2、Python3基础
2.1.变量
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。变量没有类型,"类型"是变量所指的内存中对象的类型。
1.等号(=)用来给变量赋值。
变量名 = 赋给变量的值
a = 1
print(a) # 输出结果 a = 1
2.内置函数type()用来查询变量的类型
a = 1
print(type(a)) # 输出结果 <class 'int'>
3.内置函数id()查询变量在内存中的地址
a = 1
print(type(a)) # 输出结果 2611529476400
4.删除变量使用del
del a
5.python允许同时为多个变量复制
a = b = c = 1
print(a,b,c) # 输出结果 1 1 1
a, b, c = 1, 2, 3
print(a,b,c) # 输出结果 1 2 3
6.变量命名:变量名包含子母,数字和下划线,不能以数字开头,区分大小写,命名要见名知义
name = "张三"
userName = "张三"
2.2.标准数据类型
Python3 中有六个标准的数据类型:
Number(数字)
String(字符串)
List(列表)
Tuple(元组)
Set(集合)
Dictionary(字典)
Python3 的六个标准数据类型中:
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组)
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
2.2.1.数字(Number)
Python 数字数据类型用于存储数值。
1.整型(int):包含正整数和负整数,不带小数点
1.1常见的四种表现形式:
2 进 制:以'0b'开头。例如:'0b11011'表示10进制的27
8 进 制:以'0o'开头。例如:'0o33'表示10进制的27
10 进制:正常显示
16 进制:以'0x'开头。例如:'0x1b'表示10进制的27
1.2各进间数字进行转换(内置函数):
bin(i):将i转换为2进制,以“0b”开头。
i = 121
print(bin(i)) #输出结果 0b1111001
oct(i):将i转换为8进制,以“0o”开头。
i = 121
print(oct(i)) # 输出结果 0o171
int(i):将i转换为10进制,正常显示。
i = 121
print(int(i)) # 输出结果 121
hex(i):将i转换为16进制,以“0x”开头。
i = 121
print(hex(i)) #输出结果 0x79
2.浮点型(float):由整数部分和小数部分组成 如:1.2
2.1浮点数有两种表示方法:
十进制表示
1.2
科学计数法表示:使用字母e或E作为幂的符号,以10为基数
2.0e-1 表示为: 2.0乘以10的-1次方
结果是0.2
3.3e-3 表示为: 3.3乘以10的-3次方
结果是0.0033
3.复数(complex):由实部和虚部组成,复数的虚数部分通过后缀“J”和“j”来表示
x = 12 - 12j
print(x.real) # 输出实数部分为:12.0
print(x.imag) #输出虚数部分:-12.0
4.数值运算
加法
print(1+2)
减法
print(2-1)
乘法
print(2*1)
除法得到一个浮点数
print(5/2)
除法得到一个整数
print(4//2)
取余
print(15%2)
乘方
print(2**2)
2.2.2.字符串(String)
1.python3中的字符串用单引号或者双引号引起来
print(1+2) # 输出结果为3
print('1'+'2') # 输出结果为12
2.三引号将字符串跨越多行
str = "
11
22
33
44
"
print(str)
# 输出结果
11
22
33
44
3.连接字符串
字符串运算符
" * "用于重复输出字符串
print('a' * 3) # 输出结果 aaa
" + "用于连接两个字符串
print('a' + 'b') # 输出结果 ab
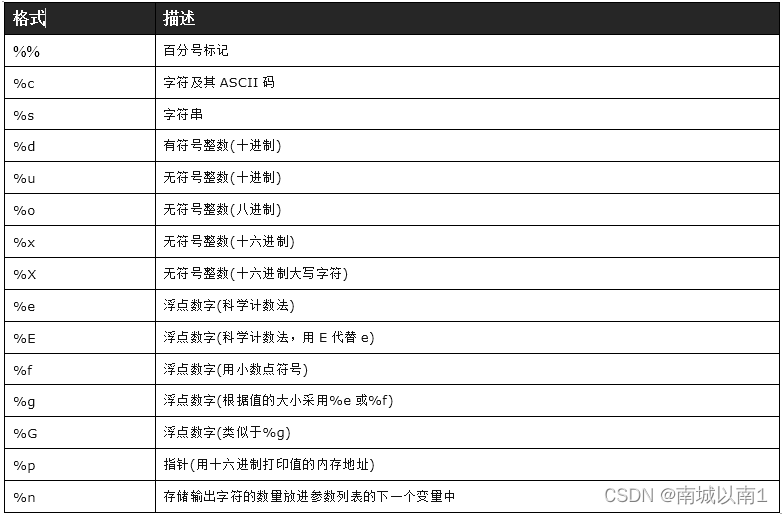
4.字符串的格式化方法分为两种,分别为占位符(%)和format方式。
占位符(%)
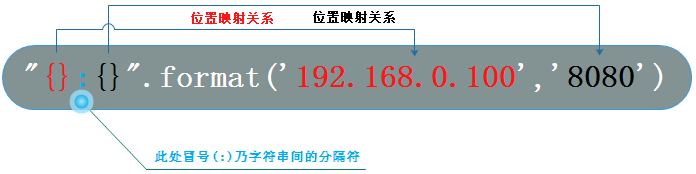
format方式
print("{}:{}".format('192.168.0.100',8888)) # #192.168.0.100:8888
5.转义字符
转义字符包含一个倒斜杠(\),紧跟着是想要添加到字符串中的字符。(尽管它包含两个字符,但大家公认它是一个转义字符。)

6.索引和切片
索引
语法: 变量[头下标]
字符串正索引从0开始,字符串负索引从-1开始
str = "123456"
print(str) # 输出字符串 123456
print(str[0]) # 输出字符串 1
切片
如果冒号后面有数字,不包含该下标对应的字符串
语法: 变量[头下标:尾下标:步长]
print(str[0:2]) # 输出结果 12
7.字符串翻转
name = 'python'
print(name[::-1]) # 输出字符串:nohtyp
8.len()返回字符串的长度
str = "python"
print(len(str)) # 输出结果6
9.in用来判断某个字符串内是否包含另外的字符串
str = "hello"
print('h' in str) # 输出结果True
10.获取字符串中的最大值、最小值
str = 'abcd'
print(max(str)) # 输出字符串 d
print(min(str)) # 输出字符串 a
2.2.3.列表(List)
1.创建列表
list01 = [1,2,3,4,5]
2.索引
列表正索引从0开始,负索引从-1开始
3.通过索引访问列表的值
list01 = [1,2,3,4,5]
print(list01[1]) # 输出结果 2
print(list01[0:2]) #输出结果 [1,2]
4.列表反转
list01 = list("hello")
print(list01[::-1]) 输出结果 ['o', 'l', 'l', 'e', 'h']
5.更新列表
通过索引修改对应的列表元素
lis01 = [1,2,3,4,5]
list01[1] = 6
print(list01) # 输出结果 [1, 6, 3, 4, 5]
通过append()在末尾追加列表元素
list01.append(7)
print(list01) # 输出结果 [1, 6, 3, 4, 5, 7]
6.拼接列表、重复列表
“+”用于组合列表
list01 = [1,2]
list02 = [3,4]
print(list01+list02) # 输出结果 [1, 2, 3, 4]
“*”用于重复列表
list01 = [1,2]
print(list01*3) # 输出结果 [1, 2, 1, 2, 1, 2]
7.列表截取
list01 = [1,2,3,4,5]
print(list01[1:]) # 输出结果 [2, 3, 4, 5]
8.嵌套列表
list01 = [1, 2]
list02 = ['a', 'b']
list03 = [list01, list02]
print(list03) # 输出结果[[1, 2], ['a', 'b']]
print(list03[0][1]) # 输出结果 2
print(list03[1]) # 输出结果 ['a', 'b']
9.列表排序
list.sort()将列表元素值首字母的ASCII码或者数值升序(默认)或者降序排列
list01 = [1, 4, 3, 2]
list01.sort() # 升序排列
print(list01) # 输出结果:[1, 2, 3, 4]
list01.sort(reverse = True) # 降序
print(list01) #输出结果 [4, 3, 2, 1]
列表反转reverse()
list01 = [1, 4, 3, 2]
list01.reverse()
print(list01) # 输出结果 [2, 3, 4, 1]
10.删除列表
del list[index] 用下标值index删除
list01 = [1,2,3,4]
del list01[2]
print(list01) # 输出结果 [1, 2, 4]
list.remove(value)用元素值删除
list01 = ['a', 'b', 'c']
list01.remove('a')
print(list01) # 输出结果:['b', 'c']
list.pop(index) 用下标值index删除,若省略则删除最后一个元素
list01 = ['a', 'b', 'c']
list01.pop() # 括号里不写下标,则删除最后一个元素
print(list01) # 输出结果 ['a', 'b']
list01.pop(1) # 括号里写下标数,则删除下标对应的列表元素
print(list01) # 输出结果['a', 'c']
11.使用list.count(value)统计列表中元素值value出现的次数
list01 = [1, 1, 3, 4, 5, 6, 5, 5, 5]
print(list01.count(5)) # 输出结果:4
12.复制列表
使用list.copy()进行浅复制
list01 = [1,'a',3,'b']
list02 = list01.copy()
print(list02) # 输出结果:[1, 'a', 3, 'b']
调用copy模块进行浅复制copy.copy(要复制的列表)
import copy
list01 = [1, 'a', 3, 'b']
list02 = copy.copy(list01)
print(list02) # 输出结果:[1, 'a', 3, 'b']
调用copy模块进行深复制copy.deepcopy(要复制的列表)
import copy
list01 = [1, 'a', 3, 'b']
list02 = copy.deepcopy(list01)
print(list02) # 输出结果:[1, 'a', 3, 'b']
13.判断元素是否存在 in 和 not in
list01 = [1,2,3,4]
print(1 in list01) # 输出结果 True
print(1 not in list01) # 输出结果 Flase
2.2.3.元组(Tuple)
1.创建元组使用“()”,括号内元素用逗号隔开
tup01 = (1,3,4,5)
tup02 = () # 创建空元组
2.元组的赋值与获取
tup01 = (1,2,3)
a,b,c = tup01
print(a,b,c) # 输出结果 1 2 3
3.用索引访问元组
tup01 = (1,2,3)
print(tup01[0]) # 输出结果:1
4.元组中只有一个元素时,元素后添加逗号进行区分
tup01 = (1)
print(type(tup01)) # 输出结果<class 'int'>
tup01 = (1,)
print(type(tup02)) # 输出结果<class 'tuple'>
5.元组的元素不能被修改,可以对元组进行重复、组合、截取操作
重复
tup01 = (1,2,3)
print(tup01 * 2) # 输出结果 (1, 2, 3, 1, 2, 3)
组合
tup01 = (1,2)
tup02 = (3,4)
print(tup01+tup02) # 输出结果 (1, 2, 3, 4)
截取
tup01 = (1,2,3,4)
print(tup01[0:2]) # 输出结果:(1, 2)
6.元组元素不能被删除,只能用del删除怎么元组
del tuple
7.元组的常用方法、内置函数
方法:
tuple.index(obj):从元组中找出某个值第一个匹配项的索引值
tuple.count(obj): 统计某个元素在元组中出现的次数
内置函数
len(tup): 返回元组中元素的个数
max(tup): 返回元组中元素最大的值
min(tup): 返回元组中元素最小的值
tuple(seq): 将列表转化为元组
8.判断一个元素是否在元组中 in 和 not in
tup01 = (1,2,3,4)
print(1 in list01) # 输出结果 True
print(1 not in list01) # 输出结果 Flase
2.2.4.字典(Dict)
1.创建字典用“{
}“,字典是一种可变容器模型,可以存储任意类型的对象
dict01 = {
key1:value1,key2:value2}
2.通过键获取值
dict01 = {
'name':'张三','age':25}
print(dict01['name']) # 输出结果 张三
print(dict01['age']) # 输出结果 25
3.添加,修改,删除字典
添加
dict01 = {
'name': '张三', 'age': 25}
dict01['school'] = "w五中"
print(dict01) # 输出结果 {'name': '张三', 'age': 25, 'school': 'w五中'}
修改
dict01 = {
'name': '张三', 'age': 25}
dict01['name'] = '李四'
print(dict01) # 输出结果 {'name': '李四', 'age': 25}
删除
删除键
dict01 = {
'name': '张三', 'age': 25}
del dict01['name']
print(dict01) # 输出结果 {'age': 25}
删除字典,字典不存在
dict01 = {
'name': '张三', 'age': 25}
del dict01
清空字典所有元素,变为空字典
dict01 = {
'name': '张三', 'age': 25}
dict01.clear()
print(dict01) # 输出结果 {}
5.遍历字典
dict01 = {
'name': '张三', 'age': 25}
for key,value in dict01.items():
print('key={0},value={1}'.format(key, value)) # 输出结果 key=name,value=张三 key=age,value=25
dict01 = {
'name': '张三', 'age': 25}
for key in dict01.keys():
print('key = {0},value = {1}'.format(key,dict01[key])) # 输出结果 key = name,value = 张三 key = age,value = 25
6.字典键的特性
1.字典的值可以是任意Python对象,也可以由用户定义,键不可以,键必须是唯一性,不允许同一个键出现第二次
2.键不可变,可以由数字,字符串,元组充当,不能用列表充当字典的键
7.字典内置函数&方法
内置函数:
cmp(dict1, dict2) #比较两个字典元素。
len(dict) #计算字典元素个数,即键的总数。
str(dict) #输出字典可打印的字符串表示。
type(variable) #返回输入的变量类型,如果变量是字典就返回字典类型。
内置方法:
dict01.clear() #删除字典内所有元素
dict01.copy() #返回一个字典的浅复制
dict01.fromkeys() #创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
dict01.get(key, default=None) #返回指定键的值,如果值不在字典中返回default值
dict01.items() #以列表返回可遍历的(键, 值) 元组数组
dict01.keys() #以列表返回一个字典所有的键
dict01.setdefault(key, default=None) #和get()类似, 但如果键不已经存在于字典中,将会添加键并将值设为default
dict01.update(dict2) #把字典dict2的键/值对更新到dict01里
dict01.values() #以列表返回字典中的所有值
8.判断python字典中key是否存在的 in和not in
radiansdict = {
'name':'张三','age':25}
print('name'in radiansdict.keys()) # 输出结果 True
print('name' in radiansdict) # 输出结果 Flase
2.2.5.集合(Set)
集合是一个无序,不包含重复元素的容器
1.创建集合用{
},空集合用set()表示
set01 = {
1,2,3,4}
2.删除重复元素
set01 = {
1,2,2,3,4,3}
print(set01) # 输出结果{1, 2, 3, 4}
3.检测集合成员 in 和 not in
set01 = {
1, 2, 3, 4}
print(1 in set01) # 输出结果 True
print(1 not in set01) # 输出结果 False
4.集合运算
set01-set02:集合set01中包含而集合set02中不包含的元素
set01|set02:集合set01或set02中包含的所有元素
set01&set02:集合set1和set02中都包含了的元素
set01^set02:不同时包含于set01和set02的元素
5.添加元素
s.add(x)
将变量看作一个整体添加到集合中,集合只增加一个数据项。如果元素已存在,则不进行任何操作。
s.update(x)
变量可以是列表、元组、字典等,可以是多个变量,用逗号分开。将所有的变量分隔成单个字符插入集合中。
6.移除元素
s.remove(x)
将元素从集合中移除。如果元素不存在,则报错。
s.discard(x)
将元素从集合中移除。即使元素不存在,也并不会报错。
s.pop()
删除集合中的一个元素,并返回删除的元素。只当集合元素是字符串类型时,
并且在脚本运行(CMD)时才会随机删除,在交互式环境(IDE)中是保持删
除左边第一个元素的。如果集合元素是其他数据类型时,是删除左边第一个元
素的。如果删除的集合为空,就会报错。
2.3.标识符
1.在Python3中使用的名称叫做标识符,变量和常量也是标识符。
标识符遵循一下命名规则
1).由子母,数字,下划线组成
2).不能以数字开头
3).区分大小写
4).以单下划线开头的(_foo)代表不能直接被访问的类属性,需要通过类提供的接口
5).以双下划线开头的(__foo)代表类的私有成员
6).以双下划线开头和结尾的(__foo__)代表Python3中的特殊方法专用的标识
2.查询Python3所有保留字
import keyword
print(keyword.kwlist)
2.4.行与缩进
1.缩进
使用缩进来表示代码块,不需要使用大括号 {
} 。
同一个代码块的语句必须包含相同的缩进空格数。缩进不一致,会导致运行错误
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
print ("False")
2.多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠(\)来实现多行语句:
total = item_one + \
item_two + \
item_three
在 [], {
}, 或 () 中的多行语句,不需要使用反斜杠(\),例如:
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
3.空行
空行与代码缩进不同,空行并不是Python语法的一部分。书写时不插入空行,
Python解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,
便于日后代码的维护或重构。空行也是程序代码的一部分。
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。
类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
4.同一行显示多条语句
Python可以在同一行中使用多条语句,语句之间使用分号(;)分隔:
import sys; x = 'runoob'; sys.stdout.write(x + '\n')
5.多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。像if、while、def和class这样的复合语句,
首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。
if expression :
suite
elif expression :
suite
else :
suite
2.5.运算符和表达式
2.5.1.算数运算符
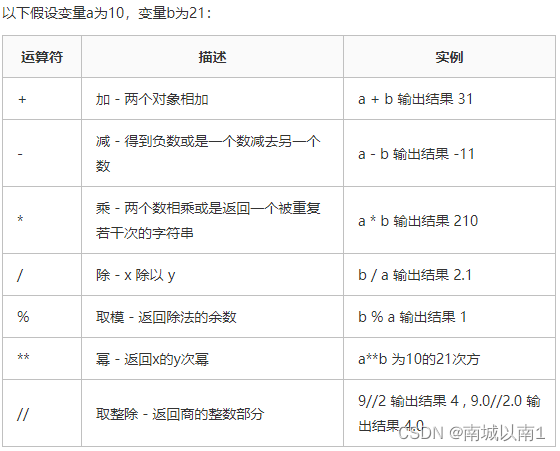
2.5.2.比较运算符

2.5.3.逻辑运算符

2.5.4.成员运算符
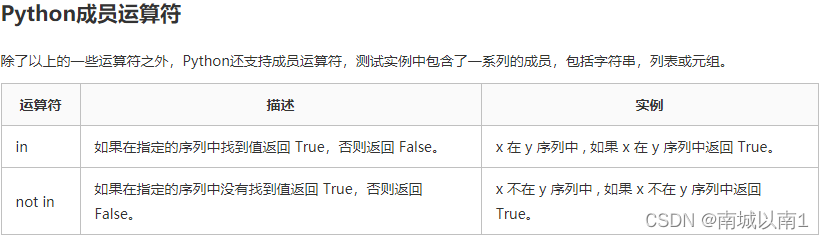
2.5.5.身份运算符
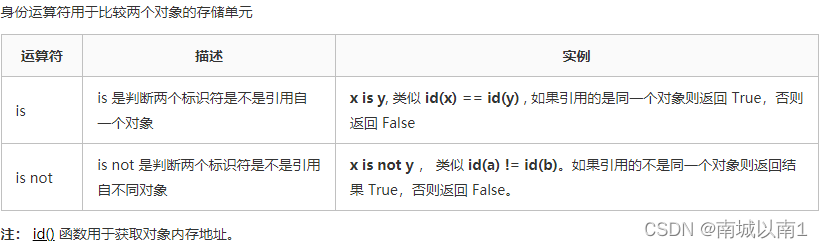
2.5.6.优先级运算符
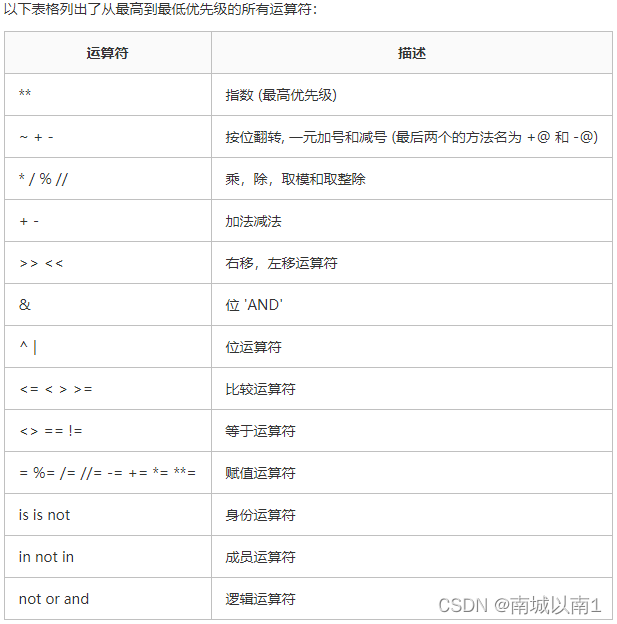
2.5.7.赋值运算符
2.5.8.位运算

2.6.条件语句if
1.python3条件语句通过关键字if-elif-else执行代码块
输出结果True或者Flase
--使用 or ( 或 ) 表示两个条件有一个成立时判断条件成功
--使用 and ( 与 ) 表示只有两个条件同时成立的情况下,判断条件才成功
if 条件:
代码块
elif 条件:
代码块
else:
代码块
2.if 中常用的操作运算符
操作符 描述
< 小于
<= 小于或等于
> 大于
>= 大于或等于
== 等于,比较对象是否相等
!= 不等于
2.7.循环语句
2.7.1.while
格式:
1.while循环
while 表达式:
语句:
逻辑:当程序执行到while语句时,首先计算"表达式"的值
如果表达式的值为假,那么结束整个while"语句"
如果表达式的值为真,那么执行语句,执行完"语句",再去执行"表达式"的值
如果表达式的值还为真,那么继续执行语句,直到表达式的值为假,整个while语句才结束
2.whlie…else语句
其else语句只有在while正常结束时才会被执行,如果while循环被break语句结束,是不会执行else语句的
num = 0
while num < 10:
num += 1
print(num)
else:
print('hello,python')
3.while…while嵌套
当第一个while执行一次,第二个while语句就要执行一轮,直到不满足第二个while的条件语句,
然后在执行第一个while循环,然后再第二个while语句执行一遍,直到不满足while的条件语句。
直到第一个while语句也不满足while语句。
n=0
while n<9:
s= 0
n+=1
while s < n:
s += 1
print("{}*{}={}".format(s,n,s*n),end=" ")
print() #换行处理
#输出结果
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
4.退出while循环有两种方法:
1.while条件语句为False
2.break
#while条件语句为False,退出循环。
num = 0
while num < 10:
num += 1
print(num)
#break退出循环
num = 0
while True:
num += 1
print(num)
if num > 10:
break
5.continue可以跳过(非退出)本次的循环执行下一次循环
num = 1
while num < 10:
num += 1
if num%2 > 0:
continue
print (num)
输出结果
2
4
6
8
10
2.7.2.for语句
1.for循环可以遍历任何序列类型的对象
for 迭代变量 in 字符串|列表|元组|字典|集合:
代码块
2.for 循环进行数值循环
range()函数可以遍历数字序列
print("计算 1+2+...+100 的结果为:")
#保存累加结果的变量
result = 0
#逐个获取从 1 到 100 这些值,并做累加操作
for i in range(101):
result += i
print(result) # 输出结果是 5050
2.for循环遍历列表和元组
my_list = [1,2,3,4,5]
for item in my_list:
print('item =', item)
# 输出结果
item = 1
item = 2
item = 3
item = 4
item = 5
3.for 循环遍历字典
在使用 for 循环遍历字典时,经常会用到和字典相关的 3 个方法,
即 items()、keys() 以及 values()
my_dic = {
'python教程':"hello python",\
'shell教程':"hello shell",\
'java教程':"hello java"}
for items in my_dic:
print('items =', items)
# 输出结果
items = python教程
items = shell教程
items = java教程
2.7.3.使用枚举遍历序列
枚举函数enumerate:返回元组(计数数字,字符)0开始计数
number01 = [10, 20, 30]
for index, date in enumerate(number01):
print('index=', index, 'data=', date)
# 输出结果
index= 0 data= 10
index= 1 data= 20
index= 2 data= 30
2.8.函数
2.8.1.函数的定义合调用
1.函数的定义
(1).函数代码块以def关键字,后接函数标识符再接()
def 函数名(参数列表)
(2).任何传入的参数和自变量必须放入()中间,()中间用于定义参数
(3).return[表达式]结束函数,不带表达式的return表示None
2.函数的语法
def 函数名(参数列表):
函数体
#定义函数
def name():
print("你的名子叫啥")
# 调用函数
name()
输出结果:
你的名子叫啥
3.调用函数
def add(a=1, b=3):
print(a + b)
add()
输出结果
4
4.函数是一个特殊的对象可以赋值给其他变量使用
def sum(x, y):
return x + y
add01 = sum
print(add01(6, 1))
输出结果
7
2.8.2.函数中的文档
在定义函数不知道是什么含义时,需要对函数进行说明,需要用到文档字符串
def sum(a,b):
"""
三引号就是说明文档字符串,在此写入add函数的含有如下
sum:a和b的和
"""
2.8.3.默认参数
调用函数时,如果没有传递参数,则使用默认参数,如果传递传递参数,默认参数就失去作用
def info(name, age=25):
print( name, age)
info(name="张三") # 函数调用时没有兑age进行传参,则使用默认参数age=25
输出结果
张三 25
def info(name, age=25):
print( name, age)
info(name="张三",age=40) #默认参数age=25失去作用
输出结果
张三 40
2.8.4.不定长参数
python3对于参数个数不确定,给与以下解决方法
1.函数用*args方式接受数据,以元组形式传参
def func(x, *args):
print("x={0},agrs={1}".format(x, args))
result = x
for index in args:
result = result + 1
return result
print('result=', func(1, 2, 3))
输出结果
x=1,agrs=(2, 3)
result= 2
2.函数中用**kargs方式结束数据,以字典形式传参
def fun2(x, **kargs):
print("x=", x)
print('kagrs', kargs)
print(fun2(1, b=2, c=3))
输出结果:
x=1
kagrs {
'b': 2, 'c': 3}
None
2.8.5.range函数
python3的range函数用来创建一个整数序列的对象,一般用在for循环中
1.语法
range(start,end,step)
start:计数冲start开始,默认从零开始
end:计数到end结束,不包含end
step:步长
for index in range(0,40,4):
#输出从0到40,步长为5的结果
print(index)
输出结果
0
4
8
12
16
20
24
28
32
36
2.8.6.函数作为参数传递
1.函数可以做为一个对象进行参数传递,叫做回调函数
def test01(fun01, a, b):
print(fun01(a, b))
def fun01(x, y):
return 2 * x + y
test01(fun01, 1, 3)
输出结果
5
2.9.文件
文件在python3也是一种类型的对象
2.9.1.操作文件
1.打开文件
file = open(文件名,打开方式,编码方式)
文件名:包含文件路径,文件名
打开方式:只读(r),写入(w),追加(a)
编码方式:打开文件的编码方式,可选参数
不同模式打开文件的完全列表:

file对象主要方法说明
file.read():读取文件的全部内容
如果读取的文件有30G,那么读取文件就会抛出MemoryErroy异常
file.readline():读取文件的一行内容
file.readlines():读取文件的全部行
file.close()关闭文件,释放资源
2.读取文件
# 打开文件,得到文件句柄并赋值给一个变量
file = open('d:text.txt','r',enciding='utf-8')
# 通过句柄兑文件进行操作
date = file.read()
print(date)
# 关闭文件
file.close()
读取大文件的三种方式
1).反复调用file(size),每次最多读取size个字节的文字内容,避免造成内存溢出异常
2).调用filelines()方法,一次性读取文件的所有内容返回list列表
file = open('d:text.txt','r',enciding='utf-8')
for line in file.readlines():
# 读取文件的每行内容,把每行的头部和尾部的空格换行符去掉输出到控制台
print(line.strip())
file.close()
3).使用迭代器遍历file对象,读取文件的每行内容,运行速度最快
file = open('d:text.txt','r',enciding='utf-8')
for line in file():
print(line.strip())
file.close()
3.写入文件
# 打开文件,得到文件句柄并赋值给一个变量
file = open('d:text.txt','w',enciding='utf-8') # 以写的方式打开文件
file = open('d:text.txt','a',enciding='utf-8') # 以追加模式打开文件
4.二进制文件
二进制文件指的是图片,音频,视频格式的文件
1.打开二进制文件:open(file,"rb")只读
2.打开二进制文件:open(file,"wb")只写
3.os.stat('文件名.后缀').st.size 获取文件的大小
2.9.2.使用with语句
1.使用with语句对文件进行读取操作,对文件的写入也是一样,代码结束时,会自动结束file.close()
with open('d:/test.txt','r',encoding='utf-8')as file
data = file.read()
2.统计文件有多少行
print('rows:%d'%len(file.readlines()))
2.9.3.电子表格
1.读取csv文件
import csv
with open('text.csv','r')as file:
reader = csv.reader(file)
2.把数据写入到csv文件
import csv
with open('test.csv','w')as file:
writer.writerow([1,2,3])
2.10.面向对象
面向对象程序设计正对大型软件设计提出,提高代码复用,和设计复用,基本原则就是计算机程序由多个能够起到子程序作用的单元或者对象组合而成,关键性理念,将数据以及对数据的操作封装在一起,组成一个相互依存,不可分割的整体,即对象
2.10.1.类与对象的定义
1.类与对象的定义
类:是对某一类事物的描述,类是对一群具有同属性方法的对象的抽象
对象:是类的实例
2.类的创建
# 类
class Wife:
# 数据成员
def __init__(self,name)
self.name = name
self.sex = sex
# 行为成员
def play(self)
'''
一起玩耍
'''
print(self.name + "玩耍")
# 创建对象,实际在调用__init__方法
w01 = Wife("莉莉","女") # 自动将对象地址传入方法
# 调用对象的行为
w01.play() # 自动将对象地址传入方法
2.构造方法
__init__()构造方法:用来为类的属性设置初始值或者进行其他必要的初始化工作,
# 类
class Wife:
# 数据成员,构造方法
def __init__(self,name)
#实例属性
self.name = name
self.sex = sex
# 行为成员
def play(self)
'''
一起玩耍
'''
print(self.name + "玩耍")
# 创建对象,实际在调用__init__方法
w01 = Wife("莉莉","女") # 自动将对象地址传入方法
# 调用对象的行为
w01.play() # 自动将对象地址传入方法
2.10.2.私有属性和方法
1.私有属性:Python3定义类的属性时,如果属性的名称
是两个下划线开头表示私有属性,私有属性在类的外部
不能直接访问,需要通过调用对象的公有方法来访问,
子类可以继承父类的公有成员,但是不能继承私有成员
class Student(object):
def __init__(self,name,age):
self.__name = name
self.__age = age
def info(self):
print('name={0},age={1}'.format(self.__name,self.__age))
stu = Student("tom",21)
stu.info()
输出结果
name=tom,age=21
2.在私有方法中可以访问类的所有属性,只能在类的内部调用私有方法,无法通过对象调用私有方法
2.10.3.继承
封装
1.定义
1.数据角度来讲,将一些基本数据类型复合成一个自定义类型
优势:更符合人类的思考方式,将数据与对数据的操作整合在一起
2.行为角度来讲,向类外提供必要的功能,影藏实现的细节
优势:以“模块化”的方式进行变成,可以集中精力设计组织,指挥多个类协同操作
3.设计角度来来讲
(1).分为治之
--将一个大的需求分解为许多类,每个类处理一个独立的功能
--拆分好处:便于分工,便于复用,可扩展性强
(2).变则疏之
--变化的地方独立封装,避免影响其他类
(3).高内聚
--类中的各个方法都在完成一项任务(单一职责的类)
(4).低耦合
--类与类的关联性与依赖度要低
私有成员
在Python里边,一个类的成员(成员变量、成员方法)是否为私有,完全由这个成员的名字决定。如果一个元成员的名字以两个下划线__开头,但不以两个下划线__结尾,则这个元素为私有的(private);否则,则为公有的(public)。Pyhton里边并没有protected的概念。
为了方便表述,如果一个元素的名字以两个下划线__开头,但不以两个下划线__结尾,我们称这个元素的名字“符合私有定义”。
我们注意到,私有成员不以以两个下划线结尾;所有的运算符重载相关方法,以一些特殊的成员方法如构造函数,都是以两个
下划线开头,两个下划线结尾,而且它们都是公有的。
私有成员,即只能在这个类里边访问;如果你在类外面访问一个私有成员,系统会抛出一个异常,提示你这个成员不存在。
请看如下代码:
class Hugo:
def __init__(self):
self.__name = "hugo"
def Say(self):
# 在类内部使用私有成员变量__name
print("my name is:", self.__name)
boy = Hugo()
boy.Say() # OK
# 此处抛出一个异常,提示__name不存在
print("name of boy:", boy.__name)
其它运行结果如下:
my name is: hugo
Traceback (most recent call last):
File "eg1.py", line 13, in <module>
print("name of boy:", boy.__name)
AttributeError: 'Hugo' object has no attribute '__name'
正如这个例如所展示的,我们可以在类的内部(成员方法中)使用私有变量__name。然而,当我们直接在外部访问__name,会收到一个异常,说Hugo类的对象没有__name方法。显然,这个异常的提示具有误导性,因为__name实际上存在,只是不能直接访问。
1、私有成员并非真正私有
其实,我们还是可以类的外面访问私有成员,方法是,在私有成员的名字前面加一个下划线和类名。
如下面例子所示:
class Hugo:
def __init__(self):
self.__name = "hugo"
def Say(self):
# 在类内部使用私有成员变量__name
print("my name is:", self.__name)
boy = Hugo()
boy.Say() # OK
# 通过_Hugo__name可以在外部访问私有变量__name
print("name of boy:", boy._Hugo__name)
我们可以通过_Hugo__name可以在外部访问私有变量__name。然后,在实际开发中,如果没有特殊的需要,请不要这么做。我们将一个成员声明为私有,是有一定的原因的,其中一个最主要的原因,就是不希望使用者直接访问它。虽然我们还是可以这么做,但请务必遵守这个约定,以免出现不必要的问题。
2、私有访问约定
,在一个模块中,如果一个函数的名字符合私有定义,那么这个方法是私有的,只能在这个模块中使用。其实,扩展到模块中定义的类和变量也一样,如果模块中的类或者变量名符合私有定义,那么它就是私有的,只能在这个模块中使用。
但实现上,即便一个元素的名字符合私有定义,依然可以在模块外使用。
不过,在理念上,如果一个函数的名字符合私有定义,那么它就是一种私有访问的约定,或者惯例,没有特殊的原因,你就不应该去直接使用它。
在大型项目开发过程中,为了提高协作的效率,我们会有很多不成文的约定(通常被称为“惯例”)。当我们见到一个东西符合某种约定,那我们最好就遵循这个惯例。
# 使用方法,封装变量
class Wife:
def __init__(self, name, age, weight):
self.name = name
# 本质:障眼法(实际将变量名改为:_类名__age)
self.__age = age
self.__weight = weight
w01 = Wife("铁扇公主", 87, 87)
# 从新创建新实例变量
w01._Wife__age = 107 # 修改了类中定义的私有变量
print(w01.name)
print(w01._Wife__age) #python 内置变量,存储对象的实例变量都在里面
输出结果
铁扇公主
107
{
'name': '铁扇公主', '_Wife__age': 107, '_Wife__weight': 87}
class Wife:
def __init__(self, name, age, weight):
self.name = name
# 本质:障眼法(实际将变量名改为:_类名__age)
self.__age = age
self.__weight = weight
# 提供公开的读写方法
def get_age(self):
return self.__age
def set_age(self,value):
if 21 <= value <= 31:
self.__age = value
else:
raise ValueError("我不要")
w01 = Wife("牛魔王",30,87)
w01.set_age(25)
print(w01.get_age())
创建property对象,只负责拦截读取操作,变量…setter 只负责拦截写入操作
class Wife:
def __init__(self, name, age, weight):
self.name = name
# 本质:障眼法(实际将变量名改为:_类名__age)
self.age = age
self.weight = weight
# 提供公开的读写方法
@property # 创建property对象,只负责拦截读取操作
def age(self):
return self.__age
@age.setter # 只负责拦截写入操作
def age(self, value):
if 21 <= value <= 31:
self.__age = value
else:
raise ValueError("我不要")
@property
def weight(self):
return self.__weight
@weight.setter
def weight(self, value):
if 32<= value <= 60:
self.__weight = value
else:
raise ValueError("我不要")
w01 = Wife("牛魔王", 30, 87)
w01.age = 25
print(w01.age)
w01.weight = 45
print(w01.weight)
练习1:定义敌人类(姓名,攻击力10–50),血量100–200创建一个敌人对象,可以修改数据,读取数据
class Enemy:
def __init__(self,name,hp, atk):
self.name = name
self.__hp = hp
self.__atk = atk
def get_hp(self):
return self.__hp
def set_hp(self,value):
if 10 <= value <= 50:
self.__hp = value
else:
raise ValueError("我不要")
def get_atk(self):
return self.__atk
def set_atk(self,value):
if 100 <= value <= 200:
self.__atk = value
else:
raise ValueError("我不要")
w01 = Enemy("面霸",80,120)
w01.set_hp(25)
print(w01.get_hp())
w01.set_atk(150)
print(w01.get_atk())
输出结果
25
150
继承
多个子类在概念上一致,所以就抽象出一个父类
多个子类的共性,可以提取到父类中
从设计角度讲:先有子再有父
从编码角度讲:先有父,再有子
子类不用写,但是可以用
子类对象可以调用子类成员,也可以调用父类成员
父类对象只可以调用父类成员,不能调用子类成员
# Python 内置函数isinstance
# 1.判断对象是否属于一个类型
# ”老师对象“是 一个老师类型
print(isinstance(t01,Teacher)) # True
# "老师对象" 是 一个学生类型
print(inistance(t01,Student)) # False
# "老师对象" 是 一个人类型
print(isinstance(t01,Person)) # True
class Person:
def say(self):
print("说话")
class Student(Person):
def study(self):
print("学习")
class Teacher(Person):
def teach(self):
print("讲课")
子类若具有构造函数,则必须先调用父类构造函数
class Person:
def __init__(self,name)
self.name = name
class Student(person):
def __init__(self,name,score):
super().__init__(name)
self.score = score
s01 = Student("张三",100)
print(s01.score)
print(s01.name)
多态
1.定义
父类的同一种动作或者行为,在不同的子类上有不同的实现
2.作用
1.继承相关概念的共性进行抽象,多态在共性的基础上,提现行为有不同的实现
2.争强可扩展性,提现开闭原则
类与类的关系
泛化:子类与父类的关系,概念的复用,耦合度最高
B类泛化A类,意味着B类是A类的一种
做法:B类继承A类
关联(聚合/组合):部分与整体的关系,功能的复用,变化影响一个
A与B关联,意味着B是A的一部分
做法:在A类中包含B类成员
依赖:合作关系,是一种相对松散的协作,变化影响一个方法
A类依赖B类,意味着A类中方法的参数并不是A的成员
2.10.4.静态方法
1.定义
@staticmethod
def 方法名称(参数列表)
方法体
2.调用
类名.方法名(参数列表)
不建议通过对象访问静态方法
3.说明
使用@staticmethod静态方法,通过类直接调用,不需要创建对象,不会隐式传递self
静态方法不能访问实例成员和类成员
4.作用
定义常用的工具函数
2.10.5.魔法方法和特殊属性
魔法方法也叫特殊方法开头结尾用双下划线,如__init__
特殊方法也是开头结尾用双下划线
1.__dict__:可以访问类的所有属性,以字典的形式返回
2.__slots__:限制类实例的属性,仅对当前类实例起作用,对继承他的子类不起作用
class Person(object):
__slots__ = ("name","age")
pass
class Student(Person):
pass
stu = Student()
stu.name = "张三"
stu.age = 28
stu.score = 99
print("name={0},score={1},age={2}".format(stu.name,stu.age,stu,score))
2.10.6.可调用对象
特殊方法__call__():将一个类实例变成可调用的对象
class Person(object):
def __init__(self,name,gender)
self.name = name
self.gender = gender
def __call__(self,friend):
print('打印类的实例属性name={0},gender={1}'.format(self.name,self.gender))
print('打印__call__()方法的参数friend={0}'.format(friend))
person = Person('tom','nale')
person('tang')
2.11.错误合异常
2.11.1.错误
当python3检测到一个错误时,解释器就无法继续执行下去,就抛出相信的信息,称为异常信息
2.11.2.异常
异常:在python3程序中的语法是正确的,在运行的时候也有可能发生错误,运行期间检测到的错误
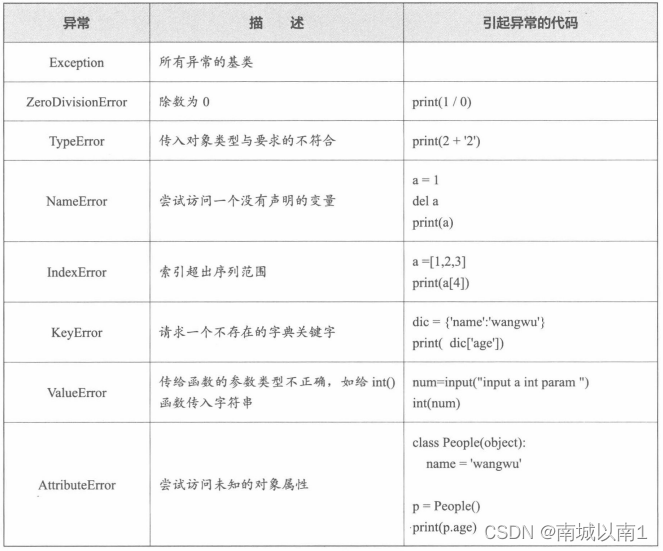
2.11.3.处理异常
1.异常处理的意义
当程序运行时出现异常,会导致程序终止运行,
为了避免这种情况,需要对预先可能出现的异
常经行处理,一旦出现该异常,就使用另一种
方式解决问题
2.异常处理两种方式
1).
try:
pass
except 异常类性 as ex:
pass
2).
try:
#主代码
pass
except 异常类型 as e:
#主代码块
pass
else:
#主代码块
pass
finally:
# 无法异常与否,最终执行该块
pass
3.异常的分类处理
try:
# 主程序
pass
except ZeroDivisionError: # 捕捉0异常
print('ZeroDivisionError')
except (TypeError.ValueError) as e: # 捕捉多个异常
print(e)
except: # 捕捉其余类型异常
print('it is still wrong')
else:
print('it work well')
2.11.4.打印异常信息
使用trackback模块捕获或者打印异常,
track模块用来精确的模仿Python解释器
的stack trace行为
import traceback
try:
print(1/0)
except:
traceback.print_exc()
2.11.5.自定义异常
1.使用raise抛出自定义异常
try:
# 主程序
pass
if 条件:
raise Myexception("自定义异常")
except MyException as err:
print('打印MyException',err)
except Exception as err:
print('打印Exception',err)
2.12.模块
序列是数据的封装,函数是语句的封装,类是方法和属性的封装
模块是程序的封装
2.12.1.导入模块
1.import语句
python3用import模块导入模块中的函数类,等到其他的代码快
1).语法:
import 模块名
import 模块名 as 别名
as:为导入的成员起一个另外的别名,避免冲突
import pandas as pd
2).作用:将某模块整体导入到当前模块中
3).本质:使用变量名名modul01关联模块地址
第一种导入方式:import语句
# 新建一个module01.py的文件,写入如下代码
print("模块1")
def fun01():
print("模块1的fun01")
class MyClass02:
def fun02(self):
print("MyClass02")
# 再新建一个demofour.py的文件,写入如下代码
import module01
module01.fun01()
my02 = module01.MyClass02()
my02.fun02()
输出结果:
模块1
模块1的fun01
MyClass02
Process finished with exit code 0
from import
1.语法:
from 模块名 import成员名[as 别名]
2.本质:将指定的成员导入到当前模块作用域中
3.作用:将模块内的一个或者多个成员导入到当前模块的作用域
# 第二种导入方式
from module01 import MyClass02
from module01 import fun01
fun01()
my02 = MyClass02()
my02.fun02()
输出结果
模块1
模块1的fun01
MyClass02
from 模块名 import *
1.语法:
from module01 import *
2.本质:将指定模块的所有成员导入到当前模块作用域
3.模块中以下划线(_)开头的属性,不会被导入
# 第三种导入方式
from module01 import *
fun01()
my02 = MyClass02()
my02.fun02()
2.12.2.模块的__name__属性
1.以程序方式运行python脚本
在控制台输入 python 文件名.py执行python脚本
2.以模块方式运行python脚本
1).在python中一个模块作为整体被执行时,
模块.__name__的值是“__main__”
2.当模块被其他模块引用时
模块.__name__的值是自己的名称
2.12.3.模块路径
当使用import导入模块时,python会在以下路径搜寻需要的模块
1.程序所在的文件加
2.标准库的安装路径
3.操作系统环境变量pythonpath所包含的路径
2.12.4.包
包是由多个模块组成:也就是很多个“.py”的文件的集合,
包是一个有层次的文件目录结构
引入某个目录的模块时,需要在该目录侠放一个__init__.py的文件

2.13.常用模块
2.13.1.os模块
在python3中os模块用来处理文件和目录
1.os.popen():从一个命令打开一个管道,在Linux,Windows中有效
import os
os.popen(要执行的命令)
import os
data = os.popen('dir').read()
print(data)
输出结果
2022/01/05 17:21 <DIR> .
2022/01/05 17:21 <DIR> ..
2022/01/05 17:09 <DIR> .idea
2022/01/04 16:17 1 feil.py
2022/01/05 17:21 61 main.py
2022/01/04 16:16 <DIR> venv
2 个文件 62 字节
4 个目录 46,910,468,096 可用字节
2.os.listdir()用于返回指定的文件包含的文件和目录的名称列表
import os
os.listdir(需要的文件路径)
2.13.2.time模块
1.获取当前时间戳
import time
print(time.time())
输出结果
1641374941.6471102
2.获取当前时间
import time
print(time.ctime())
输出结果
Wed Jan 5 17:31:10 2022
3.推迟线程的运行
time.sleep(秒数)
4.格式化日期
import time
print(time.strftime('%y-%m-%d %H:%M:%S', time.localtime()))
输出结果
22-01-05 17:38:50