介绍

目录

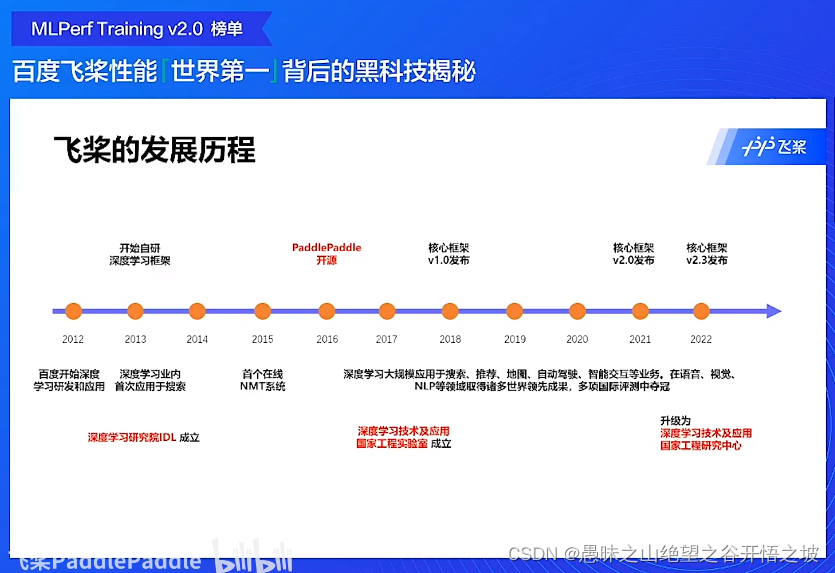
发展历程
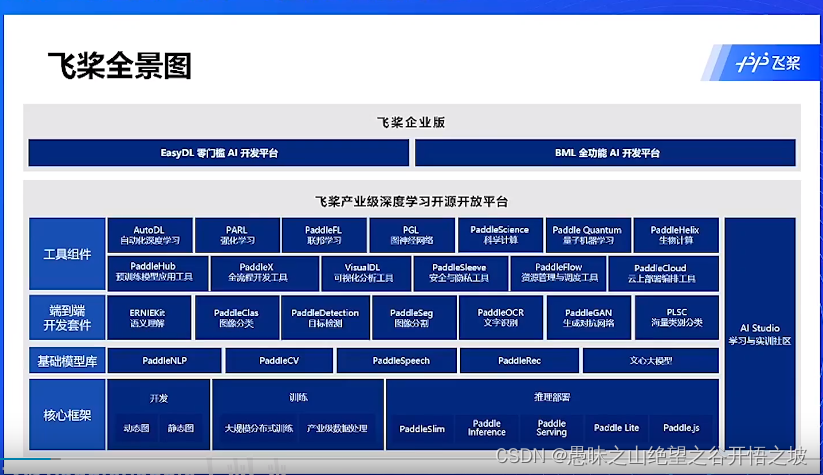
全景图,开发、训练、推理部署
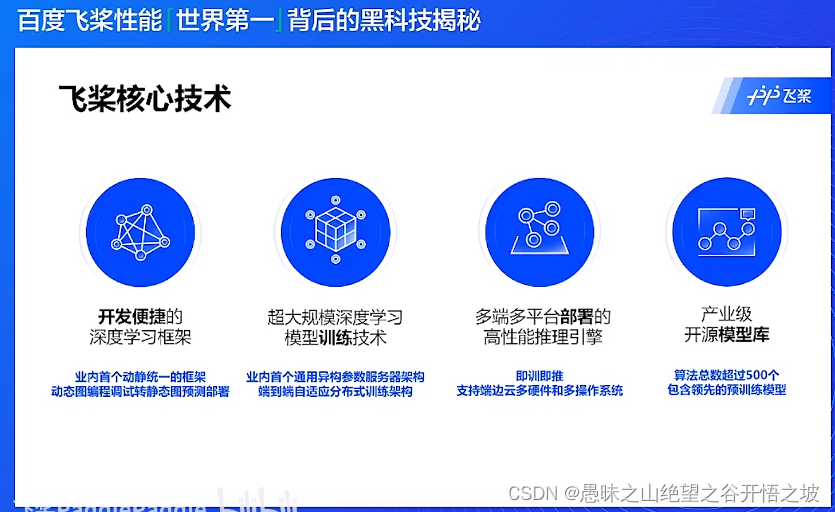
核心技术
数据和模型和硬件的组合,自动优化
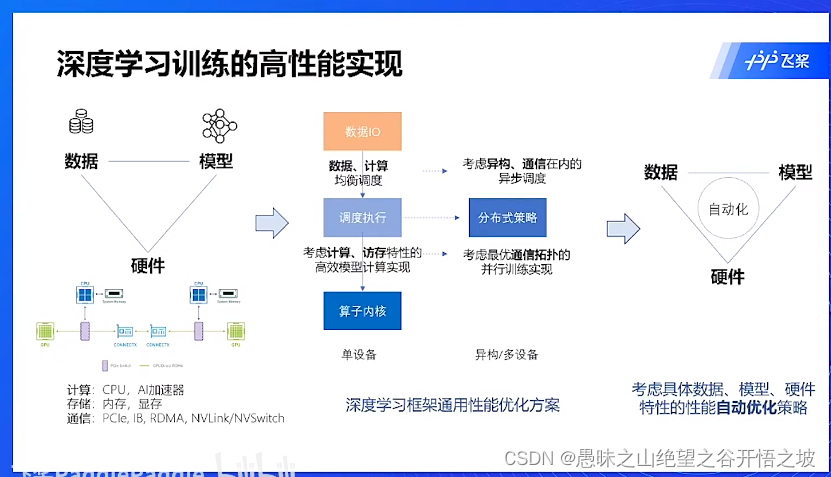
调整和优化方案
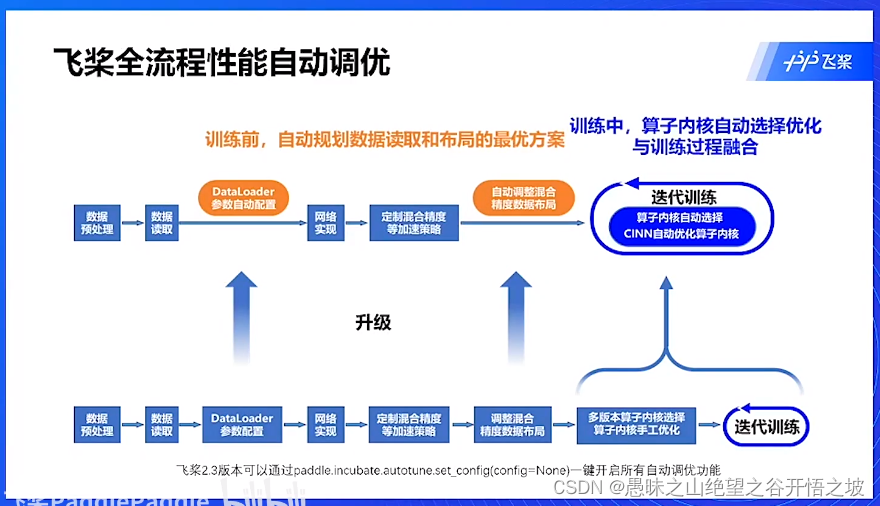
自动调优
全流程评价

评测标准和机构

介绍

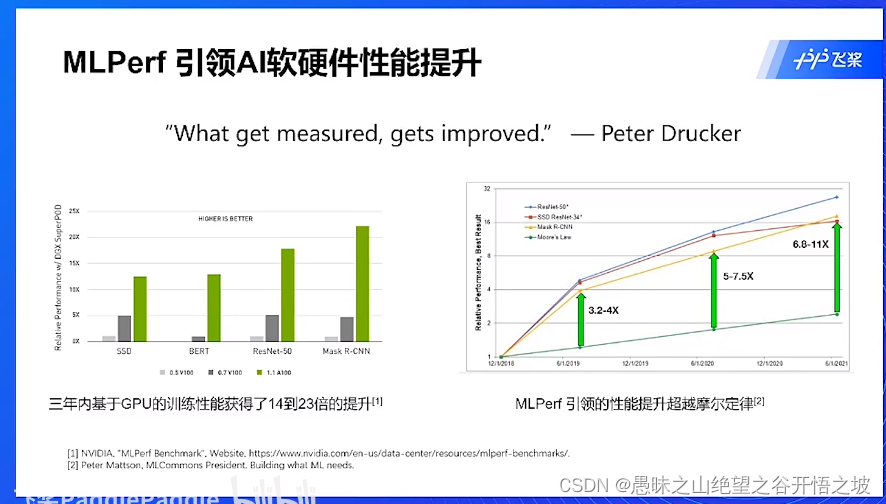
介绍,训练推理性能基准测试

性能
规则

测试结果
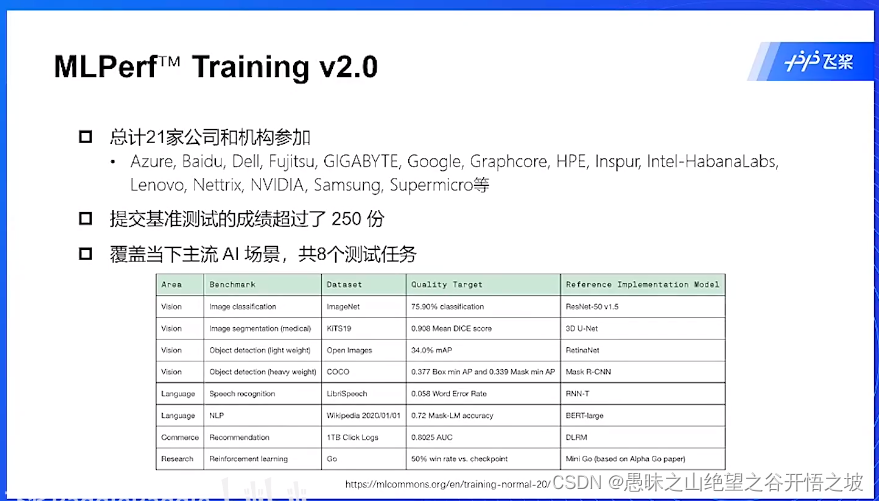
基准

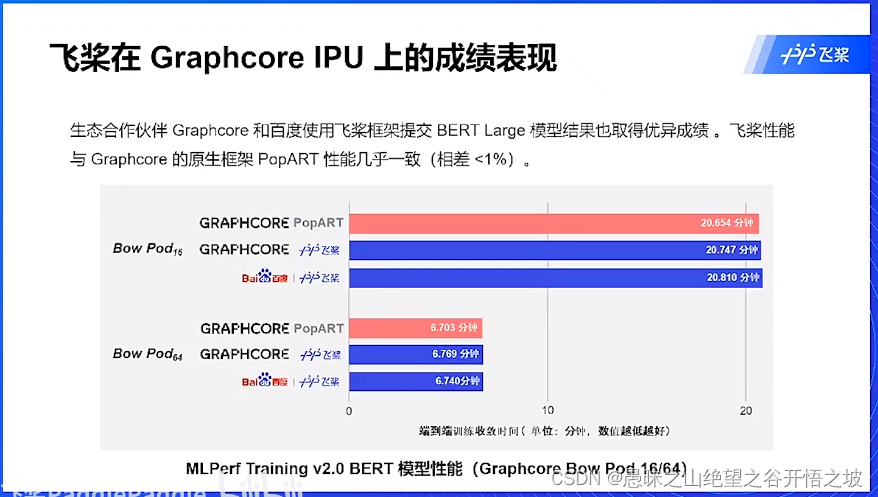
成绩表现

硬件合作厂商
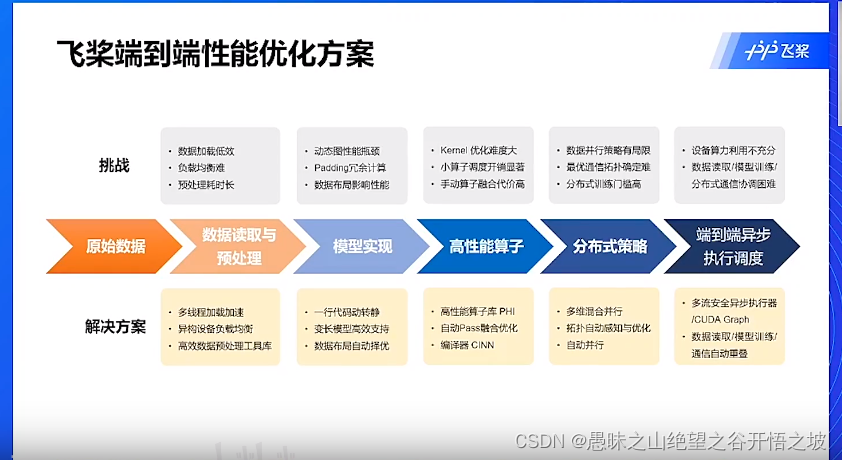
端到端的性能优化,在哪里优化,就是在整个流程
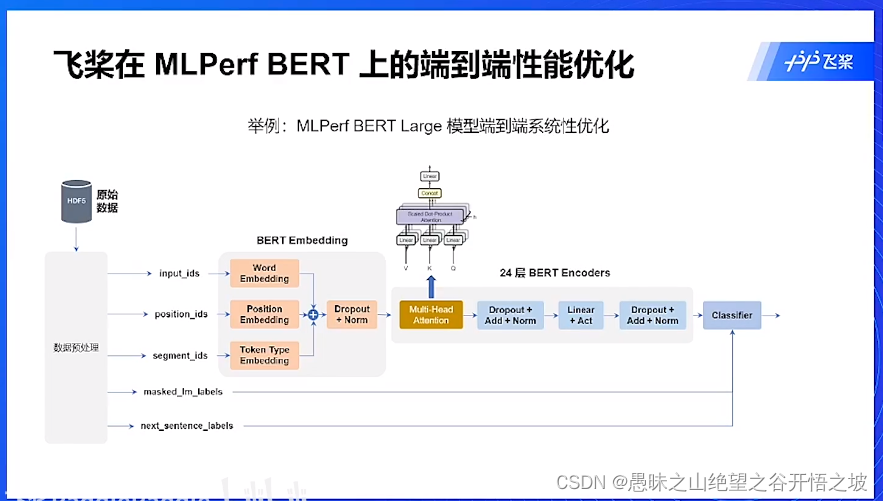
各个模块的优化
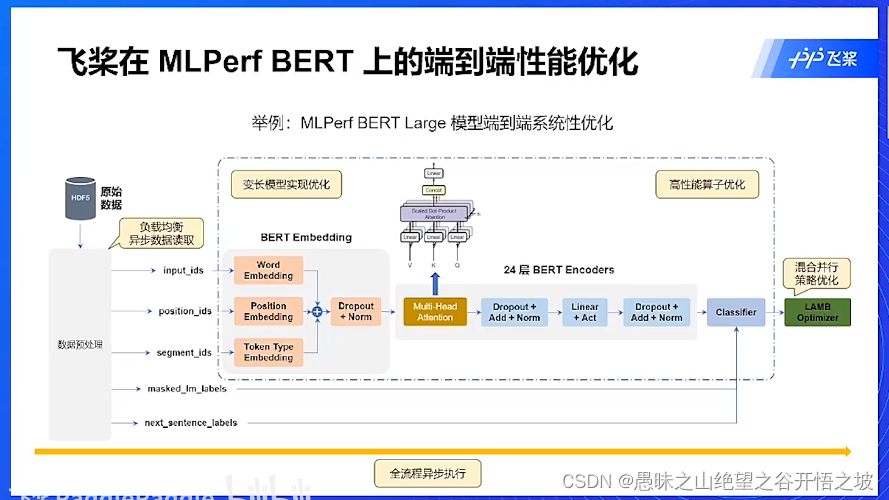
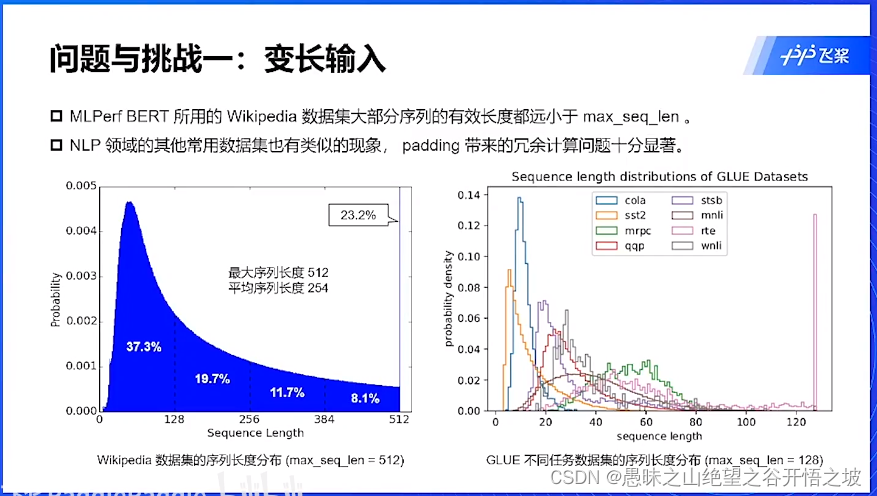
变成输入的优化,直接padding浪费资源

挑战
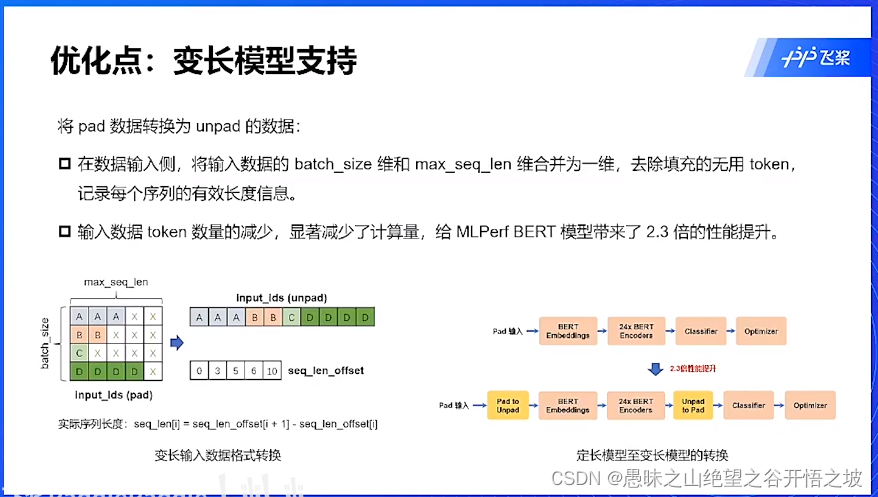
优化点
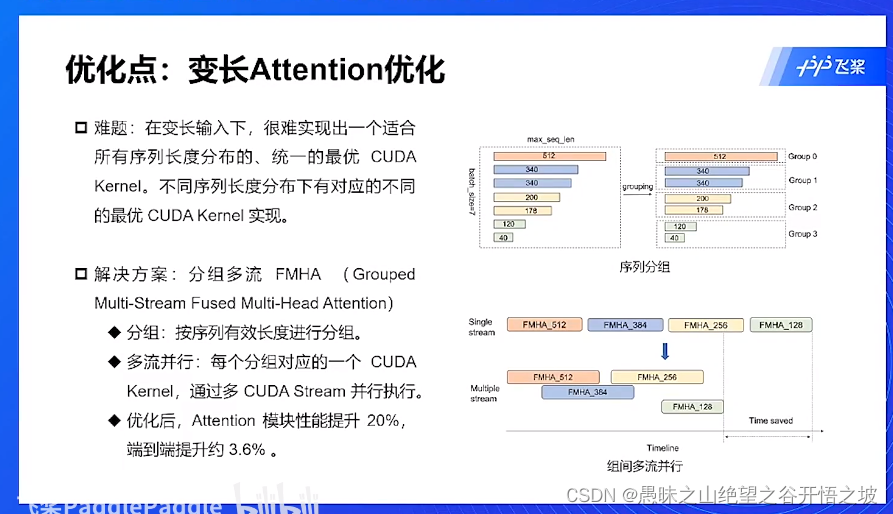
分组运算,并行
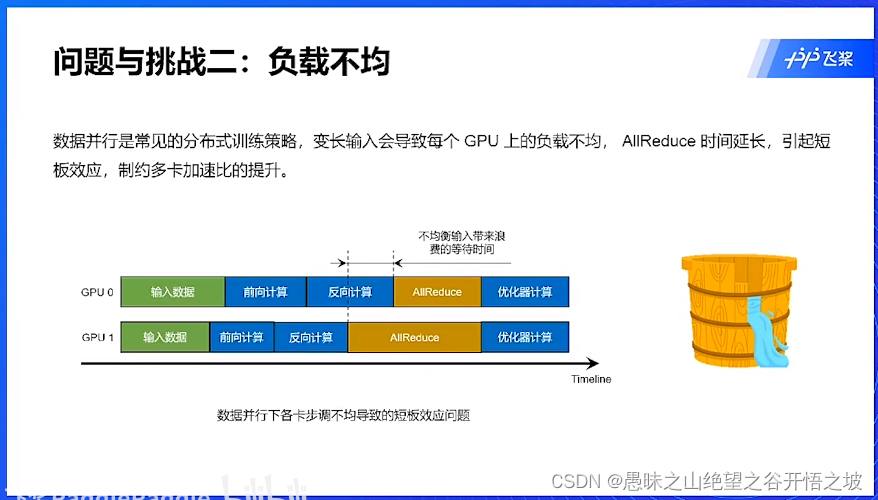
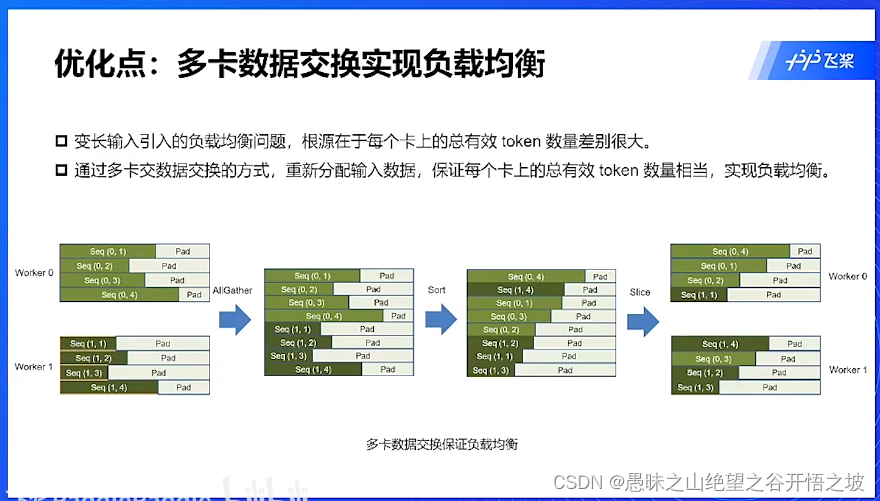
负载不均
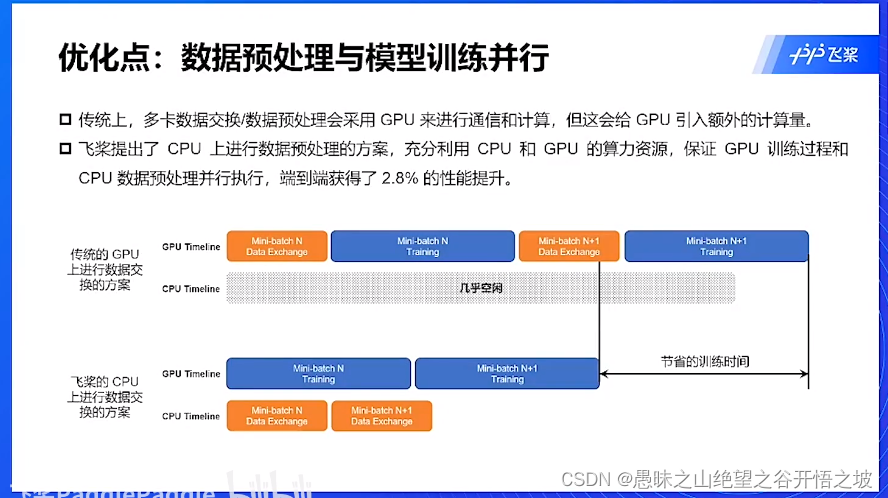
数据预处理和模型训练并行,尽量在CPU上做数据处理,GPU只是模型训练
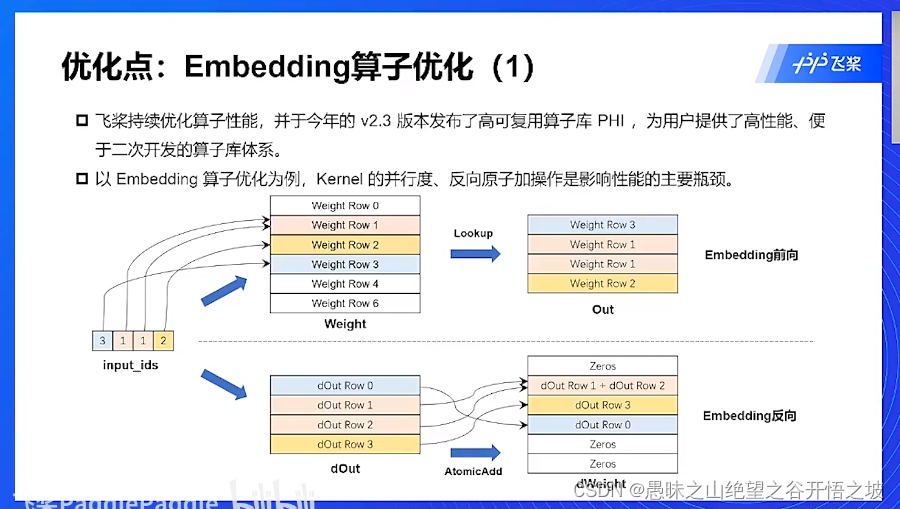
算子性能

算子优化

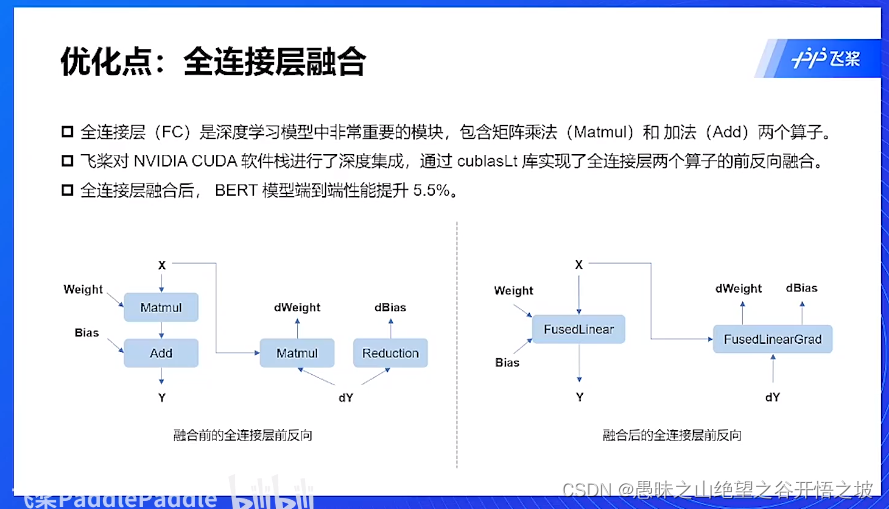
全连接层优化,减小kernel的调用
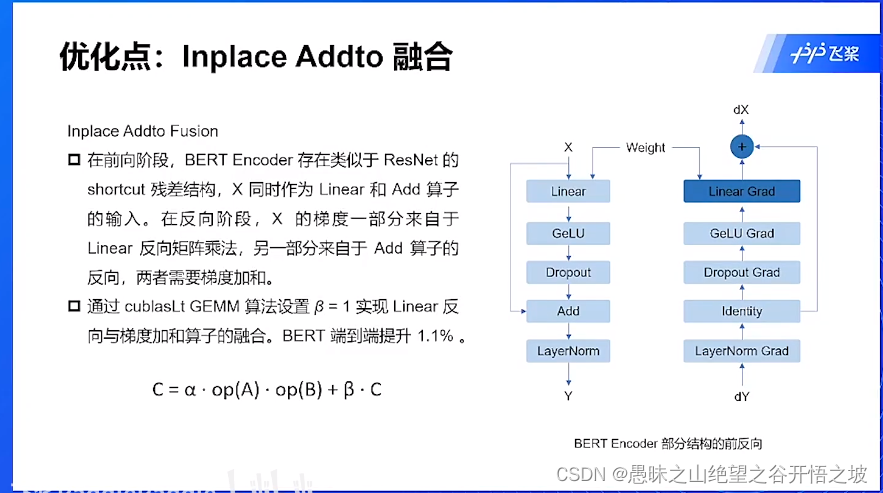
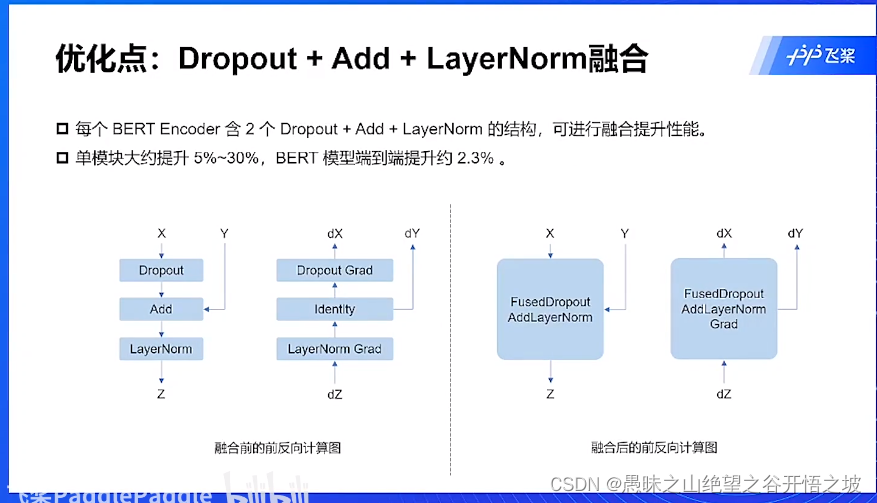
融合
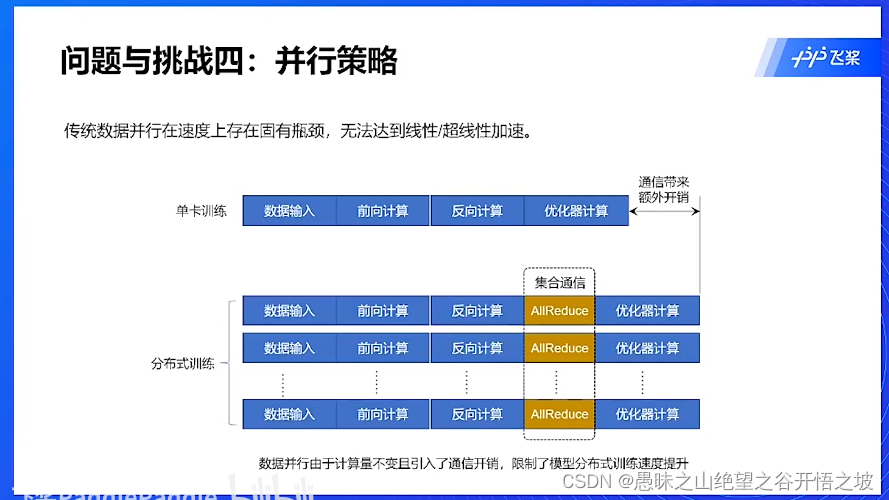
并行策略
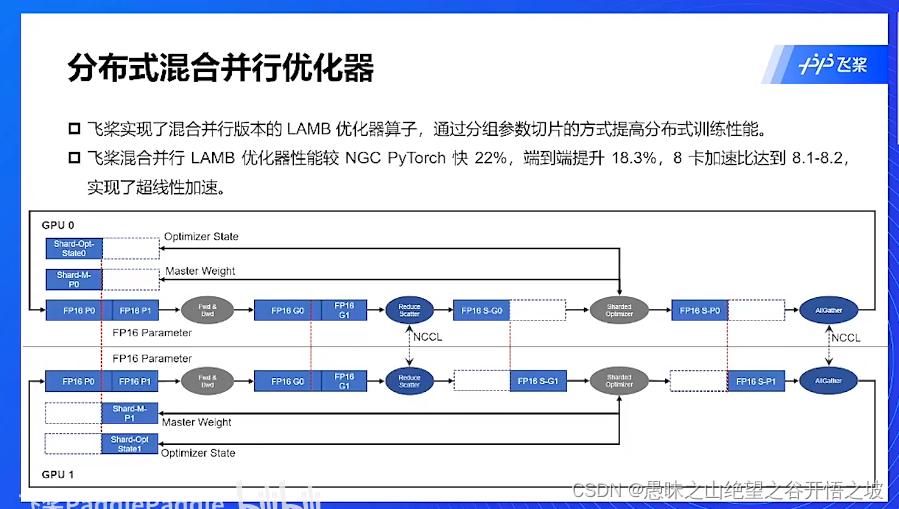
混合并行优化器
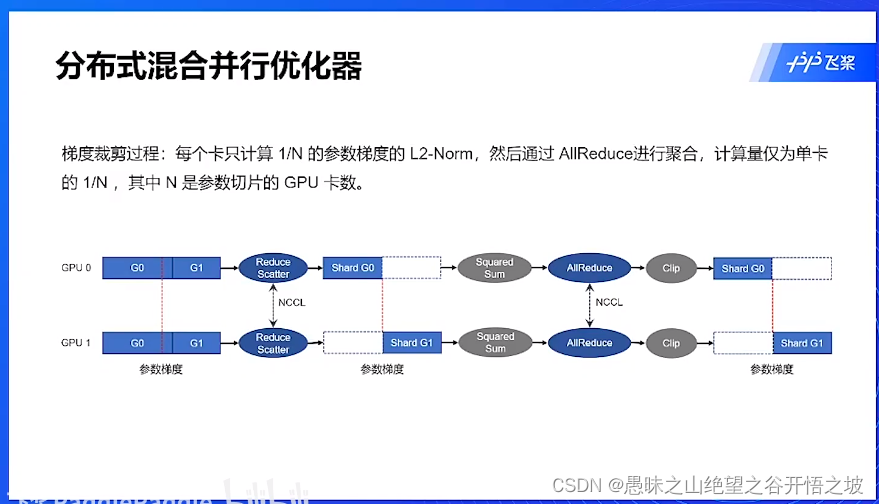
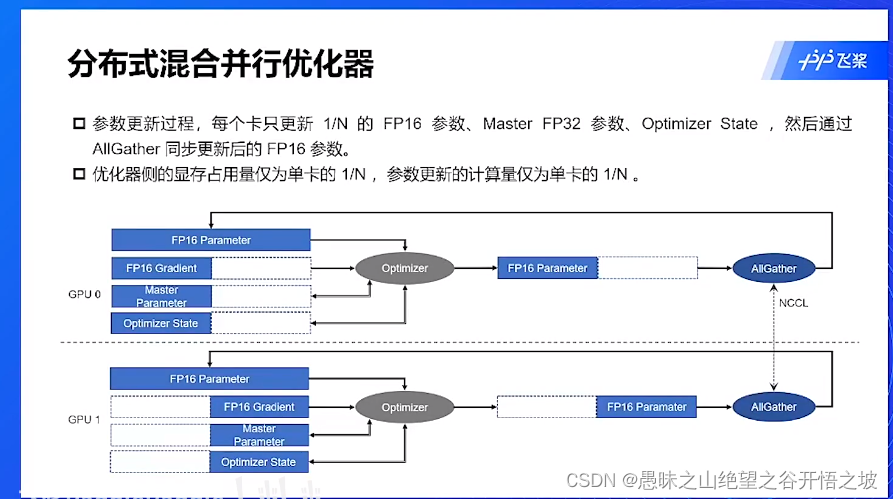
拷贝,调度问题
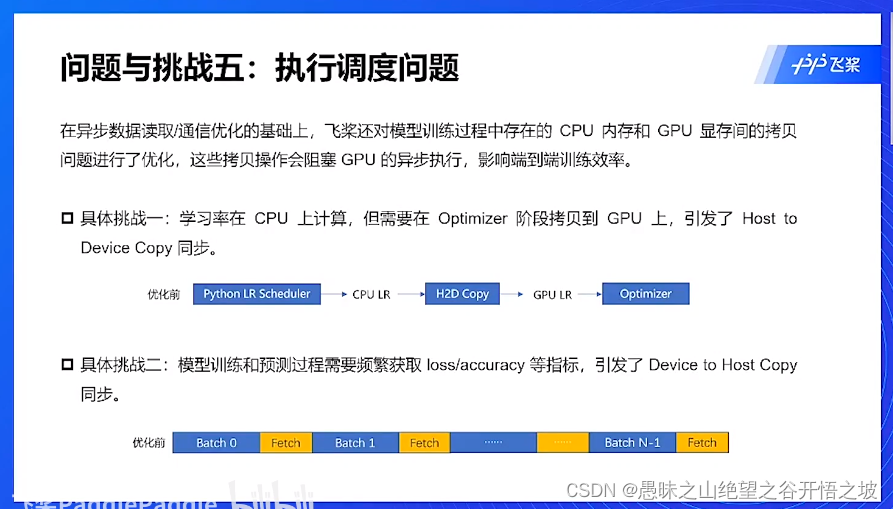
学习率直接放在GPU

提升效果
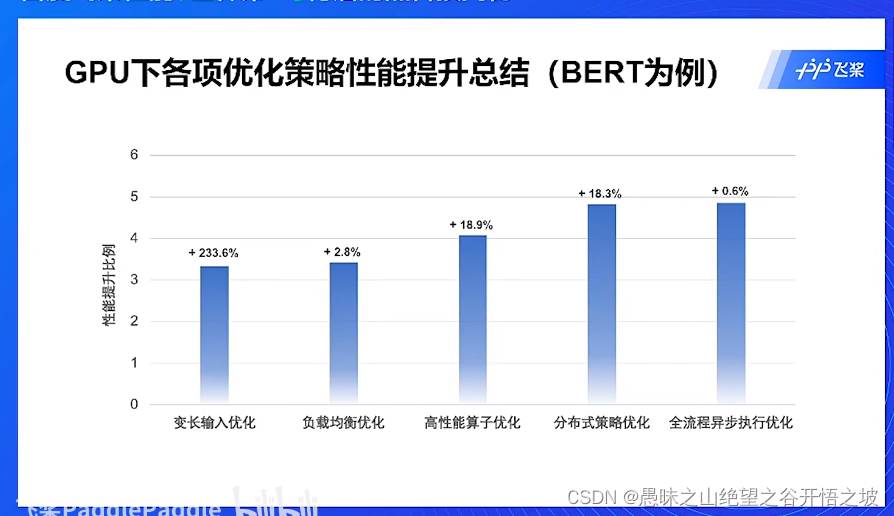
优化简介
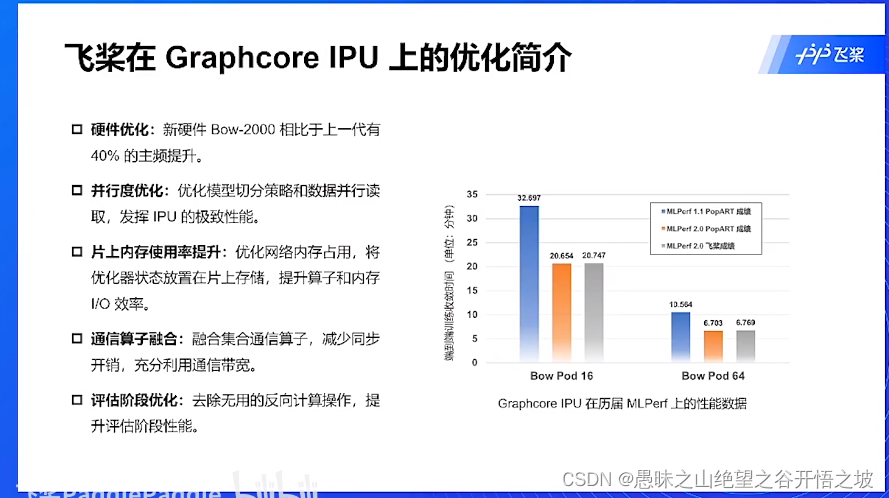
总结