一、代码仓库创建规范
1、 项目创建需符合Group规范。
2、 创建项目必须添加Project description说明。
3、 每个项目都需要README.md文件。
4、 除文档说明类型仓库,所有代码仓库都需要.gitignore。
注:有模板的项目,要以统一的模板创建项目
1.1 README文件规范
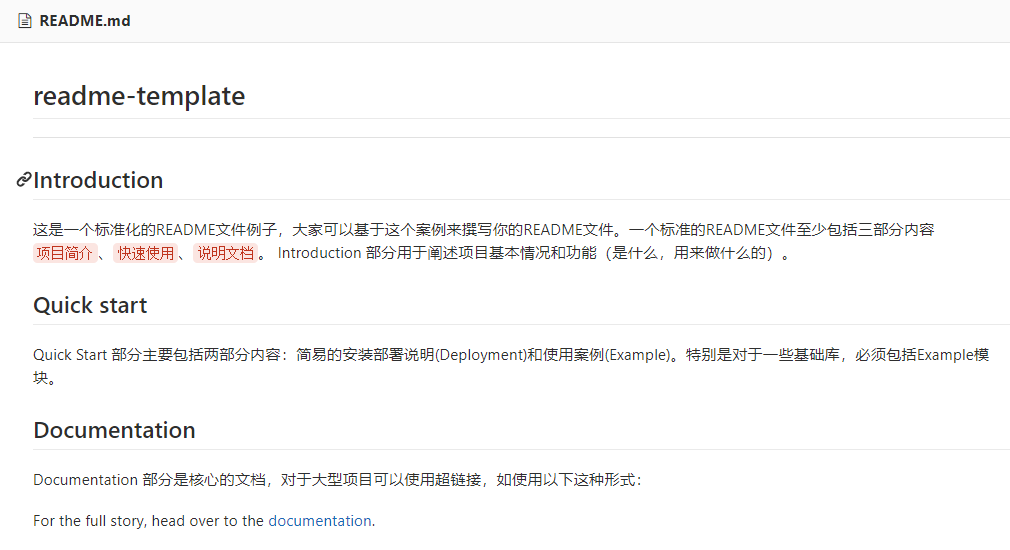
README文件结构如下:
<项目简介/Introduction>
<快速使用/Quick start>
<文档说明/Documentation>
Introduction用于阐述项目基本情况和功能(是什么,用来做什么的)。Quick Start主要包括两部分内容:简易的安装部署说明(Deployment)和使用案例(Example)。Documentation部分是核心的文档,对于大型项目可以使用超链接代替。
参考:
1.2 版本管理规范
项目代码release包括三类:
- 大版本(x.0.0)
- 小版本(x.x.0)
- 补丁(x.x.x)
1.3 Git Commit代码提交规范
1.3.1 commit message格式
git commit 提交样式规范:
:
注意:冒号后面又空格
扫描二维码关注公众号,回复: 13465669 查看本文章
<类型>: <标题>
<空一行>
<内容>
1.3.2 格式说明
1. <类型>
用于说明 commit 的类别(type),只允许使用下面7个标识。
# 主要type
feat: 增加新功能
fix: 修复bug
# 特殊type
docs: 只改动了文档相关的内容
style: 不影响代码含义的改动,例如去掉空格、改变缩进、增删分号
build: 构造工具的或者外部依赖的改动,例如webpack,npm
refactor: 代码重构时使用,重构(即不是新增功能,也不是修改bug的代码变动)
revert: 执行git revert打印的message
# 暂不使用type
test: 添加测试或者修改现有测试
perf: 提高性能的改动
ci: 与CI(持续集成服务)有关的改动
chore: 不修改src或者test的其余修改,例如构建过程或辅助工具的变动
当一次改动包括主要type与特殊type时,统一采用主要type。
2. <标题>
commit 目的的简短描述,不超过50个字符
3. <内容>
对本次 commit 的详细描述,可以分成多行,可详细说明代码变动的动机。
1.3.3 示例
feat(compiler): 题目 #10286
对本次 commit 的详细描述,可以分成多行,可详细说明代码变动的动机
1.4 分支管理规范(新增PR规范,目前阶段非必要)
1.4.1 远程仓库
1.4.1.1 分支约束
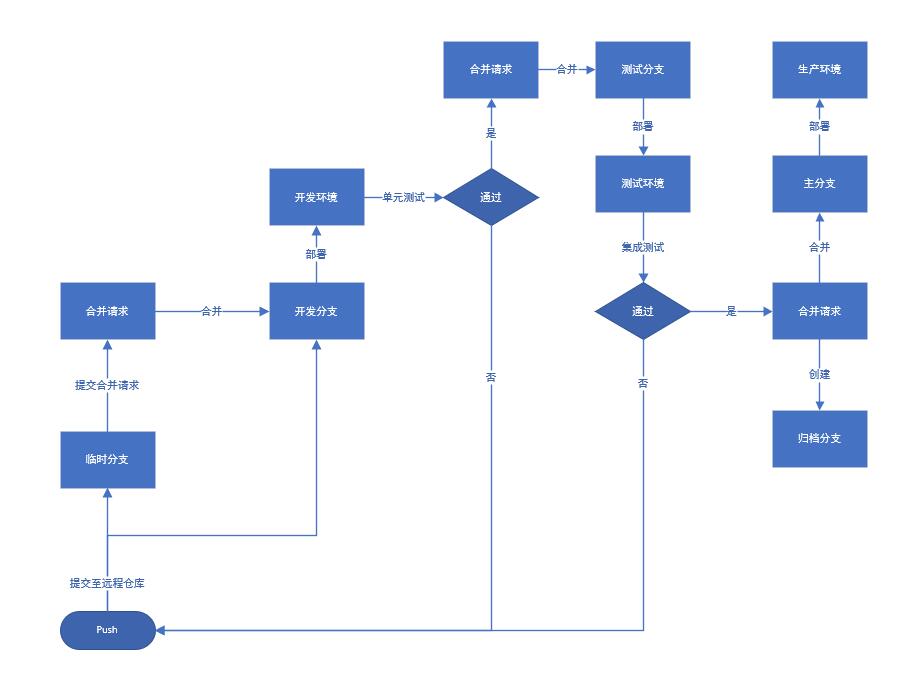
远程仓库只允许出现五种类型的分支:
- 主分支:项目的主要分支也就是master分支。用于正式发布,该分支禁止任何人直接提交,提交合并请求由对应项目主管人员确认合并。
- 开发分支:项目的开发迭代分支,用于开发发布,常规开发任务的代码直接提交至该分支或者由临时分支合并至该分支。
- 测试分支:项目的测试迭代分支,用户测试发布,该分支禁止任何人直接提交,提交合并请求由对应项目主管人员确认合并。
- 归档分支:项目的里程碑版本保留分支,由测试负责人、项目负责人、产品负责人直接定义版本,从测试分支归档出新分支。
- 临时分支:由项目的开发人员建立的临时分支,禁止交叉提交,谁建立的分支便由谁负责管理,用于合并至开发分支,合并完成之后禁止新提交应当立刻删除。
1.4.1.2 主分支
主分支全局仓库唯一,分支名称固定为master,任何对主分支的直接提交定性为严重违规行为,需要尝试对主分支进行合并应当由对应仓库的开发负责人提交合并请求并由上级负责人通过合并实现对主分支的变更。
1.4.1.3 开发分支
开发分支全局仓库唯一,分支名称固定为devLoop,开发人员允许对该分支直接提交,任何向开发分支提交的代码在提交之前应当保证能够正常通过编译、部署并运行,无法部署的提交应当立刻修复并重新提交。开发分支部署的代码应当由开发人员完成所有的单元测试,全部通过之后再向测试分支提交。
1.4.1.4 测试分支
测试分支全局仓库唯一,分支名称固定为testLooop,禁止直接对该分支提交,测试分支应当由开发分支提交合并请求而来,由开发人员提交合并请求,由主要开发人员通过合并请求实现测试部署。小型项目、中间件研发可以酌情省略测试分支,由开发分支部署交于测试进行质量校验,大型项目或产品必须保证有测试分支。
1.4.1.5 归档分支
归档分支全局仓管可以具备多个,直接由测试分支或主分支派生,除特殊情况下禁止任何提交行为,归档分支名称格式为release-版本号(如:release-1.2.0),分支由对应项目的开发主要负责人再与测试负责人沟通之后创建,已经后续无论是BUG、还是功能性问题都不应当项归档分支提交。
1.4.1.6 临时分支
临时分支全局仓库可以具备多个,临时分支名称格式为tem-开发者-创建时间(如:tem-tangyuecan-20200724),由开发人员自行创建,临时分支的提交进制交叉提交,只允许分支创建者提交,临时分支只能合并到开发分支一旦完成合并之后应当立即删除,可以直接本地合并之后向开发分支提交或者提交合并请求由开发负责人进行合并,临时分支的生命周期原则上不超过三个工作日。临时分支主要用于无法在短时间之内完成的开发工作,或者整合至开发分支之后无法运行情况,这样考虑之下才有临时分支的概念。
1.4.2 提交描述
所以代码的提交、合并都应该通过文字目前描述出改此提交、合并的目的如下面几种:
修复问题:#xxxx(禅道BUG的ID或者ISSUE)修复问题:xxxx(BUG的名称)完成功能:#xxxx(禅道的任务ID)完成功能:xxxxx(功能的名称)
任何无意义或者具体目的的提交禁止同步至远程仓库,包括远程临时分支(禁止commit)
1.4.3 合并流程
二、Java命名规范
2.1 Java中的命名规范
好的命名能体现出代码的特征,含义或者是用途,让阅读者可以根据名称的含义快速厘清程序的脉络。不同语言中采用的命名形式大相径庭,Java 中常用到的命名形式共有三种,既首字母大写的 UpperCamelCase ,首字母小写的 lowerCamelCase 以及全部大写的并用下划线分割单词的UPPER_CAMEL_UNSER_SCORE。通常约定,类一般采用大驼峰命名,方法和局部变量使用小驼峰命名,而大写下划线命名通常是常量和枚举中使用。
| 类型 | 约束 | 例 |
|---|---|---|
| 项目名 | 全部小写,多个单词用中划线分隔‘-’ | spring-cloud |
| 包名 | 全部小写 | com.alibaba.fastjson |
| 类名 | 单词首字母大写 | Feature, ParserConfig,DefaultFieldDeserializer |
| 变量名 | 首字母小写,多个单词组成时,除首个单词,其他单词首字母都要大写 | password, userName |
| 常量名 | 全部大写,多个单词,用’_'分隔 | CACHE_EXPIRED_TIME |
| 方法 | 同变量 | read(), readObject(), getById() |
2.2 包命名
包名统一使用小写,点分隔符之间有且仅有一个自然语义的英文单词或者多个单词自然连接到一块(如 springframework,deepspace 不需要使用任何分割)。包名统一使用单数形式,如果类命有复数含义,则可以使用复数形式。
包名的构成可以分为以下几四部分【前缀】 【发起者名】【项目名】【模块名】。常见的前缀可以分为以下几种:
| 前缀名 | 例 | 含义 |
|---|---|---|
| indi(或onem ) | indi.发起者名.项目名.模块名.…… | 个体项目,指个人发起,但非自己独自完成的项目,可公开或私有项目,copyright主要属于发起者。 |
| pers | pers.个人名.项目名.模块名.…… | 个人项目,指个人发起,独自完成,可分享的项目,copyright主要属于个人 |
| priv | priv.个人名.项目名.模块名.…… | 私有项目,指个人发起,独自完成,非公开的私人使用的项目,copyright属于个人。 |
| team | team.团队名.项目名.模块名.…… | 团队项目,指由团队发起,并由该团队开发的项目,copyright属于该团队所有 |
| 顶级域名 | com.公司名.项目名.模块名.…… | 公司项目,copyright由项目发起的公司所有 |
2.3 类命名
类名使用大驼峰命名形式,类命通常时名词或名词短语,接口名除了用名词和名词短语以外,还可以使用形容词或形容词短语,如 Cloneable,Callable 等,表示实现该接口的类有某种功能或能力。对于测试类则以它要测试的类开头,以 Test 结尾,如 HashMapTest。
对于一些特殊特有名词缩写也可以使用全大写命名,比如XMLHttpRequest,不过笔者认为缩写三个字母以内都大写,超过三个字母则按照要给单词算。这个没有标准如阿里巴巴中fastjson用JSONObject作为类命,而google则使用JsonObjectRequest 命名,对于这种特殊的缩写,原则是统一就好。
| 属性 | 约束 | 例 |
|---|---|---|
| 抽象类 | Abstract 或者 Base 开头 | BaseUserService |
| 枚举类 | Enum 作为后缀 | GenderEnum |
| 工具类 | Utils作为后缀 | StringUtils |
| 异常类 | Exception结尾 | RuntimeException |
| 接口实现类 | 接口名+ Impl | UserServiceImpl |
| 领域模型相关 | /DO/DTO/VO/DAO | 正例:UserDAO 反例: UserDo, UserDao |
| 设计模式相关类 | Builder,Factory等 | 当使用到设计模式时,需要使用对应的设计模式作为后缀,如ThreadFactory |
| 处理特定功能的 | Handler,Predicate, Validator | 表示处理器,校验器,断言,这些类工厂还有配套的方法名如handle,predicate,validate |
| 测试类 | Test结尾 | UserServiceTest, 表示用来测试UserService类的 |
| MVC分层 | Controller,Service,ServiceImpl,DAO后缀 | UserManageController,UserManageDAO |
2.4 方法
方法命名采用小驼峰的形式,首字小写,往后的每个单词首字母都要大写。 和类名不同的是,方法命名一般为动词或动词短语,与参数或参数名共同组成动宾短语,即动词 + 名词。一个好的函数名一般能通过名字直接获知该函数实现什么样的功能。
2.4.1 返回真伪值的方法
注:Prefix-前缀,Suffix-后缀,Alone-单独使用
| 位置 | 单词 | 意义 | 例 |
|---|---|---|---|
| Prefix | is | 对象是否符合期待的状态 | isValid |
| Prefix | can | 对象能否执行所期待的动作 | canRemove |
| Prefix | should | 调用方执行某个命令或方法是好还是不好,应不应该,或者说推荐还是不推荐 | shouldMigrate |
| Prefix | has | 对象是否持有所期待的数据和属性 | hasObservers |
| Prefix | needs | 调用方是否需要执行某个命令或方法 | needsMigrate |
2.4.2 用来检查的方法
| 单词 | 意义 | 例 |
|---|---|---|
| ensure | 检查是否为期待的状态,不是则抛出异常或返回error code | ensureCapacity |
| validate | 检查是否为正确的状态,不是则抛出异常或返回error code | validateInputs |
2.4.3 按需求才执行的方法
| 位置 | 单词 | 意义 | 例 |
|---|---|---|---|
| Suffix | IfNeeded | 需要的时候执行,不需要的时候什么都不做 | drawIfNeeded |
| Prefix | might | 同上 | mightCreate |
| Prefix | try | 尝试执行,失败时抛出异常或是返回errorcode | tryCreate |
| Suffix | OrDefault | 尝试执行,失败时返回默认值 | getOrDefault |
| Suffix | OrElse | 尝试执行、失败时返回实际参数中指定的值 | getOrElse |
| Prefix | force | 强制尝试执行。error抛出异常或是返回值 | forceCreate, forceStop |
2.4.4 异步相关方法
| 位置 | 单词 | 意义 | 例 |
|---|---|---|---|
| Prefix | blocking | 线程阻塞方法 | blockingGetUser |
| Suffix | InBackground | 执行在后台的线程 | doInBackground |
| Suffix | Async | 异步方法 | sendAsync |
| Suffix | Sync | 对应已有异步方法的同步方法 | sendSync |
| Prefix or Alone | schedule | Job和Task放入队列 | schedule, scheduleJob |
| Prefix or Alone | post | 同上 | postJob |
| Prefix or Alone | execute | 执行异步方法(注:我一般拿这个做同步方法名) | execute, executeTask |
| Prefix or Alone | start | 同上 | start, startJob |
| Prefix or Alone | cancel | 停止异步方法 | cancel, cancelJob |
| Prefix or Alone | stop | 同上 | stop, stopJob |
2.4.5 回调方法
| 位置 | 单词 | 意义 | 例 |
|---|---|---|---|
| Prefix | on | 事件发生时执行 | onCompleted |
| Prefix | before | 事件发生前执行 | beforeUpdate |
| Prefix | pre | 同上 | preUpdate |
| Prefix | will | 同上 | willUpdate |
| Prefix | after | 事件发生后执行 | afterUpdate |
| Prefix | post | 同上 | postUpdate |
| Prefix | did | 同上 | didUpdate |
| Prefix | should | 确认事件是否可以发生时执行 | shouldUpdate |
2.4.6 操作对象生命周期的方法
| 单词 | 意义 | 例 |
|---|---|---|
| initialize | 初始化。也可作为延迟初始化使用 | initialize |
| pause | 暂停 | onPause ,pause |
| stop | 停止 | onStop,stop |
| abandon | 销毁的替代 | abandon |
| destroy | 同上 | destroy |
| dispose | 同上 | dispose |
2.4.7 与集合操作相关的方法
| 单词 | 意义 | 例 |
|---|---|---|
| contains | 是否持有与指定对象相同的对象 | contains |
| add | 添加 | addJob |
| append | 添加 | appendJob |
| insert | 插入到下标n | insertJob |
| put | 添加与key对应的元素 | putJob |
| remove | 移除元素 | removeJob |
| enqueue | 添加到队列的最末位 | enqueueJob |
| dequeue | 从队列中头部取出并移除 | dequeueJob |
| push | 添加到栈头 | pushJob |
| pop | 从栈头取出并移除 | popJob |
| peek | 从栈头取出但不移除 | peekJob |
| find | 寻找符合条件的某物 | findById |
2.4.8 与数据相关的方法
| 单词 | 意义 | 例 |
|---|---|---|
| create | 新创建 | createAccount |
| new | 新创建 | newAccount |
| from | 从既有的某物新建,或是从其他的数据新建 | fromConfig |
| to | 转换 | toString |
| update | 更新既有某物 | updateAccount |
| load | 读取 | loadAccount |
| fetch | 远程读取 | fetchAccount |
| delete | 删除 | deleteAccount |
| remove | 删除 | removeAccount |
| save | 保存 | saveAccount |
| store | 保存 | storeAccount |
| commit | 保存 | commitChange |
| apply | 保存或应用 | applyChange |
| clear | 清除数据或是恢复到初始状态 | clearAll |
| reset | 清除数据或是恢复到初始状态 | resetAll |
2.4.9 成对出现的动词
| 单词 | 意义 |
|---|---|
| get获取 | set 设置 |
| add 增加 | remove 删除 |
| create 创建 | destory 移除 |
| start 启动 | stop 停止 |
| open 打开 | close 关闭 |
| read 读取 | write 写入 |
| load 载入 | save 保存 |
| create 创建 | destroy 销毁 |
| begin 开始 | end 结束 |
| backup 备份 | restore 恢复 |
| import 导入 | export 导出 |
| split 分割 | merge 合并 |
| inject 注入 | extract 提取 |
| attach 附着 | detach 脱离 |
| bind 绑定 | separate 分离 |
| view 查看 | browse 浏览 |
| edit 编辑 | modify 修改 |
| select 选取 | mark 标记 |
| copy 复制 | paste 粘贴 |
| undo 撤销 | redo 重做 |
| insert 插入 | delete 移除 |
| add 加入 | append 添加 |
| clean 清理 | clear 清除 |
| index 索引 | sort 排序 |
| find 查找 | search 搜索 |
| increase 增加 | decrease 减少 |
| play 播放 | pause 暂停 |
| launch 启动 | run 运行 |
| compile 编译 | execute 执行 |
| debug 调试 | trace 跟踪 |
| observe 观察 | listen 监听 |
| build 构建 | publish 发布 |
| input 输入 | output 输出 |
| encode 编码 | decode 解码 |
| encrypt 加密 | decrypt 解密 |
| compress 压缩 | decompress 解压缩 |
| pack 打包 | unpack 解包 |
| parse 解析 | emit 生成 |
| connect 连接 | disconnect 断开 |
| send 发送 | receive 接收 |
| download 下载 | upload 上传 |
| refresh 刷新 | synchronize 同步 |
| update 更新 | revert 复原 |
| lock 锁定 | unlock 解锁 |
| check out 签出 | check in 签入 |
| submit 提交 | commit 交付 |
| push 推 | pull 拉 |
| expand 展开 | collapse 折叠 |
| begin 起始 | end 结束 |
| start 开始 | finish 完成 |
| enter 进入 | exit 退出 |
| abort 放弃 | quit 离开 |
| obsolete 废弃 | depreciate 废旧 |
| collect 收集 | aggregate 聚集 |
2.5 变量&常量命名
2.5.1 变量命名
变量是指在程序运行中可以改变其值的量,包括成员变量和局部变量。变量名由多单词组成时,第一个单词的首字母小写,其后单词的首字母大写,俗称骆驼式命名法(也称驼峰命名法),如 computedValues,index、变量命名时,尽量简短且能清楚的表达变量的作用,命名体现具体的业务含义即可。
变量名不应以下划线或美元符号开头,尽管这在语法上是允许的。变量名应简短且富于描述。变量名的选用应该易于记忆,即,能够指出其用途。尽量避免单个字符的变量名,除非是一次性的临时变量。pojo中的布尔变量,都不要加is(数据库中的布尔字段全都要加 is_ 前缀)。
2.5.2 常量命名
常量命名CONSTANT_CASE,一般采用全部大写(作为方法参数时除外),单词间用下划线分割。那么什么是常量呢?
常量是在作用域内保持不变的值,一般使用final进行修饰。一般分为三种,全局常量(public static final修饰),类内常量(private static final 修饰)以及局部常量(方法内,或者参数中的常量),局部常量比较特殊,通常采用小驼峰命名即可。
public class HelloWorld {
/**
* 局部常量(正例)
*/
public static final long USER_MESSAGE_CACHE_EXPIRE_TIME = 3600;
/**
* 局部常量(反例,命名不清晰)
*/
public static final long MESSAGE_CACHE_TIME = 3600;
/**
* 全局常量
*/
private static final String ERROR_MESSAGE = " error message";
/**
* 成员变量
*/
private int currentUserId;
/**
* 控制台打印 {@code message} 信息
*
* @param message 消息体,局部常量
*/
public void sayHello(final String message){
System.out.println("Hello world!");
}
}
常量一般都有自己的业务含义,不要害怕长度过长而进行省略或者缩写。如,用户消息缓存过期时间的表示,那种方式更佳清晰,交给你来评判。
2.5.3 通用命名规则
- 尽量不要使用拼音;杜绝拼音和英文混用。对于一些通用的表示或者难以用英文描述的可以采用拼音,一旦采用拼音就坚决不能和英文混用。 正例: BeiJing, HangZhou 反例: validateCanShu
- 命名过程中尽量不要出现特殊的字符,常量除外。
- 尽量不要和jdk或者框架中已存在的类重名,也不能使用java中的关键字命名。
- 妙用介词,如for(可以用同音的4代替), to(可用同音的2代替), from, with,of等。 如类名采用User4RedisDO,方法名getUserInfoFromRedis,convertJson2Map等。
2.6 代码注解
2.6.1 注解的原则
好的命名增加代码阅读性,代码的命名往往有严格的限制。而注解不同,程序员往往可以自由发挥,单并不意味着可以为所欲为之胡作非为。优雅的注解通常要满足三要素。
- Nothing is strange 没有注解的代码对于阅读者非常不友好,哪怕代码写的在清除,阅读者至少从心理上会有抵触,更何况代码中往往有许多复杂的逻辑,所以一定要写注解,不仅要记录代码的逻辑,还有说清楚修改的逻辑。
- Less is more 从代码维护角度来讲,代码中的注解一定是精华中的精华。合理清晰的命名能让代码易于理解,对于逻辑简单且命名规范,能够清楚表达代码功能的代码不需要注解。滥用注解会增加额外的负担,更何况大部分都是废话。
// 根据id获取信息【废话注解】
getMessageById(id)
- Advance with the time 注解应该随着代码的变动而改变,注解表达的信息要与代码中完全一致。通常情况下修改代码后一定要修改注解。
2.6.2 注解格式
注解大体上可以分为两种,一种是javadoc注解,另一种是简单注解。javadoc注解可以生成JavaAPI为外部用户提供有效的支持javadoc注解通常在使用IDEA,或者Eclipse等开发工具时都可以自动生成,也支持自定义的注解模板,仅需要对对应的字段进行解释。参与同一项目开发的同学,尽量设置成相同的注解模板。
a. 包注解
包注解在工作中往往比较特殊,通过包注解可以快速知悉当前包下代码是用来实现哪些功能,强烈建议工作中加上,尤其是对于一些比较复杂的包,包注解一般在包的根目录下,名称统一为package-info.java。
/**
* 落地也质量检测
* 1. 用来解决什么问题
* 对广告主投放的广告落地页进行性能检测,模拟不同的系统,如Android,IOS等; 模拟不同的网络:2G,3G,4G,wifi等
*
* 2. 如何实现
* 基于chrome浏览器,用chromedriver驱动浏览器,设置对应的网络,OS参数,获取到浏览器返回结果。
*
* 注意: 网络环境配置信息{@link cn.mycookies.landingpagecheck.meta.NetWorkSpeedEnum}目前使用是常规速度,可以根据实际情况进行调整
*
* @author author
* @time 2019/12/7 20:3 下午
*/
package cn.mycookies.landingpagecheck;
b. 类注接
javadoc注解中,每个类都必须有注解。
/**
* Copyright (C), 2019-2020, Jann balabala...
*
* 类的介绍:这是一个用来做什么事情的类,有哪些功能,用到的技术.....
*
* @author 类创建者姓名 保持对齐
* @date 创建日期 保持对齐
* @version 版本号 保持对齐
*/
c. 属性注解
在每个属性前面必须加上属性注释,通常有一下两种形式,至于怎么选择,你高兴就好,不过一个项目中要保持统一。
/** 提示信息 */
private String userName;
/**
* 密码
*/
private String password;
d. 方法注释
在每个方法前面必须加上方法注释,对于方法中的每个参数,以及返回值都要有说明。
/**
* 方法的详细说明,能干嘛,怎么实现的,注意事项...
*
* @param xxx 参数1的使用说明, 能否为null
* @return 返回结果的说明, 不同情况下会返回怎样的结果
* @throws 异常类型 注明从此类方法中抛出异常的说明
*/
e. 构造方法注释
在每个构造方法前面必须加上注释,注释模板如下:
/**
* 构造方法的详细说明
*
* @param xxx 参数1的使用说明, 能否为null
* @throws 异常类型 注明从此类方法中抛出异常的说明
*/
而简单注解往往是需要工程师字节定义,在使用注解时应该注意一下几点:
- 枚举类的各个属性值都要使用注解,枚举可以理解为是常量,通常不会发生改变,通常会被在多个地方引用,对枚举的修改和添加属性通常会带来很大的影响。
- 保持排版整洁,不要使用行尾注释;双斜杠和星号之后要用1个空格分隔。
int id = 1;// 反例:不要使用行尾注释
//反例:换行符与注释之间没有缩进
int age = 18;
// 正例:姓名
String name;
/**
* 1. 多行注释
*
* 2. 对于不同的逻辑说明,可以用空行分隔
*/
三、代码开发规范
3.1 工程名称命名
- 工程命名由三部分组成:前缀-项目名称-后缀。
- 工程根据功能分为:手机工程和一般性工程,手机工程主要给手机端及app提供页面和接口,除手机之外的工程统一称为一般性工程,由前缀决定。
- 工程根据访问渠道分为:外部工程和内部工程,外部工程的主要用户为外部注册用户,对公网开放,内部工程的访问用户为公司内部人员,只能在公司内网访问,由后缀决定。
3.1.1 前缀:前缀决定工程的功能
| 前缀 | 说明 |
|---|---|
| mobile | 基于手机浏览器的web项目,主要提供h5页面 |
| android | 关于安卓手机的native app项目 |
| ios | 关于ios手机的native app项目 |
| ins | 公司的一般项目,非手机类项目都使用该前缀 |
3.1.2 项目名称
项目名称需要和项目内容非常贴切,让人一看就知道项目是干什么的,命名需要leader、部门总监,一起评审,通过后才能使用。
3.1.3 后缀:后缀决定工程的功能和使用用户
| 后缀 | 说明 |
|---|---|
| front | 前端项目 |
| web | 外部工程,提供json请求,不能提供RPC接口,此类工程偏向于提供web页面业务为主 |
| proxy | 外部工程,提供对外调用接口,不能提供RPC接口,此类工程偏向于提供外部接口为主 |
| platform | 内部工程,主要提供RPC接口服务,另:可以只为技术人员提供一些监控管理的页面,此类工程偏向于RPC接口为主且只能内网访问 |
| internal | 内部工程,即可以提供RPC接口服务也可以提供json请求,但以json请求为主。此类工程偏向于提供后台页面为主且只能内网访问,如果此类工程的业务名跟platform工程的业务名同名,则在业务名后跟admin,以免他们的client重名冲突。比如:ins-xy-platform 和 ins-xy-internal 后者应该改为ins-xyadmin-internal. |
| task | 以main函数存在的,通常是以jar包的形式,不需要容器,独立运行 |
| app | 手机上安装的软件 |
| client | 提供sdk的客户端 |
| util | 工具包(ins-utility应该改名为ins-common-util) |
3.1.3.1 示例
1、车路协同单体提供pc端访问的项目应该叫:ins-cvis-web,为车路协同提供手机端页面访问的项目应该叫:mobile-cvis-web。
2、车路协同给其他端提供业务接口调用的项目应该叫:ins-cvis-platform,为公司内部业务人员提供页面访问的项目应该叫:ins-cvis-internal。
3、给app提供外部接口支持的项目应该叫:ins-xxx-proxy。
4、像文件系统(lpfs)即需要提供管理页面,又需要提供RPC接口调用,还需要给外网提供接口和页面的项目需要根据访问渠道分成外部工程和内部工程两个工程,
外部工程应该命名为:ins-lpfs-proxy,因为主要以提供外部接口为主所以后缀应该为proxy。
5、内部工程应该命名为:ins-lpfs-platform,因为主要以RPC接口为主,且提供的页面只为内部技术人员使用,所以后缀应该为platform,如果提供的页面是给业务人员使用则应该为:ins-lpfs-internal。
3.1.4 工程结构包名
com.hiacent.项目名称.web/platform【.模块名】。
如果只有一个业务模块,则业务模块级可以省略。
例如 :
-
ins-biz-web: 工程结构包名:com.hiacent.biz.web【.模块名】
-
ins-user-platform:工程结构包名:com.hiacent.user.platform【.模块名】
工程字符集: 工程符集全部设定为UTF-8格式
3.2 继承结构及工程规范
| 模块名称 | 模块说明 | 示例 | 备注 |
|---|---|---|---|
| entity层 | 实体类命名与表名相同,首字母大写,如果表名存在_那么将_这去掉后首字母大写。 | 表名:like_log 实体名 LikeLog | 实体类属性必须与数据库字段名保持一致。 |
| dao层 | 继承com.baomidou.mybatisplus.core.mapper.BaseMapper 要求实体泛型dao层下接口命名:实体名+Mapper 。 | LikeLogMapper | |
| service层 | 要求:接口继承com.baomidou.mybatisplus.extension.service.IService要求实体泛型 | ||
| service.impl层类 | 继承com.baomidou.mybatisplus.extension.service.impl.ServiceImpl,service层下接口命名:业务名称+Service 。service.impl层命名: 业务名称+ServiceImpl 。 | LikeLogService;LikeLogServiceImpl | service层可以调用service层和dao层和其他项目。 service层下可再包一层bean层,用以存放数据结构的类,必须以Bean结尾。 平台service层内部调用的方法可以返回entity,但是被manage层调用的service方法只能返回dto或基本数据类型,不能返回entity到manage。 |
| manage层 | 调用其他服务的接口,通常使用Feign来实现 | ILikeLogMange | manage层下接口命名:I+业务名称+Manage。 |
| controller层 | 继承: org.jeecg.common.system.base.controller.JeecgController<T, S extends IService>controller层命名:以Controller结尾。 | LikeLogController | web/proxy/internal可用;controller层不能出现dto |
| form层 | web/proxy/internal可用;form下类命名:以Form结尾。 | LikeBaseInfoForm | form可以引用其他form form中不可以包含dto |
| dto层 | internal/platform 可用;dto层命名:以Dto结尾,前缀不一定是entity。 | LikeLogDto | dto不能引用别人的dto |
| schedule类 | schedule层命名: 以业务名称开头,以Schedule结尾,前缀不一定是entity。 | SendEmailSchedule | |
| Idp类 | idp层命名:以IdpHandler结尾。 | ResumeIdpHandler | |
| util层 | util层命名:以Util或Utils结尾。 | MoneyUtil | |
| consts层 | 静态变量类consts层命名:以Const结尾。 | LikeLogConst | |
| helper层 | helper层命名:client名+Helper结尾。 | UserPlatformClientHelper | Helper层主要放置调用其它端client的工具类; Helper只可以出现调平台的代码和处理平台返回错误的代码; Helper不允许调其他helper; |
| filter | filter命名:以Filter结尾。 | AuthFilter | 只能出现在common包下面的filter包中 |
| resolver | 包名只能叫resolver且同一工程下只能有一个resolve包,只能出现在common包下的resolver包中,此包下只能有一个类文件且名称为:MvcExceptionResolver。 |
3.3 数据结构体标准
dto,form,entity,bean四者间的转换只能通过手动get,set方式赋值。
类的静态变量、静态区域块、构造函数中,不允许出现数据库的调用和RPC的调用。
3.3.1 命名标准
同一工程下的受spring管理的类的类名不能相同,即使包名不同也不允许类名相同。
3.3.2 通用标准
Ajax方法里不能声明callback参数,因为此参数在使用跨域时做为系统占用参数。
所有可以通过网页端访问的URL命名统一全小写,可以在单词之间用“-”(减号)分隔,controller采用骆峰格式命名两者除了大小写之外其他尽量保持相同。
例:@RequestMapping("/getassesseeandbranch")
-
所有RPC接口统一用驼峰形式。
-
返回值是json格式URL名必须是以.json结尾.
3.4 Web URL标准
- Controller中URL的requestMapping不能以"/"结尾 。
例:@RequestMapping("/getassesseeandbranch")
- 在前端页面中书写的URL必须以“/”结尾。
- 所有非登录能访问的目录型url(不是以.*结尾的url),如果访问时没有“/”结尾,则需要自动加上“/”并作301跳转。
例如:http://www.hiacent.com/login?name=xxx应该301跳转到http://www.hiacent.com/login/?name=xxx。此条只针对get请求。
- 所有非登录能访问的列表页面,所有翻页都需要修改成 http://www.hiacent.com/list/pnX/ (X为页码)的形式。
- ajax翻页的不用遵循这个规范。
3.4.1 Ajax URL标准
- Ajax方法必须以.json结尾。
例:@RequestMapping("/getuser.json")
- header头信息里包括X-Requested-With=XMLHttpRequest 或者 带有callback参数。
3.4.2 APP URL标准
- APP方法必须以.json结尾。
例:@RequestMapping("/getuser.json")
- 请求都是压缩格式,header头信息里包括accept-encoding=gzip,不能包含X-Requested-With=XMLHttpRequest头信息或callback参数。
3.4.3 Ajax使用
ajax请求以.json结尾,header头信息里包括X-Requested-With=XMLHttpRequest 或者 带有callback参数请求并且是.json后缀的访问也属于ajax请求。
- ajax和web根据功能放在同一controller里。
请求参数放在方法行参里,不在使用reqeust获取请求参数,扁平化参数或封装form对象,controller方法参数扁平话后,大家写对象时一定要定义成Form,不要用弱对象map这些类型。
-
controller方法参数不再有HttpServletRequest、HttpServletResponse,统一在继承的父类AbstractController提供方法操作,如cookie、文件下载等。
-
返回结果使用方法直接返回ajax方法并且,返回值是json格式的方法的返回值不需要自己转换json。
请求形式:http://domain.hiacent.com/uri?key1=value1&key2=value2&...
返回协议体:{
"flag":1,"data":{
},"code":"","msg":""}
例:
@RequestMapping("/aap.json")
public List<Integer> aaph(Model model) throws BizException {
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
return list;
}
3.4.4 Ajax返回数据规范
// 正常返回
{
"flag": 1, // 数据状态标识
"data": {
// 正常返回的相关数据,可以是 Object / Array
...
}
}
// 异常返回
{
"flag": 0, // 数据状态标识
"code": "***", // 异常标识code
"msg": "some error message." // 异常提示信息
}
在正常情况下,后台只返回 flag 和 data 两个字段,异常情况下,返回 flag / code 和 msg 三个字段。
对于复杂业务场景,返回正常数据可能包含多种情况,以下面的方式来约束:
{
"flag": 1,
"data": {
"biz_code": "***",
"msg": "some notice message.",
"***": some value
}
}
和前端约定:成功失败的返回值(成功flag=1,失败flag=0)。
3.5 手机app请求手机app请求
请求以.json结尾,请求都是压缩格式,header头信息里包括accept-encoding=gzip。
请求参数放在方法行参里,不在使用reqeust获取请求参数,扁平化参数或封装form对象,请求参数放在方法行参里,不在使用reqeust获取请求参数,扁平化参
数或封装form对象,controller方法参数扁平话后,大家写对象时一定要定义成Form,不要用弱对象map这些类型。
返回结果使用方法直接返回。
请求参数形式:http://domain.lietou.com/uri?mustKey1=v1&mustKey2=v2&data={}
兼容版本 返回的协议体:
{
"message": "OK",
"status": 0,
"data": {
},
"flag": 1
}
最终版本和ajax返回一样。
3.6 Cache使用
关于缓存的使用规范
-
所有业务缓存、二级缓存缓存都用redis,不能用memcache。
-
redis只用作不持久化的缓存
四、数据库设计规范
4.1 数据库命令规范
1、所有数据库对象名称必须使用小写字母并用下划线分割
2、所有数据库对象名称禁止使用mysql保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)
3、数据库对象的命名要能做到见名识意,并且最后不要超过32个字符
4、临时库表必须以tmp_为前缀并以日期为后缀,备份表必须以bak_为前缀并以日期(时间戳)为后缀
5、所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)
4.1.1 数据库命名规范
采用小写字母、数字(通常不需要)和下划线组成。禁止使用’-’,命名简洁、含义明确。
4.1.2 表命名
-
根据业务类型不同,采用不同的前缀,小写字母、下划线组成
-
长度控制在30个字符以内
推荐的命名规则
类型 前缀 说明 业务表 tb_ 关系表 tr_ 历史表 th_ 统计表 ts_ 日志表 tl_xx_log 系统表、字典表、码表 sys_ 临时表 tmp_ 禁止使用 备份表 bak_xx_ymd 视图 view_ 避免使用
4.2 数据库基本设计规范
4.2.1 所有表必须使用Innodb存储引擎
没有特殊要求(即Innodb无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用Innodb存储引擎(mysql5.5之前默认使用Myisam,5.6以后默认的为Innodb)Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
4.2.2 数据库和表的字符集统一使用utf8mb4
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效。
- 解读:在Mysql中的UTF-8并非“真正的UTF-8”,而utf8mb4”才是真正的“UTF-8”。
4.2.3 所有表和字段都需要添加注释
使用comment从句添加表和列的备注 从一开始就进行数据字典的维护
4.2.4 尽量控制单表数据量的大小,建议控制在500万以内
500万并不是MySQL数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题
可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
4.2.5 谨慎使用MySQL分区表
分区表在物理上表现为多个文件,在逻辑上表现为一个表 谨慎选择分区键,跨分区查询效率可能更低 建议采用物理分表的方式管理大数据
4.2.6 尽量做到冷热数据分离,减小表的宽度
MySQL限制每个表最多存储4096列,并且每一行数据的大小不能超过65535字节 减少磁盘IO,保证热数据的内存缓存命中率(表越宽,把表装载进内存缓冲池时所占用的内存也就越大,也会消耗更多的IO) 更有效的利用缓存,避免读入无用的冷数据 经常一起使用的列放到一个表中(避免更多的关联操作)
4.2.7 禁止在表中建立预留字段
预留字段的命名很难做到见名识义 预留字段无法确认存储的数据类型,所以无法选择合适的类型 对预留字段类型的修改,会对表进行锁定
4.2.8 禁止在数据库中存储图片,文件等大的二进制数据
通常文件很大,会短时间内造成数据量快速增长,数据库进行数据库读取时,通常会进行大量的随机IO操作,文件很大时,IO操作很耗时 通常存储于文件服务器,数据库只存储文件地址信息
4.2.9 每张表必须设置一个主键ID,且这个主键ID使用自增主键(在满足需要的情况下尽量短),除非在分库分表环境下
- 解读:由于InnoDB组织数据的方式决定了需要有一个主键,而且若是这个主键ID是单调递增的可以有效提高插入的性能,避免过多的页分裂、减少表碎片提高空间的使用率。 而在分库分表环境下,则需要统一来分配各个表中的主键值,从而避免整个逻辑表中主键重复。
4.2.10 禁止使用外键,如果有外键完整性约束,需要应用程序控制
- 解读:外键会导致表与表之间耦合,UPDATE与DELETE操作都会涉及相关联的表,十分影响SQL的性能,甚至会造成死锁。
4.2.11 单表列数目必须小于30,若超过则应该考虑将表拆分
- 解读:单表列数太多使得Mysql服务器处理InnoDB返回数据之间的映射成本太高。
4.2.12 禁止在线上做数据库压力测试
4.2.13 禁止从开发环境,测试环境直接连接生成环境数据库
4.3 数据库字段设计规范
4.3.1 优先选择符合存储需要的最小的数据类型
原因
列的字段越大,建立索引时所需要的空间也就越大,这样一页中所能存储的索引节点的数量也就越少也越少,在遍历时所需要的IO次数也就越多, 索引的性能也就越差
方法
1)将字符串转换成数字类型存储,如:将IP地址转换成整形数据。
mysql提供了两个方法来处理ip地址:
inet_aton 把ip转为无符号整型(4-8位)
inet_ntoa 把整型的ip转为地址
插入数据前,先用inet_aton把ip地址转为整型,可以节省空间。显示数据时,使用inet_ntoa把整型的ip地址转为地址显示即可。
2)对于非负型的数据(如自增ID、整型IP)来说,要优先使用无符号整型来存储
因为:无符号相对于有符号可以多出一倍的存储空间
SIGNED INT -2147483648~2147483647
UNSIGNED INT 0~4294967295
VARCHAR(N)中的N代表的是字符数,而不是字节数
使用UTF8存储255个汉字 Varchar(255)=765个字节。过大的长度会消耗更多的内存
4.3.2 避免使用TEXT、BLOB数据类型,最常见的TEXT类型可以存储64k的数据
建议把BLOB或是TEXT列分离到单独的扩展表中
Mysql内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。
而且对于这种数据,Mysql还是要进行二次查询,会使sql性能变得很差,但是不是说一定不能使用这样的数据类型。
如果一定要使用,建议把BLOB或是TEXT列分离到单独的扩展表中,查询时一定不要使用select * 而只需要取出必要的列,不需要TEXT列的数据时不要对该列进行查询。
TEXT或BLOB类型只能使用前缀索引
因为MySQL对索引字段长度是有限制的,所以TEXT类型只能使用前缀索引,并且TEXT列上是不能有默认值的。
4.3.3 避免使用ENUM类型
1、修改ENUM值需要使用ALTER语句
2、ENUM类型的ORDER BY操作效率低,需要额外操作
3、禁止使用数值作为ENUM的枚举值
4.3.4 必须把字段定义为NOT NULL并且提供默认值
原因:
1、索引NULL列需要额外的空间来保存,所以要占用更多的空间;
2、进行比较和计算时要对NULL值做特别的处理
- 解读:
- NULL的列使索引/索引统计/值比较都更加复杂,对MySQL来说更难优化;
- NULL这种类型Msql内部需要进行特殊处理,增加数据库处理记录的复杂性;同等条件下,表中有较多空字段的时候,数据库的处理性能会降低很多;
- NULL值需要更多的存储空,无论是表还是索引中每行中的NULL的列都需要额外的空间来标识。
4.3.5 使用TIMESTAMP(4个字节)或DATETIME类型(8个字节)存储时间
TIMESTAMP 存储的时间范围 1970-01-01 00:00:01 ~ 2038-01-19-03:14:07。
TIMESTAMP 占用4字节和INT相同,但比INT可读性高
超出TIMESTAMP取值范围的使用DATETIME类型存储。
经常会有人用字符串存储日期型的数据(不正确的做法):
缺点1:无法用日期函数进行计算和比较
缺点2:用字符串存储日期要占用更多的空间
4.3.6 同财务相关的金额类数据必须使用decimal类型
1、非精准浮点:float,double
2、精准浮点:decimal
Decimal类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每4个字节可以存储9位数字,并且小数点要占用一个字节。可用于存储比bigint更大的整型数据。
4.3.7 如果存储的字符串长度几乎相等,使用CHAR定长字符串类型。
- 解读:能够减少空间碎片,节省存储空间。
4.3.8 禁用保留字,如DESC、RANGE、MARCH等,请参考Mysql官方保留字
4.4 索引设计规范
4.4.1 限制每张表上的索引数量,建议单张表索引不超过5个
索引并不是越多越好!索引可以提高效率同样可以降低效率。
索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
因为mysql优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加mysql优化器生成执行计划的时间,同样会降低查询性能。
4.4.2 禁止给表中的每一列都建立单独的索引
5.6版本之前,一个sql只能使用到一个表中的一个索引,5.6以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好
4.4.3 每个Innodb表必须有个主键
Innodb是一种索引组织表:数据的存储的逻辑顺序和索引的顺序是相同的。
每个表都可以有多个索引,但是表的存储顺序只能有一种 Innodb是按照主键索引的顺序来组织表的。
不要使用更新频繁的列作为主键,不适用多列主键(相当于联合索引) 不要使用UUID、MD5、HASH、字符串列作为主键(无法保证数据的顺序增长)。
主键建议使用自增ID值。
4.4.4 索引规约
【建议】(1)避免在更新比较频繁、区分度不高的列上单独建立索引
- 解读:区分度不高的列单独创建索引的优化效果很小,但是较为频繁的更新则会让索引的维护成本更高。
【强制】(2) JOIN的表不允许超过五个。需要JOIN的字段,数据类型必须绝对一致; 多表关联查询时,保证被关联的字段需要有索引
-
解读:太多表的JOIN会让Mysql的优化器更难权衡出一个“最佳”的执行计划(可能性为表数量的阶乘),同时要注意关联字段的类型、长度、字符编码等等是否一致。
【强制】(3)在一个联合索引中,若第一列索引区分度等于1,那么则不需要建立联合索引
-
解读:索引通过第一列就能够完全定位的数据,所以联合索引的后边部分是不需要的。
【强制】(4)建立联合索引时,必须将区分度更高的字段放在左
- 解读:区分度更高的列放在左边,能够在一开始就有效的过滤掉无用数据。提高索引的效率,相应我们在Mapper中编写SQL的WHERE条件中有多个条件时,需要先看看当前表是否有现成的联合索引直接使用,注意各个条件的顺序尽量和索引的顺序一致。
【建议】(5)利用覆盖索引来进行查询操作,避免回表
- 解读:覆盖查询即是查询只需要通过索引即可拿到所需DATA,而不再需要再次回表查询,所以效率相对很高。我们在使用EXPLAIN的结果,extra列会出现:“using index”。这里也要强调一下不要使用“SELECT * ”,否则几乎不可能使用到覆盖索引。
【建议】(6)在较长VARCHAR字段,例如VARCHAR(100)上建立索引时,应指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度即可
- 解读:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,若长度为20的索引,区分度会高达90%以上,则可以考虑创建长度例为20的索引,而非全字段索引。例如可以使用SELECT COUNT(DISTINCT LEFT(lesson_code, 20)) / COUNT(*) FROM lesson;来确定lesson_code字段字符长度为20时文本区分度。
【建议】(7)如果有ORDER BY的场景,请注意利用索引的有序性。ORDER BY最后的字段是联合索引的一部分,并且放在索引组合顺序的最后,避免出现file_sort的情况,影响查询性能。
- 解读:
- 假设有查询条件为WHERE a=? and b=? ORDER BY c;存在索引:a_b_c,则此时可以利用索引排序;
- 反例:在查询条件中包含了范围查询,那么索引有序性无法利用,如:WHERE a>10 ORDER BY b; 索引a_b无法排序。
【建议】(8)在where中索引的列不能某个表达式的一部分,也不能是函数的参数
- 解读:即是某列上已经添加了索引,但是若此列成为表达式的一部分、或者是函数的参数,Mysql无法将此列单独解析出来,索引也不会生效。
【建议】 (9)我们在where条件中使用范围查询时,索引最多用于一个范围条件,超过一个则后边的不走索引
- 解读:Mysql能够使用多个范围条件里边的最左边的第一个范围查询,但是后边的范围查询则无法使用。
【建议】 (10)在多个表进行外连接时,表之间的关联字段类型必须完全一致
- 解读:当两个表进行Join时,字段类型若没有完全一致,则加索引也不会生效,这里的完全一致包括但不限于字段类型、字段长度、字符集、collection等等。
4.5 常见索引列建议
1、出现在SELECT、UPDATE、DELETE语句的WHERE从句中的列
2、包含在ORDER BY、GROUP BY、DISTINCT中的字段
并不要将符合1和2中的字段的列都建立一个索引,通常将1、2中的字段建立联合索引效果更好
3、多表join的关联列
4.6 如何选择索引列的顺序
建立索引的目的是:希望通过索引进行数据查找,减少随机IO,增加查询性能 ,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
1、区分度最高的放在联合索引的最左侧(区分度=列中不同值的数量/列的总行数);
2、尽量把字段长度小的列放在联合索引的最左侧(因为字段长度越小,一页能存储的数据量越大,IO性能也就越好);
3、使用最频繁的列放到联合索引的左侧(这样可以比较少的建立一些索引)。
4.7 避免建立冗余索引和重复索引
因为这样会增加查询优化器生成执行计划的时间。
**重复索引示例:**primary key(id)、index(id)、unique index(id)
**冗余索引示例:**index(a,b,c)、index(a,b)、index(a)
4.8 优先考虑覆盖索引
对于频繁的查询优先考虑使用覆盖索引。
覆盖索引:就是包含了所有查询字段(where,select,ordery by,group by包含的字段)的索引
覆盖索引的好处:
-
避免Innodb表进行索引的二次查询
-
Innodb是以聚集索引的顺序来存储的,对于Innodb来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询 ,减少了IO操作,提升了查询效率。
-
可以把随机IO变成顺序IO加快查询效率
由于覆盖索引是按键值的顺序存储的,对于IO密集型的范围查找来说,对比随机从磁盘读取每一行的数据IO要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的IO转变成索引查找的顺序IO。
4.9 索引SET规范
尽量避免使用外键约束
1、不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引;
2、外键可用于保证数据的参照完整性,但建议在业务端实现;
3、外键会影响父表和子表的写操作从而降低性能。
4.10 数据库SQL开发规范
4.10.1 建议使用预编译语句进行数据库操作
预编译语句可以重复使用这些计划,减少SQL编译所需要的时间,还可以解决动态SQL所带来的SQL注入的问题 只传参数,比传递SQL语句更高效 相同语句可以一次解析,多次使用,提高处理效率。
4.10.2 不允许使用属性隐式转换
隐式转换会导致索引失效。如:select name,phone from customer where id = ‘111’;
解读:假设我们在手机号列上添加了索引,然后执行下面的SQL会发生什么?explain SELECT user_name FROM parent WHERE phone=13812345678; 很明显就是索引不生效,会全表扫描。
4.10.3 充分利用表上已经存在的索引
避免使用双%号的查询条件。
如a like ‘%123%’,(如果无前置%,只有后置%,是可以用到列上的索引的)
解读:根据索引的最左前缀原理,%开头的模糊查询无法使用索引,可以使用ES来做检索。
一个SQL只能利用到复合索引中的一列进行范围查询
如:有 a,b,c列的联合索引,在查询条件中有a列的范围查询,则在b,c列上的索引将不会被用到,在定义联合索引时,如果a列要用到范围查找的话,就要把a列放到联合索引的右侧。
使用left join或 not exists来优化not in操作
因为not in 也通常会使用索引失效。
4.10.4 数据库设计时,应该要对以后扩展进行考虑
4.10.5 程序连接不同的数据库使用不同的账号,禁止跨库查询
1、为数据库迁移和分库分表留出余地
2、降低业务耦合度
3、避免权限过大而产生的安全风险
4.10.6 禁止使用SELECT * 必须使用SELECT <字段列表> 查询
原因:
-
消耗更多的CPU和IO以网络带宽资源
-
无法使用覆盖索引
-
可减少表结构变更带来的影响
-
读取不需要的列会增加CPU、IO、NET消耗;
4.10.7 禁止使用不含字段列表的INSERT语句
如:insert into values (‘a’,‘b’,‘c’);
应使用insert into t(c1,c2,c3) values (‘a’,‘b’,‘c’);
4.10.8 避免使用子查询,可以把子查询优化为join操作
通常子查询在in子句中,且子查询中为简单SQL(不包含union、group by、order by、limit从句)时,才可以把子查询转化为关联查询进行优化。
子查询性能差的原因:
1、子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响;
3、特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大;
3、由于子查询会产生大量的临时表也没有索引,所以会消耗过多的CPU和IO资源,产生大量的慢查询。
4.10.9 避免使用JOIN关联太多的表
对于Mysql来说,是存在关联缓存的,缓存的大小可以由join_buffer_size参数进行设置。
在Mysql中,对于同一个SQL多关联(join)一个表,就会多分配一个关联缓存,如果在一个SQL中关联的表越多,所占用的内存也就越大。
如果程序中大量的使用了多表关联的操作,同时join_buffer_size设置的也不合理的情况下,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
同时对于关联操作来说,会产生临时表操作,影响查询效率Mysql最多允许关联61个表,建议不超过5个。
4.10.10 减少同数据库的交互次数
数据库更适合处理批量操作 合并多个相同的操作到一起,可以提高处理效率
4.10.11 对应同一列进行or判断时,使用in代替or
应尽量避免在WHERE子句中使用or作为连接条件
in的值不要超过500个in操作可以更有效的利用索引,or大多数情况下很少能利用到索引。
解读:根据情况可以选择使用UNION ALL来代替OR。
4.10.12 禁止使用order by rand() 进行随机排序
会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值,如果满足条件的数据集非常大,就会消耗大量的CPU和IO及内存资源。
推荐在程序中获取一个随机值,然后从数据库中获取数据的方式
4.10.13 WHERE从句中禁止对列进行函数转换和计算
对列进行函数转换或计算时会导致无法使用索引。
不推荐:
where date(create_time)='20190101'
推荐:
where create_time >= '20190101' and create_time < '20190102'
4.10.14 在明显不会有重复值时使用UNION ALL而不是UNION
1、UNION会把两个结果集的所有数据放到临时表中后再进行去重操作
2、UNION ALL不会再对结果集进行去重操作
4.10.15 拆分复杂的大SQL为多个小SQL
1、大SQL:逻辑上比较复杂,需要占用大量CPU进行计算的SQL
2、MySQL:一个SQL只能使用一个CPU进行计算
3、SQL拆分后可以通过并行执行来提高处理效率
4.10.16 禁止使用外键与级联,一切外键概念必须在应用层解决
- 解读:外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
4.11 数据库操作行为规范
4.11.1 超100万行的批量写(UPDATE、DELETE、INSERT)操作,要分批多次进行操作
大批量操作可能会造成严重的主从延迟
主从环境中,大批量操作可能会造成严重的主从延迟,大批量的写操作一般都需要执行一定长的时间,而只有当主库上执行完成后,才会在其他从库上执行,所以会造成主库与从库长时间的延迟情况
binlog日志为row格式时会产生大量的日志
大批量写操作会产生大量日志,特别是对于row格式二进制数据而言,由于在row格式中会记录每一行数据的修改,我们一次修改的数据越多,产生的日志量也就会越多,日志的传输和恢复所需要的时间也就越长,这也是造成主从延迟的一个原因。
避免产生大事务操作
大批量修改数据,一定是在一个事务中进行的,这就会造成表中大批量数据进行锁定,从而导致大量的阻塞,阻塞会对MySQL的性能产生非常大的影响。
特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批。
4.11.2 对于大表使用pt-online-schema-change修改表结构
1、避免大表修改产生的主从延迟
2、避免在对表字段进行修改时进行锁表
对大表数据结构的修改一定要谨慎,会造成严重的锁表操作,尤其是生产环境,是不能容忍的。
pt-online-schema-change它会首先建立一个与原表结构相同的新表,并且在新表上进行表结构的修改,然后再把原表中的数据复制到新表中,并在原表中增加一些触发器。
把原表中新增的数据也复制到新表中,在行所有数据复制完成之后,把新表命名成原表,并把原来的表删除掉。
把原来一个DDL操作,分解成多个小的批次进行。
4.11.3 禁止为程序使用的账号赋予super权限
当达到最大连接数限制时,还运行1个有super权限的用户连接super权限只能留给DBA处理问题的账号使用。
4.11.4 对于程序连接数据库账号,遵循权限最小原则
程序使用数据库账号只能在一个DB下使用,不准跨库 程序使用的账号原则上不准有drop权限。
五、接口设计规范
5.1 基本规范
5.1.1 公共参数
公共参数是每个接口都要携带的参数,描述每个接口的基本信息,用于统计或其他用途,放在header或url参数中。例如:
| 字段名称 | 说明 |
|---|---|
| version | 客户端版本。1.0.0 |
| token | 登录令牌 |
| os | 手机系统版本。12 |
| from | 请求来源。android/ios/h5 |
| screen | 手机尺寸。1080*1920 |
| model | 机型。IPhone7 |
| net | 网络状态。wifi |
5.1.2 响应数据
为了方便给客户端响应,响应数据会包含三个属性,状态码(code),信息描述(message),响应数据(data)。客户端根据状态码及信息描述可快速知道接口,如果状态码返回成功,再开始处理数据。
array类型数据。通过list字段,保证data的Object结构。
分页类型数据。返回总条数,用于判断是否可以加载更多。
// object类型数据
{
"code":1,
"msg":"成功",
"data":{
}
}
// array类型数据。
{
"code":1,
"msg":"成功",
"data":{
"list":[]
}
}
// 分页类型数据。
{
"code":1,
"msg":"成功",
"data":{
"list":[]
"total":"10"
}
}
列表类数据接口,无论是否要求分页,最好支持分页,pageSize=Integer.Max即可。
响应结果定义及常用方法:
public class R implements Serializable {
private static final long serialVersionUID = 793034041048451317L;
private int code;
private String message;
private Object data = null;
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public Object getData() {
return data;
}
/**
* 放入响应枚举
*/
public R fillCode(CodeEnum codeEnum){
this.setCode(codeEnum.getCode());
this.setMessage(codeEnum.getMessage());
return this;
}
/**
* 放入响应码及信息
*/
public R fillCode(int code, String message){
this.setCode(code);
this.setMessage(message);
return this;
}
/**
* 处理成功,放入自定义业务数据集合
*/
public R fillData(Object data) {
this.setCode(CodeEnum.SUCCESS.getCode());
this.setMessage(CodeEnum.SUCCESS.getMessage());
this.data = data;
return this;
}
}
5.1.3 字段类型规范
统一使用String类型。某些情况,统一使用String可以防止解析失败,减少类型转化操作。
Boolean类型,1是0否。客户端处理时,非1都是false。
if("1".equals(isVip)){
}else{
}
status类型字段,从1+开始,区别Boolean的0和1。“0”有两种含义,(1)Boolean类型的false,(2)默认的status
5.1.4 上传/下载
上传/下载,参数增加文件md5,用于完整性校验(传输过程可能丢失数据)。
5.1.5 避免精度丢失
缩小单位保存数据,如:钱以分为单位、距离以米为单位。
5.2 调用接口的先决条件-token
获取token一般会涉及到几个参数appid,appkey,timestamp,nonce,sign。我们通过以上几个参数来获取调用系统的凭证。
appid和appkey可以直接通过平台线上申请,也可以线下直接颁发。appid是全局唯一的,每个appid将对应一个客户,appkey需要高度保密。
timestamp是时间戳,使用系统当前的unix时间戳。时间戳的目的就是为了减轻DOS攻击。防止请求被拦截后一直尝试请求接口。服务器端设置时间戳阀值,如果请求时间戳和服务器时间超过阀值,则响应失败。
nonce是随机值。随机值主要是为了增加sign的多变性,也可以保护接口的幂等性,相邻的两次请求nonce不允许重复,如果重复则认为是重复提交,响应失败。
sign是参数签名,将appkey,timestamp,nonce拼接起来进行md5加密(当然使用其他方式进行不可逆加密也没问题)。
token,使用参数appid,timestamp,nonce,sign来获取token,作为系统调用的唯一凭证。token可以设置一次有效(这样安全性更高),也可以设置时效性,这里推荐设置时效性。如果一次有效的话这个接口的请求频率可能会很高。token推荐加到请求头上,这样可以跟业务参数完全区分开来。
5.3 使用POST作为接口请求方式
一般调用接口最常用的两种方式就是GET和POST。两者的区别也很明显,GET请求会将参数暴露在浏览器URL中,而且对长度也有限制。为了更高的安全性,所有接口都采用POST方式请求。
5.3.1 GET、POST、PUT、DELETE对比
1. GET
- 安全且幂等
- 获取表示
- 变更时获取表示(缓存)
适合查询类的接口使用
2. POST
- 不安全且不幂等
- 使用服务端管理的(自动产生)的实例号创建资源
- 创建子资源
- 部分更新资源
- 如果没有被修改,则不过更新资源(乐观锁)
适合数据提交类的接口使用
3. PUT
- 不安全但幂等
- 用客户端管理的实例号创建一个资源
- 通过替换的方式更新资源
- 如果未被修改,则更新资源(乐观锁)
适合更新数据的接口使用
4. DELETE
- 不安全但幂等
- 删除资源
适合删除数据的接口使用
5.4 客户端IP白名单
ip白名单是指将接口的访问权限对部分ip进行开放。这样就能避免其他ip进行访问攻击,设置ip白名单比较麻烦的一点就是当你的客户端进行迁移后,就需要重新联系服务提供者添加新的ip白名单。设置ip白名单的方式很多,除了传统的防火墙之外,spring cloud alibaba提供的组件sentinel也支持白名单设置。为了降低api的复杂度,推荐使用防火墙规则进行白名单设置。
5.5 单个接口针对ip限流
限流是为了更好的维护系统稳定性。使用redis进行接口调用次数统计,ip+接口地址作为key,访问次数作为value,每次请求value+1,设置过期时长来限制接口的调用频率。
5.6 记录接口请求日志
使用aop全局记录请求日志,快速定位异常请求位置,排查问题原因。
5.7 敏感数据脱敏
在接口调用过程中,可能会涉及到订单号等敏感数据,这类数据通常需要脱敏处理,最常用的方式就是加密。加密方式使用安全性比较高的RSA非对称加密。非对称加密算法有两个密钥,这两个密钥完全不同但又完全匹配。只有使用匹配的一对公钥和私钥,才能完成对明文的加密和解密过程。
5.8 瘦客户端
客户端尽量不处理逻辑
客户端不处理金额
客户端参数校验规则可以通过接口返回,同时提供默认规则,接口不通则使用默认规则。
5.9 拓展性
图片文案等,与校验规则类似,通过接口返回,并提供默认。
列表界面
// 静态列表
{
"name": "张三",
"sex": "男",
"age": "20岁",
"nickName": "小张"
}
// 动态列表
{
"userInfos":[
{
"key":"姓名",
"value":"张三"
},{
"key":"性别",
"value":"男"
},{
"key":"年龄",
"value":"20岁"
},{
"key":"昵称",
"value":"小张"
}]
}
多个boolean可以flag替换
{
"flag":"7" // 二进制:111,三位分别表示三个boolean字段
}
long flag = 7;
System.out.println("bit="+Long.toBinaryString(flag));
System.out.println("第一位="+((flag&1)==1));
System.out.println("第二位="+((flag&2)==1));
System.out.println("第三位="+((flag&4)==1));
5.10 响应状态码
采用http的状态码进行数据封装,例如200表示请求成功,4xx表示客户端错误,5xx表示服务器内部发生错误。状态码设计参考如下:
| 分类 | 描述 |
|---|---|
| 1xx | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2xx | 成功 |
| 3xx | 重定向,需要进一步的操作以完成请求 |
| 4xx | 客户端错误,请求包含语法错误或无法完成请求 |
| 5xx | 服务端错误 |
状态码枚举类:
public enum CodeEnum {
// 根据业务需求进行添加
SUCCESS(200,"处理成功"),
ERROR_PATH(404,"请求地址错误"),
ERROR_SERVER(505,"服务器内部发生错误");
private int code;
private String message;
CodeEnum(int code, String message) {
this.code = code;
this.message = message;
}
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
}
5.10.1 正常响应
响应状态码2xx
- 200:常规请求
- 201:创建成功
5.10.2 重定向响应
响应状态码3xx
- 301:永久重定向
- 302:暂时重定向
5.10.3 客户端异常
响应状态码4xx
- 403:请求无权限
- 404:请求路径不存在
- 405:请求方法不存在
5.10.4 服务器异常
响应状态码5xx
- 500:服务器异常