TABLE Student2(
Id INT,
Sno VARCHAR(20),
Name VARCHAR(20),
Sex VARCHAR(4),
CONSTRAINT StudentPrimary PRIMARY KEY(Id,Sno)
);