多级树集合分裂(SPIHT)算法的过程详解与Matlab实现
一、SPIHT算法与EZW算法
EZW算法是一种基于零树的嵌入式图象编码算法,虽然在小波变换系数中,零树是一个比较有效的表示不重要系数的数据结构,但是,在小波系数中还存在这样的树结构,它的树根是重要的,除树根以外的其它结点是不重要的。
对这样的系数结构,零树就不是一种很有效的表示方法。A.Said和W.A.Pearlman根据Shapiro零树编码算法(EZW)的基本思想,提出了一种新的且性能更优的实现方法,即基于多级树集合分裂排序(Set Partitioning in Hierarchical Trees, SPIHT)的编码算法。它采用了空间方向树(SOT:spatial orientation tree)、全体子孙集合D(i,j)和非直系子孙集合L(i,j)的概念以更有效地表示上述特征的系数结构,从而提高了编码效率。
SPIHT算法能够生成一个嵌入位流(embedded bit stream),使接收的位流在任意点中断时,都可解压和重构图像,具有良好的渐进传输特性;算法的初始化过程、细化过程类似于EZW算法,它改进了EZW 重要图的表示方法,也就是重要系数在表中的排序信息,使得集合的表示更为精简,从而提高了编码效率和图像压缩率。
SPIHT算法在不同的比特率下比EZW算法的峰值信噪比(PSNR)都有所提高,具有计算复杂度低、位速率容易控制的特点。
SPIHT算法在系数子集的分割和重要信息的传输方面采用了独特的方法,能够在实现幅值大的系数优先传输的同时,隐式地传送系数的排序信息。这个隐式传送是什么意思呢?我们知道,任何排序算法的执行路径都是使用分支点的比较结果进行定义的!如果解码器和编码器使用相同的排序算法,则对于编码器输入的系数比较结果,解码器通过执行相同的路径就可获得排序信息,这就是所谓的“隐式传送排序信息”了。后面我们将会看到,SPIHT算法的解码、编码程序大部分代码是相同的,只在输入输出和分支点方面有所区别!
二、SPIHT算法使用的树结构、分集规则和有序表
1、树结构
SPIHT算法的树结构与EZW算法的树结构基本相同,区别在于:
对于一幅N级二维小波分解的图像,在EZW算法的零树结构中,LL_N有三个孩子HL_N、LH_N和HH_N;而SPIHT算法的树结构中,LL_N是没有孩子的!
SPIHT算法的树结构中,树的每个节点与一个小波系数对应,我们用坐标(r,c)来标识节点或系数Cr,c。最低频子带LL_N中的系数和最高频子带中的系数没有孩子。
设X是一个小波系数坐标集:X={| (r,c) |},对于正整数n,定义函数Sn (X) 如下:
if max{| Cr,c |}>= 2 ^ n then Sn (X) = 1
else Sn (X) = 0
如果Sn (X) = 1,则坐标集X关于阈值2 ^ n 是重要的,否则是不重要的。
2、分集规则
首先引入下面四个集合符号:
(1)O (r,c) —— 节点(r,c)所有孩子的集合;
(2)D (r,c) —— 节点(r,c)所有子孙的集合(包括孩子);
(3)L (r,c) —— 节点(r,c)所有非直系子孙的集合(即不包括孩子);
L (r,c) = D (r,c) — O (r,c)
(4)H —— 所有树根的坐标集。(对N级小波分解,H就是LL_N、HL_N、LH_N和HH_N中所有系数的坐标构成的集合)
根据SPIHT算法树结构的特点,除了LL_N、LL_1、HL_1、LH_1和HH_1之外,对任意系数的坐标(r,c),都有:(由于Matlab矩阵下标起始值为1,公式作了相应调整)
O (r,c) = { (2r-1,2c-1), (2r-1,2c), (2r,2c-1), (2r,2c) }
SPIHT算法的分集规则如下:
(1) 初始坐标集为{(r,c) | (r,c)∈H }、{D(r,c) | (r,c)∈H }。
(2) 若D(r,c) 关于当前阈值是重要的,则D(r,c) 分裂成 L (r,c) 和O (r,c)。
(3) 若L (r,c) 关于当前阈值是重要的,则L (r,c) 分裂成 4 个集合 D (rO,cO), (rO,cO) ∈O (r,c)。
3、有序表
SPIHT算法引入了三个有序表来存放重要信息:
(1) LSP —— 重要系数表;
(2) LIP —— 不重要系数表;
(3) LIS —— 不重要子集表。
这三个表中,每个表项都使用坐标(r,c)来标识。在LIP和LSP中,坐标(r,c)表示单个小波系数;而LIS中,坐标(r,c)代表两种系数集,即D(r,c) 或L (r,c),分别称为D型表项、L型表项,在Matlab实现时,用一个新的列表 LisFlag 来标识 LIS 中各个表项的类型,LisFlag的元素有‘D’、‘L’两种字符。
三、SPIHT算法的编码过程如下:
(1)初始化
输出初始阈值T的指数N = floor ( log2 ( max{| Cr,c |} ) )(Matlab函数floor( num )给出不大于数值num的最大整数)

定义: LSP为空集
LIP = {(r,c) | (r,c)∈H }
LIS = {D(r,c) | (r,c)∈H且(r,c)具有非零子孙}
初始的LIS中各表项类型均为‘D’,LIS和LIP中(r,c)的排列顺序与EZW算法零树结构的扫描顺序相同(即按从上到下、从左到右的“Z”型次序排列)。
(2)排序扫描
1)扫描LIP队列
对LIP队列的每个表项(r,c):
① 输出SnOut(r,c)(函数SnOut判断(r,c)的重要性);
② 如果SnOut(r,c)= 1,则向排序位流Sn输出‘1’和(r,c)的符号位(由‘1’、‘0’表示),然后将(r,c)从LIP队列中删除,添加到LSP队列的尾部。
③ 如果SnOut(r,c)= 0,则向排序位流Sn输出‘0’。
2)扫描LIS队列
对LIS队列的每个表项(r,c):
① 如果(r,c)是‘D’型表项
输出SnOut(D (r,c));
*如果SnOut(D (r,c))= 1
向排序位流Sn输出‘1’;
对每个(rO,cO)∈O (r,c)
输出SnOut(rO,cO)
*如果SnOut(rO,cO)= 1,则向排序位流Sn输出‘1’和(rO,cO)的符号位,将(rO,cO)添加到LSP的尾部;
*如果SnOut(rO,cO)= 0,则向排序位流Sn输出‘0’,将(rO,cO)添加到LIP的尾部。
判断L (r,c)是否为空集
如果L (r,c)非空,则将(r,c)作为‘L’型表项添加到LIS的尾部;
如果L (r,c)为空集,则将‘D’型表项(r,c)从LIS中删除。
*如果SnOut(D (r,c))= 0
则向排序位流Sn输出‘0’。
② 如果(r,c)是‘L’型表项
输出SnOut(L (r,c));
*如果SnOut(L (r,c))= 1,则向排序位流Sn输出‘1’,然后将(r,c)的4个孩子(rO,cO)作为‘D’型表项依次添加到LIS的尾部,将‘L’型表项(r,c)从LIS中删除;
*如果SnOut(L (r,c))= 0,则向排序位流Sn输出‘0’。
(3)精细扫描
将上一级扫描后的LSP列表记为LSP_Old,对于(r,c)∈LSP_Old,
将系数Cr,c的绝对值转换为二进制表示Br,c;
输出Br,c中第N个最重要的位(即对应于2^N权位处的符号‘1’或‘0’)到精细位流Rn。
(4)更新阈值指数
将阈值指数N减至N—1,返回到步骤(2)进行下一级编码扫描。
程序代码如下:
function [T,SnList,RnList,ini_LSP,ini_LIP,ini_LIS,ini_LisFlag]=spihtcoding(DecIm,imDim,codeDim)
%函数SPIHTCODING()是SPIHT算法的编码主程序
%输入参数:DecIm ——小波分解系数矩阵;
% imDim ——小波分解层数;
% codeDim ——编码级数。
%输出参数:T ——初始阈值,T=2^N,N=floor(log2(max{
|c(i,j)|})),c(i,j)为小波系数矩阵的元素
% SnList ——排序扫描输出位流
% RnList ——精细扫描输出位流
% ini_L* ——初始系数(集合)表
% LSP:重要系数表
% LIP:不重要系数表
% LIS:不重要子集表,其中的表项是D型或L型表项的树根点
% LisFlag:LIS中各表项的类型,包括D型和L型两种
global Mat rMat cMat
% Mat是输入的小波分解系数矩阵,作为全局变量,在编码的相关程序中使用
% rMat、cMat是Mat的行、列数,作为全局变量,在编码、解码的相关程序中使用
%---------------------------%
% ----- Threshold ----- %
%---------------------------%
Mat=DecIm;
MaxMat=max(max(abs(Mat)));
N=floor(log2(MaxMat));
T=2^N;
%公式:N=floor(log2(max{
|c(i,j)|})),c(i,j)为小波系数矩阵的元素
%--------------------------------------%
% ----- Output Intialization ----- %
%--------------------------------------%
SnList=[];
RnList=[];
ini_LSP=[];
ini_LIP=coef_H(imDim);
rlip=size(ini_LIP,1);
ini_LIS=ini_LIP(rlip/4+1:end,:);
rlis=size(ini_LIS,1);
ini_LisFlag(1:rlis)='D';
% ini_LSP:扫描开始前无重要系数,故LSP=[];
% ini_LIP:所有树根的坐标集,对于N层小波分解,LIP是LL_N,LH_N,HL_N,HH_N所有
% 系数的坐标集合;
% 函数COEF_H()用于计算树根坐标集H
% ini_LIS:初始时,LIS是LH_N,HL_N,HH_N所有系数的坐标集合;在SPIHT算法中,
% LL_N没有孩子。
% ini_LisFlag:初始时,LIS列表的表项均为D型。
%------------------------------------------------%
% ----- Coding Input Initialization ------ %
%------------------------------------------------%
LSP=ini_LSP;
LIP=ini_LIP;
LIS=ini_LIS;
LisFlag=ini_LisFlag;
%将待输出的各项列表存入相应的编码工作列表
%--------------------------------%
% ----- Coding Loop ------ %
%--------------------------------%
for d=1:codeDim
%------------------------------------------%
% ----- Coding Initialization ------- %
%------------------------------------------%
Sn=[];
LSP_Old=LSP;
%每级编码产生的Sn都是独立的,故Sn初始化为空表
%列表LSP_Old用于存储上级编码产生的重要系数列表LSP,作为本级精细扫描的输入
%-------------------------------%
% ----- Sorting Pass ----- %
%-------------------------------%
% ----- LIP Scan -------- %
%----------------------------%
[Sn,LSP,LIP]=lip_scan(Sn,N,LSP,LIP);
%检查LIP表的小波系数,更新列表LIP、LSP和排序位流Sn
%-------------------------%
% ----- LIS Scan ----- %
%-------------------------%
[LSP,LIP,LIS,LisFlag,Sn,N]=lis_scan(N,Sn,LSP,LIP,LIS,LisFlag);
%这里,作为输出的N比作为输入的N少1,即out_N=in_N-1
%各项输出参数均作为下一编码级的输入
%-------------------------------------%
% ----- Refinement Pass ----- %
%-------------------------------------%
Rn=refinement(N+1,LSP_Old);
%精细扫描是在当前阈值T=2^N下,扫描上一编码级产生的LSP,故输入为(N+1,LSP_Old),
%输出为精细位流Rn
%-----------------------------------%
% ----- Output Dataflow ----- %
%-----------------------------------%
SnList=[SnList,Sn,7];
RnList=[RnList,Rn,7];
%数字‘7’作为区分符,区分不同编码级的Rn、Sn位流
end
编码主程序中调用到的子程序有:
COEF_H():用于计算树根坐标集H,生成初始的LIP队列;
LIP_SCAN():检查LIP表的各个表项是否重要,更新列表LIP、LSP和排序位流Sn;
LIS_SCAN():检查LIS表的各个表项是否重要,更新列表LIP、LSP、LIS、LisFlag和排序位流Sn;
REFINEMENT():精细扫描编码程序,输出精细位流Rn。
(1)下面是计算树根坐标集H的程序
function lp=coef_H(imDim)
%函数COEF_H()根据矩阵的行列数rMat、cMat和小波分解层数imDim来计算树根坐标集H
%输入参数:imDim ——小波分解层数,也可记作N
%输出参数:lp —— rMat*cMat矩阵经N层分解后,LL_N,LH_N,HL_N,HH_N所有系数的坐标集合
global rMat cMat
% rMat、cMat是Mat的行、列数,作为全局变量,在编码、解码的相关程序中使用
row=rMat/2^(imDim-1);
col=cMat/2^(imDim-1);
% row、col是LL_N,LH_N,HL_N,HH_N组成的矩阵的行、列数
lp=listorder(row,col,1,1);
%因为LIP和LIS中元素(r,c)的排列顺序与EZW零树结构的扫描顺序相同
%直接调用函数LISTORDER()即可获得按EZW扫描顺序排列的LIP列表
(2)这里调用了函数LISTORDER()来获取按EZW扫描顺序排列的LIP列表,以下是该函数的程序代码:
function lsorder=listorder(mr,mc,pr,pc)
%函数LISTORDER()生成按‘Z’型递归结构排列的坐标列表
%函数递归原理:对一个mr*mc的矩阵,其左上角元素的坐标为(pr,pc);首先将矩阵按“田”
%字型分成四个对等的子矩阵,每个子矩阵的行、列数均为mr/2、mc/2,左上角元素的坐标
%从上到下、从左到右分别为(pr,pc)、(pr,pc+mc/2)、(pr+mr/2,pc)、(pr+mr/2,pc+mc/2)。
%把每个子矩阵再分裂成四个矩阵,如此递归分裂下去,直至最小矩阵的行列数等于2,获取最小
%矩阵的四个点的坐标值,然后逐步向上回溯,即可得到按‘Z’型递归结构排列的坐标列表。
lso=[pr,pc;pr,pc+mc/2;pr+mr/2,pc;pr+mr/2,pc+mc/2];
%列表lso是父矩阵分裂成四个子矩阵后,各子矩阵左上角元素坐标的集合
mr=mr/2;
mc=mc/2;
%子矩阵的行列数是父矩阵的一半
lm1=[];lm2=[];lm3=[];lm4=[];
if (mr>1)&&(mc>1)
%按‘Z’型结构递归
ls1=listorder(mr,mc,lso(1,1),lso(1,2));
lm1=[lm1;ls1];
ls2=listorder(mr,mc,lso(2,1),lso(2,2));
lm2=[lm2;ls2];
ls3=listorder(mr,mc,lso(3,1),lso(3,2));
lm3=[lm3;ls3];
ls4=listorder(mr,mc,lso(4,1),lso(4,2));
lm4=[lm4;ls4];
end
lsorder=[lso;lm1;lm2;lm3;lm4];
%四个子矩阵结束递归回溯到父矩阵时,列表lsorder的头四个坐标值为列表lso的元素
%这四个坐标值与后面的各个子矩阵的坐标元素有重叠,故需消去
%当函数输出的列表长度length(lsorder)与矩阵的元素个数mr*mc*4不相等时,
%就说明有坐标重叠发生。
len=length(lsorder);
lsorder=lsorder(len-mr*mc*4+1:len,:);
本文给出SPIHT编码的精细扫描程序,其中包括一个能够将带小数的十进制数转换为二进制表示的函数,这个转换函数可以实现任意精度的二进制转换,特别是将小数部分转换为二进制表示。希望对有需要的朋友有所帮助。下一篇文章将给出SPIHT的解码程序。请关注后续文章,欢迎Email联系交流。
4、精细扫描程序
function Rn=refinement(N,LSP_Old)
%函数REFINEMENT()为精细编码程序,对上一级编码产生的重要系数列表LSP_Old,读取每个
%表项相应小波系数绝对值的二进制表示,输出其中第N个重要的位,即相应于2^N处的码数
%输入参数:N ——本级编码阈值的指数
% LSP_Old ——上一级编码产生的重要系数列表
%输出参数:Rn ——精细扫描输出位流
global Mat
% Mat是输入的小波分解系数矩阵,作为全局变量,在编码的相关程序中使用
Rn=[];
%每级精细扫描开始时,Rn均为空表
% LSP_Old非空时才执行精细扫描程序
if ~isempty(LSP_Old)
rlsp=size(LSP_Old,1);
%获取LSP_Old的表项个数,对每个表项进行扫描
for r=1:rlsp
tMat=Mat(LSP_Old(r,1),LSP_Old(r,2));
%读取该表项对应的小波系数值
[biLSP,Np]=fracnum2bin(abs(tMat),N);
%函数FRACNUM2BIN()根据精细扫描对应的权位N,将任意的十进制正数转换为二进制数,
%输出参数为二进制表示列表biLSP和权位N与最高权位的距离Np。
Rn=[Rn,biLSP(Np)];
% biLSP(Np)即为小波系数绝对值的二进制表示中第N个重要的位
end
end
(1)十进制数转换为二进制表示的程序
function [binlist,qLpoint]=fracnum2bin(num,qLevel)
%函数FRACNUM2BIN()根据精细扫描对应的权位N,将任意的十进制正数转换为二进制数,
%包括带有任意位小数的十进制数。Matlab中的函数dec2bin()、dec2binvec()只能将十
%进制数的整数部分转换为二进制表示,对小数部分则不转换。
%
%输入参数:num ——非负的十进制数
% qLevel ——量化转换精度,也可以是精细扫描对应的权位N
%输出参数:biLSP ——二进制表示列表
% Np ——权位N与最高权位的距离,N也是本级编码阈值的指数
intBin=dec2binvec(num);
%首先用Matlab函数dec2binvec()获取整数部分的二进制表示intBin,低位在前,高位在后
intBin=intBin(end:-1:1);
%根据个人习惯,将二进制表示转换为高位在前,低位在后
lenIB=length(intBin);
%求出二进制表示的长度
decpart=num-floor(num);
%求出小数部分
decBin=[];
%小数部分的二进制表示初始化为空表
%根据量化精度要求输出总的二进制表示列表
if (qLevel+1)>lenIB
%如果量化精度高于整数部分的二进制码长,则输出为零值列表
binlist=zeros(1,qLevel+1);
qLpoint=1;
elseif qLevel>=0
%如果量化精度在整数权位,则输出整数部分的二进制表示intBin
%不需转换小数部分,同时输出量化精度与最高权位的距离Np
binlist=intBin;
binlist(lenIB-qLevel+1:end)=0;
qLpoint=lenIB-qLevel;
elseif qLevel<0
%如果量化精度在小数权位,则需转换小数部分
N=-1;
while N>=qLevel
%小数部分的转换只需进行到量化精度处
res=decpart-2^N;
if res==0
decBin=[decBin,1];
decBin(end+1:-qLevel)=0;
%如果小数部分的转换完成时仍未达到量化精度所在的权位,则补零
break;
elseif res>0
decBin=[decBin,1];
decpart=res;
N=N-1;
else
decBin=[decBin,0];
N=N-1;
end
end
binlist=[intBin,decBin];
qLpoint=lenIB-qLevel;
%输出整数部分和小数部分的二进制表示intBin,decBin,以及量化精度与最高权位的距离Np
end
至此,SPIHT算法的编码程序就介绍完毕啦!以后有时间的话会增加熵编码的功能(例如Huffman编码)。
现在我们讨论SPIHT算法的解码过程。SPIHT的编码输出包括:初始阈值T,排序扫描位流SnList,精细扫描位流RnList,初始有序表(LSP、LIP、LIS、LisFlag),这些参数就作为SPIHT解码的输入,另外还有解码级数decodeDim。
前面我们提到,任何排序算法的执行路径都是使用分支点的比较结果进行定义的。如果解码器和编码器使用相同的排序算法,则对于编码器输入的系数比较结果,解码器通过执行相同的路径就可获得排序信息。所以,只需将编码器数学表述中的“输出”改为“输入”,解码器即可恢复数据的排序信息;在恢复数据排序信息的同时,解码器还要负责图像的重构,对于确认恢复的重要系数,通过排序扫描和精细扫描两个步骤更新系数的量化值,逐步提高逼近精度和重构图像的质量。
1、首先给出解码主程序
function DecodeMat=spihtdecoding(T,SnList,RnList,ini_LSP,ini_LIP,ini_LIS,ini_LisFlag,decodeDim)
%函数SPIHTDECODING()是SPIHT算法的解码主程序
%输入参数:T ——初始阈值,T=2^N,N=floor(log2(max{
|c(i,j)|})),c(i,j)为小波系数矩阵的元素
% SnList ——排序扫描输出位流
% RnList ——精细扫描输出位流
% ini_L* ——初始系数(集合)表
% LSP:重要系数表
% LIP:不重要系数表
% LIS:不重要子集表,其中的表项是D型或L型表项的树根点
% LisFlag:LIS中各表项的类型,包括D型和L型两种
% decodeDim ——解码级数
%输出参数:DecodeMat ——解码后重构的小波系数矩阵
%
%由SPIHT算法原理的排序特点,解码器的执行程序与编码器的程序路径基本相同,只需把编码器程序中的
%输出信息改为输入,稍作修改即可得到解码器的程序代码
global rMat cMat
% rMat、cMat是Mat的行、列数,作为全局变量,在编码、解码的相关程序中使用
%-------------------------------------------%
% ----- Decoding Input Initialization ----- %
%-------------------------------------------%
N=log2(T);
%获取初始阈值的指数-N
DecodeMat=2^(N-decodeDim)*rand(rMat,cMat);
%初始化重构矩阵为一个随机矩阵,其元素最大值小于最高级解码阈值的二分之一
%这样就可以保证未被扫描赋值的区域有一定的灰度,避免重构图像出现色块
LSP=ini_LSP;
LIP=ini_LIP;
LIS=ini_LIS;
LisFlag=ini_LisFlag;
%将输入的各项列表存入相应的解码工作列表
%---------------------------%
% ----- Decoding Loop ----- %
%---------------------------%
for d=1:decodeDim
%-------------------------------------%
% ----- Decoding Initialization ----- %
%-------------------------------------%
[Sn,SnList]=getflow(SnList);
[Rn,RnList]=getflow(RnList);
%用GETFLOW()函数读取本级解码所需的位流信息
LSP_Old=LSP;
%列表LSP_Old用于存储上级解码产生的重要系数列表LSP,作为本级精细解码的输入
%--------------------------%
% ----- Sorting Pass ----- %
%--------------------------%
% ----- LIP Scan ----- %
%----------------------%
[DecodeMat,Sn,LSP,LIP]=lip_decode(DecodeMat,Sn,N,LSP,LIP);
%----------------------%
% ----- LIS Scan ----- %
%----------------------%
[LSP,LIP,LIS,LisFlag,DecodeMat,N]=lis_decode(DecodeMat,N,Sn,LSP,LIP,LIS,LisFlag);
%-----------------------------%
% ----- Refinement Pass ----- %
%-----------------------------%
DecodeMat=decRefine(DecodeMat,Rn,N+1,LSP_Old);
end
可以看出,解码程序和编码程序几乎是一样的,执行路径也相同。只不过解码器要对输入的扫描位流SnList、RnList进行分段读取,只读入本级解码所需的位流,下面给出位流信息读取程序:
(1)位流信息读取程序
function [flow,bitflow]=getflow(bitflow)
%函数GETFLOW()用于截取本级解码所需的位流信息
%输入参数:bitflow ——初始为编码器的输入位流,在解码过程中为上一级解码截取后剩余的编码位流
%输出参数:flow ——本级解码所需的位流(排序位流Sn、精细位流Rn)
% bitflow ——本级解码截取后剩余的编码位流
flow=[];
i=1;
while bitflow(i)~=7
flow(i)=bitflow(i);
i=i+1;
end
%数字‘7’作为位流区别符,区分不同编码级的位流
bitflow(1:i)=[];
%将对应于本级解码位流的bitflow数据清空
% bitflow被完全清空后返回一个空表值
if isempty(bitflow)
bitflow=[];
end
提示:任何排序算法的执行路径都是使用分支点的比较结果进行定义的。如果解码器和编码器使用相同的排序算法,则对于编码器输入的系数比较结果,解码器通过执行相同的路径就可获得排序信息。
所以,只需将编码器数学表述中的“输出”改为“输入”,解码器即可恢复数据的排序信息;在恢复数据排序信息的同时,解码器还要负责图像的重构,对于确认恢复的重要系数,通过排序扫描和精细扫描两个步骤更新系数的量化值,逐步提高逼近精度和重构图像的质量。
global rMat cMat
% rMat、cMat是Mat的行、列数,作为全局变量,在编码、解码的相关程序中使用
%读入当前LIS的表长
rlis=size(LIS,1);
% ls是指向LIS当前表项位置的指针,初始位置为1
ls=1;
while ls<=rlis
%读入当前LIS表项的类型
switch LisFlag(ls)
% ‘D’类表项,包含孩子和非直系子孙
case 'D'
%读入该表项的坐标值
rP=LIS(ls,1);
cP=LIS(ls,2);
%根据Sn判断该表项‘D’型子孙树是否重要
if Sn(1)==1
%每次判断都是读入Sn的首位数,判断后立即删除这一位数
Sn(1)=[];
%生成该表项的孩子树
chO=coef_DOL(rP,cP,'O');
%分别判断每个孩子的重要性
for r=1:4
%读入孩子的坐标值
rO=chO(r,1);
cO=chO(r,2);
%判断该孩子的重要性
if Sn(1)==1
Sn(1)=[];
%判断该孩子的正负符号
if Sn(1)==1
Sn(1)=[];
%生成该孩子的系数值
DecodeMat(rO,cO)=1.5*2^N;
else
Sn(1)=[];
DecodeMat(rO,cO)=-1.5*2^N;
end
%将该孩子添加到重要系数列表LSP
LSP=[LSP;chO(r,:)];
else
%如果不重要,则这个孩子的系数值为0
DecodeMat(rO,cO)=0;
Sn(1)=[];
%将该孩子添加到不重要系数列表LIP
%本级阈值下不重要的系数在下一级解码中可能是重要的
LIP=[LIP;chO(r,:)];
end
end
%生成该表项的非直系子孙树
chL=coef_DOL(rP,cP,'L');
if ~isempty(chL)
%如果‘L’型树非空,则将该表项添加到列表LIS的尾端等待扫描
LIS=[LIS;LIS(ls,:)];
%表项类型更改为‘L’型
LisFlag=[LisFlag,'L'];
%至此,该表项的‘D’型LIS扫描结束,在LIS中删除该项及其类型符
LIS(ls,:)=[];
LisFlag(ls)=[];
else
%如果‘L’型树为空集
%则该表项的‘D’型LIS扫描结束,在LIS中删除该项及其类型符
LIS(ls,:)=[];
LisFlag(ls)=[];
end
else
%如果该表项的‘D’型子孙树不重要,则先删除读入的Sn值
Sn(1)=[];
%然后将指针指向下一个LIS表项
ls=ls+1;
end
%更新当前LIS的表长,转入下一表项的扫描
rlis=size(LIS,1);
case 'L'
%对‘L’类表项,不需判断孩子的重要性
%读入该表项的坐标值
rP=LIS(ls,1);
cP=LIS(ls,2);
%判断该表项的‘L’型子孙树是否重要
if Sn(1)==1
%如果该子孙树重要
Sn(1)=[];
%则生成该表项的孩子树
chO=coef_DOL(rP,cP,'O');
%将该‘L’类表项从LIS中删除
LIS(ls,:)=[];
LisFlag(ls)=[];
%将表项的四个孩子添加到LIS的结尾,标记为‘D’类表项
LIS=[LIS;chO(1:4,:)];
LisFlag(end+1:end+4)='D';
else
%如果该表项的‘L’型子孙树不重要,则先删除读入的Sn值
Sn(1)=[];
%然后将指针指向下一个LIS表项
ls=ls+1;
end
%更新当前LIS的表长,转入下一表项的扫描
rlis=size(LIS,1);
end
end
%对LIS的扫描结束,将本级阈值的指数减1,准备进入下一级编码
N=N-1;
4、精细扫描解码程序
function DecodeMat=decRefine(DecodeMat,Rn,N,LSP_Old)
%函数DECREFINE()为精细解码程序,对上一级解码产生的重要系数列表LSP_Old,根据输入的
%精细位流Rn提高重要系数值的重构精度
%输入参数:DecodeMat ——经排序扫描解码后的重构系数矩阵
% Rn ——精细扫描输出位流
% N ——本级解码阈值的指数
% LSP_Old ——上一级解码产生的重要系数列表
%输出参数:DecodeMat ——提高重要系数精度后的重构矩阵
rlsp=size(LSP_Old,1);
if ~isempty(LSP_Old)
for r=1:rlsp
dMat=DecodeMat(LSP_Old(r,1),LSP_Old(r,2));
%首先读取重构矩阵中重要系数的值dMat
rMat=abs(dMat)+(-1)^(1+Rn(1))*2^(N-1);
%对dMat的绝对值,如果Rn = 1,则加上2^(N-1),否则减去2^(N-1),结果存入rMat
if dMat<=0
rMat=-rMat;
end
%如果dMat为负数,则rMat也转为负数
Rn(1)=[];
%消去所读取的Rn信息
DecodeMat(LSP_Old(r,1),LSP_Old(r,2))=rMat;
%将提高了精度的重要系数值返回重构矩阵中
end
end
四、LIP扫描解码程序
function [DecodeMat,Sn,LSP,LIP]=lip_decode(DecodeMat,Sn,N,LSP,LIP)
%函数LIP_DECODE()根据排序位流Sn,更新列表LIP、LSP和重构系数矩阵DecodeMat
%输入参数:DecodeMat ——上一级解码后生成的重构系数矩阵
% Sn ——本级解码排序位流
% N ——本级解码阈值的指数
% LSP ——上一级解码生成的重要系数列表
% LIP ——上一级解码生成的不重要系数列表
%输出参数:DecodeMat ——本级LIP扫描后更新的重构系数矩阵
% Sn ——对LIP列表扫描后更新的排序位流
% LSP ——对LIP列表扫描后更新的重要系数列表
% LIP ——本级LIP扫描后更新的不重要系数列表
rlip=size(LIP,1);
% r是指向LIP当前读入表项位置的指针
r=1;
%解码路径与编码路径基本一致,不过解码是根据排序位流Sn来判断系数是否重要
while r<=rlip
%读入当前表项的坐标值
rN=LIP(r,1);
cN=LIP(r,2);
%根据Sn判断该表项是否重要
%根据Sn的生成原理,每次判断都是读入Sn的首位数,判断后立即删除这一位数
if Sn(1)==1
%若Sn(1)=1,则表示当前表项是重要的
Sn(1)=[];
%读入后即删除该位Sn数据,使Sn(2)变为Sn(1),进入下一次判断
%这时的Sn(1)是正负符号位
if Sn(1)==1
% Sn(1)=1,则相应的系数为正数,其值为本级解码阈值的1.5倍
DecodeMat(rN,cN)=1.5*2^N;
Sn(1)=[];
else
% Sn(1)=0,则相应的系数为负数
DecodeMat(rN,cN)=-1.5*2^N;
Sn(1)=[];
end
%将该表项添加到重要系数列表LSP
LSP=[LSP;LIP(r,:)];
%将该表项从LIP中删除
LIP(r,:)=[];
else
%若不重要,则相应的系数值为0
DecodeMat(rN,cN)=0;
Sn(1)=[];
%将指针指向下一个表项
r=r+1;
end
%判断当前LIP的表长
rlip=size(LIP,1);
end
3、LIS扫描解码程序
function [LSP,LIP,LIS,LisFlag,DecodeMat,N]=lis_decode(DecodeMat,N,Sn,LSP,LIP,LIS,LisFlag)
%函数LIS_DECODE()根据排序位流Sn,更新列表LIP、LSP和重构系数矩阵DecodeMat
%输入参数:DecodeMat ——本级LIP扫描后更新的重构系数矩阵
% N ——本级解码阈值的指数
% Sn ——经本级LIP扫描截取后的排序位流
% LSP ——经本级LIP扫描后更新的重要系数列表
% LIP ——经本级LIP扫描后更新的不重要系数列表
% LIS ——上一级编码生成的不重要子集列表
% LisFlag ——上一级编码生成的不重要子集表项类型列表
%输出参数:LSP ——本级LIS扫描后更新的重要系数列表
% LIP ——经本级LIS扫描处理后更新的不重要系数列表
% LIS ——本级LIS扫描后更新的不重要子集列表
% LisFlag ——本级LIS扫描后更新的不重要子集表项类型列表
% DecodeMat ——本级LIS扫描后更新的重构系数矩阵
% N ——下一级解码阈值的指数
现在我们分别用一幅1616的Lena局部图像和一幅6464的Girl局部图像来查看SPIHT算法的编码过程和解码效果。
五、编码过程演示
这里我们使用的源图像是一幅16*16的Lena眼睛局部图像,其源图像和3级小波分解如下图所示:

图1
3级分解的小波系数矩阵为:
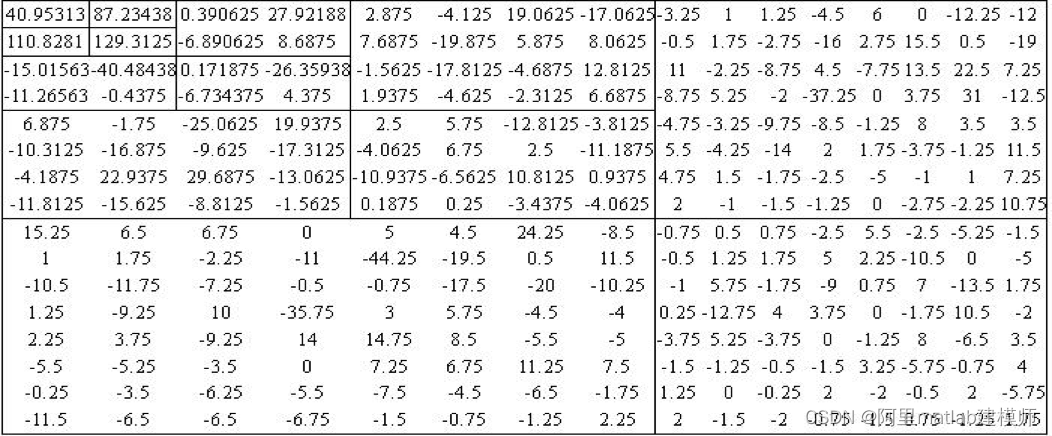
利用SPIHT编码算法对图像进行3级编码和3级解码后,输出如下结果:
N = 7 %初始阈值指数
T = 128 %初始阈值
ini_LSP = [] %初始重要系数列表
ini_LIP = %初始不重要系数列表
1 1
1 2
2 1
2 2
1 3
1 4
2 3
2 4
3 1
3 2
4 1
4 2
3 3
3 4
4 3
4 4
ini_LIS = %初始不重要子集列表
1 3
1 4
2 3
2 4
3 1
3 2
4 1
4 2
3 3
3 4
4 3
4 4
ini_LisFlag = DDDDDDDDDDDD %初始不重要子集列表中各表项的类型
codeLevel = 1 %第一级编码
Threshold = 128 %第一级编码的阈值
SnL = %第一级编码输出的排序扫描位流和精细扫描位流
0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7
RnL =
7
codeLevel = 2 %第二级编码
Threshold = 64 %第二级编码的阈值
SnL = %第二级编码输出的排序扫描位流和精细扫描位流
0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7
RnL =
7 0 7
codeLevel = 3 %第三级编码
Threshold = 32 %第三级编码的阈值
SnL = %第三级编码输出的排序扫描位流和精细扫描位流
0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 1 0 1 0 0 1 0 0 0 0 0 7
RnL =
7 0 7 0 0 1 7
RecImMat = % 3级解码后重构的小波系数矩阵
可以看到,3级解码后重构的小波系数矩阵大部分区域都是未被扫描赋值的随机数,所以要进行更高级的编码和解码,才能获得高质量的重构图像。
对源图像再进行7级编码和7级解码,我们看一下图像重构效果如何:
RecImMat = % 7级解码后重构的小波系数矩阵
可见,7级解码后系数矩阵大部分元素都被扫描赋值了,只剩下一个2*2的区域低于解码阈值而未被扫描,但由于初始的重构矩阵是一个元素最大值小于最高级解码阈值的二分之一的随机矩阵,这就保证了重构图像尽可能平滑地恢复,而不会出现区域色块。
2、运行时间
下面,我们通过一幅64*64的Girl图像来看看程序的运行时间和重构效果。
图像分解级数:3
SPIHT编码级数:7
SPIHT解码级数:7
(1)主程序代码如下:
function RecIm=spiht(Im,imDim,codeDim,decodeDim)
global rMat cMat
strtime=cputime;
[rMat,cMat]=size(Im);
% ----- Image Wavedec ----- %
DecIm=mywavedec2(Im,imDim);
% ----- SPIHT Coding ----- %
[T,SnList,RnList,ini_LSP,ini_LIP,ini_LIS,ini_LisFlag]=spihtcoding(DecIm,imDim,codeDim);
% ----- SPIHT Decoding ----- %
DecodeMat=spihtdecoding(T,SnList,RnList,ini_LSP,ini_LIP,ini_LIS,ini_LisFlag,decodeDim);
% ----- Waverec -----%
m=2^imDim;
DecImLL=DecIm(1:rMat/m,1:cMat/m)
DecodeLL=DecodeMat(1:rMat/m,1:cMat/m)
%显示小波分解系数矩阵和重构系数矩阵在LL_N分解级的数据,比较重构效果
RecIm=mywaverec2(DecodeMat,imDim,decodeDim);
Runtime=cputime-strtime
(2)小波分解系数矩阵和重构系数矩阵的LL_N分解级的数据,比较重构效果
DecImLL =
67.0625 106.3750 117.5625 130.3125 110.0000 75.6875 82.6875 65.6250
61.5000 50.7500 61.9375 127.0000 104.6875 67.8125 43.2500 36.8750
69.3750 117.4375 121.5625 146.7500 123.0625 123.4375 90.9375 92.1250
76.9375 153.5000 151.0625 143.3750 111.2500 150.3125 143.3750 124.8125
69.8750 135.8750 117.9375 106.4375 85.8750 133.1250 138.6875 116.5625
54.2500 94.8750 99.2500 117.9375 118.1250 104.3125 102.0625 88.2500
56.2500 75.5625 126.6875 129.4375 119.9375 89.8750 112.0625 83.2500
74.5000 45.7500 101.3125 133.0000 124.8125 116.1875 105.0000 77.0000
DecodeLL =
67 107 117 131 111 75 83 65
61 51 61 127 105 67 43 37
69 117 121 147 123 123 91 93
77 153 151 143 111 151 143 125
69 135 117 107 85 133 139 117
55 95 99 117 119 105 103 89
57 75 127 129 119 89 113 83
75 45 101 133 125 117 105 77
(3)运行时间
Runtime = 8.0625
最后,我们再看看对普通的256*256图像,程序运行效果如何。同样是3级小波分解、7级编码、7级解码。
Runtime = 484.8125