目录
一、ElasticSearch基本概念
1.Lucene和ElasticSearch关系
Lucene是一套信息检索工具包,是一个jar包。
Lucene包含索引结构,读写索引的工具,排序,搜索规则等等,不包含搜索引擎系统。
ElasticSearch是基于Lucene做一个封装和增强
2.ElasticSearch概述
ElasticSearch又叫es,是一个开源的高拓展的分布式全文检索引擎,它可以近乎实时的存储、检索数据。es使用java开发并使用Lucene作为其核心来实现所有索引和引擎功能,但是它的目的是通过简单地RESTful API来隐藏Lucene的复杂性,从而让搜索变得更简单。
es是一个实时分布式搜索和分析引擎,能以前所未有的速度处理大数据。它用于全文搜索,结构化搜索,分析。
3.es和solr比较
(1)对单纯的已有的数据进行搜索:solr更快
(2)当实时建立索引时,solr会产生io阻塞,es会快得多
(3)随着数据里越来越大,solr效率会越来越低,es完全没影响
4.ELK
什么是ELK?
ELK = ElasticSearch + Logstash + Kibana,也被称为Elastic Stack
其中es作为底层支持架构,用来做搜索。Lgostash是ELK的中央数据流引擎,拥有将不同格式数据过滤输出到不同目的地。Kibana将数据友好展示,并提供实时分析功能。
二、ES,head插件,Kibana插件的安装
1.下载windows版本es
注:jdk最低要1.8及以上!!!
官网地址:https://www.elastic.co/cn/downloads/elasticsearch
注:实际操作中我们下载的是7.6.1的windows版本。


直接解压就可以用了。

启动好之后登陆9200端口可以看到一串话表示成功:

2.安装head可视化界面
(1)下载
进入github:https://github.com/mobz/elasticsearch-head#running-with-built-in-server
然后下载:

(2)下载安装node.js和grunt
node.js:
node下载地址:https://nodejs.org/en/download/,下载对应环境的node版本安装即可,安装步骤略过了。
安装过程结束后,在dos窗口查看是否安装成功,使用命令:node -v。
grunt:
在node安装路径下,使用命令安装:npm install -g grunt-cli 安装grunt。
安装结束后,使用命令grunt -version查看是否安装成功。

(3)解决跨域问题
在elasticsearch.yml添加:

http.cors.enabled: true
http.cors.allow-origin: "*"然后重启es的bat文件:

(4)启动head
#打开cmd,输入如下指令
cnpm install
npm run start注:如果显示你cnpm不是内部或外部命令:
npm install -g cnpm --registry=https://registry.npm.taobao.org
cnpm -v
成功,且没有跨域问题:

简单的可以把索引当成数据库。
3.安装kibana
(1)下载
官网:https://www.elastic.co/cn/kibana/
下载地址:https://www.elastic.co/cn/downloads/kibana
注:要和es的版本一致,我们学习的时候下载windows版本

(2)启动
解压好后双击bat文件启动:


(3)开发工具,汉化
点击左边Dev Tools开发工具:
 后续我们就在这边做测试:
后续我们就在这边做测试:

再来做一下汉化:


修改完汉化后重启项目,一个字:爽!

三、ES核心概念理解
1.es与数据库对比
es是面向文档。一切内容都是json。我们可以对照关系型数据库理解es:
| 关系型数据库 | ElasticSearch |
| 数据库(db) | 索引(indices) |
| 表(tables) | types(慢慢被弃用) |
| 行(rows) | documents(文档) |
| 字段(columns) | fields |
es中可以包含多个索引(数据库),每个索引中包含多个类型(表),每个类型包含多个文档(行),每个文档包含多个列(字段)
2.物理设计
es在后台把每个索引分成多个分片,每片分片可以在集群中的不同服务器间迁移。
如果只启动一个es那它一个人也是一个集群。默认的集群名称是elasticsearch
3.逻辑设计
一个索引类型中,包含多个文档,当我们索引一篇文章时,通过这样的顺序查找:索引==>类型==>文档ID。通过这个组合我们就能索引到某个具体的文档。
我自己的简单理解:一个大的json就是索引,json里的key:value就是文档,而key:value对应的类型映射就是类型。
(1)文档
索引和搜索数据最小单位是文档,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和值,即key:value
- 层次型,一个json可以有多个层级
- 文档不依赖预先定义的模式。一个复杂的json对象,对其中添加一个字段减少一个字段很方便,而数据库需要先新建字段,才可以在对应字段添加数据
(2)类型
类型中对于字段的定义称为映射,比如name映射为字符串类型。
一个json你添加一个key:value,es会去猜你这个value的值是什么类型,这个猜有可能会猜错,所以我们最好就是提前定义好需要的映射,每个映射的值是什么类型。后面操作的时候就按照定义的来就行。
(3)索引
索引是映射类型的容器,es中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置,然后他们被存储到各个分片上
4.节点和分片
一个集群至少有一个节点,而一个节点就是一个elasticsearch进程。
节点可以有多个索引。如果你创建索引,那么索引将会有5个分片(主分片)。每个主分片会有都会有一个副分片(复制分片)。(分片可以认为一个索引被分成了5个部分,每部分叫一个分片)
如果集群有多个节点,一个节点创建了一个索引,这个索引有5个分片,这5个分片不一定都在同一个节点下,有可能在不同的节点下。实际上,每个分片 都是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得es在不扫面全部文档的情况下,就能告诉你哪些文档包含特定的关键词。
5.倒排索引
上面说了,每个分片都是一个Lucene索引,每个分片都包含倒排索引的文件目录。
常规索引是key:value铺开,有多少条数据就有多少key:value,时间复杂度为n。
倒排索引可以理解为value:keys。包含某个value的key分别是哪些,然后每次要查找指定value的时候就可以直接在keys里去找了,而不用遍历所有。
6.es的索引和Lucene索引的对比
在es中索引被分为多个分片,每份分片是一个Lucene的索引。所以一个es索引是多个Lucene索引组成的。
四、IK分词器
1.什么是分词器
分词:把一段中文或者别的划分为一个个的关键字,我们在搜索的时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,这不符合要求,因此需要中文分词器ik来解决这个问题。
2.ik中的两个分词算法
ik_smart:最少切分
ik_max_word:最细粒度划分
3.下载,安装,启动
(1)下载
注意版本:https://github.com/medcl/elasticsearch-analysis-ik/releases
(2)放到es的plugins目录下
注1:路径不要有中文
注2:压缩包要删掉,不然有可能启动不起来
(3)重启es
注1:重启 的时候关闭head和kibana和es,再重启
可以看到我们加载了ik,这样就是成功了:

也可以bin下重新开一个cmd,输入:
elasticsearch-plugin list
(4)重启kibana测试
ik_smart:

ik_max_word:

4.自定义分词
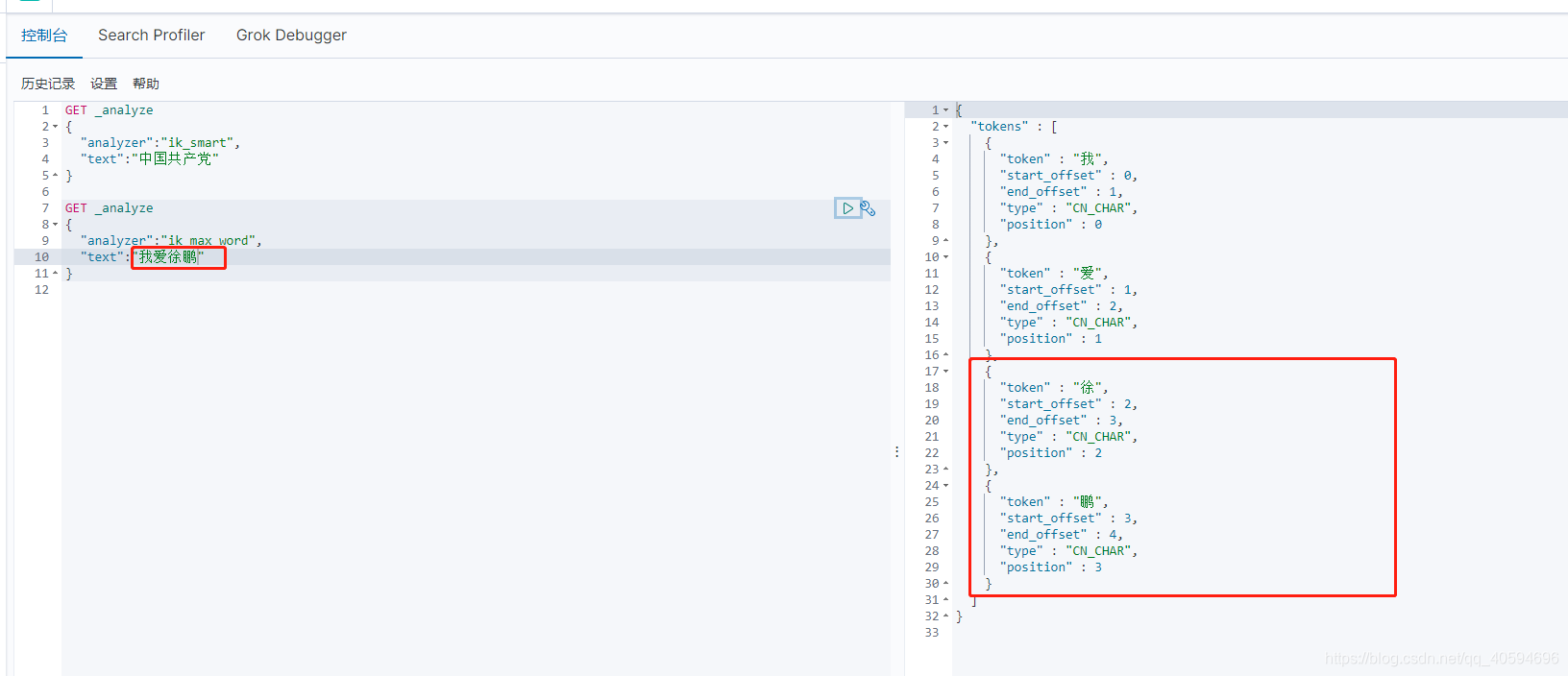
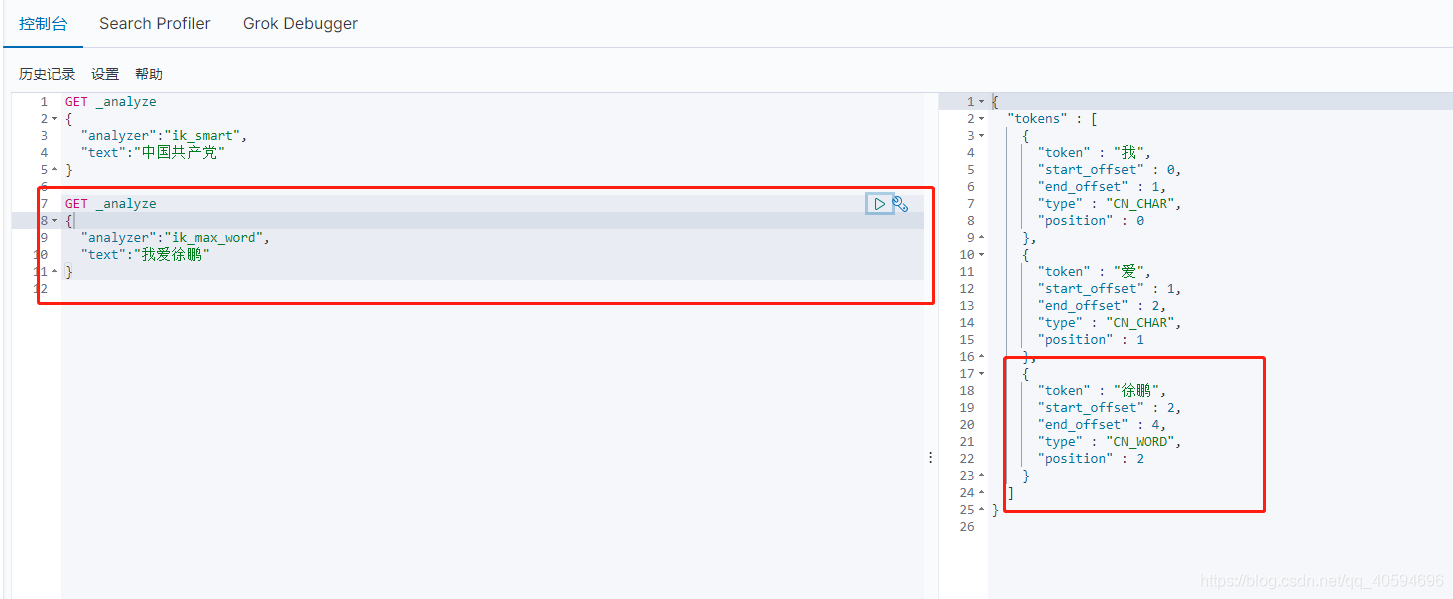
现在有一个问题,如果我们输入“我爱徐鹏”,我们要把徐鹏作为一个整体,但是因为默认汉字是单个拆分,不符合我们的需求。我们需要自定义“徐鹏”,让es能够将其视为一个整体。
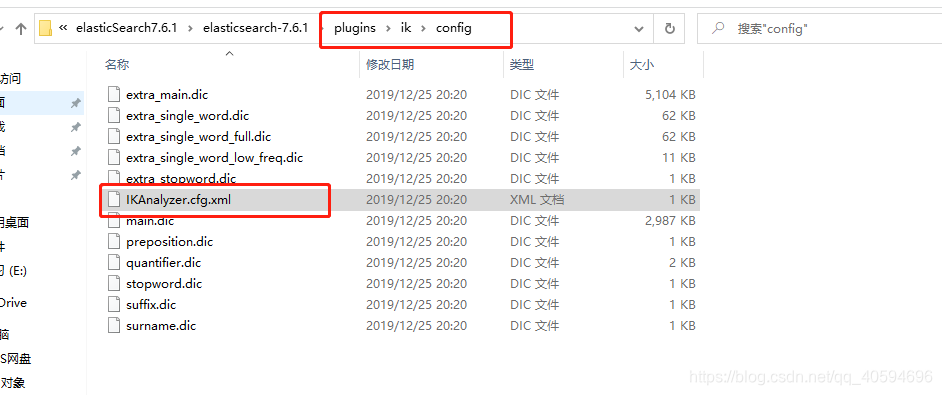
(1)修改IKAnalyzer.cfg.xml文件
.进入es的plugins,找到IKAnalyzer.cfg.xml文件:
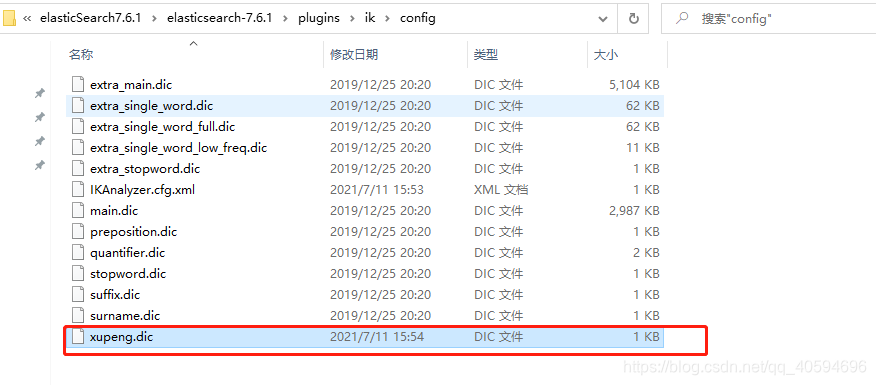
自定义一个文件名称:
(2)新建自定义文件
我们然后新建自定义文件:
注:新建时最好复制其他的dic再粘贴,避免编码等问题

(3)重启es和kibana,并测试
我们发现,徐鹏已经作为一个整体用来查询了
五、打赏请求
如果本篇博客对您有所帮助,打赏一点呗,谢谢了呢~
