作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121215445
目录
第1章 多维数据输入时遇到的困境(为什么要标准化、规范化数据集)
3.1 什么是正态分布(normal distribution)
3.6 什么是标准正态分布(standard normal distribution)
第1章 多维数据输入时遇到的困境(为什么要标准化、规范化数据集)
1.1 多维输入的困境

在现实生活中,一个目标变量(Yi)可以认为是由多维特征变量(x)影响和控制的。如上图左图中的X1_i,X2_i,X3_i ,其中i = 0,1,2,3......
这些特征变量的量纲和数值的量级就会不一样,比如x1_i = 10000,x2_i = 10,x3_i = -0.5.
可以很明显的看出特征x1和x2、x3存在量纲的差距;但不表明,X1_i对神经网络输出的影响是X2_i对神经网络输出的影响是10000/10 = 1000倍,只表明X1_i在数值上比较大而已,X1_i的波动幅度才是对神经网络的影响程度。同理X2_i和X3_i的绝对值也不表明其影响小,其波动幅度,反应X2_i的样本对神经网络的影响程度。
比如,反应一个人健康的因素有很多种,如体重、身高、血压、血脂等。
(1)体重:如果量纲是斤,其数值如120斤,如果量纲是克,其数值为120 * 1000 克。
(2)升高:如果量纲是米,其数值如 1.7米,如果量纲是厘米,其数值为1.7 * 100 = 170厘米
(3)血压:如120.
(4)血脂含量如:0.2
如果,是单一因素,作为神经网络的参数,其采用什么量纲并不重要,只要大家都遵循相同的量纲标准就可以了,如体重,不同人的体重比较,可以以米为单位进行比较,也可以厘米为单位进行比较,只要所有人的单位一直就可以。
体重血脂含量的大小的数值比较没有意义。
1.2 绝对值大小的负面影响
上述因素都反应健康状态,如果把这些因素作为神经网络的输入,就带来一个问题,对于神经网络而言,体重和血压是同等对待的,然后体重的数值比血脂含量要大很多很多;如果不对数值进行处理,就导致血脂含量较小的绝对数值的影响被体重的数值被覆盖。这很显然是不合理的。
如何有效的处理这个问题呢?如何有效的处理这些不同量纲的数据呢?
标准化是应对上述问题一种有效的方法!!!
1.3 RGB图像也有同样的困境吗?
虽然,图像的每个通道的每个像素值,都被限定在0-255之间,按理说,每张图片的每个像素的量纲是相同的,不存在上述问题,但实际也有问题。比如,同一物体,不同的背景光线的情况下,拍出来的照片的亮度是不一样的,所有像素点的数值的基准实际上相差很大,然而,他们是相同的物体,不能因为他们的背景的光线的基准不同,就把他们作为差别较大的对象来处理。
如何处理这个问题呢?
1.4 应对上述问题的思路
(1)不同量纲的原始数据
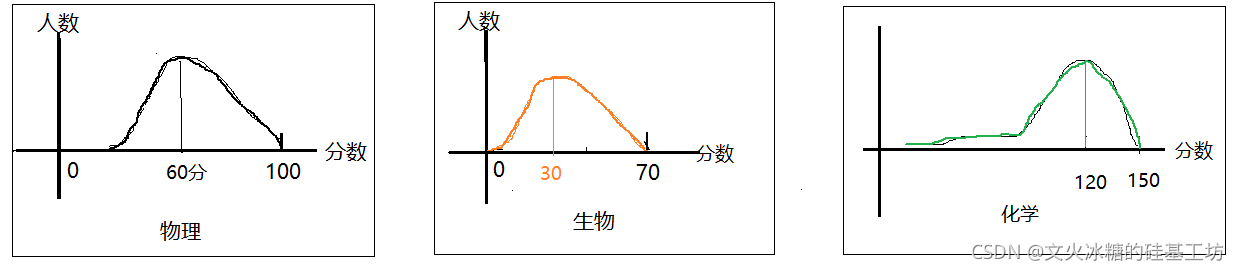
(2)折算到相同的空间
应对上述问题,一种有效的方式,就是使得不同量纲的数据,进行标准化,不管其数值大小基准是多少,我们都把他们压缩到相同的数值空间中;避免不同量纲数值在有较大的差异。
有点像考试,不管原始的总分是多少,70也好,150分也好,把所有科目的分数都折算成100制,这样不同科目就有一定的可比性。
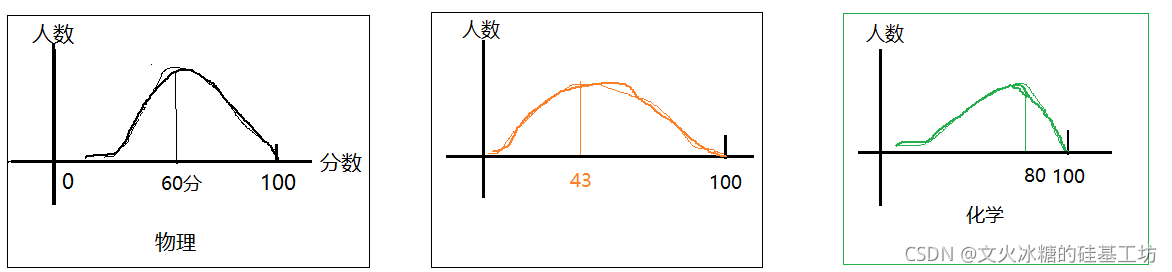
(2)折算到相同均值空间
不同科目的难度程度可能不同,因此,折算成百分制后,不同科目其实还没有可比性。为此,还需要按照各科目的平均成绩在进行一次折算,比如物理比较难,均分才60分,化学比较简单,均分在90分,经过均值折算后,他们都折算成一个新的数值。这样化学的分数与物理的分数就有了可比性。

上述两种方法的思路,就是标准化、规范化的基本思想。
第2章 什么是规范化与标准化?
2.1 规范化、标准化的概述
(1)规范化:Normalization
Normalization的中文翻译一般叫做“规范化”,是一种对数值的特殊函数变换方法,也就是说假设原始的某个数值是x,套上一个起到规范化作用的函数,对规范化之前的数值x进行转换,形成一个规范化后的数值。
规范化,完成了不同维度数据的规范和统一,但并没有对如何规范作出规定。就拿考试来讲,是规范到100制度,还是规范到150制上,并不要求,只要所有的输入都规范到相同的空间就行了。
Normalization虽然解决了自身的输入数据不同维度的规范化,但他没有解决如何规范的问题。
(2)标准化:Standardization
Standardization在Normalization的基础之上,对输入数据进行了进一步的明确和规定,比如对考试而言,不仅仅明确规定要规范到100分制,还要不同科目的不同难易程度进行规范化,采用标准化正态分布的方式,进行不同难度的规范化。
(3)规范化和标准化
在实际实现是,有时候并不区分规范化:Normalization和标准化:Standardization,他们最终的行为都是标准化。
2.2 标准化的本质
(1)标准化的本质是数值空间的重新映射
(2)标准化的映射的标准化是正态分布
第3 章 正态分布
3.1 什么是正态分布(normal distribution)
标准正态分布包含了1个关键词:normal
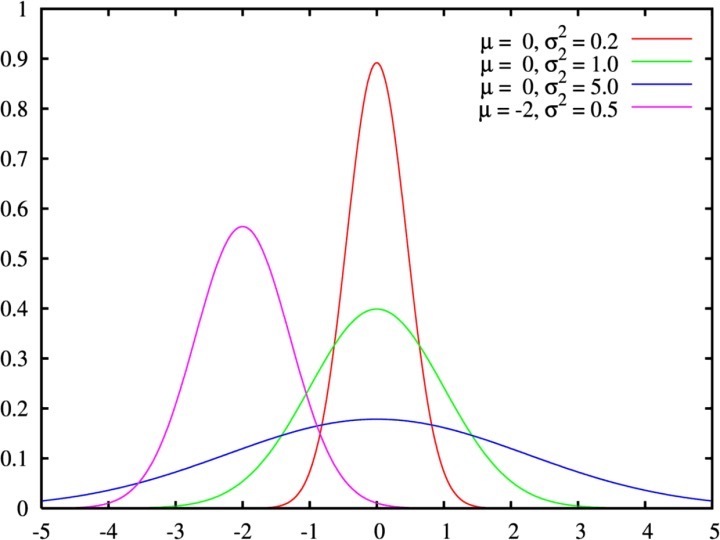
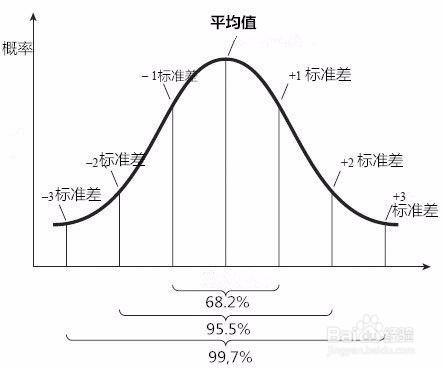
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及project等领域都很重要的概率分布,在统计学的很多方面有着重大的影响力。
正态分布的期望值μ决定了其分布的中心点的位置,其标准差σ决定了分布的幅度,扁平程度或数据的发散程度。
正态分布像一只倒扣的钟。两头低,中间高,左右对称。
大部分数据集中在平均值,小部分在两端。
因其曲线呈钟形,因此人们又常常称之为钟形曲线,如下图所示:
3.2 什么是算术平均值(加法运算)
(1)算术平均值
算术平均数,又称均值,是统计学中最基本、最常用的一种平均指标。分为简单算术平均数、加权算术平均数。
根据表现形式的不同,算术平均数有不同的计算形势和计算公式。其中,算术平均数是加权平均数的一种特殊形式(它特殊在各项的权相等),当实际问题中,当各项权不相等时,计算平均数时就要采用加权平均数,当各项权相等时,计算平均数就要采用算数平均数。
(2)简单算术平均值

(3)加权平均值

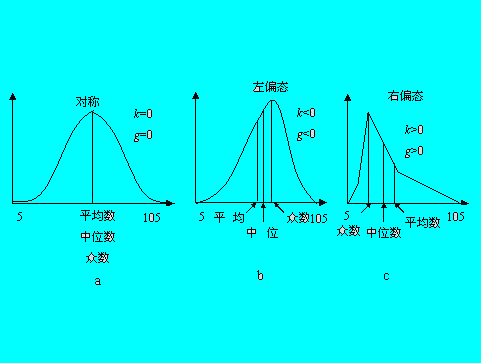
(4)算术均值的形态分类
3.3 与几何平均的区别(乘法运算)

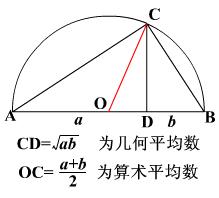
备注:方差用到的是算术平均!
3.4 什么是方差

这里用到的是统计描述中方差定义。 它是衡量取值分散程度或波动程度的一个尺度。
方差越小,数值越集中。
方差越大,数值越发散。
3.5 什么是标准差

标准差:是方差的开根号。
1个标准差,表示距离平均值1个标准差的位置,
2个标准差,表示距离平均值2个标准差的位置,
3个标准差,表示距离平均值3个标准差的位置。
3.6 正态分布实例
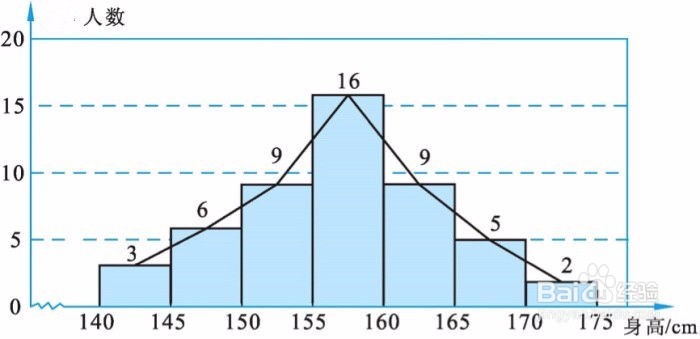
实际上人的身高和血压就是符合正态分布的。
(1)人群身高分布
(2)人群舒张压分布
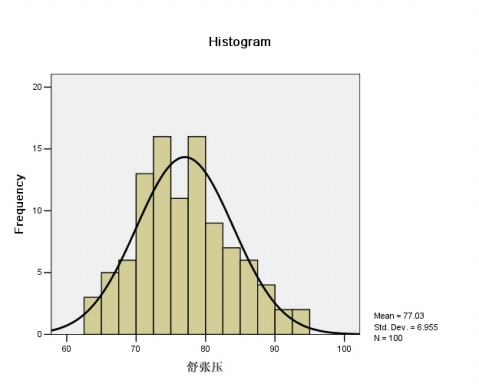
上图中,均值u=77.03,标准化差为6.955, 最大值为N=100
(3)收入水平
你去公司上班打工的商业模式,也是符合正态分布的。
大部分打工仔是处于中间平均位置的,既不能大富大贵,也不会穷到沦落街头。
3.6 什么是标准正态分布(standard normal distribution)
标准正态分布保护了两个关键词:standard normal
standard:标准化
normal:正态化、规范化、常规化
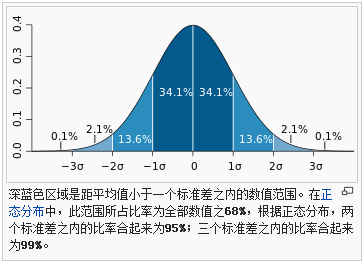
标准正态分布又称为u分布,是以u=0为均数、以1为标准差的正态分布,记为N(0,1)。
备注:
标准正态分布的数值,并不是表示所有的数值都分布在【0,1】之间。
上面的0表示均值,1表示标准差。实际的数值分布:
- 包括正数和负数
- 68.2%的数值分布在[-1, +1]之间。
- 13.6%的数值分布在[-2, -1]之间,13.6%的数值分布在[+1, +2]之间
- 其他......
第4章 标准化与归一化的区别
4.1 什么是归一化
归一化是一种无量纲处理手段,使物理系统数值的绝对值变成某种相对值关系。
简化计算,缩小量值的有效办法。
归一化方法有两种形式:
(1)一种是把数变为(0,1)之间的小数,
(2)一种是把有量纲表达式变为无量纲表达式。
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
4.2 归一化的两种分类
(1)绝对值最大归一化
用一组数据中的绝对值最大值作为基数,其他数值与该基数相除得到的数值,就是绝对值最大归一化。
这种归一化的结果是:
- 所有的数据变限制在[-1, +1]之间
- 所有值的累计和不为0.
(2)累计和归一化
用一组数据中的累计和作为基数,其他数值与该基数相除得到的数值,就是累计和归一化。
这种归一化的的结果是:
- 所有的数据变限制在[-1, +1]之间
- 所有值的累计和为0
(3)最大值值减去最小值的归一化:
这种方法,使用一组数据中的最大值-最小值作为基数(最大相对距离),用实际值-最小值作相对值(样本的相对距离),即xi-min(xi)/(max(xi)-min(xi))
这种归一化的的结果是:
- 所有的数据变限制在[0, +1]之间
- 所有值的累计和为0
这是最常用的归一化的方法。
4.3 标准化与归一化的区别
(1)相同点
- 对原始的数据进行了缩小映射。
(2)不同点
- 归一化后的数据,全部都被限制在[0,1] 之间。
- 标准化后的数据,大部分(68.2%)数据被限制[-1,+1] 之间,其他数据超出[-1,+1]区间,甚至还有非常大的数据。
- 归一化不需要指定参数,只使用样本数据即可;标准化需要指定标准化化的均值和方差值,相同的输入数据,不同的均值和方差值设定,标准化后的数据是不相同的。
4.4 任何数据集都可以归一化吗?
是的,任何数据集,都可以通过归一化的方法,进行映射,映射后的数据,全部被限制在【0,1】之间。
4.5 任何数据集都可以标准化吗?
是的,任何一个数据集,都可以通过标准化的方式,进行映射,映射后的数据,符合标准化正态分布的形态。
实际上,每一张图片的像素点的数值,就是一个数据集。不同的图片,就是不同的数据集。每个章图片,都可以通过标准化化的方式进行图片像素点的转换,转换成符合正态分布。
第5章 标准化带来的好处
(1)避免大数“吃”小数的情形
不同量纲的数据之间,他们是对等的,不会出现,因为量纲的不同,导致大量纲的数据把小量纲的数据“吃”掉的情形。
(2)提升了模型的泛化能力
不同原始数据的形态千差万别,经过标准化后,对深度学习的模型就是对等的,模型的训练,如果基于标准化后的数据进行训练,就可以泛化到任意形态的输入数据上。
(3)提升模型的训练速度
经过标准化后,输入数据符合正态分布,这就意味着,参数的参数也是符合正态分布,如果初始化的时候,就按照正态分布的方式初始化模型的参数,而不是以全0或随机的方式初始化数据,模型训练的收敛速度就非常快。
(4)降低了模型不收敛,陷入局部收敛的困境
因为模型初始化参数,是按照正态分布初始化,初始化的参数的分布与理想情形的分布是接近的,因此降低了随机初始化导致的局部收敛的情形。
第6章 什么时候使用标准化
标注化主要针对的是送入神经网络模型中的数据的,因此使用标准化化的场合就是针对这些数据的 。
(1)当数据集的各个特征取值范围存在较大差异时。
(2)各特征取值单位差异较大时。
第7章 标准化的代码实现
参看后续关于Pytorch或Tensorflow相关标准化接口函数的解读文章。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121215445