写在前面
系列汇总:一天上手Aurora 8B/10B IP核----汇总篇(直达链接)
1、Aurora 8B/10B 协议
Aurora 协议是一个用于在点对点串行链路间移动数据的可扩展轻量级链路层协议(由Xilinx开发提供)。这为物理层提供透明接口,让专有协议或业界标准协议上层能方便地使用高速收发器。Aurora协议在Xilinx的FPGA上有两种实现方式:8B/10B 与 64B/10B。两个协议大部分相同,主要区别在编码方式上:
- Aurora 8B/10B:将8bit数据编码成10bit数码进行传输,尽量平衡数据中“0”和“1”的个数以实现DC平衡,显然这个编码方式的开销是20%,也就是效率为80%
- Aurora 64B/10B:将64bit数据编码成66bit块传输,66bit块的前两位表示同步头,主要由于接收端的数据对齐和接收数据位流的同步。同步头有“01”和“10”两种,“01“表示后面的64bit都是数据,“10”表示后面的64bit是数据信息。数据信息0和1不一定是平衡的,因此需要进行加扰,开销较小
Aurora 8B/10B 常用于芯片(FPGA)与芯片(FPGA)之间通信。它用于使用一个或多个收发器在设备之间传输数据。连接可以是全双工(双向数据)或单工。最多可实现16个收发器(GTX,GTP或GTH),吞吐量可从480 Mb / s扩展到84.48 Gb / s。Aurora核心吞吐量取决于收发器的数量以及所选收发器的线路速率。 通过使用25%的开销来计算吞吐量Aurora 8B / 10B协议编码和以及线速0.5 Gb / s至6.6 Gb / s的线速范围来计算,其传输吞吐量为从单通道设计的0.4 Gb / s到最高16通道的84.48 Gb / s。
下图是一个典型的使用两个全双工模式、多条lane构成的Aurora 8B/10B 通信系统。

从上图不难看出:
- 用户使用用户接口与Aurora 8B/10B IP核进行数据交互
- Aurora 8B/10B IP核是全双工模式,其数据通路由多条Lane组成
- 发送的数据通过Aurora IP核进行8B/10B编码后,通过多条Lane发送到另一个Aurora IP核,该IP核通过用户接口将接收到的数据发送给用户
2、Aurora 8B/10B IP核
2.1、IP核组成
接下来我们看一下Aurora 8B/10B IP核的组成:

主要组成部分如下:
- Lane Logic(通道逻辑):每个GT收发器由通道逻辑模块的实例驱动,其初始化每个单独的收发器并处理控制字符的编码和解码以及错误检测。
- Global Logic(全局逻辑):全局逻辑模块执行通道初始化的绑定和验证。 在运行期间,模块会生成Aurora协议所需的随机空闲字符,并监视所有通道逻辑模块的错误。
- RX User Interface(RX接收端口):AXI4-Stream RX接收端口将数据从通道移动到应用程序,并执行流量控制功能。
- TX User Interface(TX发送端口):AXI4-Stream TX发送端口将数据从应用程序移动到通道,并执行流量控制TX功能。 标准时钟补偿模块嵌入在内核中。 该模块控制时钟补偿(CC)字符的周期性传输。
看到这里基本就清楚了:Aurora 8B/10B是一个基于GT高速收发器(物理层)的全双工点到点协议,GT高速收发器的每个Channel就是Aurora协议的一条Lane。
下图是IP核的顶层结构示意图,更好的说明了该IP核与GT高速收发器的关系。

2.2、延迟(Latency)
由于Aurora 8B/10B IP核的逻辑设计(流水线、编解码等),用户端发送给IP核的数据,需要一定的延迟才能通过IP核发送。这一延迟的近似值为37(2字节位宽)和41(4字节位宽),如下图所示:

2.3、Throughput(吞吐率):
Aurora 8B/10B IP核吞吐率取决于GT收发器的数量和线速率。 单通道设计到16通道设计的吞吐率分别为0.4Gb/s到84.48Gb/s。 通过Aurora 8B/10B协议编码和0.5Gb/s至6.6 Gb/s线路速率范围的20%开销来计算吞吐率。
也就是说,使用的GT高速收发器的通道越多、且其支持的线速率越高,则整个Aurora 8B/10B IP核的吞吐率越高,但是要注意乘以80%,因为8B/10B编码存在20%的开销。
2.4、大小端
在IP核的定制中,有一个大小端的选择问题。所谓的小端,就是我们最常见的多位数据定义方式:[n:0] 左边是高位,右边是低位,符合Verilog编写习惯,大端反之。
2.5、数据发送、接收接口
Aurora 8B/10B IP核支持AXI4-Stream协议,并依据是否对AXI4-Stream协议进行再封装来提供两种数据传输接口:Framing 接口(帧传输接口)和Streaming接口(流传输接口)。
- Framing接口(帧传输接口):在AXI4-Stream的基础上添加了帧头、帧尾等控制信号,使得传输更准确,但是会降低传输效率和使用较多资源
- Streaming接口(流传输接口):基本上就是一个非常简化的AXI4-Stream接口,只有数据有效、握手和数据信号,此种方式传输效率高,但无法保证传输的准确性
关于AXI4-Stream协议可以参考:带你快速入门AXI4总线--汇总篇(直达链接)
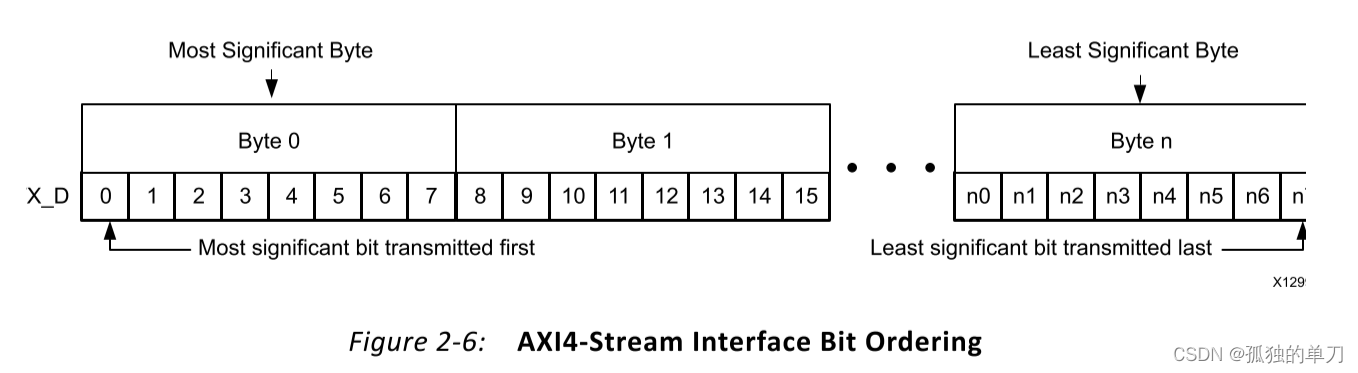
2.5.1、AXI4-Stream位排序(AXI4-Stream Bit Ordering):
Aurora 8B / 10B IP核采用升序排列。 首先发送和接收最高有效字节的最高有效位。 下图显示了n字节的Aurora 8B / 10B IP核的AXI4-Stream数据接口示例。
2.5.2、Framing接口
Framing接口示意图如下:

Framing接口由于存在frame(帧)的概念,所以接口信号较之Streaming接口要复杂一点,主要接口如下:
发送端(相对于用户来说):
| 名称 | 方向 | 时钟域 | 说明 |
| s_axi_tx_tdata[(8n–1):0] | 输入 | user_clk | 用户要发送的数据,位宽由链路位宽和链路数量决定 |
| s_axi_tx_tready | 输出 | user_clk | 为高表明当前IP核准备接收数据 |
| s_axi_tx_tlast | 输入 | user_clk | 发送的最后一个数据,高电平有效 |
| s_axi_tx_tkeep[(n–1):0] | 输入 | user_clk | 用来指示发送的最后一个数据的有效字节 |
| s_axi_tx_tvalid | 输入 | user_clk | 为高表明当前用户发送的数据有效 |
接收端(相对于用户来说):
| 名称 | 方向 | 时钟域 | 说明 |
| m_axi_rx_tdata[8(n–1):0] | 输出 | user_clk | 接收到的数据,位宽由链路位宽和链路数量决定 |
| m_axi_rx_tlast | 输出 | user_clk | 接收的最后一个数据,高电平有效 |
| m_axi_rx_tkeep[(n–1):0] | 输出 | user_clk | 用来指示接收的最后一个数据的有效字节 |
| m_axi_rx_tvalid | 输出 | user_clk | 为高表明当前接收的数据有效 |
如果你熟悉AXI4-Stream协议的话,基本就能马上上手数据的接收发送部分了。
发送数据
- 从发送端的几个信号就可以判断,当s_axi_tx_tready与s_axi_tx_tvalid握手成功后,即可发送数据
- 使用s_axi_tx_tlast来表示当前发送最后一个数据
- s_axi_tx_tkeep来表示最后一个数据的有效字节(应用场景在发送奇数个字节时,IP核会自动添加一个pad到数据中,所以存在一个无效字节需要指出),这一点倒是与AXI4-Stream协议不太一样
接收数据
- 接收数据不需要握手过程
- 当m_axi_rx_tvalid为高时,即说明此时的数据是有效数据,可以拿来用了
- m_axi_rx_tkeep与m_axi_rx_tlast的用法与发送端对应的信号一致
帧结构
TX子模块将每个接收的用户帧通过TX接口转换为Aurora 8B / 10B帧。 帧开始(SOF)通过在帧开始处添加2字节的SCP代码组来指示。 帧结束(EOF)是通过在帧的末尾添加一个2字节的信道结束通道协议(ECP)码组来确定。 数据不可用时插入空闲代码组。 代码组是8B / 10B编码字节对,所有数据都作为代码对发送,因此具有奇数个字节的用户帧具有称为PAD的控制字符,附加到帧的末尾以填写最终的代码组。 下图显示了具有偶数数据字节的典型Aurora 8B / 10B帧。

4种发送案例
手册(PG046)里举了4种传输案例方便我们理解发送过程:
Example A: Simple Data Transfer(简单数据传输)
在valid信号与ready信号握手成功期间传输数据,传输到最后一个数据DATA2时,拉高tlast信号,表明此时传输的是最后一个数据。tkeep信号表示最后一个数据的那些字节是有效的。

Example B: Data Transfer with Pad(奇数字节数据传输)
在valid信号与ready信号握手成功期间传输数据,传输到最后一个数据DATA2时,拉高tlast信号,表明此时传输的是最后一个数据。tkeep信号表示最后一个数据的那些字节是有效的。由于此时传输的是奇数个字节,所以最后一个数据中存在无效字节,故tkeep信号的值为N-1。

Example C: Data Transfer with Pause(带有暂停的数据传输)
在valid信号与ready信号握手成功期间传输数据,传输到最后一个数据DATA2时,拉高tlast信号,表明此时传输的是最后一个数据。tkeep信号表示最后一个数据的那些字节是有效的。
在握手期间,用户通过拉低valid信号中断了握手,实现了数据发送的暂停(流控)。

Example D: Data Transfer with Clock Compensation(带时钟补偿的数据传输)
当Aurora 8B / 10B IP核发送时钟补偿序列时,会自动中断数据传输。 时钟补偿序列每10,000字节加上每个通道的12字节开销。其他与上述情况一致。

接收数据案例
不同于发送数据的握手过程,接收数据过程简单的很,只需要数据有效信号m_axi_rx_tvalid为高时,则表示此时接收的数据有效,也用m_axi_rx_tkeep、m_axi_rx_tlast来修饰接收的最后一个数据。典型过程如下:

当m_axi_rx_tvalid为高时,接收到的数据有效,其他时候则无效。
Framing接口总结:
- Framing接口类似被再封装的AXI4-Streaming接口,IP核自动加入帧头、帧尾,并在固定时间内完成时钟补偿
- 发送端用户只需要在发送、接收双方完成握手后,即可发送数据,通信双方均可通过握手信号来反压对方;接收端用户仅需要在valid信号有效时从总线上拿数据即可
- 由于是帧结构,所以需要有信号来约束帧长度--tlast;由于数据的发送是成对发送,所以最后一个数据可能存在无效字节的情况,故需要对最后一个数据的有效字节数进行约束--tkeep
2.5.3、Streaming接口
Streaming接口示意图如下:

看起来比 Framing接口清爽了很多,因为发送端和接收端都少了keep和last这两个信号(共4个)。之前说过,Framing接口的帧框架使得需要使用keep和last这两个信号来控制帧的长度,所以信号较多。而Streaming接口则没有帧框架,相当于一条不停流动的管道,所以不需要使用keep和last这两个信号来控制长度。
用起来也很简单,发送数据只要在tvalid信号和tready信号握手成功时就可以发送;接收数据就更简单了,只要tvalid为高则说明此时接收的数据是有效的。
直接看图来加深理解:
Example A: TX Streaming Data Transfer(数据发送)
简单直白,只有当s_axi_tx_tready、s_axi_tx_tvalid均为高(成功握手)时,才可以发送数据。

Example B: RX Streaming Data Transfer(接收数据)
简单直白,只有当m_axi_rx_tvalid为高时才说明接收到的数据为有效数据。

Streaming接口总结:
- Streaming接口就是经典的AXI4-Streaming接口,没有帧的概念,数据总线上数据长度是不受限制的
- 发送端用户只需要在发送、接收双方完成握手后,即可发送数据,通信双方均可通过握手信号来反压对方;接收端用户仅需要在valid信号有效时从总线上拿数据即可
3、其他
- 下一节我们再来一起学习下Aurora IP核的时钟架构、复位和指示信号。
- 创作不易,如果本文对您有帮助,还请多多点赞、评论和收藏。您的支持是我持续更新的最大动力!
参考资料
Aurora 8B/10B Protocol Specification
Aurora 8B/10B v11.1 LogiCORE IP Product Guide