【mmaction2 slowfast 行为分析(商用级别)】总目录
目录
一,ffmpeg视频转图片帧
这个很简单,怎么安装ffmpeg各位自己查。
ffmpeg -i ./v/3.mp4 -vf fps=4 ./frame/3/%3d.jpg
将v文件下的3.mp4视频,按照每秒4帧的方式裁剪,得到的图片保留在:/frame/3/当中
二,faster cnn检测图片并转化为via格式
python ./mywork/detection2_outvia3.py /home/lxn/0yangfan/mmaction/JN-OpenLib-mmaction2/mywork/faster_rcnn_r50_fpn_2x_coco.py /home/lxn/0yangfan/mmaction/JN-OpenLib-mmaction2/Checkpionts/mmdetection/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth --input ./Datasets/Interaction/images/train/*/*.jpg --gen_via3 --output ./Datasets/Interaction/annotations_proposal/ --score-thr 0.5 --show
这个代码有点长。
首先,当然是要进入项目:JN-OpenLib-mmaction2当中,进入到项目目录中。
./mywork/detection2_outvia3.py
是核心代码,后面会有专门的解释
/home/lxn/0yangfan/mmaction/JN-OpenLib-mmaction2/mywork/faster_rcnn_r50_fpn_2x_coco.py
是配置文件的位置,用的绝对地址
/home/lxn/0yangfan/mmaction/JN-OpenLib-mmaction2/Checkpionts/mmdetection/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth
是模型权重位置,用的绝对位置
–input ./Datasets/Interaction/images/train//.jpg --gen_via3 --output ./Datasets/Interaction/annotations_proposal/
输入和输出文件的地址。
–score-thr 0.5
识别为人的阈值设置为0.5
三,via中的json格式
来自:Structure of VIA Project JSON File

{
"project": {
# ["project"] contains all metadata associated with this VIA project
"pid": "__VIA_PROJECT_ID__", # uniquely identifies a shared project (DO NOT CHANGE)
"rev": "__VIA_PROJECT_REV_ID__", # project version number starting form 1 (DO NOT CHANGE)
"rev_timestamp": "__VIA_PROJECT_REV_TIMESTAMP__", # commit timestamp for last revision (DO NOT CHANGE)
"pname": "VIA3 Sample Project", # Descriptive name of VIA project (shown in top left corner of VIA application)
"creator": "VGG Image Annotator (http://www.robots.ox.ac.uk/~vgg/software/via)",
"created": 1588343615019, # timestamp recording the creation date/time of this project (not important)
"vid_list": ["1", "2"] # selects the views that are visible to the user for manual annotation (see ["view"])
},
"config": {
# Configurations and user settings (used to modify behaviour and apperance of VIA application)
"file": {
"loc_prefix": {
# a prefix automatically appended to each file 'src' attribute. Leave it blank if you don't understand it. See https://gitlab.com/vgg/via/-/blob/master/via-3.x.y/src/js/_via_file.js
"1": "", # appended to files added using browser's file selector (NOT USED YET)
"2": "", # appended to remote files (e.g. http://images.google.com/...)
"3": "", # appended to local files (e.g. /home/tlm/data/videos)
"4": "" # appended to files added as inline (NOT USED YET)
}
},
"ui": {
"file_content_align": "center",
"file_metadata_editor_visible": true,
"spatial_metadata_editor_visible": true,
"spatial_region_label_attribute_id": ""
}
},
"attribute": {
# defines the things that a human annotator will describe and define for images, audio and video.
"1": {
# attribute-id (unique)
"aname":"Activity", # attribute name (shown to the user)
"anchor_id":"FILE1_Z2_XY0", # FILE1_Z2_XY0 denotes that this attribute define a temporal segment of a video file. See https://gitlab.com/vgg/via/-/blob/master/via-3.x.y/src/js/_via_attribute.js
"type":4, # attributes's user input type ('TEXT':1, 'CHECKBOX':2, 'RADIO':3, 'SELECT':4, 'IMAGE':5 )
"desc":"Activity", # (NOT USED YET)
"options":{
"1":"Break Egg", "2":"Pour Liquid", "3":"Cut Garlic", "4":"Mix"}, # defines KEY:VALUE pairs and VALUE is shown as options of dropdown menu or radio button list
"default_option_id":""
},
"2": {
"aname":"Object",
"anchor_id":"FILE1_Z1_XY1", # FILE1_Z1_XY1 denotes attribute of a spatial region (e.g. rectangular region) in a video frame. See https://gitlab.com/vgg/via/-/blob/master/via-3.x.y/src/js/_via_attribute.js
"type":1, # an attribute with text input
"desc":"Name of Object",
"options":{
}, # no options required as it has a text input
"default_option_id":""
}
},
"file": {
# define the files (image, audio, video) used in this project
"1":{
# unique file identifier
"fid":1, # unique file identifier (same as above)
"fname":"Alioli.ogv", # file name (shown to the user, no other use)
"type":4, # file type { IMAGE:2, VIDEO:4, AUDIO:8 }
"loc":2, # file location { LOCAL:1, URIHTTP:2, URIFILE:3, INLINE:4 }
"src":"https://upload.wikimedia.org/wikipedia/commons/4/47/Alioli.ogv" # file content is fetched from this location (VERY IMPORTANT)
},
"2":{
"fid":2,
"fname":"mouse.mp4",
"type":4,
"loc":3, # a file residing in local disk (i.e. file system)
"src":"/home/tlm/data/svt/mouse.mp4"
}
},
"view": {
# defines views, users see the "view" and not file, each view contains a set of files that is shown to the user
"1": {
# unique view identifier
"fid_list":[1] # this view shows a single file with file-id of 1 (which is the Alioli.ogv video file)
},
"2": {
"fid_list":[2] # this view also shows a single video file (but a view can contain more than 1 files)
}
},
"metadata": {
# a set of all metadata define using the VIA application
"-glfwaaX": {
# a unique metadata identifier
"vid": "1", # view to which this metadata is attached to
"flg": 0, # NOT USED YET
"z": [2, 6.5], # z defines temporal location in audio or video, here it records a temporal segment from 2 sec. to 6.5 sec.
"xy": [], # xy defines spatial location (e.g. bounding box), here it is empty
"av": {
# defines the value of each attribute for this (z, xy) combination
"1":"1" # the value for attribute-id="1" is one of its option with id "1" (i.e. Activity = Break Egg)
}
},
"+mHHT-tg": {
"vid": "1",
"flg": 0,
"z": [9, 20],
"xy": [],
"av": {
"1":"2" # the value for attribute-id="1" is one of its option with id "2" (i.e. Activity = Pour Liquid)
}
},
"ed+wsOZZ": {
"vid": "1",
"flg": 0,
"z": [24, 26],
"xy": [],
"av": {
"1":"2"
}
},
"fH-oMre1": {
"vid": "1",
"flg": 0,
"z": [0.917], # defines the video frame at 0.917 sec.
"xy": [2, 263, 184, 17, 13], # defines a rectangular region at (263,184) of size (17,13). The first number "2" denotes a rectangular region. Other possible region shapes are: { 'POINT':1, 'RECTANGLE':2, 'CIRCLE':3, 'ELLIPSE':4, 'LINE':5, 'POLYLINE':6, 'POLYGON':7, 'EXTREME_RECTANGLE': 8, 'EXTREME_CIRCLE':9 }
"av": {
"2":"Egg" # the value of attribute-id "2" is "Egg" (i.e. Object = Egg)
}
}
}
}
四,核心代码解析
4.1 detection2_outvia3.py代码关键处解析
位置:/JN-OpenLib-mmaction2/mywork/detection2_outvia3.py
import argparse
import glob
import cv2
import mmcv
import os
from mmdet.apis import inference_detector, init_detector
import numpy as np
from collections import defaultdict
from mywork.via3_tool import Via3Json
from tqdm import tqdm
from colorama import Fore
def parse_args():
parser = argparse.ArgumentParser(description='MMDetection video demo')
parser.add_argument('config', help='Config file')
parser.add_argument('checkpoint', help='Checkpoint file')
parser.add_argument(
'--input',
nargs='+',
help='A list of space separated input images; '
'or a single glob pattern such as directory/*.jpg or directory/*.mp4',
)
parser.add_argument('--gen_via3', action='store_true', help='generate via3 files for images or videos.' )
parser.add_argument('--output', default='output',help='output directory')
parser.add_argument(
'--device', default='cuda:0', help='Device used for inference')
parser.add_argument(
'--score-thr', type=float, default=0.3, help='Bbox score threshold')
parser.add_argument('--out', type=str, help='Output video file')
parser.add_argument('--show', action='store_true', help='Show video')
parser.add_argument(
'--wait-time',
type=float,
default=1,
help='The interval of show (s), 0 is block')
args = parser.parse_args()
return args
def process_image(model, image_path, output):
results = inference_detector(model, image_path)
return results[0]
def process_video(model, video_path, output):
pass
def main():
args = parse_args()
assert args.out or args.show, \
('Please specify at least one operation (save/show the '
'video) with the argument "--out" or "--show"')
#args.input ['./Datasets/Interaction/images/train/*/*.jpg']
# len(args.input) 821
if len(args.input) == 1:
#不会进入这里,train下面有2个文件
args.input = glob.glob(os.path.expanduser(args.input[0]))
args.input.sort()
assert args.input, "The input path(s) was not found"
#初始化检测模型
model = init_detector(args.config, args.checkpoint, device=args.device)
if len(args.input) == 1:
#也不会进入这里
args.input = glob.glob(os.path.expanduser(args.input[0]))
assert args.input, "The input path(s) was not found"
images_results_dict = defaultdict(list)
videos_results_dict = defaultdict(list)
# images_results_dict defaultdict(<class 'list'>, {})
# videos_results_dict defaultdict(<class 'list'>, {})
for file_path in tqdm(args.input, bar_format='{l_bar}%s{bar}%s{r_bar}' % (Fore.BLUE, Fore.RESET)):
# file_path ./Datasets/Interaction/images/train/2/001.jpg
# 加载一个个的图片
extension = os.path.splitext(file_path)[-1]
if extension in ['.png', '.jpg', '.bmp', 'tif', 'gif']:
file_dir, file_name = os.path.split(file_path)
results = process_image(model, file_path, args.output)
results = results[results[:, 4] > args.score_thr]
results[:,[2,3]]= results[:,[2,3]] - results[:,[0,1]]
images_results_dict[file_dir].append((file_name, results))
#images_results_dict defaultdict(<class 'list'>, {'./Datasets/Interaction/images/train/2': [('001.jpg', array([[401.9775 , 138.73132 , 307.38522 , 411.7107 ,0.99856526]], dtype=float32)), ('002.jpg', array([[401.1002 , 140.16426 , 308.95303 , 413.97455 , 0.9984402]], dtype=float32)), ('003.jpg', array([[399.90347 , 140.76791 , 310.91885 , 423.98422 , 0.9988949]], dtype=float32))]})
#这里就是将图片挨个丢入检测网络模型中,然后返回人的坐标值
elif extension in ['.mp4', '.avi', '.wmv']:
result = process_video(model, file_path, args.output)
else:
print('不能处理 {} 格式的文件, {}'.format(extension,file_path))
continue
for images_dir in images_results_dict:
print("images_dir",images_dir)
#images_dir ./Datasets/Interaction/images/train/2
#images_dir ./Datasets/Interaction/images/train/3
#这里是循环创建文件,train下的每个文件的所有图片的检测结果,保存在一个***_proposal.json中
images_results = images_results_dict[images_dir]
if args.output:
json_path = os.path.join(args.output, os.path.basename(images_dir) + '_proposal.json')
else:
json_path = os.path.join(images_dir, os.path.basename(images_dir)+'_proposal.json')
num_images = len(images_results)
via3 = Via3Json(json_path, mode='dump')
vid_list = list(map(str,range(1, num_images+1)))
via3.dumpPrejects(vid_list)
via3.dumpConfigs()
'''
attributes_dict = {'1':dict(aname='person', type=2, options={'0':'None',
'1':'handshake', '2':'point', '3':'hug', '4':'push',
'5':'kick', '6':'punch'},default_option_id='0', anchor_id = 'FILE1_Z0_XY1'),
'2': dict(aname='modify', type=4, options={'0': 'False',
'1': 'Ture'}, default_option_id='0',anchor_id='FILE1_Z0_XY0')}
'''
attributes_dict = {
'1':dict(aname='person', type=2, options={
'0':'sit',
'1':'writingReading', '2':'turnHeadTurnBody', '3':'playPhone', '4':'bendOverDesk',
'5':'handUP', '6':'stand', '7':'talk'},default_option_id='0', anchor_id = 'FILE1_Z0_XY1'),
'2': dict(aname='modify', type=4, options={
'0': 'False',
'1': 'Ture'}, default_option_id='0',anchor_id='FILE1_Z0_XY0')}
via3.dumpAttributes(attributes_dict)
files_dict, metadatas_dict = {
},{
}
for image_id, (file_name, results) in enumerate(images_results,1):
files_dict[str(image_id)] = dict(fname=file_name, type=2)
for vid, result in enumerate(results,1):
metadata_dict = dict(vid=str(image_id),
xy=[2, float(result[0]), float(result[1]), float(result[2]), float(result[3])],
av={
'1': '0'})
#metadata_dict = dict(vid=vid, xy=[2], av={'1':'0'})
metadatas_dict['image{}_{}'.format(image_id,vid)] = metadata_dict
via3.dumpFiles(files_dict)
via3.dumpMetedatas(metadatas_dict)
views_dict = {
}
for i, vid in enumerate(vid_list,1):
views_dict[vid] = defaultdict(list)
views_dict[vid]['fid_list'].append(str(i))
via3.dumpViews(views_dict)
via3.dempJsonSave()
if __name__ == '__main__':
main()
4.2 detection2_outvia3.py 模型的初始化代码追踪
/JN-OpenLib-mmaction2/mywork/中的detection2_outvia3.py
调用了init_detector

/JN-OpenLib-mmaction2/mmdet/apis/中的inference.py
调用了init_detector

/JN-OpenLib-mmaction2/mmdet/models/中的builder.py
调用了build_detector
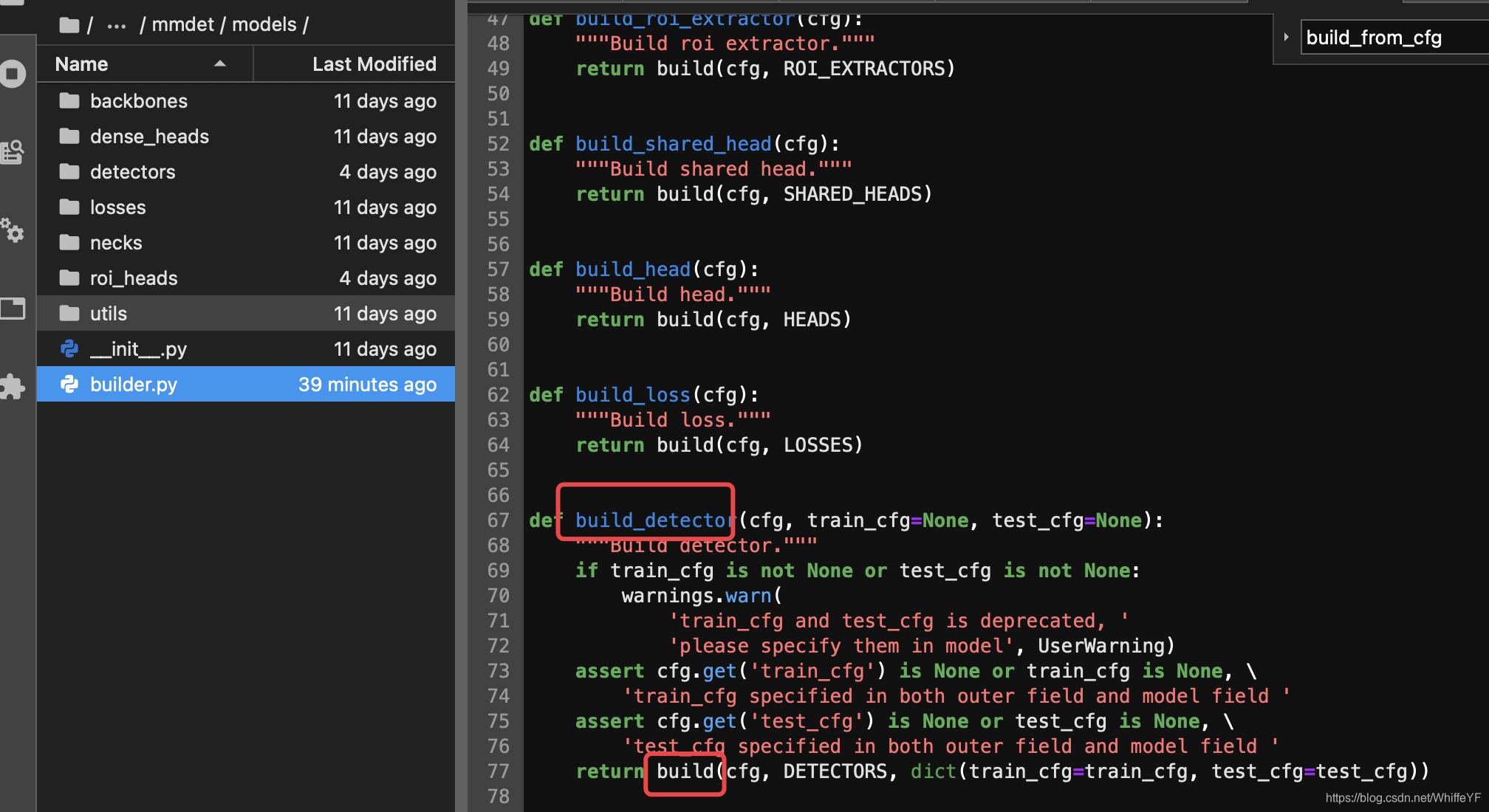
调用了build

/anaconda3/envs/JN-OpenLib-mmaction2-pytorch1.6-py3.6/lib/python3.6/site-packages/mmcv/utils中的registry.py
build_from_cfg这个函数在这个项目中多次被调用

最后补充一个,关于faster rcnn参数的解释,别人的博客:
faster_rcnn_r50_fpn_1x.py配置文件