github mmaction2 官网:https://github.com/open-mmlab/mmaction2
github mmaction2 ava数据集制作流程:https://github.com/open-mmlab/mmaction2/blob/master/tools/data/ava/README.md
b站视频:https://www.bilibili.com/video/BV1yL411c7pR?spm_id_from=333.999.0.0
AI平台:https://cloud.videojj.com/auth/register?inviter=18452&activityChannel=student_invite
目录
0 前言
ava 数据可视化 目的在于更直观看出ava数据集的结构,注意,这篇博客只是做人的检测框与ID的可视化。
1 mmaction2 安装
1.1 安装
在AI平台中选择如下版本镜像:

安装命令如下:
cd home
git clone https://gitee.com/YFwinston/mmaction2.git
pip install mmcv-full==1.3.17 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8.0/index.html
pip install opencv-python-headless==4.1.2.30
cd mmaction2
pip install -r requirements/build.txt
pip install -v -e .
1.2 测试
python tools/test.py configs/recognition/tsn/tsn_r50_1x1x3_100e_kinetics400_rgb.py \
checkpoints/SOME_CHECKPOINT.pth \
--eval top_k_accuracy mean_class_accuracy
3 ava数据集标注文件与修改
3.1 ava标注文件
由于ava数据集过于庞大,普通电脑并不能承受这么大的数据集,所以我们需要将数据集修剪的更小。
在AI平台中,有ava数据集的标注文件(/datasets/ava/ava_actions_v2.2/ava_train_v2.2.csv):
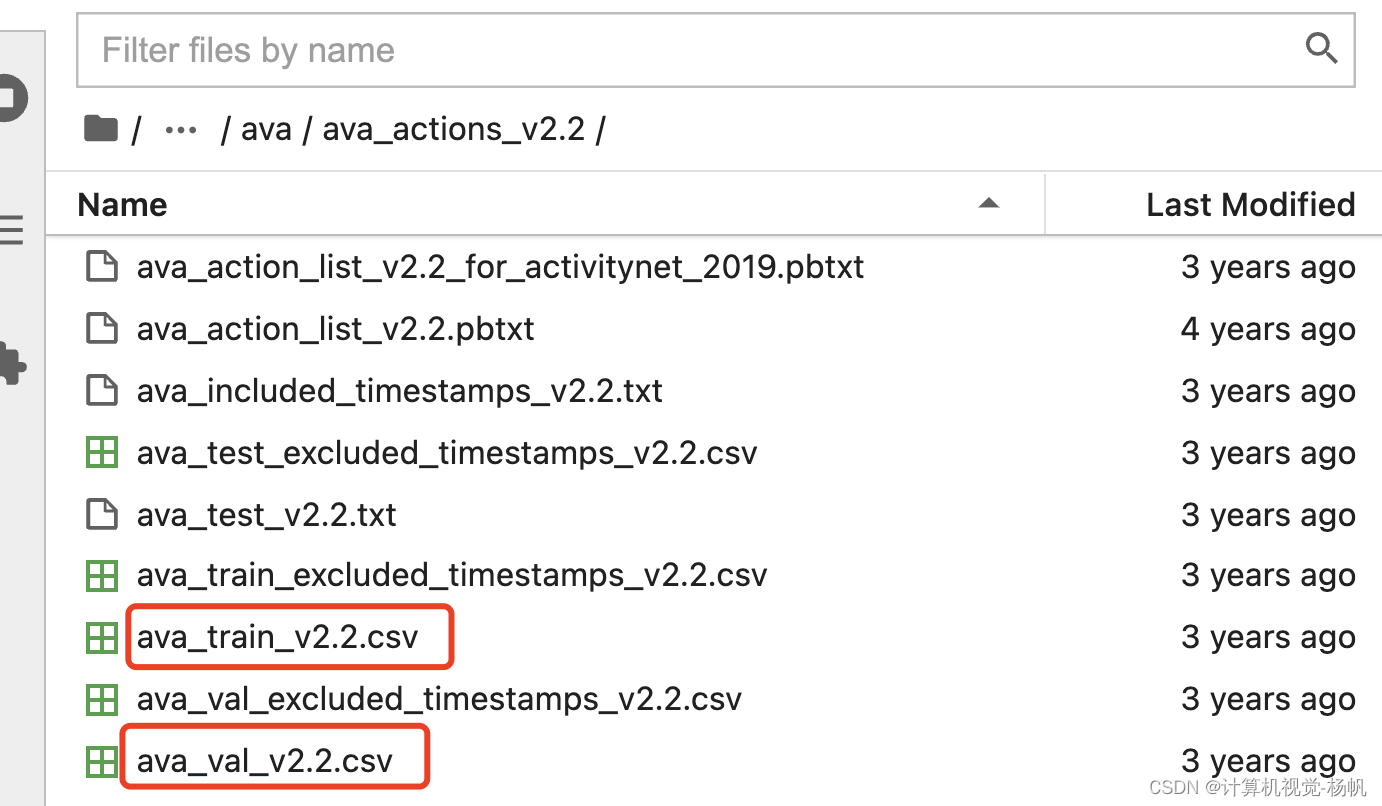
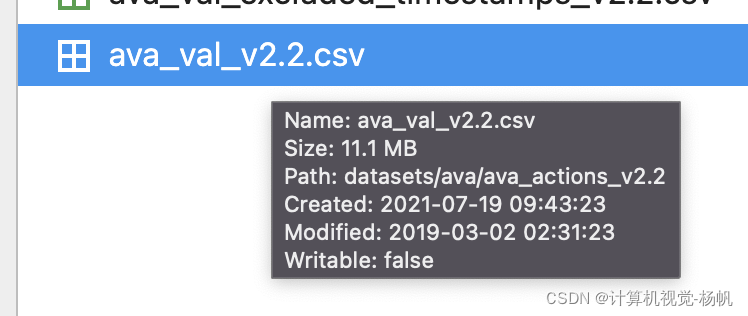
下面的图是训练标注文件与测试标注文件的大小,训练文件39.2MB,测试文件11.1MB,这明显是非常巨大的。

3.2 ava标注文件自定义
我们需要将这样的标注文件缩小,只要我们想要的部分,下面的代码为创建缩小版ava数据集:
import csv
# videos存放从 ava_train_v2.2.csv 截取对应视频标注的 视频名字
videos = ["_a9SWtcaNj8", "_Ca3gOdOHxU", "_dBTTYDRdRQ", "_eBah6c5kyA", "_ithRWANKB0", "_mAfwH6i90E", "_-Z6wFjXtGQ", "-5KQ66BBWC4", "_7oWZq_s_Sk"]
# minCsv 用以存放缩小版的ava数据集的标注内容
minCsv = []
with open('ava_train_v2.2.csv', 'r') as db01:
reader = csv.reader(db01)
for row in reader:
for video in videos:
if video in row:
minCsv.append(row)
with open('ava_train_v2.2_mini.csv',"w") as csvfile:
writer = csv.writer(csvfile)
writer.writerows(minCsv)
4 ava数据集视频下载
4.1 本地下载
由于ava数据集过于庞大,我这里就找了9个视频进行可视化,这9个视频先下载到自己的本地。
9个视频的链接如下(下载方法可以参考:【ava数据集】ava数据集下载 使用迅雷)
https://s3.amazonaws.com/ava-dataset/trainval/_-Z6wFjXtGQ.mkv
https://s3.amazonaws.com/ava-dataset/trainval/_7oWZq_s_Sk.mkv
https://s3.amazonaws.com/ava-dataset/trainval/_a9SWtcaNj8.mkv
https://s3.amazonaws.com/ava-dataset/trainval/_Ca3gOdOHxU.mp4
https://s3.amazonaws.com/ava-dataset/trainval/_dBTTYDRdRQ.webm
https://s3.amazonaws.com/ava-dataset/trainval/_eBah6c5kyA.mkv
https://s3.amazonaws.com/ava-dataset/trainval/_ithRWANKB0.mp4
https://s3.amazonaws.com/ava-dataset/trainval/_mAfwH6i90E.mkv
https://s3.amazonaws.com/ava-dataset/trainval/-5KQ66BBWC4.mkv
4.2 数据集上传
数据集需要压缩后才能上传到AI平台,数据上传方法请查看:AI平台的数据管理
注意需要在AI平台的数据管理中创建avaData这个文件夹哦
我输入的上传命令如下:
./vcloud-oss-cli up E:/杨帆/ava数据集/1.zip /avaData/1.zip

4.3 数据集解压
上传后,进入AI平台
在终端中,进入:/user-data/avaData
解压1.zip
unzip 1.zip
然后在 /user-data 下创建 /user-data/avaData/videos 文件夹,然后将解压的文件夹放入到 /user-data/avaData/videos 下面去
除此之外,还需要在 /user-data/avaData下创建:videos_15minr、awframes两个文件夹
5 创建软连接
什么是软连接?软连接的作用?
当我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在其它的 目录下用ln命令链接(link)就可以,不必重复的占用磁盘空间。
也就是说,我们在使用AI平台的时候,不需要将/user-data 中的数据复制到 /home/mmaction2/data/ava 当中,而是创建一个软连接,操作如下:
格式:ln -s 源地址 目的地址
ln -s /user-data/avaData/videos /home/mmaction2/data/ava
ln -s /user-data/avaData/videos_15min /home/mmaction2/data/ava
ln -s /user-data/avaData/rawframes /home/mmaction2/data/ava
6 数据集中视频裁剪
视频并不是能全部时间段都要用,只有第15分钟到第30分钟才能用,这就需要再新建一个文件夹:videos_15min
mmaction2中有裁剪视频的代码
进入:/home/mmaction2/tools/data/ava/
终端输入:
bash cut_videos.sh
7 数据集中视频裁剪为帧
在ava数据集训练中,输入的神经网络中的是多张图片,而不是一个视频,所以这一步是将视频裁剪为帧。
在终端输入:
bash extract_rgb_frames_ffmpeg.sh
8 数据集可视化
这是这篇博客最关键的一步,前面做了那么多的铺垫,目的就是为了让ava数据集可视化。
代码如下(只是可视化9个视频中的一个,如果需要可视化其余的视频,修改对应的视频名字即可,另外,这个只是人的检测框与ID的可视化):
import cv2
import matplotlib.pyplot as plt
import csv
import os
import time
path1 = './rawframes/'
tempNum = ''
tempOutPath = ''
font = cv2.FONT_HERSHEY_SIMPLEX
color = (255, 0, 0)
thickness = 2
with open('annotations/ava_train_v2.2_mini.csv', 'r') as avaData:
reader = csv.reader(avaData)
for row in reader:
if tempNum == row[1]:
path2 = tempOutPath
else:
tempNum = row[1]
num = str((int(row[1]) - 900) * 30 + 1)
#print("num",num)
num = num.zfill(5)
path2 = path1 + row[0] + '/img_' + num + '.jpg'
image = cv2.imread(path2)
sp = image.shape
h = sp[0]
w = sp[1]
x1 = int( float(row[2]) * w )
y1 = int( float(row[3]) * h )
x2 = int( float(row[4]) * w )
y2 = int( float(row[5]) * h )
start_point = (x1,y1)
end_point = (x2,y2)
image = cv2.rectangle(image, start_point, end_point, color, thickness)
image = cv2.putText(image, row[7], (x1, y1+15), font, 1, (255, 255, 255), 1)
tempOutPath = './out/' + row[0] + '/img_' + num + '.jpg'
cv2.imwrite(tempOutPath, image)
if row[0] != '-5KQ66BBWC4':
break
#### 图片合成视频
def picvideo(path):
filelist = os.listdir(path) # 获取该目录下的所有文件名
#filelist.sort(key=lambda x: int(x[4:-4])) ##文件名按数字排序
'''
fps:
帧率:1秒钟有n张图片写进去[控制一张图片停留5秒钟,那就是帧率为1,重复播放这张图片5次]
如果文件夹下有50张 534*300的图片,这里设置1秒钟播放5张,那么这个视频的时长就是10秒
'''
fps = 10
file_path = r"./outVideo/5KQ66BBWC4.mp4" # 导出路径
fourcc = cv2.VideoWriter_fourcc('D', 'I', 'V', 'X') # 不同视频编码对应不同视频格式(例:'I','4','2','0' 对应avi格式)
image = cv2.imread(path + '/img_00060.jpg')
sp = image.shape
size = (sp[1],sp[0])
print(size)
video = cv2.VideoWriter(file_path, cv2.VideoWriter_fourcc(*'mp4v'), 2, size)
print("file_path",file_path)
for item in filelist:
if item.endswith('.jpg'): # 判断图片后缀是否是.png
item = path + item
img = cv2.imread(item) # 使用opencv读取图像,直接返回numpy.ndarray 对象,通道顺序为BGR ,注意是BGR,通道值默认范围0-255。
video.write(img) # 把图片写进视频
video.release() # 释放
picvideo(r'./out/-5KQ66BBWC4/')
