文章目录
官方文档百科:https://github.com/alibaba/druid/wiki/Druid%E8%BF%9E%E6%8E%A5%E6%B1%A0%E4%BB%8B%E7%BB%8D
导言
项目里都配了,代码除了配了下,也没写相关代码,咱也不明白这是干啥的,今天来从零开始认识下吧,学会坚强。

什么是Druid连接池?
Druid连接池是阿里巴巴开源的数据库连接池项目。
Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。
哦,首先Druid是一个数据库连接池,第一次学,我也不知道,那么先来看看什么的数据库连接池
什么是数据库连接池?
数据库连接池(Database Connection Pooling)在程序初始化时创建一定数量的数据库连接对象并将其保存在一块内存区中,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个;释放空闲时间超过最大空闲时间的数据库连接以避免因为没有释放数据库连接而引起的数据库连接遗漏。
即在程序初始化的时候创建一定数量的数据库连接,用完可以放回去,下一个在接着用,通过配置连接池的参数来控制连接池中的初始连接数、最小连接、最大连接、最大空闲时间这些参数保证访问数据库的数量在一定可控制的范围类,防止系统崩溃,使用户的体验好
哦,懂了,跟那个线程池似的
再来看看它是干嘛的?
刚才说道他的作用: Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。
哦,懂了,监控对数据库的行为的
那他有什么意义呢?
数据库连接池的意义在于,能够重复利用数据库连接,提高对请求的响应时间和服务器的性能。
连接池中提前预先建立了多个数据库连接对象,然后将连接对象保存到连接池中,当客户请求到来时,直接从池中取出一个连接对象为客户服务,当请求完成之后,客户程序调用close()方法,将连接对象放回池中。
哦,懂了,提高了数据库连接效率(提高对请求的响应时间和服务器的性能)
那为什么就用它呢?
各产品性能指标如下:
Druid连接池在性能、监控、诊断、安全、扩展性这些方面远远超出竞品
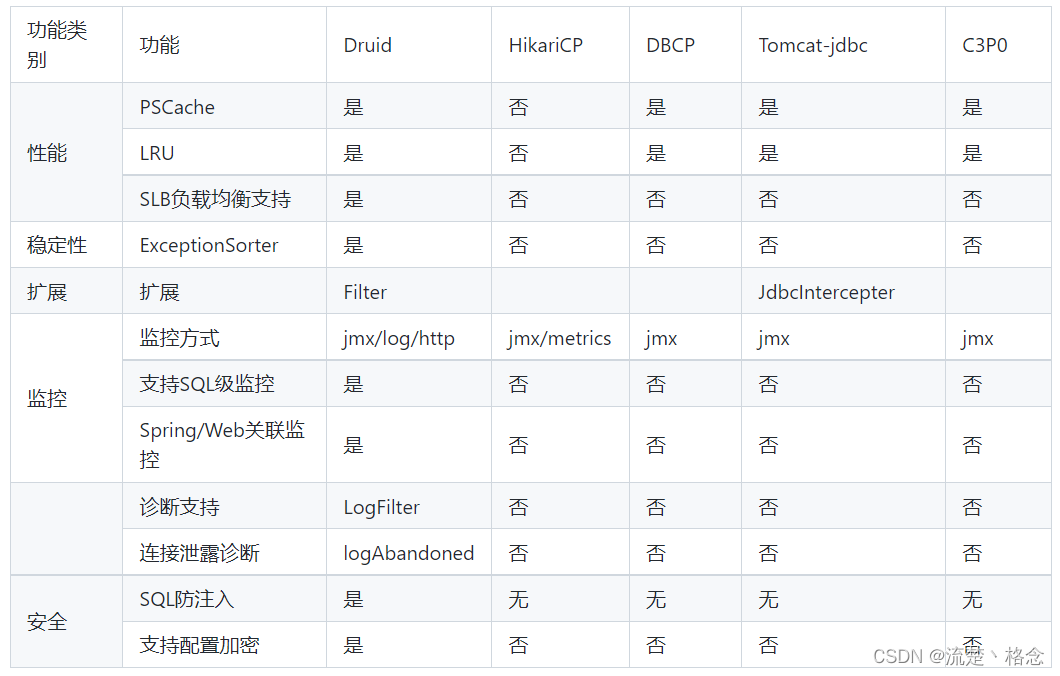
哦,懂了,因为Druid它牛

哦,那怎么用?
查了半天有人说是先要管理配置DataSource连接池对象
那先看看什么是DataSource,这个不要慌,翻译成中文就好,就是数据源(数据源就是一个数据的来源,在这相当于数据库)
说到这扩展一下什么是DataSource对象:
什么是DataSource对象?
DataSource对象是javax.sql包中的一个接口,其实就是可以标识为一个数据库连接资源,数据源对象里面应该存储连接的url,用户名和密码等连接信息。
哦,DataSource对象是个接口,放数据库连接信息的
在使用JDBC连接数据库的时候,都使用通过DriverManager进行获取Connection对象,getConnection方法都需要传递url,name.passwd等信息,其实这些信息就是可以充当一个数据源对象。
那什么是DataSource连接池呢?
翻译成中文就是数据源连接池。数据源就是一个数据的来源,相当于数据库。
但是程序去访问数据库并不直接访问,会通过一个代理,也就是数据连接池,每一个数据连接池引用的对象肯定有数据源。DataSource的实现子类有很多,其中很多第三方的连接池都是需要实现DataSource的,如果创建一个带数据池的数据源,则就有连接池功能了。
哦,其实就是数据库连接池呗
比如:Mybatis就有默认的数据源实现类(就是你在xml中配置的)
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/db_test?characterEncoding=UTF-8&allowMultiQueries=true"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
这你来来回回绕了半天,就是一句话啊:就是先配置数据库连接池,数据库连接池是啥刚才说了
比如现在说的是Druid连接池,那么项目中使用的数据源连接池为:DruidDataSource。
Druid连接池配置
【第一步】添加Druid连接池依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
注意:除了添加以上两个依赖之外,别忘了添加spring-context依赖。
【第二步】配置DruidDataSource连接池Bean对象
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/spring_db"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</bean>
【第三步】在测试类中从IOC容器中获取连接池对象并打印
public class App {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
DataSource dataSource = (DataSource) ctx.getBean("dataSource");
System.out.println(dataSource);
}
}
结果为:

哦,有连接池了
配置参数
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="url" value="${jdbc_url}" />
<property name="username" value="${jdbc_user}" />
<property name="password" value="${jdbc_password}" />
<property name="filters" value="stat" />
<property name="maxActive" value="20" />
<property name="initialSize" value="1" />
<property name="maxWait" value="6000" />
<property name="minIdle" value="1" />
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<property name="minEvictableIdleTimeMillis" value="300000" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<property name="poolPreparedStatements" value="true" />
<property name="maxOpenPreparedStatements" value="20" />
<property name="asyncInit" value="true" />
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- 基本属性 url、user、password -->
<property name="url" value="${jdbc_url}" />
<property name="username" value="${jdbc_user}" />
<property name="password" value="${jdbc_password}" />
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="5" />
<property name="minIdle" value="10" />
<property name="maxActive" value="20" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="6000" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="2000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="600000" />
<property name="maxEvictableIdleTimeMillis" value="900000" />
<property name="validationQuery" value="select 1" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<!-- 配置监控统计拦截的filters -->
<property name="filters" value="stat" />
</bean></bean>
好了后面原理不写了
我先没时间学了,有空看看大佬们整理的
吐槽
学一个习真难,现在Java生态越来越好,遗留的杂乱的旧知识也越来越多,哎,对于一个新人,又没有老师教,很难学。
网上的文章也乱七八糟,也不知道说的啥,排名还挺高
也可能是我没啥好办法,没有好资源,各位大佬如果有"很正统的"新的Java学习资源、团队可以拉我下,求带飞
