第一个区别是,如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。
这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较
少,执行效率也就比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较
多,执行效率也较低。
第二个区别是,WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分
组计算的函数和分组字段作为筛选条件。
这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以
无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。
这么说你可能不太好理解,我来举个小例子。假如超市经营者提出,要查询一下是哪个收银员、在哪天卖了 2 单商品。这种必须先分组才能筛选的查询,用
WHERE 语句实现就比较难,我们可能要分好几步,通过把中间结果存储起来,才能搞定。但是用 HAVING,则很轻松,代码如下:
mysql> SELECT
-> a.transdate, c.operatorname
-> FROM
-> demo.transactionhead AS a
-> JOIN
-> demo.transactiondetails AS b ON (a.transactionid = b.transactionid)
-> JOIN
-> demo.operator AS c ON (a.operatorid = c.operatorid)
-> GROUP BY a.transdate,c.operatorname
-> HAVING count(*)=2; -- 销售了2单
+---------------------+--------------+
| transdate | operatorname |
+---------------------+--------------+
| 2020-12-10 00:00:00 | 张静 |
+---------------------+--------------+
1 row in set (0.01 sec)
我汇总了 WHERE 和 HAVING 各自的优缺点,如下图所示:
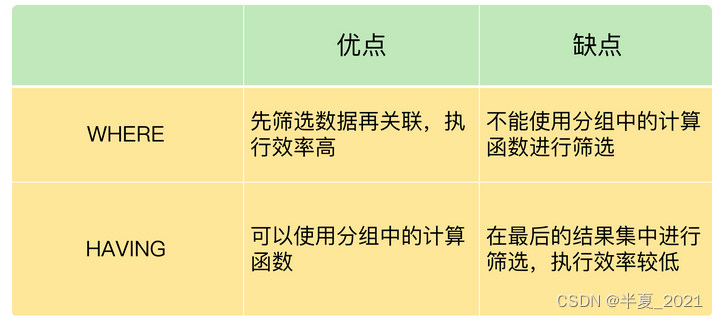
不过,需要注意的是,WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。
举个例子,假设现在我们有一组销售数据,包括交易时间、收银员、商品名称、销售数量、价格和销售金额等信息,超市的经营者要查询“2020-12-10”和“2020-
12-11”这两天收银金额超过 100 元的销售日期、收银员名称、销售数量和销售金额。
mysql> SELECT
-> a.transdate,
-> c.operatorname,
-> d.goodsname,
-> b.quantity,
-> b.price,
-> b.salesvalue
-> FROM
-> demo.transactionhead AS a
-> JOIN
-> demo.transactiondetails AS b ON (a.transactionid = b.transactionid)
-> JOIN
-> demo.operator AS c ON (a.operatorid = c.operatorid)
-> JOIN
-> demo.goodsmaster as d on (b.itemnumber=d.itemnumber);
+---------------------+--------------+-----------+----------+-------+------------+
| transdate | operatorname | goodsname | quantity | price | salesvalue |
+---------------------+--------------+-----------+----------+-------+------------+
| 2020-12-10 00:00:00 | 张静 | 书 | 1.000 | 89.00 | 89.00 |
| 2020-12-10 00:00:00 | 张静 | 笔 | 2.000 | 5.00 | 10.00 |
| 2020-12-11 00:00:00 | 李强 | 书 | 2.000 | 89.00 | 178.00 |
| 2020-12-12 00:00:00 | 李强 | 笔 | 10.000 | 5.00 | 50.00 |
+---------------------+--------------+-----------+----------+-------+------------+
4 rows in set (0.00 sec)
如果你仔细看 HAVING 后面的筛选条件,就会发现,条件 a.transdate IN (‘2020-12-10’ , ‘2020-12-11’),其实可以用 WHERE 来限定。我们把查询改一下试试:
mysql> SELECT
-> a.transdate,
-> c.operatorname,
-> SUM(b.quantity),
-> SUM(b.salesvalue)
-> FROM
-> demo.transactionhead AS a
-> JOIN
-> demo.transactiondetails AS b ON (a.transactionid = b.transactionid)
-> JOIN
-> demo.operator AS c ON (a.operatorid = c.operatorid)
-> WHERE a.transdate in ('2020-12-12','2020-12-11') -- 先按日期筛选
-> GROUP BY a.transdate , operatorname
-> HAVING SUM(b.salesvalue)>100; -- 后按金额筛选
+---------------------+--------------+-----------------+-------------------+
| transdate | operatorname | SUM(b.quantity) | SUM(b.salesvalue) |
+---------------------+--------------+-----------------+-------------------+
| 2020-12-11 00:00:00 | 李强 | 2.000 | 178.00 |
+---------------------+--------------+-----------------+-------------------+
1 row in set (0.00 sec)
很显然,我们同样得到了需要的结果。这是因为我们把条件拆分开,包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE
条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。