Count(1) Count(0) Count(*) Count(列名)
count(1) count(0) count(*) 三者查询效率没有明显差别,
1. count(1) and count(*)
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了!
从执行计划来看,count(1)和count()的效果是一样的。 但是在表做过分析之后,count(1)会比count()的用时少些(1w以内数据量),不过差不了多少。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count( ∗ * ∗)自动会优化指定到那一个字段。所以没必要去count(1),用count( ∗ * ∗),sql会帮你完成优化的 因此: count(1)和count(*)基本没有差别!
2. count(1) and count(字段)
两者的主要区别是
(1) count(1) 会统计表中的所有的记录数, 包含字段为null 的记录。
(2) count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即 不统计字段为null 的记录。
这里是一个简单的这次测试的脚本
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for test
-- ----------------------------
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`age` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of test
-- ----------------------------
INSERT INTO `test` VALUES (1, 'zhangsan', NULL);
INSERT INTO `test` VALUES (2, '', 23);
INSERT INTO `test` VALUES (3, 'tom', 25);
INSERT INTO `test` VALUES (4, 'q', 23);
SET FOREIGN_KEY_CHECKS = 1;
这个是这个表呈现的样子。

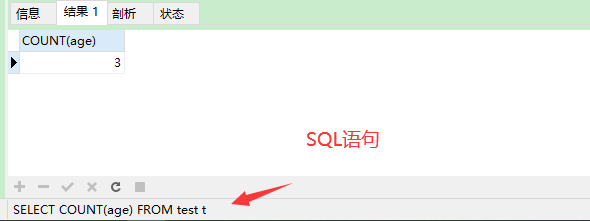
SELECT COUNT(age) FROM test t;
可以看到count列名,只有3列,除去了第一列age为空的那一列
SELECT COUNT(0) FROM test t;
SELECT COUNT(1) FROM test t;
SELECT COUNT(*) FROM test t;
这三条查询都是返回的结果4

count(*)包括了所有的列,相当于行数,在统计结果的时候, 不会忽略列值为NULL
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候, 不会忽略列值为NULL
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数, 即某个字段值为NULL时,不统计。
执行效率上:
列名为主键,count(列名)会比count(1)快
列名不为主键,count(1)会比count(列名)快
如果表多个列并且没有主键,则 count(1) 的执行效率优于 count()
如果有主键,则 select count(主键)的执行效率是最优的
如果表只有一个字段,则 select count()最优。