问题引领:
问题引领:我有GPU,有CUDA,但是却识别不到,情况如下:
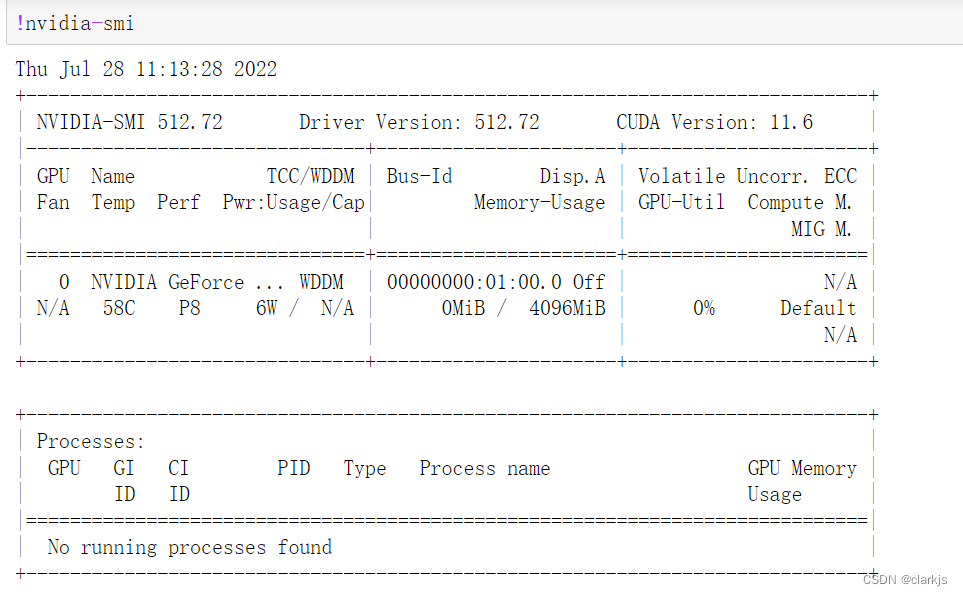
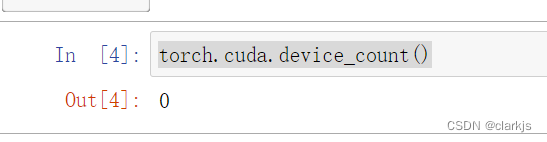
看起来很慌,其实不用慌滴,很快既可以解决掉,听我细细道来:

这是由于当初配置虚拟环境的时候,安装的是CPU版本的PyTorch(直接pip,默认是CPU),所以应该安装CUDA 11.6版本的PyTorch (上图中显示我是11.6的),但是不能直接安装,因为我已经有了CPU的PyTorch,同时安装两种会冲突,而删去CPU版本的PyTorch很难,因为仅删除envs里面的文件夹是很不靠谱的,因此需要删掉整个虚拟环境,重新安装正确的PyTorch,步骤如下:
conda remove -n [虚拟环境名] --all
2. 创建虚拟环境
conda create -n [虚拟环境名] python=3.8
3. 激活虚拟环境
conda activate [虚拟环境名]

此时,在左面会出现括号,括号里是你刚才创建的虚拟环境名字(随便起,不用和我的一样哦~)
4. 换源

(博主找不到命令出处了,只剩图片了,我怕自己敲错,uu们自己敲叭~)
5. 安装CUDA 11.6的PyTorch
安装pytorch可以自己找源下载,也可以去官网,博主有强迫症,就去官网了,拍个链接:
https://pytorch.org/get-started/locally/
然后根据自己的需要,选择合适的版本就好了,我选的是pip,因为选conda会有个NOTE,怕出问题,就选的NOTE,因为刚才换源了,再加上我用的热点,直接起飞了(之前需要47小时~,现在只需要1分钟):

6. End
然后可以根据自己的需求安装其他的包即可.
注意:pip install的时候不能开代理!!!!
附:为什么大家都用Anaconda?
Anaconda是一个Python发行版本,其包含了conda、Python等180多个科学包及其依赖项,它是科学计算领域非常流行的Python包以及集成环境管理的应用。它的优势主要表现在以下几个方面:
默认可以帮你安装好Python主程序,而不用单独下载安装。
常用的数据工作包,包含数据导入、清洗、处理、计算、展示等各个环节的主要包都已经安装好,如Pandas、Numpy、Scipy、Statsmodels、Scikit-Learn(sklearn)、NetworkX、Matplotlib等。常用的非结构化数据处理工具也一应俱全,如beautifulsoup4、lxml、NLTK、pillow、scikit-image等。
很多包的安装有依赖,这点在Linux系统上非常常见,而Anaconda已经将这些依赖的问题统统解决。尤其在离线环境下做Python和大量库的安装部署工作时,Anaconda大大降低了实施难度,是项目开发过程中必不可少的有效工具。
提供了类似于pip的包管理功能的命令conda,可以对包进行展示、更新、安装、卸载等常用操作。当然,如果你更喜欢pip,仍然可以继续使用该命令,因为Anaconda默认也安装了该命令。
多平台、多版本的通用性,而且紧跟Python主程序更新的步伐。Anaconda支持Windows、Mac OS和Linux系统,且同时包含32位和64位的Python版本(Python 2和Python 3全都支持)。
提供了IPyton、Jupyter、Spyder交互环境,可以直接通过界面化的方式引导用户操作,易用程度非常高,甚至连具体细分的学习资源都准备好了。
